数据库原理 - 序列2 - 事务隔离级别和死锁检测
2019-04-11 10:59 travis2046 阅读(458) 评论(0) 收藏 举报本文节选自《软件架构设计:大型网站技术架构与业务架构融合之道》第6.4章节。 作者微信公众号:
架构之道与术。进入后,可以加入书友群,与作者和其他读者进行深入讨论。也可以在京东、天猫上购买纸质书。
6.4.1 事务的四个隔离级别
通俗地讲,事务就是一个“代码块”,这个代码块要么不执行,要么全部执行。事务要操作数据(数据库里面的表),事务与事务之间会存在并发冲突,就好比在多线程编程中,多个线程操作同一份数据,存在线程间的并发冲突是一个道理。
事务与事务并发地操作数据库的表记录,可能会导致下面几类问题,如表6-3所示。
表6-3 事务并发导致的几类问题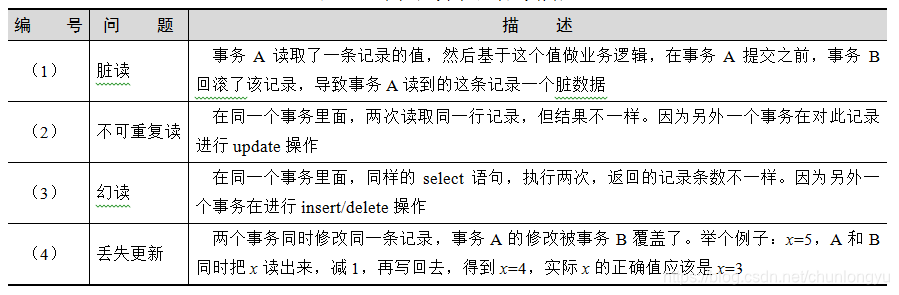
为了解决上面几类问题,数据库设置了不同的事务隔离级别。不同数据库在事务隔离级别的定义和实现上会有差异,下面以MySQL InnoDB引擎为例,分析隔离级别是如何定义的,如表6-4所示。
表6-4 InnoDB事务隔离级别
从表6-4中可以看出,隔离级别,一级比一级严格。隔离级别4就是串行化,所有事务串行执行,虽然能解决上面的四个问题,但性能无法接受,所以一般不会采用;隔离级别1没有任何作用,也不会采用;所以常用的是隔离级别2和隔离级别3。
既然默认的隔离级别是3(RR),如何解决最后一个问题,丢失更新呢?这涉及下面要讲的悲观锁和乐观锁。
6.4.2 悲观锁和乐观锁
丢失更新在业务场景中非常常见,数据库没有帮工程师解决这个问题,只能靠我们自己解决了。先看丢失更新出现的场景:假设DB中有张数据表,如表6-5所示。
表6-5 用户余额表T
两个事务并发地对同一条记录进行修改,一个充钱,一个扣钱,伪代码如下:
事务A:
start transaction
int b = select balance from T where user_id = 1
b = b + 50
update T set balance = b where user_id = 1
commit事务B:
start transaction
int b = select balance from T where user_id = 1
b = b - 50
update T set balance = b where user_id = 1
commit如果正确地执行了事务A和事务B(无论谁先谁后),执行完成之后,user_id=1的用户余额都是30;但现在事务A和事务B并行执行,执行结果可能是30(正确结果),也可能是80(事务A把事务B的结果覆盖了),或者是20(事务B把事务A的结果覆盖了),这两种结果都是错误的。
要解决这个问题,有下面几种方法:
方法1:利用单条语句的原子性
在上面的每个事务里,都是把数据先select出来,再update回去,没有办法保证两条语句的原子性。如果改成一条语句,就能保证原子性,如下所示:
事务A:
start transaction
update T set balance = balance + 50 where user_id = 1
commit事务B:
start transaction
update T set balance = balance -50 where user_id = 1
commit这种方法简单可行,但很有局限性。因为实际的业务场景往往需要把balance先读出来,做各种逻辑计算之后再写回去。如果不读,直接修改balance,没有办法知道修改之前的balance的值是多少。
方法2:悲观锁
悲观锁,就是认为数据发生并发冲突的概率很大,所以读之前就上锁。利用select xxx for update语句,伪代码如下所示:
事务A:
start transaction
//对user_id=1的记录上悲观锁
int b = select balance from T where user_id = 1 for update
b = b + 50
update T set balance = b where user_id = 1
commit事务B:
start transaction
//对user_id=1的记录上悲观锁
int b = select balance from T where user_id = 1 for update
b = b - 50
update T set balance = b where user_id = 1
commit悲观锁有潜在问题,假如事务A在拿到锁之后、Commit之前出问题了,会造成锁不能释放,数据库死锁。另外,一个事务拿到锁之后,其他访问该记录的事务都会被阻塞,这在高并发场景下会造成用户端的大量请求阻塞。为此,有了下面的乐观锁。
方法3:乐观锁
对于乐视锁,认为数据发生并发冲突的概率比较小,所以读之前不上锁。等到写回去的时候再判断数据是否被其他事务改了,即多线程里面经常会讲的CAS(Comapre And Set)的思路。下面来看一下,如何实现在数据库层面做CAS:如表6-6所示,给上面的表再加一列version字段。
表6-6 实现乐观锁的表结构
对应的伪代码如下所示:
事务A
while(!result) //CAS不成功,把数据重新读出来,修改之后,重新CAS
{
start transaction
int b, v1 = select balance, version from T where user_id = 1 ;
b = b + 50;
result = update T set balance = b, version = version + 1 where user_id = 1 and version = v1; //CAS
commit
} 事务B
while(!result)
{
start transaction
int b, v1 = select balance, version from T where user_id = 1 ;
b = b - 50;
result = update T set balance = b, version = version + 1 where user_id = 1 and version = v1; //CAS
commit
}CAS的核心思想是:数据读出来的时候有一个版本v1,然后在内存里面修改,当再写回去的时候,如果发现数据库中的版本不是v1(比v1大),说明在修改的期间内别的事务也在修改,则放弃更新,把数据重新读出来,重新计算逻辑,再重新写回去,如此不断地重试。
在实现层面,就是利用update语句的原子性实现了CAS,当且仅当version=v1时,才能把balance更新成功。在更新balance的同时,version也必须加1。version的比较、version的加1、balance的更新,这三件事情都是在一条update语句里面完成的,这是这个事情的关键所在!
