2021面向对象第一单元总结 BUAA_OO
BUAA OO 第一单元作业总结
综述
作业回顾
- 本次作业一共包含3个homework,难度递增,且总体符合迭代式开发需求。通过复杂需求的提出,强化了对于代码的总体架构,类以及方法的设计思路,代码的可拓展性的考虑深度,初步理解了面向对象的基本含义以及重要之处。
- 题目回顾:
- homework1:
对于如 f(x) = +06 + -2*x**-1 +9*x 函数的求导 (无复合函数,无三角函数,无嵌套) - homework2:
对于如 fx()= (2*x+sin(x))*x**3 + 3*x**3 函数的求导 (无复合函数,有三角函数,有嵌套) - homework3:
对于如 f(x) = sin(sin(x**2))*sin(x)**2 + -09 函数的求导 (有复合函数,有三角函数,有嵌套) 并增加了 格式检查
- homework1:
总体架构
-
对于第一次作业,仅仅用了Arraylist来完成,没有用到面向对象的思想。
-
对于第二次作业,无奈之下必须重构,运用了 递归下降 的方法,递归二叉求解。具有了面向对象的部分特征。
-
对于第三次作业,在第二次作业的基础上稍加改动,完成了求导部分。对于格式检查则完全面向过程,枚举完成,bug众多。
各作业分析
第一次作业
程序结构
总体
- 总体由一个主类,三个对象类组成。共计400行代码,主要集中在三个对象类。
类以及方法
- 类图由idea生成,手动进行了排布和分析

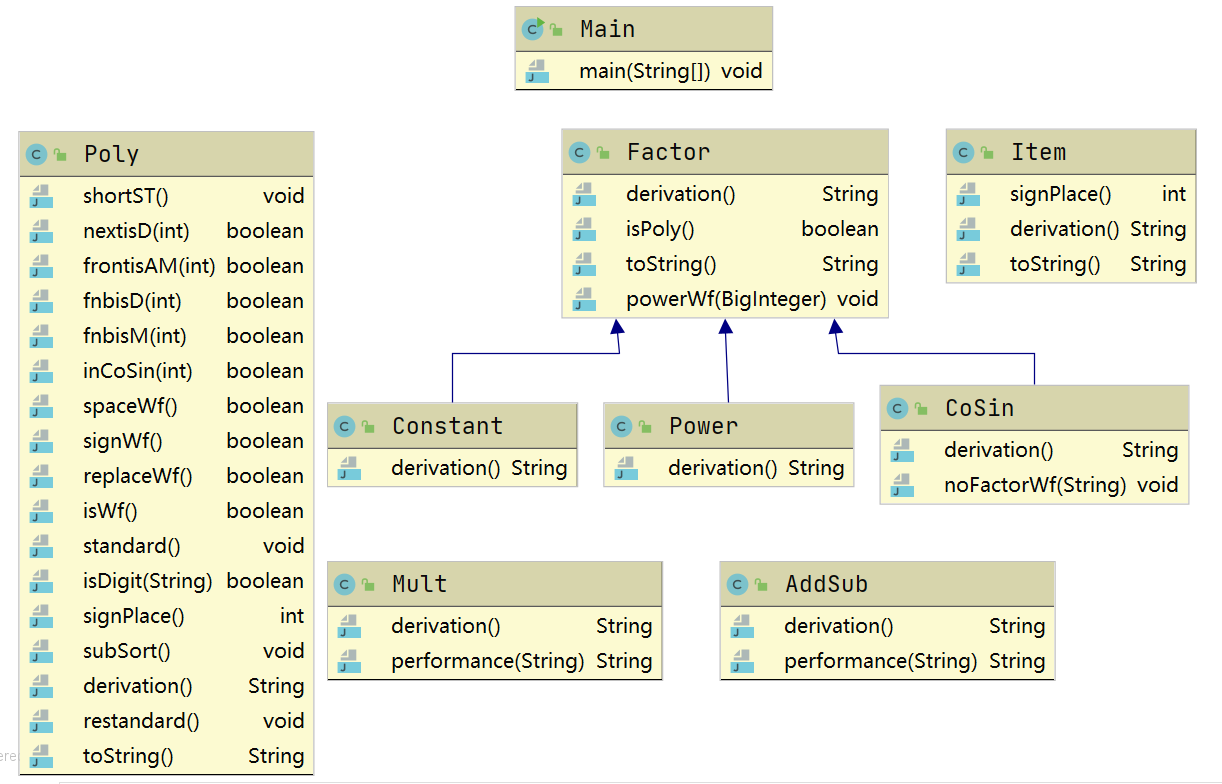
- 如类图所示,整个项目由一个主类,三个成逻辑包含关系的类组成。Poly指整个表达式,Item指一个由乘号连接的项,Factor指一个形如 3*x**2 的因子。由于在理论课上老师讲解了关于面向对象的封装性,所以有意识地把原本其实可以放在一个类里的所有方法按照对象进行了分类。
复杂度分析
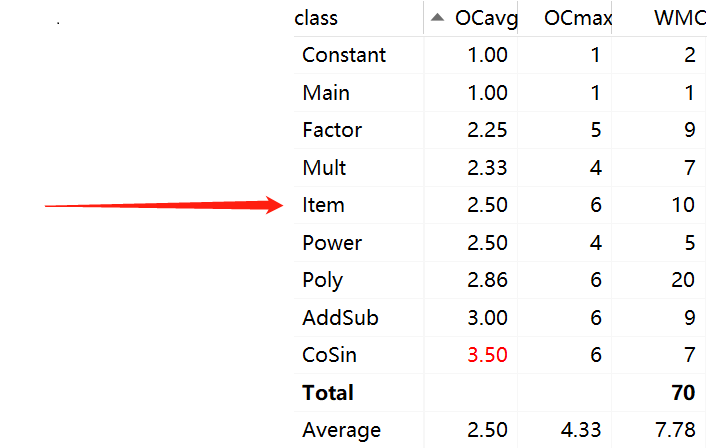
-
复杂度分析由idea的插件MetricsReload生成,手动进行了分析。
-
OCavg代表类的方法的平均循环复杂度。OCmax代表类的方法的最大循环复杂度。WMC代表类的总循环复杂度。
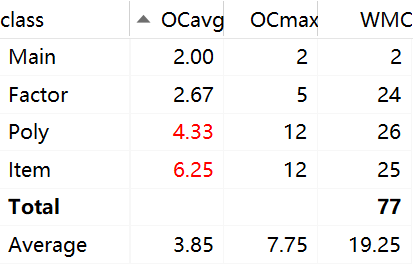
