使用"不安全编程"帮你绕过 Go 语言中的类型检测系统
楔子
不安全编程?用 Go 语言的时候也没发现有啥不安全的啊,而且 Go 里面有垃圾回收,也不需要我们来管理内存。当听到不安全编程这几个字,唯一能想到的也就是指针了,只有指针才可能导致不安全问题。我们知道 Go 是有指针的,但是 Go 的指针并不像 C 语言中的指针一样可以进行运算,因此在提供了指针的便利性的同时,又保证了安全。
先来聊一聊 Go 的指针。
指针
只要将数据存储在内存中都会为其分配内存地址,内存地址使用十六进数据表示,可以使用 & 获取其地址。
package main
import "fmt"
func main() {
var i int = 10
// 使用 %p 打印变量的内存地址
fmt.Printf("%p\n", &i) //0xc0000a0068
// Go 的变量如果没有赋初始值, 那么默认有一个零值, 所以已经分配好内存了
// 既然分配好内存了, 那么就一定有地址
var j int
fmt.Printf("%p\n", &j) //0xc0000a00a0
}
如果想将获取的地址进行保存,应该怎样做呢?可以通过指针变量来存储,所谓的指针变量:就是用来存储一个值的内存地址。
package main
import "fmt"
func main() {
var a = "hello"
//格式: var 指针变量名 *类型 = &变量
//不过在声明变量的时候, 如果赋了初始值, 则可以省略类型
//这里就将 a 的地址赋值给指针变量 p1 和 p2, 指针变量也是变量, 只不过它保存的是地址
var p1 *string = &a
var p2 = &a
// p1 和 p2 是同一个变量的地址, 所以它们的值是一样的
fmt.Println(p1, p2) // 0xc0000441f0 0xc0000441f0
//有了指针变量, 那么通过 *指针变量 即可操作指向的内存
fmt.Println(*p1) // hello
//将 p1 指向的值修改之后, p2 指向的值、以及 a 本身都会改变, 因为它们都是同一份内存
*p1 = "world"
fmt.Println(*p2, a) // world world
}
此外还有很重要的一点,那就是 Go 的变量传递统统都是值传递,Go 里面没有所谓的引用传递。无论是传递值,还是传递指针,都是值传递(即拷贝一份出来)。
package main
import "fmt"
func main() {
var a = 123
var b = a
// b = a 表示将 a 的值拷贝一份给 b, 所以这两个变量的地址是不一样的
fmt.Printf("%p %p\n", &a, &b) // 0xc0000a0068 0xc0000a0080
var c = 456
var p1 = &c
var p2 = p1
//因为将 p1 赋值给了 p2, 所以这两个指针变量的值是一样的, 因为存储的都是变量 c 的地址
//但我们说了, Go 变量的传递都是值传递, 也就是要拷贝一份出来
//所以 p1 和 p2 存储的值一样, 表示它们存储的地址是一样的, 修改 *p1 会影响 *p2, 修改 *p2 会影响 *p1, 因为都指向同一份内存
//但是这两个指针变量本身的地址是不一样的, 指针变量也是有地址的
fmt.Printf("%p %p\n", &p1, &p2) // 0xc000006030 0xc000006038
//此时修改 p1, 不会影响 p2; 修改 p2 不会影响 p1, 因为它们是两个不同的变量, 只是存储的值(地址)一样, 而其本身的地址不一样
}
注意:还有很重要的一点,指针变量如果不赋初始值的话,那么它就是一个空指针,也就是 nil。
package main
import (
"fmt"
)
func main() {
var p1 *int
var p2 *int
//空指针也是有地址的, 它已经分配好了内存, 因为指针也是有零值的, 而 nil 就是指针的零值
//打印布尔值用 %t, 可以看到这两个指针是一样的, 虽然地址不一样, 但是存储的值一样都是 nil
fmt.Printf("%p %p %t\n", &p1, &p2, p1 == p2) // 0xc000006028 0xc000006030 true
fmt.Println(p1, p2) // <nil> <nil>
//另外空指针的话, 你不能操作其指向的内存, 这是不允许的, 因为空指针没有指向一块合法的内存
//所以虽然这个指针本身被分配了内存, 但是指针指向的内存并没有分配, 所以需要给指针赋一个初始值才可以
//给指针赋值, 一定要通过取变量地址的方式赋值, 直接 var p *int = 0xF000006060 这种方式是不允许的
}
所以指针变量需要指向一个具体的普通变量,但是除了创建一个变量并取其 & 符的方式之外,还可以使用 new 函数。
package main
