数据库学习之MySQL进阶
数据库进阶
一、视图
数据库视图是虚拟表或逻辑表,它被定义为具有连接的SQL SELECT查询语句。其本质是为常用的查询语句起个别名。用户使用时只需使用【名称】即可获取结果集,并可以将其当作表来使用。不是真正存在。视图存在数据库中。
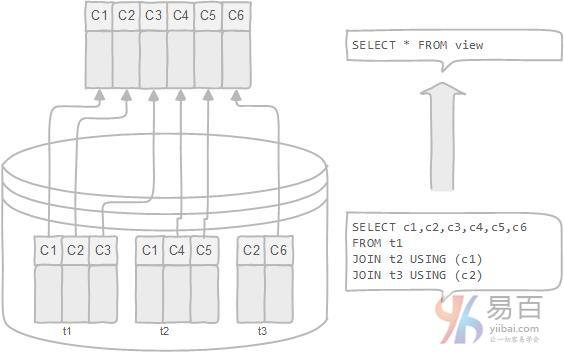
数据库视图是动态的,因为它与物理模式无关。数据库系统将数据库视图存储为具有连接的SQL SELECT语句。当表的数据发生变化时,视图也反映了这些数据的变化。
数据库视图的优点
- 简单:使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件,对用户来说已经是过滤好的复合条件的结果集。
- 安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权限管理并不能限制到某个行某个列,但是通过视图就可以简单的实现。
- 数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加列对视图没有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
总而言之,使用视图的大部分情况是为了保障数据安全性,提高查询效率。
数据库视图的缺点
除了上面的优点,使用数据库视图有几个缺点:
- 性能:从数据库视图查询数据可能会很慢,特别是如果视图是基于其他视图创建的。
- 表依赖关系:将根据数据库的基础表创建一个视图。每当更改与其相关联的表的结构时,都必须更改视图。
一、创建视图


CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
1 参数解释
2 1)OR REPLACE:表示替换已有视图
3 2)ALGORITHM:表示视图选择算法,默认算法是UNDEFINED(未定义的):MySQL自动选择要使用的算法 ;merge合并;temptable临时表
4 3)select_statement:表示select语句
5 4)[WITH [CASCADED | LOCAL] CHECK OPTION]:表示视图在更新时保证在视图的权限范围之内
6 cascade是默认值,表示更新视图的时候,要满足视图和表的相关条件
7 local表示更新视图的时候,要满足该视图定义的一个条件即可
8 TIPS:推荐使用WHIT [CASCADED|LOCAL] CHECK OPTION选项,可以保证数据的安全性
基本格式:
create view <视图名称>[(column_list)]
as select语句
with check option;
mysql> create view v_F_players(编号,名字,性别,电话)
-> as
-> select PLAYERNO,NAME,SEX,PHONENO from PLAYERS
-> where SEX='F'
-> with check option;
Query OK, 0 rows affected (0.00 sec)
mysql> desc v_F_players;
+--------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+----------+------+-----+---------+-------+
| 编号 | int(11) | NO | | NULL | |
| 名字 | char(15) | NO | | NULL | |
| 性别 | char(1) | NO | | NULL | |
| 电话 | char(13) | YES | | NULL | |
+--------+----------+------+-----+---------+-------+
4 rows in set (0.00 sec)
mysql> select * from v_F_players;
+--------+-----------+--------+------------+
| 编号 | 名字 | 性别 | 电话 |
+--------+-----------+--------+------------+
| 8 | Newcastle | F | 070-458458 |
| 27 | Collins | F | 079-234857 |
| 28 | Collins | F | 010-659599 |
| 104 | Moorman | F | 079-987571 |
| 112 | Bailey | F | 010-548745 |
+--------+-----------+--------+------------+
5 rows in set (0.02 sec)
mysql> create view v_match
-> as
-> select a.PLAYERNO,a.NAME,MATCHNO,WON,LOST,c.TEAMNO,c.DIVISION
-> from
-> PLAYERS a,MATCHES b,TEAMS c
-> where a.PLAYERNO=b.PLAYERNO and b.TEAMNO=c.TEAMNO;
Query OK, 0 rows affected (0.03 sec)
mysql> select * from v_match;
+----------+-----------+---------+-----+------+--------+----------+
| PLAYERNO | NAME | MATCHNO | WON | LOST | TEAMNO | DIVISION |
+----------+-----------+---------+-----+------+--------+----------+
