CuPy:将 NumPy 数组调度到 GPU 上运行
楔子
提到 Python 的科学计算,必然离不开 NumPy 这个库,但 NumPy 在设计之初没有考虑对 GPU 的支持。正如 NumPy 的作者 Travis Oliphant 所说,如果当时给 NumPy 添加了 GPU 的支持,就没有后来的 Tensorflow、Torch 等深度学习框架什么事了。但世间没有如果,当时的 NumPy 也不具备支持 GPU 的条件,不过时代已经变了,现在有 CuPy 了。
相信你已经知道 CuPy 是干什么的了,它和 NumPy 一样,都是用来创建数组(矩阵),然后对其进行运算的。但 NumPy 是通过 CPU 来计算的,而 CuPy 通过 GPU 来计算,并且是并行计算。最重要的是,CuPy 和 NumPy 提供的函数基本是一致的,毕竟 CuPy 就是为了让 NumPy 支持 GPU 而设计的。
import numpy as np
import cupy as cp
之前使用 np.xxx(),现在只需要将 np 换成 cp 即可,即 cp.xxx()。当然 Cupy 尚未完全支持 Numpy 的全部功能,但大部分常用的都支持。
然后还需要说明的是,CuPy 虽然在大型、高维数组/矩阵的计算方面非常非常快,但它在计算之前会涉及 GPU 的初始化,这个过程是需要时间的。因此当你决定使用 CuPy 时,要确保数组的维度和尺寸一定要足够大,不然还不如用 NumPy。然后要避免 CPU 和 GPU 混合编程,因为数据在 CPU 和 GPU 之间传递等操作非常耗时,比如一会儿 CPU 计算,一会儿 GPU 计算,那么此时用 Cupy 反而会降低效率。
好,下面就来学习 CuPy,我们会通过复习 NumPy 的语法,然后用 CuPy 进行演示,并在某些时候对比两者的性能差异。不过在学习之前,我们还有一个重要的事情没有做,就是安装 CuPy。
