RabbitMQ
应用场景
- 异步处理
- 应用解耦
- 流量削峰
安装
docker
# 下载镜像
docker pull rabbitmq
# 运行镜像
docker run -d --name my-rabbitmq -p 4369:4369 -p 5671:5671 -p 5672:5672 -p 25672:25672 rabbitmq
windows
- 安装Erlang
- http://www.erlang.org/downloads 下载otp_winxx_{版本}.exe
- 安装并配置环境变量
- %ERLANG_HOME%\bin
- 安装RabbitMq
关键词
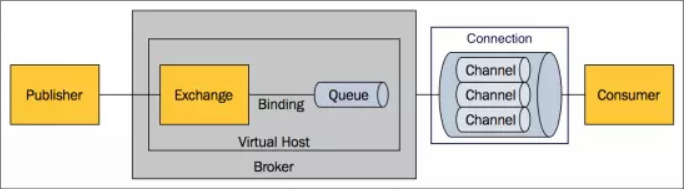
-
Pbulisher/Producer:发布者
-
Consumer:消费者
-
Connection:TCP连接,一个 TCP 连接上可以建立成百上千个信道,通过这种方式,可以减少系统开销,提高性能。
- Channel: 信道是生产者,消费者和 RabbitMQ 通信的渠道,是建立在 TCP 连接上的虚拟连接。
-
Broker: 接收客户端连接,实现 AMQP 协议的消息队列和路由功能的进程。
-
Virtual Host: 虚拟主机的概念,类似权限控制组,一个 Virtual Host 里可以有多个 Exchange 和 Queue,权限控制的最小粒度是 Virtual Host。
-
Exchange: 交换机,接收生产者发送的消息,并根据 Routing Key 将消息路由到服务器中的队列 Queue。
- ExchangeType: 交换机类型决定了路由消息的行为模式
- direct:路由模式
- topic:匹配模式
- fanout:发布订阅模式
- ExchangeType: 交换机类型决定了路由消息的行为模式
-
BindingKey: 绑定关键字,将一个特定的 Exchange 和一个特定的 Queue 绑定起来。
-
Message Queue: 消息队列,用于存储还未被消费者消费的消息,由 Header 和 body 组成。
- Header:由生产者添加的各种属性的集合,包括 Message 是否被持久化、优先级是多少、由哪个 Message Queue 接收等
- body:真正需要发送的数据内容。
-
注意:生产者、消费者、消息代理可能不在同一主机上
Hello World
- pip install pika
- 生产者发送消息至消息队列,消费者从消息队列中接收消息
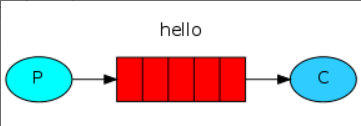
生产者代码
-
与RabbitMQ建立连接
-
声明使用的消息队列
-
发布消息给Broker
-
关闭连接
# producer.py import pika # 建立连接 hostname = 'xxx.xxx.xxx.xxx' credentials = pika.PlainCredentials('username','password') parameters = pika.ConnectionParameters(hostname,credentials=credentials) connection = pika.BlockingConnection(parameters) channel = connection.channel() # 声明信道对象 # 创建队列 channel.queue_declare(queue="hello") # 消息内容 content = 'Hello World' # 发布消息 channel.basic_publish(exchange='', routing_key='hello', body=content) print("[x] Sent Hello World") connection.close()
消费者代码
-
与RabbitMQ建立连接
-
声明使用的消息队列
-
定义接收到消息之后触发的方法
-
从Broker中获取消息并消费(接收消息)
# consumer.py import pika hostname = 'xxx.xxx.xxx.xxx' credentials = pika.PlainCredentials('username','password') parameters = pika.ConnectionParameters(hostname,credentials=credentials) connection = pika.BlockingConnection(parameters) channel = connection.channel() # 声明使用的队列 channel.queue_declare(queue="hello") # 接受到消息后触发的方法 def callback(ch, method, properties, body): print("[x] Received {}".format(body)) # 消费消息 channel.basic_consume('hello', callback, auto_ack=True) print('[*] Waiting for messages. To exit press Ctrl+C') channel.start_consuming() -
运行结果
-
先运行consumer.py再运行producer.py
python consumer.py # => [*] Waiting for messages. To exit press CTRL+C # => [x] Received 'Hello World!' python producer.py # => [x] Sent 'Hello World!'