| 6 | Parmenter | 1 | 3 | 1 | 1 | first |
| 44 | Baker | 4 | 3 | 2 | 1 | first |
| 83 | Hope | 5 | 0 | 3 | 1 | first |
| 112 | Bailey | 12 | 1 | 3 | 2 | second |
| 8 | Newcastle | 13 | 0 | 3 | 2 | second |
+----------+-----------+---------+-----+------+--------+----------+
5 rows in set (0.04 sec)
- 视图将我们不需要的数据过滤掉,将相关的列名用我们自定义的列名替换。视图作为一个访问接口,不管基表的表结构和表名有多复杂。
- 如果创建视图时不明确指定视图的列名,那么列名就和定义视图的select子句中的列名完全相同;
- 如果显式的指定视图的列名就按照指定的列名。
注意:显示指定视图列名,要求视图名后面的列的数量必须匹配select子句中的列的数量。
二、查看视图
1、使用show create view语句查看视图信息
1 mysql> show create view v_F_players\G;
2 *************************** 1. row ***************************
3 View: v_F_players
4 Create View: CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL SECURITY DEFINER VIEW `v_F_players` AS select `PLAYERS`.`PLAYERNO` AS `编号`,`PLAYERS`.`NAME` AS `名字`,`PLAYERS`.`SEX` AS `性别`,`PLAYERS`.`PHONENO` AS `电话` from `PLAYERS` where (`PLAYERS`.`SEX` = 'F') WITH CASCADED CHECK OPTION
5 character_set_client: utf8
6 collation_connection: utf8_general_ci
7 1 row in set (0.00 sec)
2、视图一旦创建完毕,就可以像一个普通表那样使用,视图主要用来查询
mysql> select * from view_name;
3、有关视图的信息记录在information_schema数据库中的views表中
1 mysql> select * from information_schema.views
2 -> where TABLE_NAME='v_F_players'\G;
3 *************************** 1. row ***************************
4 TABLE_CATALOG: def
5 TABLE_SCHEMA: TENNIS
6 TABLE_NAME: v_F_players
7 VIEW_DEFINITION: select `TENNIS`.`PLAYERS`.`PLAYERNO` AS `编号`,`TENNIS`.`PLAYERS`.`NAME` AS `名字`,`TENNIS`.`PLAYERS`.`SEX` AS `性别`,`TENNIS`.`PLAYERS`.`PHONENO` AS `电话` from `TENNIS`.`PLAYERS` where (`TENNIS`.`PLAYERS`.`SEX` = 'F')
8 CHECK_OPTION: CASCADED
9 IS_UPDATABLE: YES
10 DEFINER: root@localhost
11 SECURITY_TYPE: DEFINER
12 CHARACTER_SET_CLIENT: utf8
13 COLLATION_CONNECTION: utf8_general_ci
14 1 row in set (0.00 sec)
三、视图的更改
1、CREATE OR REPLACE VIEW语句修改视图
基本格式:
create or replace view view_name as select语句;
在视图存在的情况下可对视图进行修改,视图不在的情况下可创建视图
2、ALTER语句修改视图
ALTER
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
[DEFINER = { user | CURRENT_USER }]
[SQL SECURITY { DEFINER | INVOKER }]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
注意:修改视图是指修改数据库中已存在的表的定义,当基表的某些字段发生改变时,可以通过修改视图来保持视图和基本表之间一致
3、DML操作更新视图
因为视图本身没有数据,因此对视图进行的dml操作最终都体现在基表中
DML更新视图当然,视图的DML操作,不是所有的视图都可以做DML操作。
①select子句中包含distinct
②select子句中包含组函数
③select语句中包含group by子句
④select语句中包含order by子句
⑤select语句中包含union 、union all等集合运算符
⑥where子句中包含相关子查询
⑦from子句中包含多个表
⑧如果视图中有计算列,则不能更新
⑨如果基表中有某个具有非空约束的列未出现在视图定义中,则不能做insert操作
4、drop删除视图
DROP VIEW [IF EXISTS]
view_name [, view_name] ...