首先你要去 https://developer.nvidia.cn/cuda-downloads 下载 CUDA 工具包,我这里下载的是最新版 12.2,操作系统是 Windows。

安装包大小是 3 个 G,下载完毕之后直接双击安装即可。但是注意:在安装的时候,要确保你的主机已经配备了 NVIDIA 显卡,无论是新款的 40 系,还是以前的 30 系、20 系等等都是可以的,我当前是 GTX4080。安装完之后,你的 C 盘应该会有这个目录:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2。
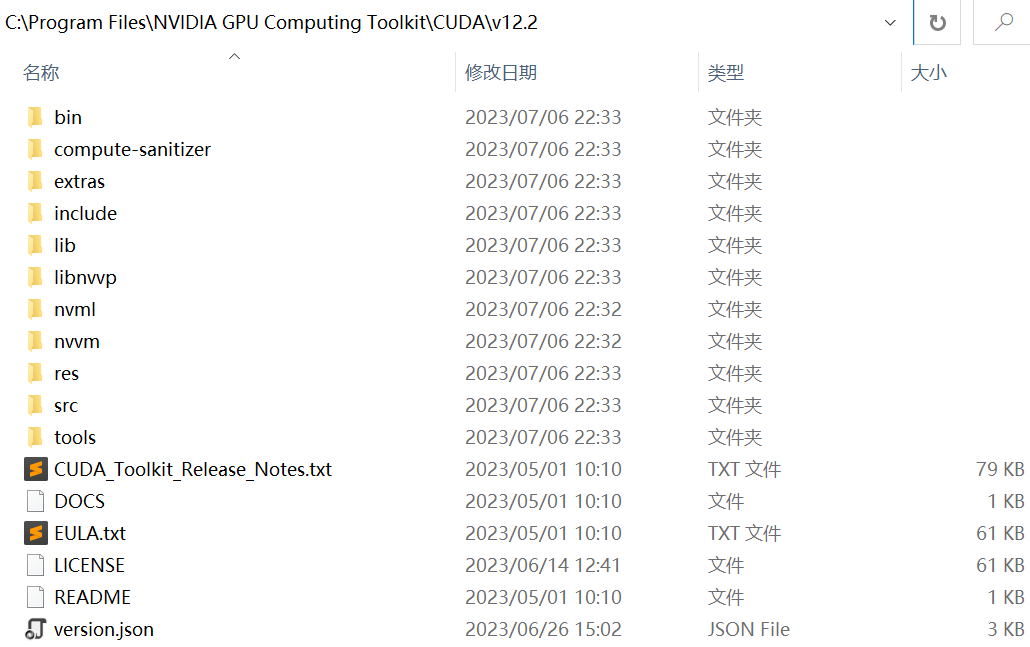
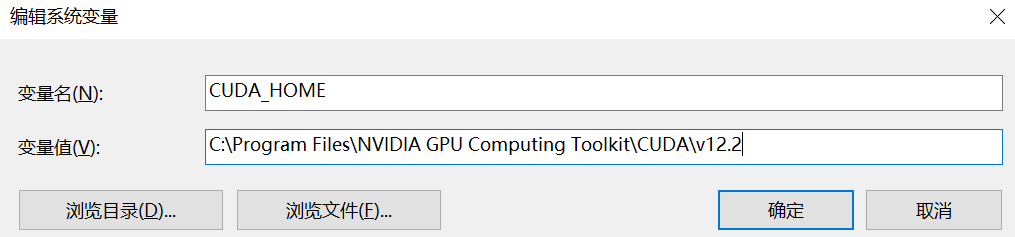
由于我安装的 CUDA 工具包是 12.2 版本,所以路径的最后一个子目录是 v12.2,如果安装的是其它版本,比如 11.0,那么目录就是 v11.0。然后我们该路径设置成环境变量,变量名称为 CUDA_HOME。
到此我们的准备工作就算完成了,然后正式安装 CuPy,而安装有两种方式。第一种是 pip install cupy,该方式安装的 CuPy 不依赖特定的 CUDA 版本,属于通用 CuPy。第二种是安装针对特定 CUDA 版本的 CuPy,我当前采用的是第二种。

我安装的 CUDA 版本是 12.2,所以安装命令式 pip install cupy-cuda12x。然后测试一下能不能用:
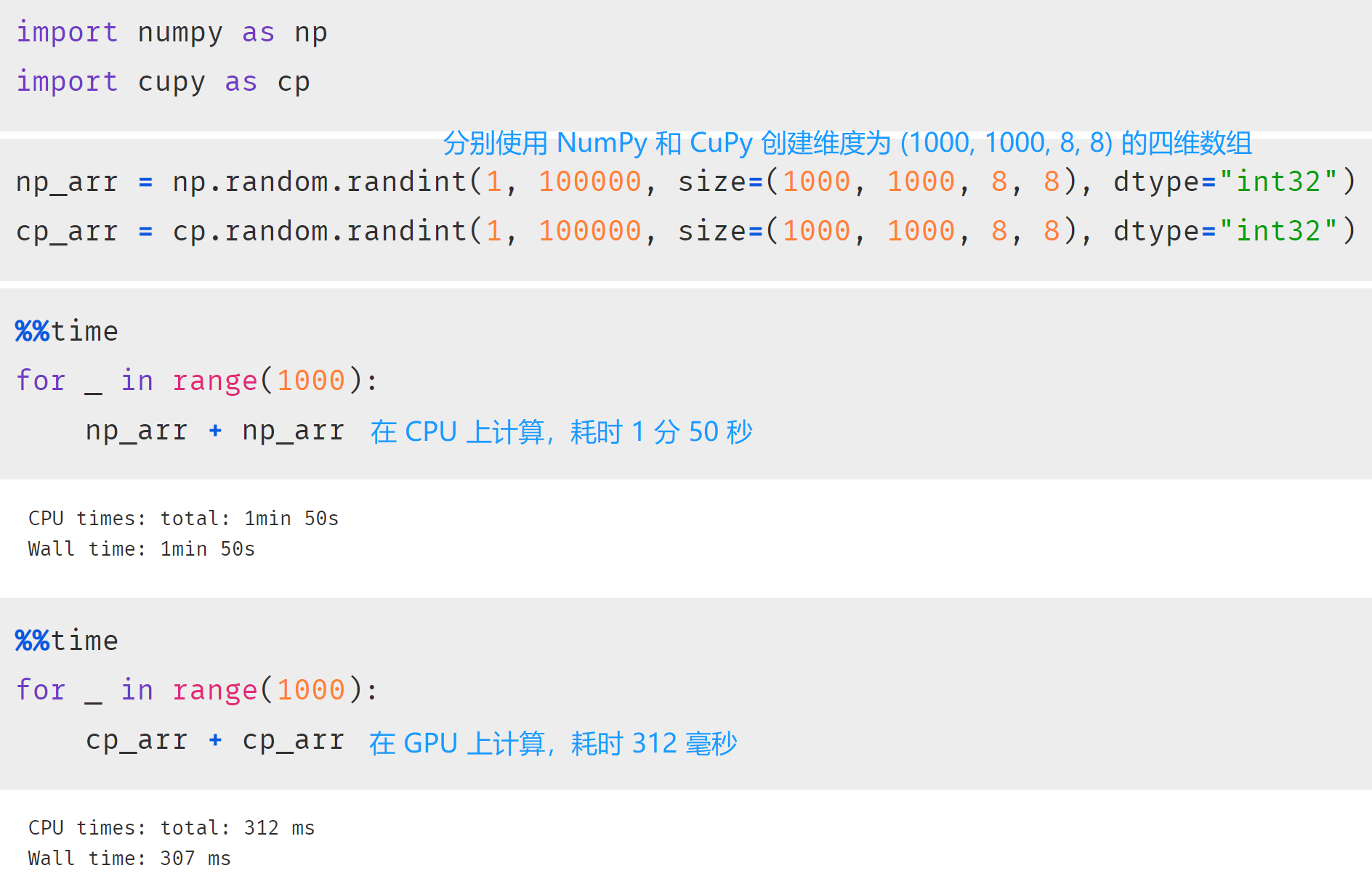
程序正常执行,说明 CuPy 安装成功,而且我们看到两者之间的计算速度真的是天壤之别,使用 GPU 快的太多了。
下面就来正式开始学习 CuPy,事实上熟悉 NumPy 的话,那么 CuPy 根本不需要专门去学,因此这里就当复习语法了。