-
工作队列
主要思想
- 生产者将耗时的任务分发给多个消费者(一个生产者,一个消息队列,多个消费者)
- 处理资源密集型任务,并且还要等它完成
- 将工作封装为一个消息队列,工作在多个消费者(进程)共享
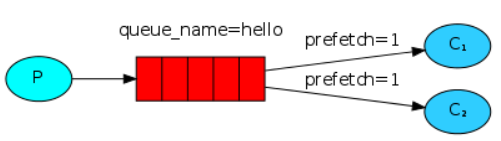
两种消息分发机制
-
轮询分发:将消息轮流发送给每个消费者,要等到一个消费者处理完,才把消息发送给下一个消费者(效率低)
-
公平分发:只要有消费者处理完,就会把消息发送给目前空闲的消费者(效率高)
# 告诉RabbitMQ一次向消费者只发送1个消息,直到消费者发送消息确认后再发送下一个,消息确认前将下一个消息发送给空闲的消费者 channel.basic_qos(prefetch_count=1)
消息确认
-
确保消费者死亡,任务也不会丢失,将任务交付给下一个消费者
-
在回调函数中添加消息确认,告诉生产者已经接收到消息
def callback(ch, method, properties, body): print("[x] Received %r" % body) time.sleep(body.count(b'.')) print("[x] Done") # 告诉生产者,消费者已收到消息,一般在处理结尾发送确认 ch.basic_ack(delivery_tag=method.delivery_tag)
消息持久化
-
确保即使RabbitMQ服务器崩溃,消息也不会丢失
-
确保队列是永久的
channel.queue_declare(queue='task_queue', durable=True) -
确保消息是永久的
channel.basic_publish(exchange='', routing_key='task_queue', body=message, properties=pika.BasicProperties( delivery_mode=2, # 确保消息是持久的 ))
生产者代码
- 与RabbitMQ建立连接
- 声明使用的持久化消息队列
- 发布持久化消息给Broker
- 关闭连接
import pika
import sys
hostname = '127.0.0.1'
parameters = pika.ConnectionParameters(hostname)
connection = pika.BlockingConnection(parameters)
channel = connection.channel()
# durable = True 代表消息队列持久化存储,False 非持久化存储
channel.queue_declare(queue='work_queue',durable=True)
message = ''.join(sys.argv[1:]) or 'Hello World'
# delivery_mode = 2 声明消息在队列中持久化,delivery_mod = 1 消息非持久化
channel.basic_publish(exchange='',
routing_key='work_queue',
body=message,
properties=pika.BasicProperties(delivery_mode=2,))
print("[x] Sent %r" % message)
connection.close()
消费者代码
- 与RabbitMQ建立连接
- 声明需要使用的持久化消息队列
- 定义接收到消息之后触发的方法
- 方法结尾发送确认信息
- 设置消息公平分发(接收一条,处理一条,处理结束之后再接收)
- 从Broker中获取消息并消费(接收消息)
import pika
import time
hostname = '127.0.0.1'
parameters = pika.ConnectionParameters(hostname)
connection = pika.BlockingConnection(parameters)
channel = connection.channel()
# durable = True 代表消息队列持久化存储,False 非持久化存储
channel.queue_declare(queue='work_queue', durable=True)
def callback(ch, method, properties, body):
print("[x] Received %r" % body)
time.sleep(body.count(b'.'))
