Celery进阶
Celery进阶
在你的应用中使用Celery
我们的项目
proj/__init__.py
/celery.py
/tasks.py
# celery.py
from celery import Celery
app = Celery('proj',
broker='amqp://', # 消息中介(我更喜欢叫消息枢纽)
backend='rpc://', # 后端,跟踪任务状态和结果
include=['proj.tasks']) # 引入指定的任务,即tasks.py
# Optional configuration, see the application user guide.
app.conf.update(
result_expires=3600, # 设置结果超时为1小时
)
if __name__ == '__main__':
app.start()
# tasks.py
from .celery import app
@app.task
def add(x, y):
return x + y
@app.task
def mul(x, y):
return x * y
@app.task
def xsum(numbers):
return sum(numbers)
注意:如果有多个修饰器的话,@app.task要放在最上面
启动worker
$ celery -A proj worker -l INFO
# 启动成功就会看到一下展示
--------------- celery@halcyon.local v4.0 (latentcall)
--- ***** -----
-- ******* ---- [Configuration]
- *** --- * --- . broker: amqp://guest@localhost:5672//
- ** ---------- . app: __main__:0x1012d8590
- ** ---------- . concurrency: 8 (processes) # 指的是当前可使用的进程有8个,默认是CPU的核数(进程池)
- ** ---------- . events: OFF (enable -E to monitor this worker)
- ** ----------
- *** --- * --- [Queues]
-- ******* ---- . celery: exchange:celery(direct) binding:celery
--- ***** -----
[2012-06-08 16:23:51,078: WARNING/MainProcess] celery@halcyon.local has started.
Celery支持进程池、Eventlet、Gevent以及运行一个简单的线程
重试、访问有关当前任务请求的信息以及添加到自定义任务基类的任何附加功能都需要绑定任务。
logger = get_task_logger(__name__) # 创建一个公共的日志对象
@app.task(bind=True)
def add(self, x, y): # 这里的self时app.Task类
logger.info(self.request.id) # 任务请求包含id,组,参数等属性
@app.task()的参数
- bind=True:绑定任务
- base=XXX:任务继承某类
- name='xxx':设置任务名称
- typing=True:参数需要检查
- argsrepr/kwargsrepr=repr('xxxx'):隐藏敏感信息
- autoretry_for=(XXXError,):当遇到某异常时,自动重新执行
- retry_kwargs={‘’}:重新执行的操作选项,比如max_retries:最大重试次数
- trows=XXX:抛出异常
- ignore_result=True:忽略结果
调用任务
- apply_async()
- delay():不支持操作选项
- calling(_call_):直接使用()
add.apply_async((2,2),queue='lori',countdown=10)
# 第一个参数是个元组,是用来向add这个方法传值的
# queue:任务将会发送到名为‘lori’的队列中
# countdown:倒计时秒
# delay()只能传add方法的参数,而apply_async()不仅为add传参,还可以对消息做相关处理
delay()和apply_async()都会返回一个AsyncResult对象,用于任务执行的状态,但是必须另结果后台可用,从而将数据保存到某处(结果默认是不保存的)
res = add.delay(2,2)
res.get(timeout=1) # 获取任务执行结果,超时为1秒
res.id # 任务的ID
res.get(propagate=False) # 屏蔽掉具体的异常展示
res.failed() # 任务执行失败返回True,成功返回False
res.successful() # 任务执行成功返回True,失败返回False
res.state # 返回任务的当前状态
# 启动状态是一种特殊的状态,只有当task_track_started设置是启用的,或者为任务设置了@task(track_started=True)选项时,才会记录该状态。
# 实际上PENDING状态不会被记录,所以
from proj.celery import app
res = app.AyncResult('this-id-does-not-exist') # 这样在任务ID不存在的情况下,显示默认的状态
res.state
# 'PENDING'
操作选项
