容器基础复习之Map
Map复习笔记
翻到了大学时候做的笔记,迁移到博客园上来,方便查看,温故而知新
写在前面
现在也大四了,到了找实习的时候,做准备时复习到了Map,之前学习的不够深入,现在整理回顾一下Map的知识内容,加深了解。本文主要复习了HashMap和LinkedHashMap。
先丢一张图
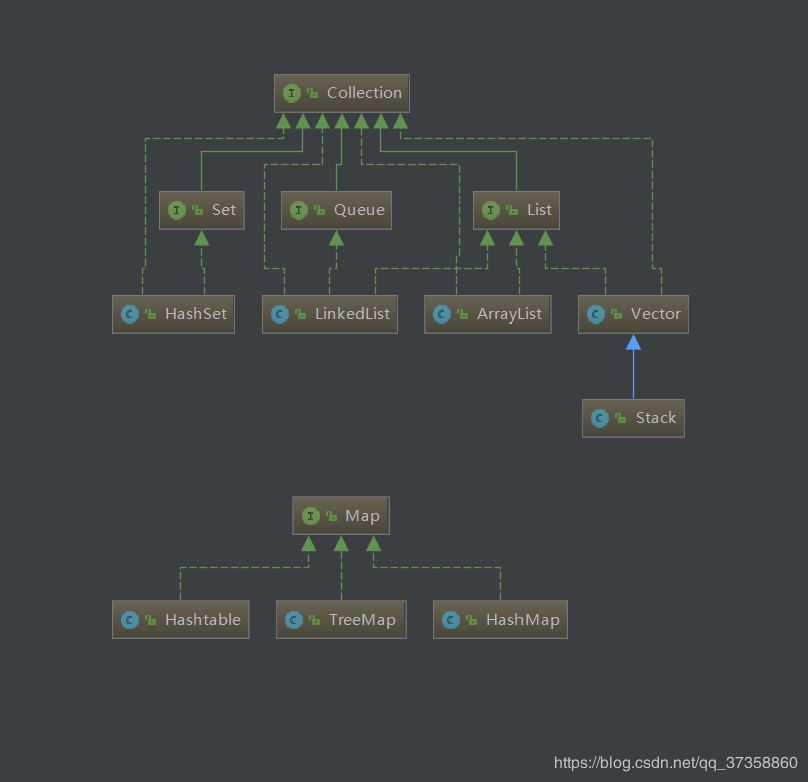
概述
Map(映射),Map是以键值对存储数据的,将键映射到值的对象。
一个映射不能包含重复的键,每个键最多能映射到一个值
值可以重复,并且值的对象还可以是Map类型,就像数组中元素还可以是数组一
Map的主要实现类有HashMap、HashTable、TreeMap、ConcurrentHashMap、LinkedHashMap等等。
一些异常
- 当访问的值不存在的时候,方法就会抛出一个NoSuchElementException异常.
- 当对象的类型和Map里元素类型不兼容的时候,就会抛出一个 ClassCastException异常。
- 当在不允许使用Null对象的Map中使用Null对象,会抛出一个NullPointerException 异常。
- 当尝试修改一个只读的Map时,会抛出一个UnsupportedOperationException异常。
1)HashMap
关于哈希
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
关于散列表:
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
特点
- HashMap长度是可变的
- HashMap没有顺序,随着HashMap中的键值对越来越多的时候,打印的顺序也也是会发生变化的.
- HashMap中的key值是不可重复的,value值是可以重复的
- 线程不安全
- 特点:键值对
- 存储结构: 这里是重点,HashMap中的数据存储结构在容器中是相对复杂的,HashMap的存储结构是 数组+单向链表+红黑树 并且是基于散列算法,保证了性能.
存储结构
众所周知,HashMap底层是以 数组+链表 实现的,1.8之后引入红黑树,结构会稍有不同

我们看到table属性就是一个数组,存储的是Node类型的值.
Node是HashMap的一个内部类.包括一个final修饰int类型的hash属性,一个final 修饰的泛型key, 一个泛型 value,最后一个还是Node类型 的 next ,通过最后一个 属性,我们可以猜测到,这是一个单向链表结构.
put方法
当我们执行 map.put(“XX”, XX); 之后,我们会发现table中已经有值,在下标为XX的位置有了一个Node,这个Node中的key和value就是我们put进去的key和value.
有没有考虑数组下标是怎么来的呢,我们可以进一步看HashMap中put的源码.

put方法中返回了一个putVal(),还有键值;其中putVal方法返回一个hash(key),可以进hash()方法查看源码

hash()就是根据push进去的key值,判断是否为空,是则返回0,不是测调用key的hashCode()方法,计算出一个hashCode码,并返回hashCode码的高十六位和低十六位按位异或运算得到的结果,返回结果是int类型
putVal()方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}