print("[x] Done")
# 告诉生产者,消费者已收到消息,一般在处理结尾发送确认
ch.basic_ack(delivery_tag=method.delivery_tag)
# 直到消费者发送消息确认后再发送下一个,消息确认前将下一个消息发送给空闲的消费者
channel.basic_consume('work_queue', callback) # auto_ack=False,自动发送确认消息默认是False
# 告诉RabbitMQ一次只向消费者发送1条消息
channel.basic_qos(prefetch_count=1)
print("[*] Waiting for messages. To exist press Ctrl+C")
channel.start_consuming()
交换机
-
通过声明交换机的交换类型,确定消息队列的工作模式
-
交换类型有三种:
- direct:路由模式
- topic:匹配模式
- fanout:发布/订阅模式
# 声明交换机名称、类型 channel.exchange_declare(exchange='exchange_name', exchange_type='fanout') # direct or topic or fanout
-
发布/订阅模式
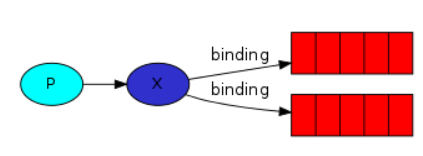
主要思想
- 消息经过交换机之后,交换机将收到的所有消息广播到所有队列(一个生产者,一个交换机,多个消息队列)
临时队列
- (因为是广播,无所谓什么队列,所以可以使用临时队列)
# 使用result记录创建的临时队列
result = channel.queue_declare(exclusive=True) # exclusive=True,一旦消费者关闭连接,删除临时队列
绑定
- (交换机需要和队列绑定)
channel.queue_bind(exchange='exchange_name',
queue=result.method.queue)
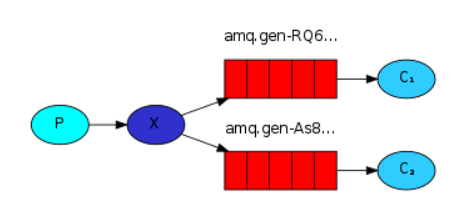
(一个生产者,一个交换机,多个消息队列,一个消息队列对应一个消费者?)
- 思考:一个消息队列能对应多个消费者吗?
生产者代码
-
与RabbitMQ建立连接
-
声明使用的交换机,类型为fanout
-
发布消息给交换机
-
关闭连接
# producer.py import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明交换机是发布/订阅模式 channel.exchange_declare(exchange='logs', exchange_type='fanout') message = ' '.join(sys.argv[1:]) or 'info: Hello World' channel.basic_publish(exchange='logs', routing_key='', body=message) print('[x] Sent %r ' % message) connection.close()
消费者代码
-
与RabbitMQ建立连接
-
声明使用的交换机,类型为fanout
-
声明创建临时队列
-
获取临时队列名
-
绑定临时队列
-
定义接收到消息之后触发的方法
-
从Broker中获取消息并消费
# consumer.py import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明交换机是发布/订阅模式 channel.exchange_declare(exchange='logs', exchange_type='fanout') # 声明只允许当前连接的队列 result = channel.queue_declare('',exclusive=True) # 获取临时队列名 queue_name = result.method.queue channel.queue_bind(exchange='logs', queue=queue_name) print('[*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print('[x] %r ' % body) channel.basic_consume('', callback) channel.start_consuming()
路由模式
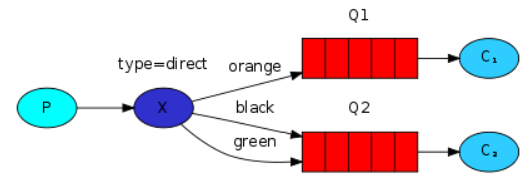
主要思想
-
为了让生产者发布的消息定向的精确发送到指定的队列(严格过滤,完全匹配)
-
在绑定的时候使用routing_key参数,即绑定键
channel.queue_bind(exchange=exchange_name, queue=queue_name, routing_key='black') -
也可以使用多个绑定实现类广播效果(当然之后的匹配模式就是如此)
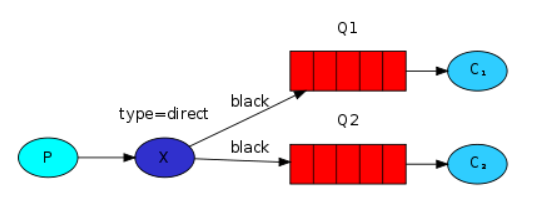
例如日志消息
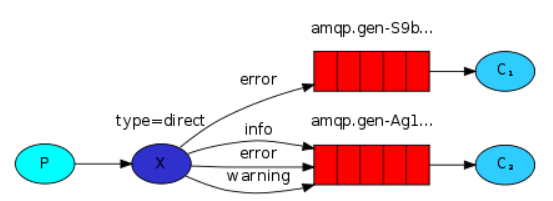
生产者代码
-
与RabbitMQ建立连接
-
声明使用的交换机,类型为direct
-
通过命令行第2个参数确定交换机的routing_key
-
发布消息给交换机
-
关闭连接
import sys import pika connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs_direct', exchange_type='direct') print(sys.argv[1:]) # 根据命令行输入的第2个参数确定routing_key(error,warning,info) # 将不同类型的日志消息保存到不同的队列 severity = sys.argv[1] if len(sys.argv) > 2 else 'info' message = ' '.join(sys.argv[2:]) or 'Hello World' channel.basic_publish(exchange='logs_direct', routing_key=severity, body=message) print("[x] Sent %r:%r " % (severity, message)) connection.close()