link和link_error
# 定义错误处理的任务
@app.task
def error_handler(request, exc, traceback):
print('Task {0} raised exception: {1!r}\n{2!r}'.format(
request.id, exc, traceback))
# 任务发生异常时,执行错误处理任务,相当于时捕获异常
add.apply_async((2, 2), link_error=error_handler.s())
# link和link_error都可以是列表,顺序执行列表中的任务(任务结果作为值传递给下一个任务)
add.apply_async((2, 2), link=[add.s(16), other_task.s()])
on_message:常用于跟踪任务的执行进度
@app.task(bind=True)
def hello(self, a, b): # 任务一般都是需要执行一段时间的
time.sleep(1) # 一般是根据条件判断
self.update_state(state="PROGRESS", meta={'progress': 50})
time.sleep(1)
self.update_state(state="PROGRESS", meta={'progress': 90})
time.sleep(1)
return 'hello world: %i' % (a+b)
def on_raw_message(body):
print(body)
a, b = 1, 1
r = hello.apply_async(args=(a, b))
print(r.get(on_message=on_raw_message, propagate=False))
"""
以下信息会会根据状态的变化逐步输出
{'task_id': '5660d3a3-92b8-40df-8ccc-33a5d1d680d7',
'result': {'progress': 50},
'children': [],
'status': 'PROGRESS',
'traceback': None}
{'task_id': '5660d3a3-92b8-40df-8ccc-33a5d1d680d7',
'result': {'progress': 90},
'children': [],
'status': 'PROGRESS',
'traceback': None}
{'task_id': '5660d3a3-92b8-40df-8ccc-33a5d1d680d7',
'result': 'hello world: 10',
'children': [],
'status': 'SUCCESS',
'traceback': None}
hello world: 10
"""
eta、countdown、expiration
eta是定时,countdown是倒计时,expiration就是任务到期时长(相当于timeout)
from datetime import datetime, timedelta
tomorrow = datetime.utcnow() + timedelta(days=1)
# 定时到明天执行
add.apply_async((2, 2), eta=tomorrow)
# 3秒后执行
result = add.apply_async((2, 2), countdown=3)
# 60秒内执行完,否则会将任务标记成REVOKED(TaskRevokeError)对象(撤回对象)
add.apply_async((10, 10), expires=60)
retry:连接失败时,重发消息
-
max_retires:最大重发次数
-
interval_start:间隔开始,第一次重发需要等待的时间
-
interval_step:间隔步长,每次重发间隔的时间
-
interval_max:间隔最大值
add.apply_async((2, 2), retry=True, retry_policy={ 'max_retries': 3, 'interval_start': 0, 'interval_step': 0.2, 'interval_max': 0.2, }) # 重试全都结束后会法伤OperationalError,一般这种情况就打到日志里,使用try去捕捉而不是用link_error
serializer:消息序列化
序列化类型:
- json(常用)
- pickle
- yaml
- maspack
compression:压缩
压缩类型:
- brotli
- bzip2
- gzip
- lzma
- zlib
- zstd
queue:指定消息队列(路由)
ignore_result:控制是否忽视结果,True为忽视,False为不忽视
针对RabbitMQ的操作选项
exchange
routing_key
priority:优先级(0~255,0是最高优先级)
内置状态
PENDING->STARTED->SUCCESS/FAILURE->RETRY->REVOKED
自定义状态
@app.task(bind=True)
def upload_files(self, filenames):
for i, file in enumerate(filenames):
if not self.request.called_directly:
self.update_state(state='PROGRESS',
meta={'current': i, 'total': len(filenames)})
Canvas:设计工作流
签名(signature)