数组的基础知识
NumPy 和 CuPy 都提供了同构多维数组(ndarray 对象),并基于数组构建了大量的相关操作。
import numpy as np
import cupy as cp
print(np.array([]).__class__)
print(cp.array([]).__class__)
"""
<class 'numpy.ndarray'>
<class 'cupy.ndarray'>
"""
调用 array 方法,传递一个列表,即可创建一个数组(ndarray 对象),后续都是围绕着数组进行操作。在创建数组的时候,还可以指定其它参数。
1)dtype:数组元素的类型
import numpy as np
import cupy as cp
# 比如 cp.int8、cp.int16、cp.int32、cp.int64
# cp.uint8、cp.uint16、cp.uint32、cp.uint64
# cp.float16、cp.float32、cp.float64、cp.complex64、cp.complex128
print(cupy.array([1, 2, 256, 257], dtype=cp.int8))
"""
[1 2 0 1]
"""
# int8 能表示的最大整数为 255,因此 256 会被环绕成 0,257 被环绕成 1
# 换成 int32,由于元素都是整数,所以默认是 int32
print(cupy.array([1, 2, 256, 257], dtype=cp.int32))
"""
[1 2 256 257]
"""
# 换成 float32
print(cupy.array([1, 2, 256, 257], dtype=cp.float32))
"""
[1. 2. 256. 257.]