mysql> drop view v_student;
- 注:如果视图不存在,则抛出异常;使用IF EXISTS选项使得删除不存在的视图时不抛出异常。
四、使用WITH CHECK OPTION约束
对于可以执行DML操作的视图,定义时可以带上WITH CHECK OPTION约束
作用:
对视图所做的DML操作的结果,不能违反视图的WHERE条件的限制。
示例:创建视图,包含1960年之前出生的所有球员(老兵)
mysql> create view v_veterans
-> as
-> select * from PLAYERS
-> where birth_date < '1960-01-01'
-> with check option;
Query OK, 0 rows affected (0.01 sec)
mysql> select * from v_veterans;
+----------+---------+----------+------------+-----+--------+----------------+---------+----------+-----------+------------+----------+
| PLAYERNO | NAME | INITIALS | BIRTH_DATE | SEX | JOINED | STREET | HOUSENO | POSTCODE | TOWN | PHONENO | LEAGUENO |
+----------+---------+----------+------------+-----+--------+----------------+---------+----------+-----------+------------+----------+
| 2 | Everett | R | 1948-09-01 | M | 1975 | Stoney Road | 43 | 3575NH | Stratford | 070-237893 | 2411 |
| 39 | Bishop | D | 1956-10-29 | M | 1980 | Eaton Square | 78 | 9629CD | Stratford | 070-393435 | NULL |
| 83 | Hope | PK | 1956-11-11 | M | 1982 | Magdalene Road | 16A | 1812UP | Stratford | 070-353548 | 1608 |
+----------+---------+----------+------------+-----+--------+----------------+---------+----------+-----------+------------+----------+
3 rows in set (0.02 sec)
mysql> update v_veterans
-> set BIRTH_DATE='1970-09-01'
-> where PLAYERNO=39;
ERROR 1369 (HY000): CHECK OPTION failed 'TENNIS.v_veterans'
- 因为违反了视图中的WHERE birth_date < '1960-01-01'子句,所以抛出异常;
- 利用with check option约束限制,保证更新视图是在该视图的权限范围之内。
嵌套视图:定义在另一个视图的上面的视图
mysql> create view v_ear_veterans
-> as
-> select * from v_veterans
-> where JOINED < 1980;
使用WITH CHECK OPTION约束时,(不指定选项则默认是CASCADED)
可以使用CASCADED或者 LOCAL选项指定检查的程度:
WITH CASCADED CHECK OPTION:检查所有的视图
例如:嵌套视图及其底层的视图
WITH LOCAL CHECK OPTION:只检查将要更新的视图本身
例如:对嵌套视图不检查其底层的视图
五、定义视图时的其他选项
CREATE [OR REPLACE]
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
[DEFINER = { user | CURRENT_USER }]
[SQL SECURITY { DEFINER | INVOKER }]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
1、ALGORITHM选项:选择在处理定义视图的select语句中使用的方法
①UNDEFINED:MySQL将自动选择所要使用的算法
②MERGE:将视图的语句与视图定义合并起来,使得视图定义的某一部分取代语句的对应部分
③TEMPTABLE:将视图的结果存入临时表,然后使用临时表执行语句
缺省ALGORITHM选项等同于ALGORITHM = UNDEFINED
2、DEFINER选项:指出谁是视图的创建者或定义者
①definer= '用户名'@'登录主机'
②如果不指定该选项,则创建视图的用户就是定义者,指定关键字CURRENT_USER(当前用户)和不指定该选项效果相同
3、SQL SECURITY选项:要查询一个视图,首先必须要具有对视图的select权限。
但是,如果同一个用户对于视图所访问的表没有select权限,那会怎么样?