消费者代码
-
与RabbitMQ建立连接
-
声明使用的交换机,类型为direct
-
声明创建临时队列
-
获取临时队列名
-
绑定临时队列,通过命令行的参数确定交换机的routing_key
-
定义接收到消息之后触发的方法
-
从Broker中获取消息并消费
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 设置路由模式 channel.exchange_declare(exchange='logs_direct', exchange_type='direct') # 声明临时队列 result = channel.queue_declare('', exclusive=True) queue_name = result.method.queue # 设置队列和交换机绑定的键,通过参数确定接收什么类型的日志消息(即从指定的队列中获取消息) severties = sys.argv[1:] for severity in severties: channel.queue_bind(queue=queue_name, exchange='logs_direct', routing_key=severity) print("[*] Waiting for logs. To exit press CTRL+C") def callback(ch, method, properties, body): print("[x] %r:%r" % (method.routing_key, body)) channel.basic_consume(queue_name, callback) channel.start_consuming() -
运行
# 如果只想保存'warning'和'error'(而不是'info')将消息记录到文件中,只需打开一个控制台并输入: python receive_logs_direct.py warning error > logs_from_rabbit.log # 如果您希望在屏幕上看到所有日志消息,请打开一个新终端并执行以下操作: python receive_logs_direct.py info warning error # 例如,要输出error日志消息,只需输入: python emit_log_direct.py error "Run. Run. Or it will explode."
-
匹配模式
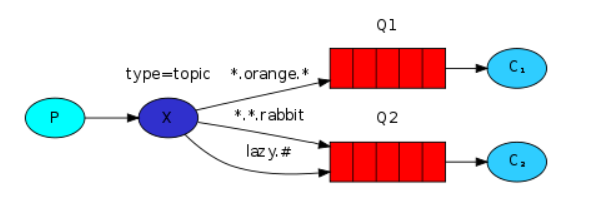
主要思想
- 路由模式是精确严格的筛选,而匹配模式根据匹配的条件过滤(模糊匹配)
规范
- 必须是由”.“连接单词列表
- 最多255个字节
- ”*“ 可以代替一个单词
- ”#“可以代替0个或者多个单词
- 交换机类型为topic
生产者代码
# emit_log_topic.py
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 交换机类型为topic
channel.exchange_declare(exchange='logs_topic', exchange_type='topic')
print(sys.argv[1:])
severity = sys.argv[1] if len(sys.argv) > 2 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World'
channel.basic_publish(exchange='logs_topic', routing_key=severity, body=message)
print("[x] Sent %r:%r " % (severity, message))
connection.close()
消费者代码
# receive_logs_topic.py
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 交换机类型为topic
channel.exchange_declare(exchange='logs_topic', exchange_type='topic')
result = channel.queue_declare('', exclusive=True)
queue_name = result.method.queue
# 设置队列和交换机绑定的键
severties = sys.argv[1:]
for severity in severties:
channel.queue_bind(queue=queue_name, exchange='logs_topic', routing_key=severity)
print("[*] Waiting for logs. To exit press CTRL+C")
def callback(ch, method, properties, body):
print("[x] %r:%r" % (method.routing_key, body))
channel.basic_consume(queue_name, callback)
channel.start_consuming()
运行
#要接收所有日志运行:
python receive_logs_topic.py "#"
#要从设施“ kern ” 接收所有日志:
python receive_logs_topic.py "kern.*"
#或者,如果您只想听到关于“ critical ”日志的信息:
python receive_logs_topic.py "*.critical"
#您可以创建多个绑定:
python receive_logs_topic.py "kern." ".critical"
#发布带有路由键“ kern.critical ”类型的日志:
python emit_log_topic.py "kern.critical" "A critical kernel error"
远程过程调用(RPC)
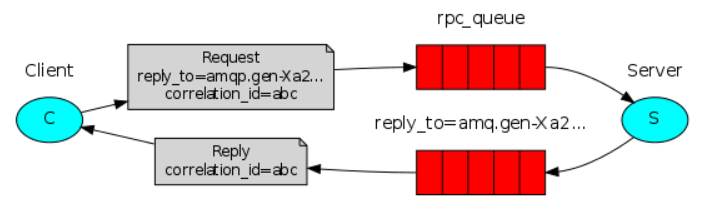
主要思想
- 客户端与服务器之间是完全解耦的,即两端既是消息的发送者也是接受者。
服务器代码(消费者)
- 建立连接
- 声明队列
- 定义接收请求的回调函数(函数处理之后,向Client发送响应)