import (
"fmt"
)
func main() {
//new 函数里面接收一个类型, 会自动创建一个该类型的零值(相当于分配内存), 然后返回其指针
var p1 = new(int)
fmt.Println(*p1) // 0
//所以 p1 这个指针变量不是空指针 nil, 它是有具体指向的
*p1 = 123
fmt.Println(*p1) // 123
//上面就等价于:
var i int
var p2 = &i
fmt.Println(*p2) // 0
//只不过此时我们知道 p2 这个指针变量指向谁, 修改其中一个都会影响另一个, 因为都是同一份内存
i = 1
fmt.Println(*p2, i) // 1 1
*p2 = 2
fmt.Println(*p2, i) // 2 2
}
因此 new 函数就方便很多,会动态分配空间,而且我们不需要关心空间释放,Go 编译器会自动帮我们做到这一点。
既然说起指针,我们很容易想到 C,都说指针是 C 语言的灵魂,不会指针说明你不懂 C,那么在 Go 中是不是这样呢?答案不是的,虽然 Go 的指针也很重要,但没有 C 的指针那么强大。不过能够获取一个变量的地址,并且能通过地址来改变存储的值,我个人觉得已经足够了。因为 Go 是一个高级语言,它要保证安全性,而指针是很危险的,像其它语言在语法层面上都摒弃指针了。
所以一句话:Go 里面有指针,但是相较于 C,Go 的指针被限制了许多,因此既提供了指针的便利性,又保证了安全。那么它都进行了哪些限制呢?
限制一:Go 的指针不能进行数学运算限制二:Go 不同类型的指针不能进行转化或者赋值限制三:Go 不同类型的指针不能进行比较
但是在 Go 里面,可以通过一个叫做 unsafe 的包让指针突破限制,从而进行运算,可一旦用不好就会导致很严重的问题,所以说这是不安全编程。但即便如此我们还是可以使用的,因为用好了在某些场景下能够带来很大的便利,而且 Go 的内部也在大量的使用 unsafe 这个包。
unsafe:不安全编程
我们知道 Go 的指针实际上是类型安全的,因为 Go 编译器对类型的检测十分严格,让你在享受指针带来的便利时,又给指针施加了很多制约来保证安全。但保证安全是需要以牺牲效率为代价的,如果你能保证写出的程序就是安全的,那么你可以使用 Go 的不安全指针,从而绕过类型系统的检测,让你的程序运行的更快。
如果是一个高阶 Go 程序员的话,怎么能不会 unsafe 包呢?它可以绕过 Go 的类型系统的检测,直接访问内存,增加效率。Go 的很多限制,比如不能操作结构体的未导出成员等等,在有了 unsafe 包之后,都可以被打破。所以这个包叫做 unsafe,我们称使用 unsafe 为不安全编程,因为它很危险,官方也不推荐使用,估计正因为如此才设计了这么个名字吧。但是底层都在大量使用,那我们为什么不能用。
package unsafe
type ArbitraryType int
type Pointer *ArbitraryType
func Sizeof(x ArbitraryType) uintptr
func Offsetof(x ArbitraryType) uintptr
func Alignof(x ArbitraryType) uintptr
unsafe 包下面只有一个 unsafe.go 文件,这个文件里面把注释去掉就上面 6 行代码,是的你没有看错。当然功能肯定都内嵌在编译器里面,至于怎么实现的我们就不管啦,看看怎么用就行了。我们先来看看这两行:
type ArbitraryType int
type Pointer *ArbitraryType
Arbitrary 表示任意的,所以这个 Pointer 可以是任何类型的指针,比如:*int、*string、*float64 等等。也就是说任何类型的指针都可以传递给它。
package main
import (
"fmt"
"unsafe"
)
func main() {
var a int
var s string
var f float64
fmt.Println(unsafe.Pointer(&a)) //0xc000062080
fmt.Println(unsafe.Pointer(&s)) //0xc00004e1c0
fmt.Println(unsafe.Pointer(&f)) //0xc000062088
}
unsafe.Pointer 我们称之为万能指针类型,任何类型的指针都可以转成它。但 unsafe.Pointer 也无法进行运算,如果无法运算,那么就仍无法实现通过指针自增的方式,访问数组的下一个元素。所以还有一个整数类型:uintptr,unsafe.Pointer 是可以和 uintptr 互相转化的,而这个 uintptr 可以运算,并且它还足够大。
因此我们目前看到了两个功能:
- 任何类型的指针都可以和 unsafe.Pointer 相互转化
- unsafe.Pointer 可以和 uintptr 互相转化
