GIL
-
小历史
Guido van Rossum(吉多·范罗苏姆)创建python时就只考虑到单核CPU,解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁, 于是有了GIL这把超级大锁。因为cpython解析只允许拥有GIL全局解析器锁才能运行程序,这样就保证了保证同一个时刻只允许一个线程可以使用cpu。由于大量的程序开发者接收了这套机制,现在代码量越来越多,已经不容易通过c代码去解决这个问题。
-
并行与并发
并行:多个CPU同时执行多个任务(多进程)
并发:一个CPU交替处理多个任务(多线程),还是有两个程序,但是只有一个CPU,会交替处理这两个程序,而不是同时执行,只不过因为CPU执行的速度过快,而会使得人们感到是在“同时”执行,执行的先后取决于各个程序对于时间片资源的争夺 -
GIL:Global Interperter Lock(全局解释器锁)
-
Cpython解释器的内存管理并不是线程安全的
-
保护多线程情况下对Python对象的访问,Cpython使用简单的锁机制避免多个线程同时执行字节码(即只有一个线程占用CPU)
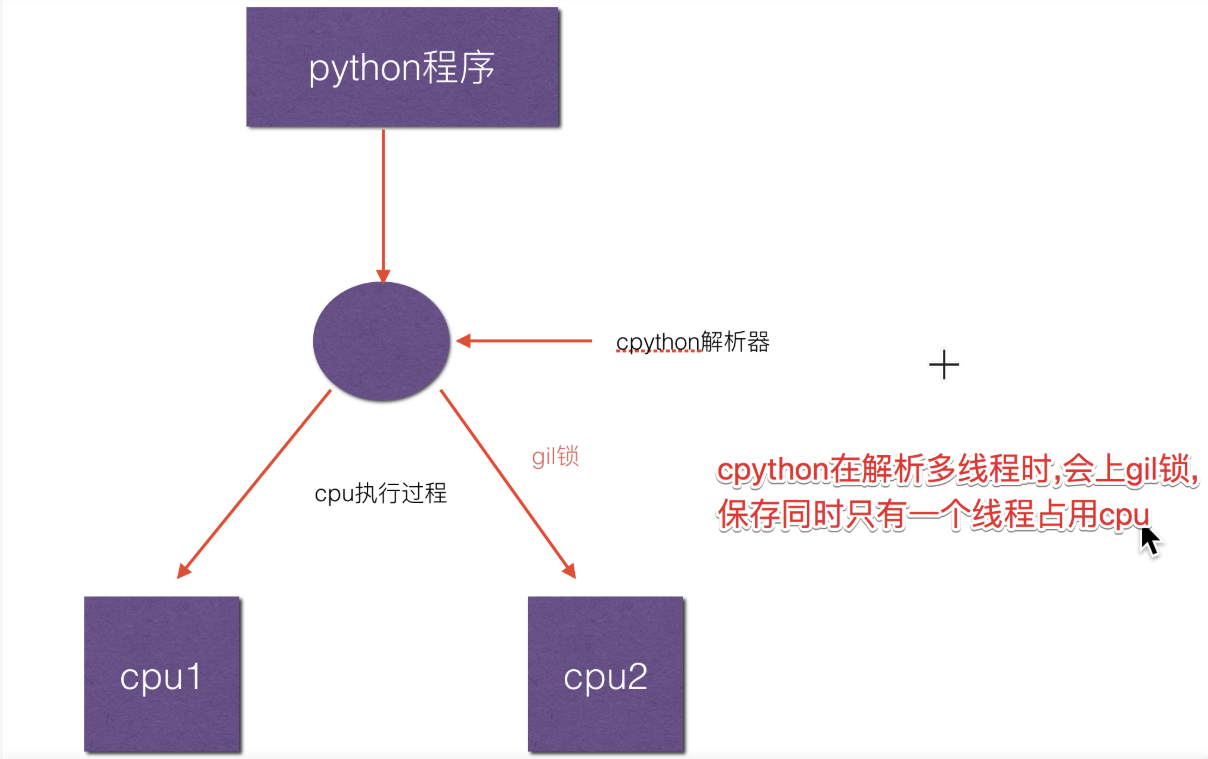
-
-
影响:
- 限制了程序的多核运行,同一时间只能有一个线程给你执行字节码(即只有一个线程占用CPU)
- CPU密集程序难以利用多核优势(大部分时间花在计算上)
- IO期间会释放GIL,对IO密集程序影响不大 (大部分时间花在网络传输上)
- 限制了程序的多核运行,同一时间只能有一个线程给你执行字节码(即只有一个线程占用CPU)
-
如何规避影响:
区分是CPU密集还是IO密集
1. CPU密集可以使用多进程+进程池或者cython扩展(使用多进程完成多线程的任务)
2. IO密集使用多线程/协程 -
为什么有了GIL还要关注线程安全?