是用来封装任务的参数以及执行选项
与delay()和apply_async不同,签名不会运行,就像为任务对象添加了属性而已
s()是signature()的简写,但是不能控制执行选项
s1 = add.signature((2,2),countdown=10) # 或者简写s1 = add.s(2,2)
res = s1.delay() # 运行最后还是要用过delay()和apply_async()或者使用()
# add(2,2) = add.s(2,2)() = add.s(2,2).delay()
# add.signature((2,2),countdown=10).apply_async() = add.apply_async((2,2),countdown=10)
部分参数
为了串联任务使用,将一个任务的结果传到下一个任务中做参数
拼接args
s1 = add.s(2) # s() 是signature() 的快捷方式,快捷方式没有操作选项的参数
res = s1.deplay(8) # 实际执行的是s1.deplay(8,2)
参数覆盖kwargs
s2 = add.s(2,2,debug=True)
s2.delay(debuy=False)
永久性
部分参数用于回调,任何链接的任务,或和弦回调将应用于父任务的结果。有时需要指定一个回调函数,它不接受额外的参数,可以将签名设置为不可变的
主要是应对串联执行任务的时候,当前任务不受上一任务的结果影响
add.apply_async((2, 2), link=reset_buffers.signature(immutable=True))
# 缩写用si()
add.apply_async((2, 2), link=reset_buffers.si())
add.si(2,2)
回调
使用link参数,将一个任务的结果传到下一个任务中做参数(也可以叫链接)
add.apply_async((2, 2), link=add.s(8))
# 2+2=4, add.delay(8,4)=>8+4=12
原语
-
Groups:组,多个任务并行执行,返回一组结果
from celery import group from proj.tasks import add g = group(add.s(2, 2), add.s(4, 4)) res = g().get() >>> [4, 8] group(add.s(i, i) for i in range(10))().get() >>> [0, 2, 4, 6, 8, 10, 12, 14, 16, 18] # 部分组,与部分签名一样 g = group(add.s(i) for i in range(10)) g(10).get() >>>[10, 11, 12, 13, 14, 15, 16, 17, 18, 19] -
Chains:链,使多个任务按顺序执行,且将父任务的执行结果作为参数传给子任务(chain括号内从左往右顺序执行)
from celery import chain from proj.tasks import add, mul # (4 + 4) * 8 chain(add.s(4, 4) | mul.s(8))().get() # 使用| 可以将上一个任务的结果作为参数,传到下一个任务签名中 >>> 64 # (? + 4) * 8 g = chain(add.s(4) | mul.s(8)) g(4).get() >>> 64 (add.s(4, 4) | mul.s(8))().get() # 简写可以去掉chain >>> 64 # 若像使子任务的参数不变,则使用si() res = (add.si(2, 2) | add.si(4, 4) | add.si(8, 8))() res.get() # 16 res.parent.get() # 8 res.parent.parent.get() # 4 -
Chords:和弦,得出组得所有结果(待所有组中的任务执行完),并作为参数传到子任务
from celery import chord from proj.tasks import add, xsum chord((add.s(i, i) for i in xrange(10)), xsum.s())().get() # 将并行的结果实例传到串行的方法中执行 >>> 90 (group(add.s(i, i) for i in xrange(10)) | xsum.s())().get() # 链接到其他任务的组将自动转换为和弦 >>> 90 upload_document.s(file) | group(apply_filter.s() for filter in filters)错误处理
组中的任务若有一个出现了错误,会报异常,但是其他的任务仍旧会继续执行,唯一显示首先失败的任务
-
**map **& starmap:图和星图
与组的区别是:
- 只发送一个任务消息
- 操作是顺序的
map和starmap的区别:
-
map:列表中的值作为单个参数传递
res = task.map([1, 2]) # res = [task(1), task(2)] -
starmap:列表中的值是元组传递
res = add.starmap([(2, 2), (4, 4)]) # res = [add(2, 2), add(4, 4)] # 通常会使用zip处理元组 res = add.starmap(zip(range(10), range(10)))
-
chunks:块,就是将大量的任务分成若干块