"""
# 元素是浮点数,所以默认是 float64
print(cupy.array([3.14, 2.71, 1.414]))
"""
[3.14 2.71 1.414]
"""
# 如果此时将类型指定为整型,那么小数部分会发生截断
print(cupy.array([3.14, 2.71, 1.414], dtype=cp.int32))
"""
[3 2 1]
"""
至于 NumPy 就不演示了,两者的 API 是一致的,并且 CuPy 里面的 int32、float64 等类型也是 NumPy 里面导入的。然后在指定 dtype 的时候,也可以使用字符串,比如 "int32"、"float16",这样也是可以的。
2)copy:是否返回一个新的数组
创建数组时,除了传递一个列表,也可以传递数组本身。在传递数组的时候,如果 copy 参数为 True,那么会创建一个新数组(默认行为),否则直接返回已有数组。
import numpy as np
import cupy as cp
np_arr1 = np.array([1, 2, 3])
np_arr2 = np.array(np_arr1)
# np_arr1 本身就是数组,然后 copy=False,所以直接返回 np_arr1
np_arr3 = np.array(np_arr1, copy=False)
print(np_arr1 is np_arr2) # False
print(np_arr1 is np_arr3) # True
cp_arr1 = cp.array([1, 2, 3])
cp_arr2 = cp.array(cp_arr1)
cp_arr3 = cp.array(cp_arr1, copy=False)
print(cp_arr1 is cp_arr2) # False
print(cp_arr1 is cp_arr3) # True
但如果你传入的不是数组,而是列表,那么无论 copy 是 True 还是 False,都会创建新数组。
3)order:连续方式
数组有两种连续方式,一种是 C 连续,一种是 Fortran 连续。
import numpy as np
import cupy as cp
# order 为 "C" 表示 C 连续,"F" 表示 Fortran 连续,默认 C 连续
np_arr = np.array([1, 2, 3], order="F")
cp_arr = cp.array([1, 2, 3], order="F")
多补充一点,Python 提供了一个缓冲区协议,而实现了缓冲区协议的对象(即使是不同类型)可以共享内存。而在 CPython 的源码中有一个结构体叫 Py_buffer,它内部有一个指针 void *buf,指向了缓冲区(存储具体的数据)。所有实现缓冲区协议的对象,一律通过 Py_buffer 来操作缓冲区,从而屏蔽不同类型之间的差异。而两个对象能够共享内存,那么它们的 Py_buffer 内部的指针 buf,一定指向了同一个缓冲区。
那么返回的数组都有哪些属性呢?
import cupy as cp
arr = cp.array([[1, 2, 3], [4, 5, 6]])
print(arr)
"""
[[1 2 3]
[4 5 6]]
"""
# ndim:数组的维度个数(也被称为 rank)
print(arr.ndim)
"""
2
"""
# shape:数组的形状,比如 n 行和 m 列的矩阵,shape 就是 (n, m)
# 因此 shape 元组的长度就是 rank 或维度的个数 ndim
print(arr.shape)
"""
(2, 3)
"""
# size:元素的总个数,等于 shape 里面每个元素的乘积
print(arr.size)
"""
6
"""
# dtype:数组元素的类型,返回的是 np.int32 或者 cp.int32,而不是字符串 "int32"
print(arr.dtype)
"""
int32
"""
# itemsize:数组中每个元素的大小,这个大小显然是由元素类型决定的
# 因此 arr.itemsize 等价于 arr.dtype.itemsize
print(arr.itemsize, arr.dtype.itemsize)
"""
4 4
"""
# data:缓冲区包含的实际元素, 通常不需要使用此属性,因为通过索引来访问会更方便
print(arr.data)
"""
<MemoryPointer 0xb10000000 device=0 mem=<cupy.cuda.memory.PooledMemory object at 0x00...>>
"""
# flags:数组的内存信息
print(arr.flags)
"""
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
"""