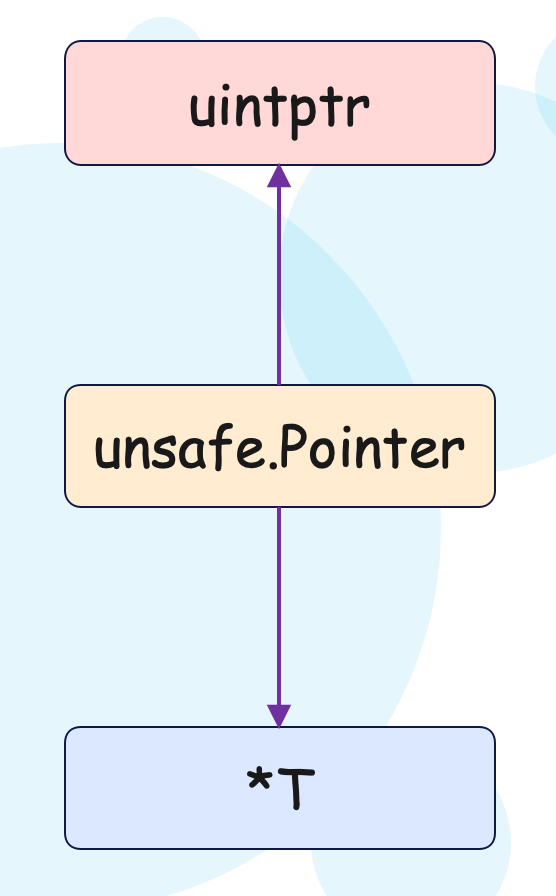
但需要注意的是,uintptr 并没有指针的含义,所以它指向的内存是会被回收的;而 unsafe.Pointer 有指针的含义,可以确保其指向的对象不会被回收。
那么我们就来看看 unsafe 这个包具有哪些黑魔法,以及它又能帮助我们实现什么功能。
像 C 语言一样访问数组或切片
切片内部也是通过数组来存储元素的,这里就以切片为例。
package main
import (
"fmt"
"unsafe"
)
func main() {
var s = []int{177, 123, 3, 221, 5, 1211}
// 获取第二个元素的指针,我们就不从头获取了
// 因为从中间获取都可以的话,那么从头获取肯定可以
// 然后传给 unsafe.Pointer(),将 *int 转化成 Pointer 类型
pointer := unsafe.Pointer(&s[1])
// 注:如果从头获取的话,那么指针要使用 &s[0],而不是 &s
// 注意了:下面要将 Pointer 转成 uintptr,因为 Pointer 是不能运算的
u_pointer := uintptr(pointer)
// 此时的 u_pointer 就相当于 C 的指针了,但是还有一点不同
// C 的指针直接 ++ 即可,指针会自动移动到下一个元素的位置
// 而 Go 的 uintptr 相当于一个整型,我们不能 ++,而是需要 +8
// 因为一个 int 占 8 个字节,所以 Go 里面需要加上元素所占的大小
// 所以我们发现 C 的 +n 是从当前元素开始,移动 n 个元素,不管元素是什么类型
// 但 Go 的 +n 是移动 n 个字节,所以 C 的指针 +n 等于 Go 的 uintptr + n * (元素类型所占的字节)
u_pointer += 16 // 移动两个元素
// 然后再转回来,要先转成 Pointer,再转成对应的指针类型
pointer = unsafe.Pointer(u_pointer)
// 这个 pointer 是通过 &s[1] 也就是 *int 类型的指针得到的,那么结果也要转成 *int
int_pointer := (*int)(pointer)
// 打印了 221,结果是正确的
fmt.Println(*int_pointer) // 221
// 这里也可以转成 *string,即便我们的 pointer 是通过 *int 得到的
// 因为 Pointer 可以是任何指针类型
string_pointer := (*string)(pointer)
// 也是可以打印的,但通过 * 来访问内存的话就会报错
// panic: runtime error: invalid memory address or nil pointer dereference
fmt.Println(string_pointer) //0xc00008c048
// 这里我们再加上 1,不加 8,那么会出现什么后果
// 我们知道再加上 8,就会访问 221 后面的 5
u_pointer += 1
fmt.Println(*(*int)(unsafe.Pointer(u_pointer))) // 360287970189639680
// 此时得到的是一个不知道从哪里来的脏数据,所以一定要加上对应的字节
}
所以我们发现 unsafe.Pointer 就类似于一座桥,*T 通过 Pointer 转成 uintptr,然后进行指针运算。运算完成之后,再通过Pointer 转回 *T,此时的 *T 就是我们想要的了。
指针访问结构体
结构体是可以有字段的,那么我们也可以把结构体想象成数组,字段想象成数组的元素。
package main
import (
"fmt"
"unsafe"
)
type score struct {
math int
english int
history int
}
func main() {
s := score{math: 90, english: 92, history: 85}
// 通过 unsafe.Pointer 获取结构体的指针,并且结构体的地址等于结构体第一个字段的地址
p := unsafe.Pointer(&s)
fmt.Println(*(*int)(p)) // 90
// math 字段是一个整型,那么 p 转为 uintptr 之后加上8,就可以转换成第二个字段的指针
fmt.Println(*(*int)(unsafe.Pointer(uintptr(p) + 8))) // 92
// 同理加上 16 就是第三个
fmt.Println(*(*int)(unsafe.Pointer(uintptr(p) + 16))) // 85
// 这里显然就是一个乱七八糟的值了
fmt.Println(*(*int)(unsafe.Pointer(uintptr(p) + 29))) // 70709489434624