- properties.reply_to:客户端发来的绑定键
- properties.correlation_id:客户端发来的相关ID
- 设置公平分发
- 接收消息,触发请求
# server.py
import pika
hostname = '192.168.253.129'
credentials = pika.PlainCredentials('admin', 'admin')
parameters = pika.ConnectionParameters(hostname, credentials=credentials)
connecion = pika.BlockingConnection(parameters=parameters)
channel = connecion.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
"""
返回第n个斐波那契数
:param n:返回数量
:return: 返回第n个斐波那契数
"""
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
def on_request(ch, method, properties, body):
"""
接收client发来的请求,处理之后,再向client发送响应信息
:param ch:
:param method:
:param properties:client请求的属性
:param body:响应信息的内容
:return:
"""
# 收到请求后的处理过程
n = int(body)
print(f'[.] fib({n})')
response = fib(n)
# 将处理结果发送回client
channel.basic_publish(exchange='',
routing_key=properties.reply_to, # 响应的信息是要发回给请求的队列,而不是rpc_queue
properties=pika.BasicProperties(
correlation_id=properties.correlation_id # 请求的唯一值属性
),
body=str(response))
ch.basic_ack(delivery_tag=method.delivery_tag) # 消息确认
channel.basic_qos(prefetch_count=1) # 处理过程中只接受一条消息
channel.basic_consume(queue='rpc_queue', on_message_callback=on_request) # 接受Client请求
print(" [x] Awaiting RPC requests")
channel.start_consuming()
客户端代码(生产者)
- 初始化
- 建立连接
- 回调处理响应消息
- 定义处理响应消息的回调函数
- 定义发送请求的函数
- 创建对象
- 发送请求
- 关闭连接
# client.py
import pika
import uuid
class FibRPCClient:
'''
定义一个客户端类,发送信息的Producer
初始化的时候建立连接和渠道
随机生成一个队列作为回调队列
从回调队列中接收server响应的消息
'''
def __init__(self):
hostname = '192.168.253.129'
credentials = pika.PlainCredentials('admin', 'admin')
parameters = pika.ConnectionParameters(hostname, credentials=credentials)
self.connecion = pika.BlockingConnection(parameters=parameters)
self.channel = self.connecion.channel()
result = self.channel.queue_declare(queue='',exclusive=True) # 声明临时的队列
self.callback_queue = result.method.queue # 记录临时队列的队列号
self.channel.basic_consume(queue=self.callback_queue,on_message_callback=self.on_response) # 接受响应信息
self.response = ''
self.correlation_id = ''
def on_response(self, ch, method, properties, body):
"""
处理响应信息
:param ch:
:param method:
:param properties:从属性中获取correlation_id
:param body: 获取响应信息的内容
:return:
"""
# 当请求的唯一值相同则获取响应信息
if self.correlation_id == properties.correlation_id:
self.response = body
def call(self, n):
"""
Fib客户端发送请求
:param n:
:return:
"""
self.response = None
self.correlation_id = str(uuid.uuid4()) # 唯一的ID
# 发送请求到server端
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue, # 指定回调队列
correlation_id=self.correlation_id # 使请求唯一
),
body=str(n))
# 等待server的响应
while self.response is None:
self.connecion.process_data_events()
return int(self.response)
fib_rpc = FibRPCClient()
print('[x] Requesting fib(30)')
response = fib_rpc.call(30)
print(f'[.] Got %s ' % response)
fib_rpc.connecion.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号