
- 进程和线程:进程和线程都是一个时间段的描述,是CPU工作时间段的描述,不过是颗粒大小不同.进程就是包换上下文切换的程序执行时间总和 = CPU加载上下文+CPU执行+CPU保存上下文.线程是共享了进程的上下文环境的更为细小的CPU时间段。
- 判别式模型和生成式模型:
- 判别式模型直接学习决策函数f(X)或条件概率分布P(Y|X)作为预测的模型.往往准确率更高,并且可以简化学习问题.如k近邻法/感知机/决策树/最大熵模型/Logistic回归/线性判别分析(LDA)/支持向量机(SVM)/Boosting/条件随机场算法(CRF)/线性回归/神经网络
- 生成式模型由数据学习联合概率分布P(X,Y),然后由P(Y|X)=P(X,Y)/P(X)求出条件概率分布作为预测的模型,即生成模型.当存在隐变量时只能用生成方法学习.如混合高斯模型和其他混合模型/隐马尔可夫模型(HMM)/朴素贝叶斯/依赖贝叶斯(AODE)/LDA文档主题生成模型
- 概率质量函数 (probability mass function,PMF)是离散随机变量在各特定取值上的概率。
- 概率密度函数(p robability density function,PDF )是对 连续随机变量 定义的,本身不是概率,只有对连续随机变量的取值进行积分后才是概率。
- 累积分布函数(cumulative distribution function,CDF) 能完整描述一个实数随机变量X的概率分布,是概率密度函数的积分。对於所有实数x ,与pdf相对。
- 极大似然估计:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值
- 最小二乘法:二乘的英文是least square,找一个(组)估计值,使得实际值与估计值之差的平方加总之后的值
![]() 最小.求解方式是对参数求偏导,令偏导为0即可.样本量小时速度快.
最小.求解方式是对参数求偏导,令偏导为0即可.样本量小时速度快.
- 梯度下降法:负梯度方向是函数值下降最快的方向,每次更新值都等于原值加学习率(步长)乘损失函数的梯度.每次都试一个步长看会不会下降一定的程度,如果没有的话就按比例减小步长.不断应用该公式直到收敛,可以得到局部最小值.初始值的不同组合可以得到不同局部最小值.在最优点时会有震荡.
- 批量梯度下降(BGD):每次都使用所有的m个样本来更新,容易找到全局最优解,但是m较大时速度较慢
![]()
- 随机梯度下降(SGD):每次只使用一个样本来更新,训练速度快,但是噪音较多,不容易找到全局最优解,以损失很小的一部分精确度和增加一定数量的迭代次数为代价,换取了总体的优化效率的提升.注意控制步长缩小,减少震荡.
![]()
posted @
2024-01-03 18:30
唐青云
阅读(
18)
评论()
收藏
举报

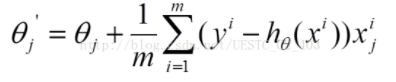

 浙公网安备 33010602011771号
浙公网安备 33010602011771号