当然,在实际场景中,不会让客户端无限循环地重试,可以重试三次,然后在操作界面上提示稍后再操作。
顺便介绍Java是如何利用CAS来做乐观锁的。下面是JDK6的JUC包里面,AtomicInteger的源代码:
public final int getAndIncrement() {
for (;;) { //失败,无限循环重试
int current = get(); //读取值
int next = current + 1; //修改值
if (compareAndSet(current, next)) return current; //CAS
}
}
public final int getAndDecrement() {
for (;;) {
int current = get();
int next = current - 1;
if (compareAndSet(current, next)) return current;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update); //调用native代码,实现一个CAS原子操作
} 方法4:分布式锁
乐观锁的方案可以很好地应对上述场景,但有一个限制是select和update的是同一张表的同一条记录,如果业务场景更加复杂,有类似下面的事务:
start_transaction
select xxx from T1
select xxx from T2
…根据T1和T2查询结果进行逻辑计算,然后更新T3
update T3
commit要实现update表T3的同时,表T1和表T2是锁住状态,不能让其他事务修改。在这种场景下,乐观锁也不能解决,需要分布式锁。当然,分布式锁也不是一个完善的方案,存在各种问题,后面会对其专门探讨。
6.4.3 死锁检测
上层应用开发会加各种锁,有些锁是隐式的,数据库会主动加;而有些锁是显式的,比如上文所说的悲观锁。因为开发使用的不当,数据库会发生死锁。所以,作为数据库,必须有机制检测出死锁,并解决死锁问题。
先以两个事务为例,看一下死锁发生的原理。
如图6-5所示:事务A持有锁1,事务B持有锁2,然后事务A请求锁2,但请求不到;事务B请求锁1,也请求不到。两个事务各拿一个锁,各请求对方的锁,互相等待,发生死锁。
图6-5 两个事务发生死锁示意图
把两个事务的场景扩展到多个事务,如图6-6所示。
图6-6 多个事务发生死锁的示意图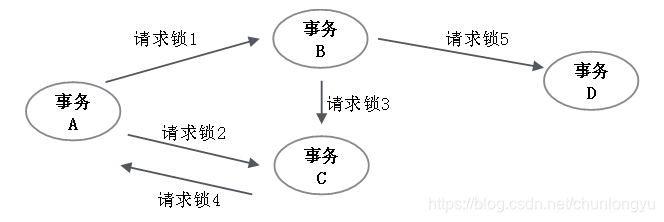
以事务为顶点,以事务请求的锁为边,构建一个有向图,这个图被称为Wait-for Graph。比如事务A要请求锁1、锁2,而锁1、锁2分别被事务B、事务C持有,因此事务A依赖事务B、事务C;事务B要请求锁3,而锁3被事务C持有,所以事务B依赖事务C;事务C要请求锁4,而锁4被事务A持有,所以事务C依赖事务A;依此类推。
死锁检测就是发现这种有向图中存在的环,本图中就是事务A、事务B、事务C之间出现了环,所以发生了死锁。关于如何判断一个有向图是否存在环属于图论中的基本问题,存在多种算法,此处不展开讨论。
检测到死锁后,数据库可以强制让其中某个事务回滚,释放掉锁,把环断开,死锁就解除了。
具体到MySQL,开发者可以通过日志或者命令查看当前数据库是否发生了死锁现象。遇到这种问题,需要排查代码,分析死锁发生的原因,定位到具体的SQL语句,然后解决。死锁发生的场景非常的多,与代码有关,也与事务隔离级别有关,只能根据具体问题分析SQL语句解决。下面随便列举两个死锁发生的场景。
场景1:如表6-7所示,事务A操作了表T1、T2的两条记录,事务B也操作了表T1、T2中同样的两条记录,顺序刚好反过来,可能发生死锁。
表6-7 死锁发生场景1
场景2:如表6-8所示,同一张表,在第三个隔离级别(RR)下,insert操作会增加Gap锁,可能导致两个事务死锁。这个比较隐晦,不容易看出来。
表6-8 死锁发生场景2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号