# 将100个元组,分成每10个一块,得出二维数组的结果 res = add.chunks(zip(range(100), range(100)), 10)() res.get() >>>[[0, 2, 4, 6, 8, 10, 12, 14, 16, 18], [20, 22, 24, 26, 28, 30, 32, 34, 36, 38], [40, 42, 44, 46, 48, 50, 52, 54, 56, 58], [60, 62, 64, 66, 68, 70, 72, 74, 76, 78], [80, 82, 84, 86, 88, 90, 92, 94, 96, 98], [100, 102, 104, 106, 108, 110, 112, 114, 116, 118], [120, 122, 124, 126, 128, 130, 132, 134, 136, 138], [140, 142, 144, 146, 148, 150, 152, 154, 156, 158], [160, 162, 164, 166, 168, 170, 172, 174, 176, 178], [180, 182, 184, 186, 188, 190, 192, 194, 196, 198]] # 还可以在执行前继续分组 add.chunks(zip(range(100), range(100)), 10).group() """ 场景: 将100个用例分配到10台执行机并行执行10个用例 """ -
graphs:画出节点图
方便追踪任务中发生异常的节点,一般这些节点都是临时节点,使用的是uuid
res = chain(add.s(4, 4), mul.s(8), mul.s(10))() res.parent.parent.graph """ 872c3995-6fa0-46ca-98c2-5a19155afcf0(2) 285fa253-fcf8-42ef-8b95-0078897e83e6(1) 463afec2-5ed4-4036-b22d-ba067ec64f52(0) """ # 将节点序列写入文件,为了生成图片 with open('graph.dot', 'w') as fh: res.parent.parent.graph.to_dot(fh)$ dot -Tpng graph.dot -o graph.png
Worker
woker的启动、停止、重启
celery -A proj worker -l INFO # 启动任务名为proj的worker
celery worker --help # 查看帮助
# 停止worker
pkill -9 -f "celery worker"
ps auxww | awk '/celery worker/ {print $2}' | xargs kill -9
# 重启worker
celery multi start 1 -A proj -l INFO -c4 --pidfile=/var/run/celery/%n.pid
celery multi restart 1 --pidfile=/var/run/celery/%n.pid
路由
Celery支持RabbitMQ的所有路由,可将消息发送到指定的任务队列
# rabbitMQ路由的配置
app.conf.update(
task_routes = {
'proj.tasks.add': {'queue': 'hipri'},
},
)
------------------------------
# celery发送消息到指定队列
from proj.tasks import add
add.apply_async((2, 2), queue='hipri')
可以使用celery -Q指定队列
$ celery -A proj worker -Q hipri # 可以在运行worker的时候指定
$ celery -A proj worker -Q hipri,celery # 用逗号分割指定多个
远程控制
-
检查
# celery -A proj inspect --help 检查 celery -A proj inspect active celery -A proj inspect active --destination=celery@example.com # 指定worker celery -A proj status # 显示所有worker的状态列表 -
控制
# celery -A proj control --help 控制 celery -A proj control enable_events # 远程启用事件 celery -A proj events --dump # 启动事件后,可以启动事件转储程序,并行查看woker执行状况 celery -A proj control disable_events # 远程禁用事件
周期任务
时区
app.conf.timezone = 'Europe/London'
入口
from celery import Celery
from celery.schedules import crontab
app = Celery()
@app.on_after_configure.connect # 在应用配置后发送
def setup_periodic_tasks(sender, **kwargs):
"""
可以看到以下使用的都是签名
"""
# 每10秒调用一次 test('hello')
sender.add_periodic_task(10.0, test.s('hello'), name='add every 10')
# 每30秒调用一次 test('world'),10秒内执行完
sender.add_periodic_task(30.0, test.s('world'), expires=10)