SQL SECURITY选项决定执行的结果:
①SQL SECURITY DEFINER:定义(创建)视图的用户必须对视图所访问的表具有select权限,也就是说将来其他用户访问表的时候以定义者的身份,此时其他用户并没有访问权限。
②SQL SECURITY INVOKER:访问视图的用户必须对视图所访问的表具有select权限。
缺省SQL SECURITY选项等同于SQL SECURITY DEFINER
视图权限总结:
使用root用户定义一个视图(推荐使用第一种):u1、u2
1)u1作为定义者定义一个视图,u1对基表有select权限,u2对视图有访问权限:u2是以定义者的身份访问可以查询到基表的内容;
2)u1作为定义者定义一个视图,u1对基表没有select权限,u2对视图有访问权限,u2对基表有select权限:u2访问视图的时候是以调用者的身份,此时调用者是u2,可以查询到基表的内容。
六、视图查询语句的处理
示例:所有有罚款的球员的信息
mysql> create view cost_raisers
-> as
-> select * from PLAYERS
-> where playerno in (select playerno from PENALTIES);
mysql> select playerno from cost_raisers
-> where town='Stratford';
+----------+
| PLAYERNO |
+----------+
| 6 |
+----------+
# 先把select语句中的视图名使用定义视图的select语句来替代;
# 再处理所得到的select语句。
mysql> select playerno from
-> (
-> select * from PLAYERS
-> where playerno in-> (select playerno from PENALTIES)
-> )as viewformula
-> where town='Stratford';
+----------+
| PLAYERNO |
+----------+
| 6 |
+----------+
先处理定义视图的select语句,这会生成一个中间的结果集;
然后,再在中间结果上执行select查询。
mysql> select <列名> from <中间结果>;
二、存储过程
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
优点
- 存储过程可封装,并隐藏复杂的商业逻辑。
- 存储过程可以回传值,并可以接受参数。
- 存储过程无法使用 SELECT 指令来运行,因为它是子程序,与查看表,数据表或用户定义函数不同。
- 存储过程可以用在数据检验,强制实行商业逻辑等。
缺点
- 存储过程,往往定制化于特定的数据库上,因为支持的编程语言不同。当切换到其他厂商的数据库系统时,需要重写原有的存储过程。
- 存储过程的性能调校与撰写,受限于各种数据库系统。
一.创建存储过程 create procedure sp_name() begin ......... end
二.调用存储过程 1.基本语法:call sp_name() 注意:存储过程名称后面必须加括号,哪怕该存储过程没有参数传递
三.删除存储过程 1.基本语法: drop procedure sp_name//
2.注意事项 (1)不能在一个存储过程中删除另一个存储过程,只能调用另一个存储过程
四.其他常用命令
1.show procedure status 显示数据库中所有存储的存储过程基本信息,包括所属数据库,存储过程名称,创建时间等
2.show create procedure sp_name 显示某一个MySQL存储过程的详细信息
五、存储过程实例
1、创建存储过程
-- 创建存储过程
delimiter //
create procedure p1()
BEGIN
select * from t1;
END//
delimiter ;
-- 执行存储过程
call p1()
无参数存储过程
对于存储过程,可以接收参数,其参数有三类:
- in 仅用于传入参数用
- out 仅用于返回值用
- inout 既可以传入又可以当作返回值
-- 创建存储过程
delimiter \\
create procedure p1(
in i1 int,
in i2 int,
inout i3 int,
out r1 int
)
BEGIN
DECLARE temp1 int;
DECLARE temp2 int default 0;
set temp1 = 1;
set r1 = i1 + i2 + temp1 + temp2;
set i3 = i3 + 100;
end\\
delimiter ;
-- 执行存储过程
set @t1 =4;
set @t2 = 0;
CALL p1 (1, 2 ,@t1, @t2);
SELECT @t1,@t2;
有参数的存储过程
delimiter //
create procedure p1()
begin
select * from v1;
end //
delimiter ;
delimiter //
create procedure p2(
in n1 int,
inout n3 int,
out n2 int,
)
begin
declare temp1 int ;
declare temp2 int default 0;
select * from v1;
set n2 = n1 + 100;
set n3 = n3 + n1 + 100;
end //
delimiter ;
2. 结果集+out值
delimiter \\
create PROCEDURE p1(
OUT p_return_code tinyint
)
BEGIN
DECLARE exit handler for sqlexception
BEGIN
-- ERROR
set p_return_code = 1;
rollback;
END;
DECLARE exit handler for sqlwarning
BEGIN
-- WARNING
set p_return_code = 2;
rollback;
END;
START TRANSACTION;
DELETE from tb1;
insert into tb2(name)values('seven');
COMMIT;
-- SUCCESS
set p_return_code = 0;
END\\
delimiter ;
delimiter //
create procedure p3()
begin