}
前面说了,切片是一个结构体,有三个字段,分别是指向底层数组的指针,以及大小和容量。
package main
import (
"fmt"
"unsafe"
)
func main() {
//申请大小为 5,容量为 10 的切片
s := make([]int, 5, 10)
//第一个元素显然是指向底层数组的指针,大小也是 8 个字节。我们来看第二个和第三个
//虽然有些长,但是从内往外的话,还是很好看懂的。如果不习惯的话可以多写几行
fmt.Printf("长度:%d\n", *(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + 8))) //长度:5
fmt.Printf("容量:%d\n", *(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + 16))) //容量:10
}
注意里面获取的指针是 &s[0],而不是 &s。因为结构体的地址等于结构体第一个字段的地址,如果你要操作的是字段,那么直接获取结构体的地址即可。但如果你要操作的是具体的元素,由于元素实际是存在数组里面的,所以要获取 &s[0]。
当然,如果把切片换成数组,比如 arr,那么 &arr[0] 和 &arr 就是等价的,因为数组的地址等于数组第一个元素的地址。但切片本质是一个结构体,它的地址等于结构体第一个字段的地址。
我们看到 unsafe 包还是很强大的,之所以叫 unsafe 是因为如果用不好后果会很严重。但是如果能正确使用的话,能够做到很多之前做不到的事情。
获取对象的大小
我们目前可以使用 unsafe 做很多事情了,但是还不够,我们看到 unsafe 这个包除了给我们提供了 Pointer 这个类型之外,还提供了三个函数。
func Sizeof(x ArbitraryType) uintptr
func Offsetof(x ArbitraryType) uintptr
func Alignof(x ArbitraryType) uintptr
这三个函数返回的都是 uintptr 类型,这个类型你就看成是整型即可,它是可以和数字进行运算的,可以转为 int。我们先来看看 Sizeof:
package main
import (
"fmt"
"unsafe"
)
func main() {
a := 123
b := "h"
c := []int{1, 2, 3}
fmt.Println(unsafe.Sizeof(a)) // 8
//关于字符串为什么是 16
//Go 的字符串在底层是一个结构体,这个结构体有两个元素
//一个是字符串的首地址,一个是字符串的长度
//所以是 16,因为 Go 的字符串底层对应的是一个字符数组
fmt.Println(unsafe.Sizeof(b)) //16
//切片也是一个结构体,有三个字段,指向底层数组的指针、大小、容量,所以是 24 个字节
fmt.Println(unsafe.Sizeof(c)) //24
}
Go 的 Sizeof 和 C 的 sizeof 还是比较类似的,但是 Go 的 Sizeof 不能接收类型本身,比如你可以传入一个 123,但是你不能传入一个 int,这是不行的。至于获取一个字符串的大小结果是 16,这个是由 Go 底层字符串的结构决定的。
获取结构体成员的偏移量
对于一个结构体来说,可以使用 Offsetof 来获取结构体成员的偏移量,进而获取成员的地址,从而改变内存的值。
package main
import (
"fmt"
"unsafe"
)
type girl struct {
//对应的字节数
name string // 16
age int // 8
gender string // 16
hobby []string // 24
}
func main() {
g := girl{"mashiro", 17, "f", []string{"画画", "开车"}}
fmt.Println(*(*string)(unsafe.Pointer(&g))) // mashiro
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&g)) + 16))) // 17
fmt.Println(*(*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&g)) + 16 + 8))) // f
fmt.Println(*(*[]string)(unsafe.Pointer(uintptr(unsafe.Pointer(&g)) + 16 + 8 + 16))) // [画画 开车]
//我们看到即使对具有不同字段类型的结构体,依旧可以自由操作,只要搞清楚每个字段的大小即可
*(*[]string)(unsafe.Pointer(uintptr(unsafe.Pointer(&g)) + 16 + 8 + 16)) =