因为Python 还有 check interval 这样的抢占机制
比如,运行如下代码:
import threading
n = 0
def foo():
global n
n += 1
threads = []
for i in range(100):
t = threading.Thread(target=foo)
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
print(n)
执行此代码会发现,其大部分时候会打印 100,但有时也会打印 99 或者 98,原因在于 n+=1 这一句代码让线程并不安全。如果去翻译 foo 这个函数的字节码就会发现,它实际上是由下面四行字节码组成:
>>> import dis
>>> dis.dis(foo)
LOAD_GLOBAL 0 (n)
LOAD_CONST 1 (1)
INPLACE_ADD
STORE_GLOBAL 0 (n)
而这四行字节码中间都是有可能被打断的!所以,千万别以为有了 GIL 程序就不会产生线程问题,我们仍然需要注意线程安全。
-
python什么操作是原子的?
-
一个操作若是一个字节码指令完成的就是原子的,原子的就是线程安全的(不算LOAD和RETURN)
-
使用dis来分析字节码❓
import dis def update_list(l): l[0] = 1 dis.dis(update_list) """ 2 0 LOAD_CONST 1 (1) #2是行号 2 LOAD_GLOBAL 0 (l) 4 LOAD_CONST 2 (0) 6 STORE_SUBSCR # 单字节码操作,线程安全 8 LOAD_CONST 0 (None) 10 RETURN_VALUE """ -
一般使用加互斥锁的方式保证线程安全,但对性能有一定影响
import threading lock = threading.Lock() n=[0] def foo(): with lock: # 加锁,执行完后释放锁 n[0] +=1 n[0] +=1 threads = [] for i in range(5000): t = threading.Thread(target=foo) threads.append(t) for t in threads: t.start() print(n)
-
-
如何剖析程序性能
使用各种profile工具(内置或第三方)
1. 二八定律,大部分时间耗时在少量代码上
2. 内置的profile/cprofile等工具
3. 使用pyflame、flameprof的火焰图工具 -
服务端性能优化措施
Web应用一般语言不会成为瓶颈
1. 数据结果与算法优化
2. 数据库层:索引优化,慢查询消除,批量操作减少IO,NoSQL
- 慢查询日志:记录响应时间超过阈值的语句,long_query_time,默认为10秒
3. 网络IO:批量操作,pipeline操作减少IO
- 用pipeline,避免频繁跟redis服务端交互,大量减少网络io
-pipline+hmsetimport redis #创建连接池获取连接 pool = redis.ConnectionPool(host='wykd', port=6379,password='123456', decode_responses=True) rp1 = redis.Redis(connection_pool=pool) #创建管道,可以选择开启或关闭事务,这里的事务与Redis事务一样是弱事务型 pipe = rp1.pipeline(transaction=True) #在管道中添加命令 device.info = { 'machineId':machineId_str, 'machineNum':machineId_str, 'factoryId':factory } pipe.hmset(device_info_key,device_info) #执行pipeline里的脚本 pipe.execute()- 缓存:使用内存数据库redis/memcached,处理高并发的请求
- 异步:asyncio,celery
- 并发:gevent/多线程
问题
-
什么时候会释放GIL锁?
- 遇到像 I/O操作这种会有时间空闲情况造成CPU闲置的情况会释放GIL
- 会有一个专门ticks进行计数 一旦ticks数值达到100 这个时候释放GIL锁,线程之间开始竞争GIL锁(说明:ticks这个数值可以进行设置来延长或者缩减获得GIL锁的线程使用cpu的时间)
-
互斥锁和GIL锁的关系?
GIL锁 :保证同一时刻只有一个线程能使用到cpu
互斥锁:多线程时,保证修改共享数据时是有序的,不会产生数据修改混乱简单地说就是GIL锁是使用CPU的锁,互斥锁是修改数据的锁
首先假设只有一个进程,这个进程中有两个线程 Thread1,Thread2, 要修改共享的数据date, 并且有互斥锁
执行以下步骤
- 多线程运行,假设Thread1获得GIL可以使用cpu,这时Thread1获得互斥锁lock,Thread1可以改date数据(但并
没有开始修改数据) - Thread1线程在修改date数据前发生了 i/o操作或者ticks计数满100 (注意就是没有运行到修改data数据),这个
时候 Thread1 让出了GIL,GIL锁可以被竞争 - Thread1 和 Thread2 开始竞争 GIL (注意:如果Thread1是因为 i/o 阻塞 让出的GIL Thread2必定拿到GIL,如果
Thread1是因为ticks计数满100让出GIL 这个时候 Thread1 和 Thread2 公平竞争) - 假设 Thread2正好获得了GIL, 运行代码去修改共享数据date,由于Thread1有互斥锁lock,所以Thread2无法更改共享数据
date,这时Thread2让出GIL锁 , GIL锁再次发生竞争 - 假设Thread1又抢到GIL,由于其有互斥锁Lock所以其可以继续修改共享数据data,当Thread1修改完数据释放互斥锁lock,
Thread2在获得GIL与lock后才可对data进行修改
- 多线程运行,假设Thread1获得GIL可以使用cpu,这时Thread1获得互斥锁lock,Thread1可以改date数据(但并

 浙公网安备 33010602011771号
浙公网安备 33010602011771号