declare ssid int; -- 自定义变量1
declare ssname varchar(50); -- 自定义变量2
DECLARE done INT DEFAULT FALSE;
DECLARE my_cursor CURSOR FOR select sid,sname from student;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
open my_cursor;
xxoo: LOOP
fetch my_cursor into ssid,ssname;
if done then
leave xxoo;
END IF;
insert into teacher(tname) values(ssname);
end loop xxoo;
close my_cursor;
end //
delimter ;
delimiter \\
CREATE PROCEDURE p4 (
in nid int
)
BEGIN
PREPARE prod FROM 'select * from student where sid > ?';
EXECUTE prod USING @nid;
DEALLOCATE prepare prod;
END\\
delimiter ;
5. 动态执行SQL
2、删除存储过程
drop procedure proc_name;
3、执行存储过程
-- 无参数
call proc_name()
-- 有参数,全in
call proc_name(1,2)
-- 有参数,有in,out,inout
set @t1=0;
set @t2=3;
call proc_name(1,2,@t1,@t2)
执行存储过程
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 执行存储过程
cursor.callproc('p1', args=(1, 22, 3, 4))
# 获取执行完存储的参数
cursor.execute("select @_p1_0,@_p1_1,@_p1_2,@_p1_3")
result = cursor.fetchall()
conn.commit()
cursor.close()
conn.close()
print(result)
pymysql执行存储过程
三、触发器
如果希望在对某张表的增、删、改的前后进行触发某个特定的行为时,可以使用触发器来自定义操作,触发器用于定制用户对表的行进行【增/删/改】前后的行为。
创建触发器
在MySQL中,创建触发器语法如下:
CREATE TRIGGER trigger_name
trigger_time
trigger_event ON tbl_name
FOR EACH ROW
trigger_stmt
trigger_name:标识触发器名称,用户自行指定;
trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句。
由此可见,可以建立6种触发器,即:BEFORE INSERT、BEFORE UPDATE、BEFORE DELETE、AFTER INSERT、AFTER UPDATE、AFTER DELETE。
另外有一个限制是不能同时在一个表上建立2个相同类型的触发器,因此在一个表上最多建立6个触发器。
trigger_event 详解
MySQL 除了对 INSERT、UPDATE、DELETE 基本操作进行定义外,还定义了 LOAD DATA 和 REPLACE 语句,这两种语句也能引起上述6中类型的触发器的触发。
LOAD DATA 语句用于将一个文件装入到一个数据表中,相当与一系列的 INSERT 操作。
REPLACE 语句一般来说和 INSERT 语句很像,只是在表中有 primary key 或 unique 索引时,如果插入的数据和原来 primary key 或 unique 索引一致时,会先删除原来的数据,然后增加一条新数据,也就是说,一条 REPLACE 语句有时候等价于一条。
INSERT 语句,有时候等价于一条 DELETE 语句加上一条 INSERT 语句。
INSERT 型触发器:插入某一行时激活触发器,可能通过 INSERT、LOAD DATA、REPLACE 语句触发;
UPDATE 型触发器:更改某一行时激活触发器,可能通过 UPDATE 语句触发;
DELETE 型触发器:删除某一行时激活触发器,可能通过 DELETE、REPLACE 语句触发。
BEGIN … END 详解
在MySQL中,BEGIN … END 语句的语法为:
BEGIN
[statement_list]
END
其中,statement_list 代表一个或多个语句的列表,列表内的每条语句都必须用分号(;)来结尾。
而在MySQL中,分号是语句结束的标识符,遇到分号表示该段语句已经结束,MySQL可以开始执行了。因此,解释器遇到statement_list 中的分号后就开始执行,然后会报出错误,因为没有找到和 BEGIN 匹配的 END。
这时就会用到 DELIMITER 命令(DELIMITER 是定界符,分隔符的意思),它是一条命令,不需要语句结束标识,语法为:
DELIMITER new_delemiter
new_delemiter 可以设为1个或多个长度的符号,默认的是分号(;),我们可以把它修改为其他符号,如$:
DELIMITER $
在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了$,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。
# 假设系统中有两个表:
# 班级表 class(班级号 classID, 班内学生数 stuCount)
# 学生表 student(学号 stuID, 所属班级号 classID)
# 要创建触发器来使班级表中的班内学生数随着学生的添加自动更新,代码如下:
DELIMITER $
create trigger tri_stuInsert after insert
on student for each row
begin
declare c int;
set c = (select stuCount from class where classID=new.classID);
update class set stuCount = c + 1 where classID = new.classID;
end$
DELIMITER ;
MySQL 中使用 DECLARE 来定义一局部变量,该变量只能在 BEGIN … END 复合语句中使用,并且应该定义在复合语句的开头,
