
机器学习&数据挖掘笔记_24(PGM练习八:结构学习)
前言:
本次实验包含了2部分:贝叶斯模型参数的学习以及贝叶斯模型结构的学习,在前面的博文PGM练习七:CRF中参数的学习 中我们已经知道怎样学习马尔科夫模型(CRF)的参数,那个实验采用的是优化方法,而这里贝叶斯模型参数的学习是先假定样本符合某种分布,然后使用统计的方法去学习这些分布的参数,来达到学习模型参数的目的。实验内容请参考 coursera课程:Probabilistic Graphical Models 中的assignmnet 8,实验code可参考网友的:code
实验中所用到的body pose表现形式如下:
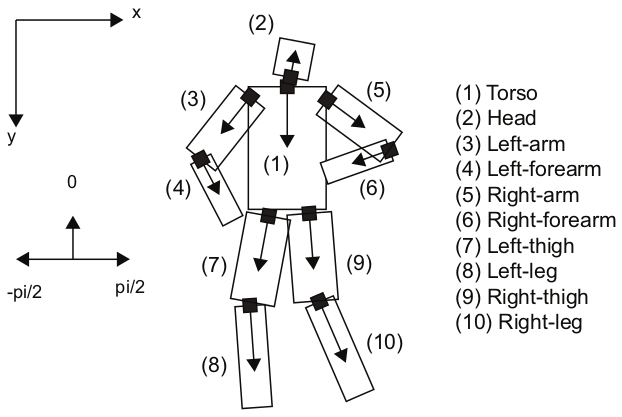
共有10个节点,每个节点由2个坐标变量和1个方向变量构成。关节名称和坐标系可直接参考上图。
matlab知识:
cov(x): 求的是X无偏差的协方差,即分母除的是n-1.
cov(X,1):求的是X的最大似然估计协方差,即分母除的是n.
实验中一些函数简单说明:
[mu sigma] = FitGaussianParameters(X):
实验1内容。输入X是一个向量,该函数是计算X的均值和标准差,直接按照均值方程公式计算就OK了。
[Beta sigma] = FitLinearGaussianParameters(X, U):
实验2内容。X: 大小为(M x 1),表示输入的样本向量X含有M个样本,是树结构中的子节点。U: 大小为(M x N), 表示有N个父节点,每个父节点也对应M个样本。该函数主要是计算N+1个beta系数和一个sigma系数,其计算方法可参考前面的公式。给出本节点的数据和其所有父节点的数据,就可以计算出在父节点下的条件概率参数。本实验中,如果某个节点只含有一个父节点,在使用公式计算时也相当于有3个父节点,这是因为每个节点由3个维度构成,需4个参数。
关于CLG(conditional linear Gaussian)模型有:
如果节点X有n个父节点U1..Un,则条件概率为:
![]()
求出样本的log似然表达式,然后分别这些表达式中的n+1个参数求导,令导数为0,化简后可得到n+1个方程,其中与X直接相关的为:
![]()
其它X分别与n个父节点相关的方程为:
![]()
利用上面n+1个方程就可以求出Beta的n+1个参数了,最后将log似然函数对sigda求导,并化简有下面式子(怎么我推导出来不同呢):
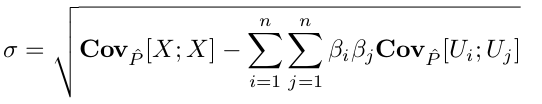
这样的话,CLG模型中所有的参数都可以从数据样本中学到了。
VisualizeDataset(Dataset):
DataSet大小为n*10*3,即有n个样本,每个样本包含了骨架中的10个节点信息。该函数是将这n个样本对应的骨架图一张张显示出来,有动画感,大家可以跑一下, 有点意思。
val = lognormpdf(x, mu, sigma):
求高斯分布在x处的log值,高斯分布的参数为mu和sigma,可以是多维的高斯分布。
loglikelihood = ComputeLogLikelihood(P, G, dataset):
实验3的内容。P为模型参数的结构体,P.c为长度为2的向量,其值分别代表human和alien的先验概率。P.clg为CLG模型中的参数,包含有mu_x, mu_y, mu_angle, sigma_x, sigma_y, sigma_angle, 以及theta(theta长度为12,因为每个节点有3个坐标信息,而每个坐标在其父节点情况下需4个参数表示). 当然P.clg中应该同时包含human和alien的这些参数。参数G为父节点的描述,具体表示细节可参考实验教材。dataset为训练样本,大小为N x 10 x 3. 输出参数loglikelihood为整个dataset在模型下的log似然值。似然函数值表示模型对数据的拟合程度,可作为后续样本分类的依据。loglikeihood的值按下列公式计算:
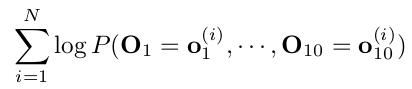
其中的联合概率可以按类别的全概率公式分解计算,如下:
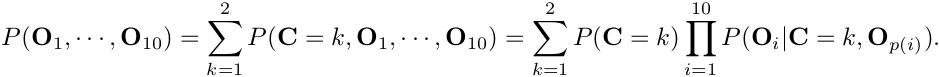
[P loglikelihood] = LearnCPDsGivenGraph(dataset, G, labels):
实验4的内容。在实验3中,我们是已知了每个节点的CLG参数,然后求在这些参数下数据的似然值的。那么这些参数到底怎样得到呢?本函数就是完成该功能的。对每个节点的3个坐标而言,每次计算一个坐标对应的CLG参数,使用的样本为:该数据对应的样本以及其父节点对应样本(包含全部3个坐标),然后调用FitLinearGaussianParameters()来计算模型参数,结果都保存在P中,另外输出的loglikelihood是直接调用ComputeLogLikelihood()来函数实现。
accuracy = ClassifyDataset(dataset, labels, P, G):
实验5的内容。给定样本dataset和标签labels,给定模型结构G,给定模型参数P,求对应样本分类的正确率。实现时需记住:有多少个类别,相当于计算了多少个模型,计算哪个模型下产生该样本的概率大,就将该样本分类为对应的类别。
I = GaussianMutualInformation(X, Y):
输入的矩阵X大小为N*D1,表示N个样本,每个样本D1维;矩阵Y大小为N*D2,同样表示N个样本,每个样本D2维。这两个矩阵X和Y的每一维样本都服从高斯分布。该函数是计算两个多维高斯分布样本的互信息(互信息是个标量,如果2个矩阵相同,则互信息为0),计算公式如下:
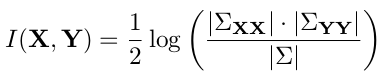
adj = MaxSpanningTree (weights):
weights为N*N大小的对称矩阵,weights(I,j)的值表示节点i和节点j之间的权重。返回的adj也是一个N*N大小的矩阵,但不是对称矩阵。adj(I,j)=1表示有从节点i指向节点j的边。该函数的功能就是从权值矩阵中学出tree的结构,并输出。
[A W] = LearnGraphStructure(dataset):
实验6的内容。该函数是从样本矩阵dataset(没有使用标签信息)中学习模型的权值矩阵W和模型的树形结构矩阵A.其中每条边的权值计算公式如下:
![]()
该公式第一个等号的推导过程可参考Daphne Koller,Probabilistic Graphical Models Principles and Techniques书籍第18章的18.4小节。它的物理意义是:在i和j之间加入边前后得分score的变化量,如果为正,则表示加入该边后score增加,且说明该结构有利,score增加越大,结构就越有利。第二个等号的推导可参考coursera课程:Probabilistic Graphical Models 在structure learning课件中的第7页,等号成立是在likelihood score前提下。
G = ConvertAtoG(A):
该函数是将max spanning tree A转换为图的结构矩阵G,G的含义与前面的一样。
[P G loglikelihood] = LearnGraphAndCPDs(dataset, labels):
实验7的内容。该函数实现的是使用dataset学习模型的结构,然后结合labels来学习模型的参数,最后利用该参数来计算样本的log似然。
相关理论知识点:
这部分可参考Corsera中的课件以及网友demonstrate的blog:PGM 读书笔记节选(十五)
Structure learning的好处有:可发现数据中的相关信息;当专业领域的知识不完善而建立不起完全正确的graph model时可采用。structure learning常见的有2种:constraint-based structure learning和score-based structure learning,BNs结构学习中一般采用后面那种比较多,即在预设的几个结构中找出得分最高的那个(通过 搜索)。