第一个判断,判断table是否为空或者tab长度为0,则resize()方法重新赋值。

第二个判断
第一个 执行的是 (n-1) 得到的结果是15
table的初始长度是16,此时我们先把n当做16,为了保证我们的思路能够清晰,这里先不看别的方法.
第二个 执行的是 i = (n - 1) & hash 也就是15 与一个 int 类型的整数进行 按位与 运算的结果赋值给 变量 i
i 代表的是tab这个数组也可以说是table这个数组中的下标,那么这个下标是怎么来的呢? 首先说 n 代表的是数组的长度,那么当n等于16的时候,最大最大下标的位置就是 15 ,也就是说只有 0-15 之间的数可以做这个数组的下标 到这里,也就是说我想给 i 这个变量赋值一个0-15之间的下标, 然后通过这个下标去数组中取值 给 变量 p 赋值. 我们考虑一下这个 i 下标需要满足什么特性? a. i >= 0 && i <= 15 b. 我下次再put值的时候, 这个i的值应该是相同的. 我们看下HashMap是怎么实现的. (n - 1) & hash a. 现在已知 n-1 = 15 , hash是一个int整数 ,我们来进行按位与运算
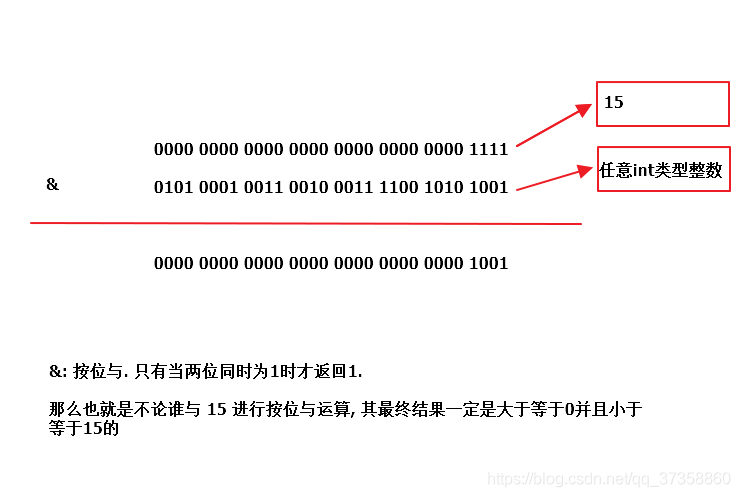
b.怎么保证 i 下次再计算的时候 i 的值是不变的 , 这个时候我们就需要看这个这两个运算数是怎么来的, 15 根据数组长度来的,只要数组长度不变,这个就绝对不会变(如果数组长度改变的话,涉及到扩容,存储的位置也可能发生变化),另外一个hash变量是跟你你传入的key的hashCode()方法返回的hashCode码得来的,java中同一个对象多次调用hashCode()方法返回的值是相同的,除非你重新了hashCode()方法.
第三个 执行的就是(p = tab[i = (n - 1) & hash]) 相当于p = tab[i] ,在数组中取值,然后赋值给 p . 第四个 执行的就是 if ((p = tab[i = (n - 1) & hash]) == null); 也就是最终判断 p == null
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
if条件如果为true会执行什么,然后在看条件判断这部分.
先看tab[i] = newNode(hash, key, value, null); 这行代码我感觉挺简单的,之前将HashMap中的table赋值给了tab,并且做了一些处理之后才赋值的,确保table不为null,长度大于0.那么tab就是一个Node类型的数组,这里就是根据你传给putVal方法的值创建了一个Node对象,然后赋值给tab[i]这个位置.
ok,这个时候我们可以继续看上面的条件什么时候为true了,(i的这个值,也是在条件判断的时候赋值的) if ((p = tab[i = (n - 1) & hash]) == null); 先看这行代码中的几个属性: p 是Node类型的对象, 但是没有初始化 tab 就是table赋值过来的Node类型的数组 n 就是table的length
整个if大致流程图为
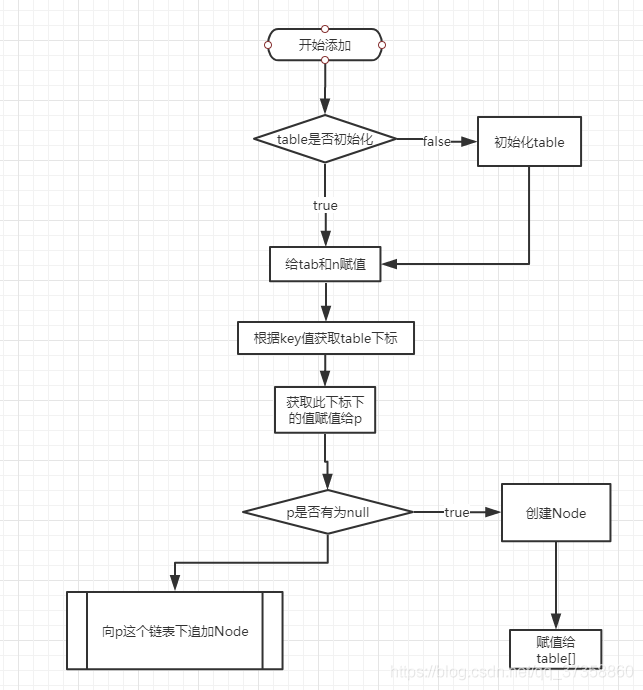
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
判断当前要保存的key值是否跟当前位置的key值相同
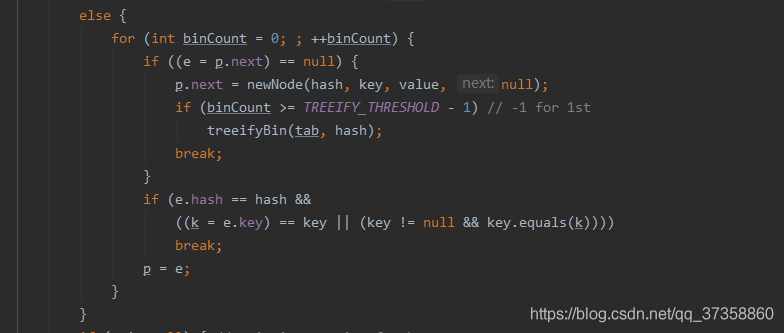
遍历这个链表下的所有的所有节点,依次判断key值是否是当前要添加的key,如果是的话就直接改变这个node就ok了,如果不是的话就看看这个node指向的下一个node是否为null,如果是null,就创建一个Node赋值给当前这个Node的next属性就ok了,赋值完之后还要判断一下当前数组位置下的链表的长度.
2)LinkedHashMap
特点
LinkedHashMap是有序的,且默认为插入顺序。
跟HashMap一样,它也是提供了key-value的存储方式,并提供了put和get方法来进行数据存取。
LinkedHashMap继承了HashMap,所以它们有很多相似的地方。 其中最大的不同在于entry的定义上
区别