# 每周一上午7点30分执行
sender.add_periodic_task(
crontab(hour=7, minute=30, day_of_week=1),
test.s('Happy Mondays!'),
)
@app.task
def test(arg):
print(arg)
@app.task
def add(x, y):
z = x + y
print(z)
crontab方法
crontab(minute='*', hour='*', day_of_week='*', day_of_month='*', month_of_year='*', **kwargs)
*:表示所有
*/n:表示每间隔n个时刻
n:表示每次到n时刻时开始
太阳能时间表
按照日出、日落、黎明、黄昏来执行
from celery.schedules import solar
app.conf.beat_schedule = {
# Executes at sunset in Melbourne
'add-at-melbourne-sunset': {
'task': 'tasks.add',
'schedule': solar('sunset', -37.81753, 144.96715),
'args': (16, 16),
},
}
solar(event, latitude, longitude)
| 标志 | 争论 | 意义 |
|---|---|---|
+ |
latitude |
北 |
- |
latitude |
南 |
+ |
longitude |
东 |
- |
longitude |
西 |
| 事件 | 意义 |
|---|---|
dawn_astronomical |
在天空不再完全黑暗的那一刻执行。这是太阳在地平线以下 18 度的时候。 |
dawn_nautical |
当有足够的阳光让地平线和一些物体可以区分时执行;正式地,当太阳在地平线以下 12 度时。 |
dawn_civil |
当有足够的光线可以区分物体时执行,以便开始户外活动;正式地,当太阳在地平线以下 6 度时。 |
sunrise |
当早晨太阳的上边缘出现在东部地平线时执行。 |
solar_noon |
当当天太阳位于地平线上方时执行。 |
sunset |
当傍晚太阳的后缘消失在西部地平线上时执行。 |
dusk_civil |
在民用暮光结束时执行,此时物体仍可区分并且一些恒星和行星可见。正式地,当太阳在地平线以下 6 度时。 |
dusk_nautical |
当太阳在地平线以下 12 度时执行。物体不再可区分,地平线不再是肉眼可见的。 |
dusk_astronomical |
在天空变得完全黑暗的那一刻执行;正式地,当太阳在地平线以下 18 度时。 |
启动调度服务
celery -A proj beat
celery -A proj beat -s # 将任务的上次运行时间存储在本地数据库中
路由任务
自动路由
启动task_create_missing_queues配置(默认启动),会自动创建尚未定义的命名队列
app.conf.task_routes = ([
('feed.tasks.*', {'queue': 'feeds'}), # ('任务名称正则',{'queue':'队列名'})
('web.tasks.*', {'queue': 'web'}),
(re.compile(r'(video|image)\.tasks\..*'), {'queue': 'media'}),
],)
# 可以在启动时指定队列
celery -A proj worker -Q feeds,celery
手动路由
from kombu import Queue
app.conf.task_default_queue = 'default' # 默认队列名称
# 任务队列实例
app.conf.task_queues = (
Queue('feed_tasks', routing_key='feed.#'), # 在默认交换机
Queue('regular_tasks', routing_key='task.#'), # 在默认交换机
Queue('image_tasks', exchange=Exchange('mediatasks', type='direct'), # 在mediatasks交换机
routing_key='image.compress'),
)
app.conf.task_default_exchange = 'tasks' # 默认交换机
app.conf.task_default_exchange_type = 'topic' # 默认交换类型
app.conf.task_default_routing_key = 'task.default' # 路由关键字
app.conf.task_routes = {
'feeds.tasks.import_feed': {
'queue': 'feed_tasks',
'routing_key': 'feed.import',
},
}
消息优先级
RabbitMQ
from kombu import Exchange, Queue
# 为指定队列设置x-max-priority参数将队列配置为支持优先级
app.conf.task_queues = [
Queue('tasks', Exchange('tasks'), routing_key='tasks',
queue_arguments={'x-max-priority': 10}),
]
# 为所有队列设置优先级
app.conf.task_queue_max_priority = 10