Likelihood Score:指的是给定模型结构G和数据D,求出最优的参数,然后求出在G和该参数下对数据D的log似然值。其表达式如下:
![]()
式中第一个求和表示子节点与父节点之间的互信息,第2个求和为节点的熵,关于互信息计算公式如下:
![]()
互信息的值>=0,且当变量x和y相互独立时互信息为0,但通常情况下即使x和y是从相互独立中的分布采用得来的,其互信息也大于0。
Likelihood score容易overfitting,为了减少overfitting可采用BIC score(BIC:Bayesian Information Criterion),公式为:
![]()
该score对模型中相互独立参数的个数进行了限制,能够平衡模型对数据的拟合度和模型的复杂度。BIC score具有渐进一致性(consistency),因为随着样本的增多,它能够收敛到与true graph的I-equivalent网络上,并且score也越来越大。
Bayesian score是利用所有参数的加权平均,其表达式如下:
![]()
第一项叫Marginal Likelihood,包含了参数的先验知识在里面,要求是能够分解。第二项叫结构先验,它对边的数目,参数的个数进行惩罚,即对模型的复杂度进行了惩罚。在Bayesian score 中,有唯一一个导致 consistency 的参数先验BDe prior,所以一般情况下选择BDe prior. BIC score是Bayeisan score的一种近似。
在拥有score函数以及一些候选网络结构后,需要用搜索算法来寻找最优网络结构。一般可采用候选网络结构为tree(由tree构成forest), 因为tree能够很好的被优化,且拥有稀疏参数,泛化能力较强。另外tree中每个节点顶多有1个父节点,所以我们可以对它进行分解来计算score值:先将有父节点和无父节点的节点分开,然后根据边的权值公式在网络加入边直到score不再增加,或者出现环时停止。最后采用max-weight spanning trees(MST)搜索算法找出权值大的那些边。
对于Likelihood score来说,边的权值非负,对于BIC score和Bayesian score来说,边的权值可以为负数(因为score函数对边数有惩罚,相当于边权值为负)。
实际中很多网络并不是tree结构,也就是说可以有多个父节点,更复杂。有理论证明,如果父节点个数>1,则搜索得分最高的网络的过程是NP-hard的。此时一般采用启发式搜索,以greedy爬山法为例:给定一个初始的网络结构(可以是空的,随机的,或是学习出来的tree,亦或是先验设计的),在该网络基础上采用添加、删除、反向等操作逐步选择得分最高的那个操作,依次迭代直到score不再变。虽然边的反向操作可以由删除和添加2个步骤构成,但是由于在局部最优点附近采用greedy的方法时,删除边会导致score降低(意味着不会采用该操作),这样就实现不了边的反向了,因此需要引入Edge Reversal操作。
Naive Computational Analysis: 每一步edge的添加、删除、反向的时间复杂度为O(n^2);如果网络中有n个component,且计算每个component的充分统计量需O(M)时间;另外环检测(Acyclicity check)时间和边数m成正比,为O(m); 则结构搜索中的每一步代价为O(n^2*(Mn+m)).
错误提示:
matlab2013b+ubuntu13.10下矩阵运算出现如下错误:
BLAS loading error: dlopen: cannot load any more object matlab.
网上查了下有不少人碰见过,我这里是重启下matlab解决的。
参考资料:
coursera课程:Probabilistic Graphical Models
网友demonstrate的blog:PGM 读书笔记节选(十五)
Daphne Koller,Probabilistic Graphical Models Principles and Techniques书籍第18章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号