LinkedHashMap中的entry多出了一个before和after,这维护了entry的上一个元素和下一个元素,这样下来,
LinkedHashMap的每个节点,就包含了6个属性:
hash:HashMap的键的hashcode,LinkedHashMap的键的hashcode。
key:该节点的键。
value:该节点的值。
next:单链表指针,HashMap专用。
before:双链表指针,LinkedHashMap专用。
after:双链表指针,LinkedHashMap专用。
LinkedHashMap结构图
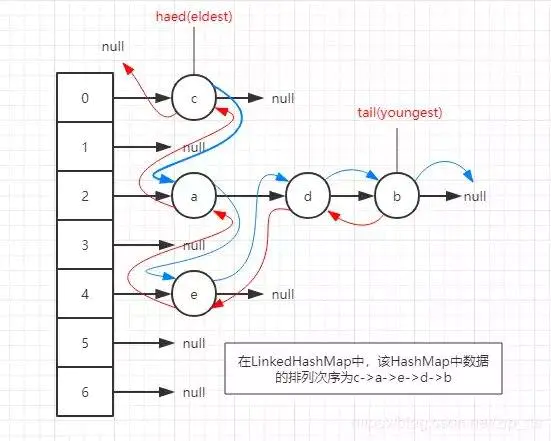
总结
- HashMap中的table的默认大小是16
- HashMap的长度达到table.length乘以0.75(负载因子)的值的时候就需要扩容了
- 扩容是扩容2倍,(一定是2n)
resize()功能是初始化和扩容.
扩容后的数据转存三种情况 1.table[]数组中的这个位置不为null,且next下为null,直接重新添加 2.table[]数组中的这个位置不为null,且next下不为null,类型是红黑树,打散重新添加 3.table[]数组中的这个位置不为null,且next下不为null,类型是链表,重新计算位置. 计算位置方式,只有两种可能,一种是原来的位置,另一种是原来的位置+原来数组的长度. 用hash码与原来数组长度进行&运算结果为0就是原来的位置.不为0就是原来的位置加上原来数组长度的位置.
思考:HashMap的单向链表有next指针,为什么不能保证有序?
答:因为单向链表只是发生hash碰撞时,存储具有多个相同hash值的数据结构。也就是说,只是桶内有序。但是HashMap的table数组是无序的,这个是按照哈希值来定位数组中的位置,并不是按照插入顺序排序的。
不过,从这点来看,HashMap也是“有序”的,只不过这里的“有序”不是插入时的顺序。
后记
大部分转自https://blog.csdn.net/qq_37358860/article/details/100539941
一步一步学习,作者讲得很详细深入,值得大家去学习和重温。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号