# 使用task_default_priority设置指定所有任务的默认优先级
app.conf.task_default_priority = 5
Redis
Redis本身没有优先级概念,所以需要如下配置
app.conf.broker_transport_options = {
'queue_order_strategy': 'priority',
}
"""
通过为每个队列创建 n 个列表来实现优先级支持。这意味着即使有 10 (0-9) 个优先级,默认情况下它们也被合并为 4 个级别以节省资源。这意味着一个名为 celery 的队列将真正分为 4 个队列:
['celery0', 'celery3', 'celery6', 'celery9']
"""
路由器
路由器是决定任务的路由选项的功能
def route_task(name, args, kwargs, options, task=None, **kw):
if name == 'myapp.tasks.compress_video':
return {'exchange': 'video',
'exchange_type': 'topic',
'routing_key': 'video.compress'}
广播
from kombu.common import Broadcast
from celery.schedules import crontab
app.conf.task_queues = (Broadcast('broadcast_tasks'),) # 使用的时Broadcast而不是Queue
app.conf.beat_schedule = {
'test-task': {
'task': 'tasks.reload_cache',
'schedule': crontab(minute=0, hour='*/3'),
'options': {'exchange': 'broadcast_tasks'}
},
}
监控管理
命令行管理
celery <command> --help
命令
- shell:放入 Python shell
- status:列出此集群中的活动节点
- result:显示任务的结果
- purge:从所有配置的任务队列中清除消息(无法撤销)
- inspect:
- active:列出活动任务
- sheduled:列出计划的 ETA 任务
- reserved:列出保留的任务
- revoker:列出已撤销任务的历史记录
- registered:列出注册的任务
- stats:显示worker统计信息
- query_task:按id显示任务信息
- control:
- enable_events:启用事件
- disable_events:禁用时间
- migrate:将任务迁移到另一个broker
Flower
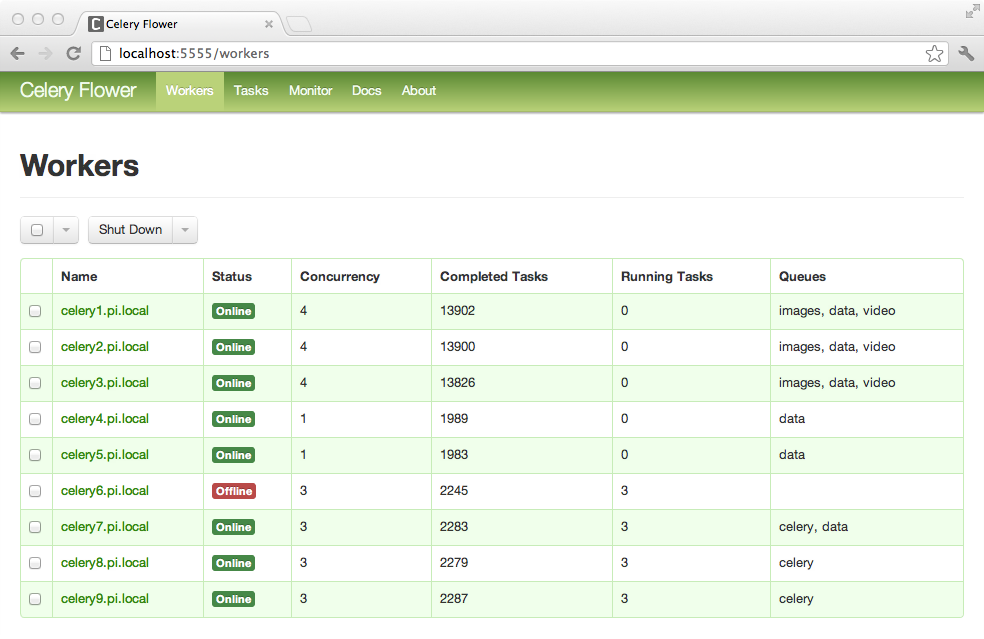
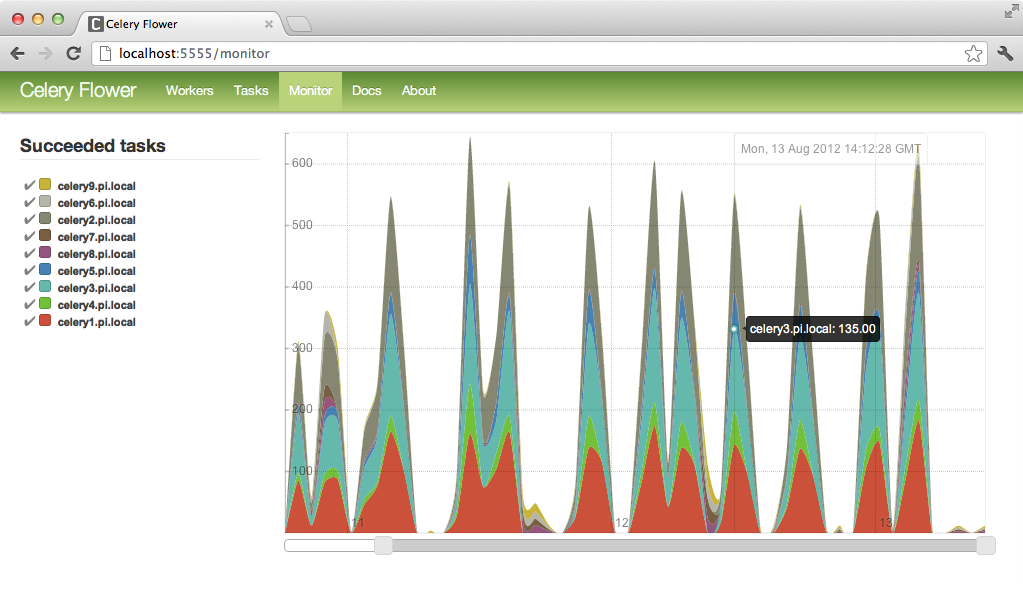
用法
- 安装:pip install flower
- 启动:celery -A proj flower -port=5555
- 浏览器访问
实时处理
-
Receiver:事件使用者
-
事件进入时调用的一组处理程序
-
状态
from celery import Celery def my_monitor(app): state = app.events.State() def announce_failed_tasks(event): state.event(event) # task name is sent only with -received event, and state # will keep track of this for us. task = state.tasks.get(event['uuid']) print('TASK FAILED: %s[%s] %s' % ( task.name, task.uuid, task.info(),)) with app.connection() as connection: recv = app.events.Receiver(connection, handlers={ 'task-failed': announce_failed_tasks, '*': state.event, }) recv.capture(limit=None, timeout=None, wakeup=True) # 该wakeup给的说法capture将信号发送给所有工人迫使他们发送心跳。这样,您可以在监视器启动时立即看到工作人员。 if __name__ == '__main__': app = Celery(broker='amqp://guest@localhost//') my_monitor(app)任务事件
- task-sent:在发布任务消息并task_send_sent_event启用设置时发送
- task-received:任务接收时发送
- task-started:任务启动时发送
- task-succeeded:任务成功时发送
- task-failed:任务失败时发送
- task-rejected:任务被拒绝时发送
- task-retried:任务失败则重试
- task-revoked:任务被撤销则发送
Worker事件
- worker-online:worker在线
- woker-heartbeat:在指定时间内没有发送心跳则是失去连接
- woker-offline:worker断开连接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号