append(*(*[]string)(unsafe.Pointer(uintptr(unsafe.Pointer(&g)) + 16 + 8 + 16)), "料理")
fmt.Println(g) // {mashiro 17 f [画画 开车 料理]}
//虽然操作起来没有问题,但是有一个缺陷,就是我们必须要事先计算好每一个字段占多少个字节,尽管通过 unsafe.Sizeof 可以很方便的计算
//但是有没有不用计算的方法呢?显然有,就是我们说的 Offsetof。但是这个 Offsetof 又有点特殊,它表示的是偏移量
//比如我想访问 hobby 这个字段,那么这么做可以,直接以 &g 为起点(此时偏移量为 0),加上 unsafe.Offsetof(g.hobby),直接偏移到 hobby
fmt.Println(*(*[]string)(unsafe.Pointer(uintptr(unsafe.Pointer(&g)) + unsafe.Offsetof(g.hobby)))) // [画画 开车 料理]
//其余的也是一样,获取哪个字段,直接传入哪个字段即可,个人觉得使用 Offsetof 比自己计算要方便一些
fmt.Println(*(*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&g)) + unsafe.Offsetof(g.name)))) // mashiro
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&g)) + unsafe.Offsetof(g.age)))) // 17
fmt.Println(*(*string)(unsafe.Pointer(uintptr(unsafe.Pointer(&g)) + unsafe.Offsetof(g.gender)))) // f
}
而且我们知道,如果在别的包里面,结构体里的字段没有大写,那么是无法导出的,然鹅即便如此,我们依旧可以通过 unsafe 包绕过这些限制。
package hahaha
type OverWatch struct {
name string
age int
Gender string
weapon string
}
这些字段有三个没有大写,理论上是无法导出的,因为 Go 会进行检测,但使用 unsafe 可以绕过这些检测。
package main
import (
"fmt"
"hahaha"
"unsafe"
)
func main() {
hero := new(hahaha.OverWatch)
//设置 name
*(*string)(unsafe.Pointer(uintptr(unsafe.Pointer(hero)))) = "麦克雷"
//设置 age,因为 Offsetof 需要指定访问的字段,而字段又没有被导出,所以无法通过 Offsetof 的方式
//因此需要手动计算对应类型的偏移量,因为是 string 类型,所以加上一个 Sizeof(""),当然也可以手动填上16
*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(hero)) + unsafe.Sizeof(""))) = 37
//这个就可以直接设置了,因为被导出了
hero.Gender = "男"
//老规矩,这里是两个string加上一个int的大小
*(*string)(unsafe.Pointer(uintptr(unsafe.Pointer(hero)) + unsafe.Sizeof("")*2 + unsafe.Sizeof(123))) = "维和者"
fmt.Println(*hero) // {麦克雷 37 男 维和者}
}
小结
参考于:https://qcrao.com/2019/06/03/dive-into-go-unsafe/ ,用原文作者的话来说就是:
unsafe 包绕过了 Go 的类型系统,达到直接操作内存的目的,使用它有一定的风险性。但是在某些场景下,使用 unsafe 包提供的函数会提升代码的效率,Go 源码中也是大量使用 unsafe 包。
uintptr 可以和 unsafe.Pointer 进行相互转换,uintptr 可以进行数学运算,这样通过 uintptr 和 unsafe.Pointer 的结合就解决了 Go 指针不能进行数学运算的限制。通过 unsafe 相关函数,可以获取结构体私有成员的地址,进而对其做进一步的读写操作,突破 Go 的类型安全限制。关于 unsafe 包,我们更多关注它的用法。
顺便说一句,unsafe 包用多了之后,也不觉得它的名字不 "美观" 了。相反,因为使用了官方并不提倡的东西,反而觉得有点酷炫,或许这就是叛逆的感觉吧。
个人非常赞同,觉得真的很酷。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号