# C_CONTIGUOUS:是否是 C 连续,F_CONTIGUOUS:是否是 Fortran 连续
# OWNDATA:实现了缓冲区协议的对象,会对应一个缓冲区,该字段表示缓冲区是否属于该对象
arr2 = arr[:]
print(arr2.flags["OWNDATA"]) # False
# 基于切片会创建一个新数组,而切片操作显然不应该拷贝数据,会影响性能
# 但实际的数组都存储在缓冲区里面,因此这两个数组会共用一个缓冲区
# 在创建 arr2 的时候,只是新建了一个 Py_buffer,但指针指向的缓冲区并没有拷贝
# 但缓冲区属于谁呢?显然是 arr,因为它是伴随着 arr 创建的,而不是 arr2
关于缓冲区的更多细节,后续还会补充。
创建数组的其它方式
创建数组的时候,我们希望元素是类似 1 2 3 4 5 .... n 这样的一段连续数字,这时可以使用 arange 创建。
import numpy as np
import cupy as cp
np_arr = np.arange(1, 10)
cp_arr = cp.arange(1, 10)
print(np_arr) # [1 2 3 4 5 6 7 8 9]
print(cp_arr) # [1 2 3 4 5 6 7 8 9]
# 前三个参数分别是 start、stop、step,和 Python 的 range 是类似的
# 第四个参数是 dtype,负责表示类型
np_arr = np.arange(1, 10, 2)
cp_arr = cp.arange(1, 10, 2)
print(np_arr) # [1 3 5 7 9]
print(cp_arr) # [1 3 5 7 9]
np_arr = np.arange(1, 10, 2, dtype="float64")
cp_arr = cp.arange(1, 10, 2, dtype="float64")
print(np_arr) # [1. 3. 5. 7. 9.]
print(cp_arr) # [1. 3. 5. 7. 9.]
# 步长也可以是小数,但 range 的步长必须是整数
np_arr = np.arange(1, 10, 1.8)
cp_arr = cp.arange(1, 10, 1.8)
print(np_arr) # [1. 2.8 4.6 6.4 8.2]
print(cp_arr) # [1. 2.8 4.6 6.4 8.2]
如果我们希望创建具有指定形状的数组,该怎么做呢?
import numpy as np
import cupy as cp
# 创建具有指定形状的数组,并将元素全部初始化为 1
# 第一个参数为 shape,表示数组的形状,比如这里创建 shape 为 (2, 2, 2) 的数组
# 第二个参数 dtype 默认是 float,第三个参数 order 默认是 "C",即 C 连续
print(np.ones((2, 2, 2), dtype="float64", order="C"))
"""
[[[1. 1.]
[1. 1.]]
[[1. 1.]
[1. 1.]]]
"""
print(cp.ones((2, 2, 2), dtype="float64", order="C"))
"""
[[[1. 1.]
[1. 1.]]
[[1. 1.]
[1. 1.]]]
"""
# 如果你希望里面的元素不是 1,比如希望是 9,要怎么做呢?
print(cp.ones((2, 2, 2)) * 9)
"""
[[[9. 9.]
[9. 9.]]
[[9. 9.]
[9. 9.]]]
"""
除了 ones 还有 zeros,两者用法一样,不过 zeros 是将元素初始化为 0。然后还有一个 empty,用法也是一样的,但根据 dtype 的不同,会有些许变化。
import cupy as cp
print(cp.empty((2, 2), dtype="int32"))
"""
[[0 0]
[0 0]]
"""
print(cp.empty((2, 2), dtype="float64"))
"""
[[0. 0.]
[0. 0.]]
"""
print(cp.empty((2, 2), dtype="unicode"))
"""
[['' '']
['' '']]
"""
# 如果将 dtype 指定为 "O",那么表示元素的类型为 object
# 此时会将元素初始化为 None,并且 dtype 为 "O" 时,数组里面存储的就是对象的引用
print(cp.empty((2, 2), dtype="O"))
"""
[[None None]
[None None]]
"""
然后你也可以给出数组的起始元素和终止元素,并将其按照指定大小等分,比如:
import cupy as cp
# 将 1 ~ 10 等分成 5 份(默认是 50 份)
print(cp.linspace(1, 10, 5))
"""
[1. 3.25 5.5 7.75 10.]