即其它语句之前,语法如下:
DECLARE var_name[,...] type [DEFAULT value]
其中:
var_name 为变量名称,同 SQL 语句一样,变量名不区分大小写;type 为 MySQL 支持的任何数据类型;可以同时定义多个同类型的变量,用逗号隔开;变量初始值为 NULL,如果需要,可以使用 DEFAULT 子句提供默认值,值可以被指定为一个表达式。
在 INSERT 型触发器中,NEW 用来表示将要(BEFORE)或已经(AFTER)插入的新数据;
在 UPDATE 型触发器中,OLD 用来表示将要或已经被修改的原数据,NEW 用来表示将要或已经修改为的新数据;
在 DELETE 型触发器中,OLD 用来表示将要或已经被删除的原数据;
使用方法: NEW.columnName (columnName 为相应数据表某一列名)
另外,OLD 是只读的,而 NEW 则可以在触发器中使用 SET 赋值,这样不会再次触发触发器,造成循环调用(如每插入一个学生前,都在其学号前加“2013”)。
SET var_name = expr [,var_name = expr] ...
查看触发器
SHOW TRIGGERS [FROM schema_name];
# 其中,schema_name 即 Schema 的名称,在 MySQL 中 Schema 和 Database 是一样的,也就是说,可以指定数据库名,这样就
# 不必先“USE database_name;”了。
删除触发器
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name
触发器的执行顺序
我们建立的数据库一般都是 InnoDB 数据库,其上建立的表是事务性表,也就是事务安全的。这时,若SQL语句或触发器执行失败,MySQL 会回滚事务,有:
- 如果 BEFORE 触发器执行失败,SQL 无法正确执行。
- SQL 执行失败时,AFTER 型触发器不会触发。
- AFTER 类型的触发器执行失败,SQL 会回滚。
四、索引
1.索引简介:索引是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据。对于索引,会保存在额外的文件中。
2.索引作用:加速查找+约束
3.索引种类:
主键索引:加速查找、不重复、非空
唯一索引:加速查找、不重复
普通索引:加速查找
联合索引:加速查找
联合唯一索引:加速查找、不重复
PS:联合索引遵循最左前缀原则
id name pwd email 假设name,pwd,email 建立联合索引
select * from name='xx'; 命中索引
select * from name='xx' and pwd='123'; 命中索引
select * from name='xx' and pwd='123' and email='qq'; 命中索引
select * from name='xx' and emai='qq'; 命中索引
select * from email='qq' and pwd='123'; 不能命中索引
覆盖索引:select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖,如索引为name,也仅查找name列
索引合并:使用多个单列索引去查找数据,如name和age 都为索引,使用name和age联合查询
4.创建索引语法
--创建表时
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
);
CREATE TABLE test2(
id INT,
name VARCHAR(20),
INDEX index_name (name)
);
---CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
---ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
CREATE INDEX index_emp_name on emp1(name);
ALTER TABLE emp2 ADD UNIQUE INDEX index_bank_num(band_num);
# 语法:DROP INDEX 索引名 on 表名
DROP INDEX index_emp_name on emp1;
DROP INDEX bank_num on emp2;
5.索引测试实验
--创建表
create table t1(id int,name varchar(20));
--存储过程
delimiter $$
create procedure autoinsert()
BEGIN
declare i int default 1;
while(i<5000)do
insert into t1 values(i,'yuan');
set i=i+1;
end while;
END$$
delimiter ;
--调用函数
call autoinsert();
-- 花费时间比较:
-- 创建索引前
select * from t1 where id=300000;--0.32s
-- 添加索引
create index index_id on t1(id);
-- 创建索引后
select * from Indexdb.t1 where id=300000;--0.00s
--删除索引
drop index index_id on t1;
use crawed;
desc doutula;
select count(*) from doutula;
+----------+
| count(*) |
+----------+
| 27308 |
+----------+
select name from doutula where name like '%坏蛋%';
--34 rows in set (0.53 sec)
create index index_name on doutula (name);
select name from doutula where name like '%坏蛋%';
--34 rows in set (0.05 sec)
6.正确使用索引 数据库表中添加索引后确实会让查询速度起飞,但前提必须是正确的使用索引来查询,如果以错误的方式使用,则即使建立索引也会不奏效。 即使建立索引,索引也不会生效:
like '%xx'
select * from tb1 where name like '%cn';
- 使用函数
select * from tb1 where reverse(name) = 'wupeiqi';