"""
# 将 1 ~ 10 等分成 6 份
print(cp.linspace(1, 10, 6))
"""
[ 1. 2.8 4.6 6.4 8.2 10.]
"""
# 默认包含终止位置(比如这里的 10),如果不想包含,那么将 endpoint 指定为 False
print(cp.linspace(1, 10, 5, endpoint=False, dtype="float32"))
"""
[1. 2.8 4.6 6.4 8.2]
"""
创建数组的时候也可以将元素都初始化为随机数,比如:
import cupy as cp
# 创建形状为 (3, 4)、元素为 1 到 9 的数组
arr = cp.random.randint(1, 10, size=(3, 4))
print(arr)
"""
[[3 9 2 6]
[9 2 7 5]
[7 8 4 7]]
"""
# 创建形状为 (3, 4)、元素为 0 到 1 的数组
arr = cp.random.random((3, 4))
print(arr)
"""
[[0.6022529 0.55502925 0.46847286 0.36882837]
[0.43470827 0.20144734 0.35096298 0.93200072]
[0.61387078 0.90212744 0.94287527 0.07541207]]
"""
# 创建形状为 (3, 4)、元素为 1 到 9 的数组,但元素是浮点数
arr = cp.random.uniform(1, 10, size=(3, 4))
print(arr)
"""
[[8.19099449 6.43776048 8.64009843 7.31526072]
[7.05237259 6.88452832 6.34699105 6.73653786]
[5.45949242 2.54578101 1.33799185 5.34975854]]
"""
# 按照正态分布创建形状为 (3, 4) 的数组,均值为 1、标准差为 0.5
arr = cp.random.normal(1, 0.5, size=(3, 4))
print(arr)
"""
[[0.10983038 0.34493599 1.28167303 0.77545233]
[1.08171111 0.58458639 2.03343729 1.13864053]
[1.89585321 1.48647556 0.17346172 1.54502525]]
"""
以上就是创建的数组的几种常见方式,对于日常工作来说应该是足够了。
基本操作
数组执行算术运算,会作用在元素级别。
import cupy as cp
# 如果要给列表的每个元素加 1,要怎么做呢?
lst = [10, 20, 30]
print([item + 1 for item in lst])
"""
[11, 21, 31]
"""
# 但数组则不一样,它的运算操作会作用在每个元素身上
arr = cp.array([10, 20, 30])
print(arr + 1)
"""
[11 21 31]
"""
# 加减乘除、取模、位运算、比较运算等等,都是一样的
print(arr << 1)
"""
[20 40 60]
"""
arr = cp.arange(1, 10)
print(arr)
"""
[1 2 3 4 5 6 7 8 9]
"""
print(arr >= 5)
"""
[False False False False True True True True True]
"""
print(arr % 2 == 0)
"""
[False True False True False True False True False]
"""
# 两个数组也可以进行运算,会对每个元素进行运算,此时要求两个数组的形状是一样的
A = cp.array([11, 22, 33])
B = cp.array([44, 55, 66])
print(A + B)
"""
[55 77 99]
"""
# 加减乘除、取模、位运算、比较运算也是一样的,都是基于对应元素进行操作
# 在 NumPy 和 CuPy 中,数组也可以理解为矩阵
A = cp.array([[1, 2], [3, 4]])
B = cp.array([[5, 6], [7, 8]])
# 此时是两个数组的对应元素相乘
print(A * B)
"""
[[ 5 12]
[21 32]]
"""
# 如果希望实现矩阵乘法,那么使用 @
print(A @ B)
"""
[[19 22]
[43 50]]
"""
还是比较简单的,然后是类型,如果类型不同,那么会向上扩展。比如整型数组和一个浮点数相加,那么得到的数组的 dtype 就是 float。
通用函数
CuPy 也提供了很多的通用函数,你能想到的基本都有,下面我们来介绍一些常用的。
未完待续
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号