- or
select * from tb1 where nid = 1 or email = 'seven@live.com';
特别的:当or条件中有未建立索引的列才失效,以下会走索引
select * from tb1 where nid = 1 or name = 'seven';
select * from tb1 where nid = 1 or email = 'seven@live.com' and name = 'alex'
- 类型不一致
如果列是字符串类型,传入条件是必须用引号引起来,不然...
select * from tb1 where name = 999;
- !=
select * from tb1 where name != 'alex'
特别的:如果是主键,则还是会走索引
select * from tb1 where nid != 123
- >
select * from tb1 where name > 'alex'
特别的:如果是主键或索引是整数类型,则还是会走索引
select * from tb1 where nid > 123
select * from tb1 where num > 123
- order by
select email from tb1 order by name desc;
当根据索引排序时候,选择的映射如果不是索引,则不走索引
特别的:如果对主键排序,则还是走索引:
select * from tb1 order by nid desc;
- 组合索引最左前缀
如果组合索引为:(name,email)
name and email -- 使用索引
name -- 使用索引
email -- 不使用索引
五、函数
mysql提供了许多内置函数
CHAR_LENGTH(str)
返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。
对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。
CONCAT(str1,str2,...)
字符串拼接
如有任何一个参数为NULL ,则返回值为 NULL。
CONCAT_WS(separator,str1,str2,...)
字符串拼接(自定义连接符)
CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
CONV(N,from_base,to_base)
进制转换
例如:
SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示
FORMAT(X,D)
将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。
例如:
SELECT FORMAT(12332.1,4); 结果为: '12,332.1000'
INSERT(str,pos,len,newstr)
在str的指定位置插入字符串
pos:要替换位置其实位置
len:替换的长度
newstr:新字符串
特别的:
如果pos超过原字符串长度,则返回原字符串
如果len超过原字符串长度,则由新字符串完全替换
INSTR(str,substr)
返回字符串 str 中子字符串的第一个出现位置。
LEFT(str,len)
返回字符串str 从开始的len位置的子序列字符。
LOWER(str)
变小写
UPPER(str)
变大写
LTRIM(str)
返回字符串 str ,其引导空格字符被删除。
RTRIM(str)
返回字符串 str ,结尾空格字符被删去。
SUBSTRING(str,pos,len)
获取字符串子序列
LOCATE(substr,str,pos)
获取子序列索引位置
REPEAT(str,count)
返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。
若 count <= 0,则返回一个空字符串。
若str 或 count 为 NULL,则返回 NULL 。
REPLACE(str,from_str,to_str)
返回字符串str 以及所有被字符串to_str替代的字符串from_str 。
REVERSE(str)
返回字符串 str ,顺序和字符顺序相反。
RIGHT(str,len)
从字符串str 开始,返回从后边开始len个字符组成的子序列
SPACE(N)
返回一个由N空格组成的字符串。
SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len)
不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。
mysql> SELECT SUBSTRING('Quadratically',5);
-> 'ratically'
mysql> SELECT SUBSTRING('foobarbar' FROM 4);
-> 'barbar'
mysql> SELECT SUBSTRING('Quadratically',5,6);
-> 'ratica'
mysql> SELECT SUBSTRING('Sakila', -3);
-> 'ila'
mysql> SELECT SUBSTRING('Sakila', -5, 3);
-> 'aki'
mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2);
-> 'ki'
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str)
返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。
mysql> SELECT TRIM(' bar ');
-> 'bar'
mysql> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx');
-> 'barxxx'
mysql> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx');
-> 'bar'
mysql> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz');
-> 'barx'
部分内置函数
delimiter \\
create function f1(
i1 int,
i2 int)
returns int
BEGIN
declare num int;
set num = i1 + i2;
return(num);
END \\
delimiter ;
drop function func_name;
# 获取返回值
declare @i VARCHAR(32);
select UPPER('alex') into @i;
SELECT @i;
# 在查询中使用
select f1(11,nid) ,name from tb2;
mysql> select concat('M','y','SQL');
+-----------------------+
| concat('M','y','SQL') |
+-----------------------+
| MySQL |
+-----------------------+
1 row in set (0.00 sec)
mysql> select concat('M','y','SQL','5.7');
+-----------------------------+
| concat('M','y','SQL','5.7') |
+-----------------------------+
| MySQL5.7 |
+-----------------------------+
1 row in set (0.00 sec)
mysql> select concat('M','y','SQL',' 5.7');
+------------------------------+
| concat('M','y','SQL',' 5.7') |
+------------------------------+
| MySQL 5.7 |
+------------------------------+
1 row in set (0.00 sec)
mysql> SELECT concat_ws("-",'2012','09');
+----------------------------+
| concat_ws("-",'2012','09') |
+----------------------------+
| 2012-09 |
+----------------------------+
1 row in set (0.00 sec)
mysql> SELECT concat_ws(":",'2012','09');
+----------------------------+
| concat_ws(":",'2012','09') |
+----------------------------+
| 2012:09 |
+----------------------------+
1 row in set (0.00 sec)
mysql> SELECT concat_ws("-:",'2012','09');
+-----------------------------+
| concat_ws("-:",'2012','09') |
+-----------------------------+
| 2012-:09 |
+-----------------------------+
1 row in set (0.00 sec)
mysql> SELECT concat_ws(":-",'2012','09');
+-----------------------------+
| concat_ws(":-",'2012','09') |
+-----------------------------+
| 2012:-09 |
+-----------------------------+
1 row in set (0.00 sec)
mysql> SELECT concat_ws(null,'2012','09');
+-----------------------------+
| concat_ws(null,'2012','09') |
+-----------------------------+
| NULL |
+-----------------------------+
1 row in set (0.00 sec)
mysql> select concat(1,2);
+-------------+
| concat(1,2) |
+-------------+
| 12 |
+-------------+
1 row in set (0.00 sec)
mysql> select strcmp('ac','ac');
+-------------------+
| strcmp('ac','ac') |
+-------------------+
| 0 |
+-------------------+
1 row in set (0.06 sec)
mysql> select strcmp('ab','ac');
+-------------------+
| strcmp('ab','ac') |
+-------------------+
| -1 |
+-------------------+
1 row in set (0.00 sec)
mysql> select strcmp('ac','ab');
+-------------------+
| strcmp('ac','ab') |
+-------------------+
| 1 |
+-------------------+
1 row in set (0.00 sec)
mysql> help length;
Name: 'LENGTH'
Description:
Syntax:
LENGTH(str)
Returns the length of the string str, measured in bytes. A multibyte
character counts as multiple bytes. This means that for a string
containing five 2-byte characters, LENGTH() returns 10, whereas
CHAR_LENGTH() returns 5.
URL: http://dev.mysql.com/doc/refman/5.7/en/string-functions.html
Examples:
mysql> SELECT LENGTH('text');
-> 4
mysql> select length('1 2');
+---------------+
| length('1 2') |
+---------------+
| 3 |
+---------------+
1 row