-
可以看出,Poly和Item的分支复杂度明显非常高,这是由于在判断多项式因子的结构时,使用了大量的if-else if-else结构,用以处理读入求导和结果输出。例如以下的这一段代码:
-
if (String.valueOf(power).equals("0")) { return String.valueOf(ecoff); } if (String.valueOf(ecoff).equals("1")) { if (String.valueOf(power).equals("1")) { return "x"; } else { return ("x**" + power); } } else if (String.valueOf(ecoff).equals("-1")) { if (String.valueOf(power).equals("1")) { return "-x"; } else { return ("-x**" + power); } } else { if (String.valueOf(power).equals("1")) { return (ecoff + "*x"); } else { return (ecoff + "*" + "x**" + power); } } -
可以看到,造成if-else分支结构大量出现的原因,是因为我对于每个项以及因子的处理以及传输更多的停留在字符串层面上。每一次的分析都需要频繁识别以及判断。在homework1结束后,我学习到了可以使用Hashmap进行数据的存储,如此一来,就省去了繁复的格式处理,合并同类项也更加简单。
耦合度分析
-
ev(G) 基本复杂度是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
-
iv(G) 模块设计复杂度是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
-
v(G) 是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。
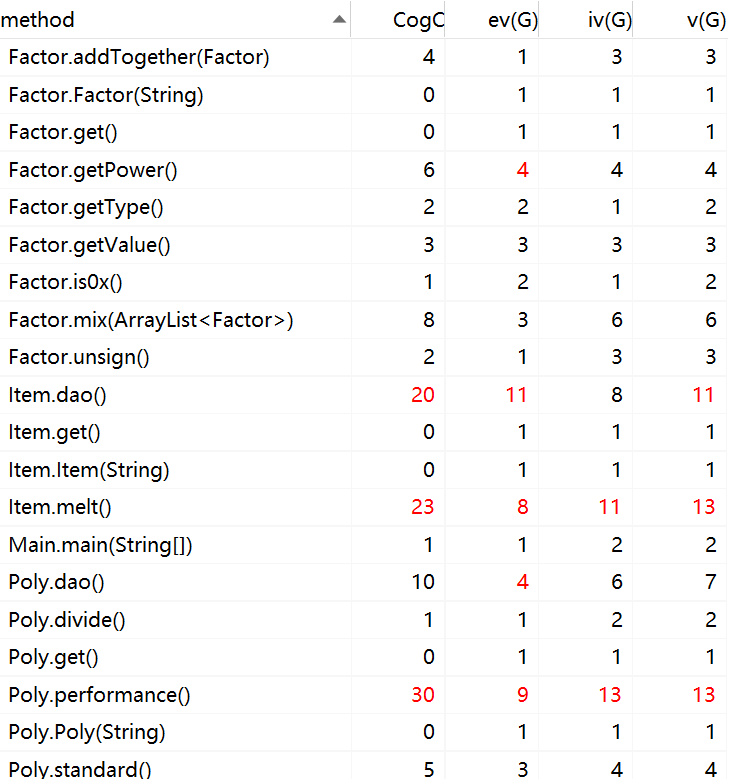
- 我们可以看到,耦合度最高的方法主要是item的求导,item的化简,和最终表达式的化简。与复杂度分析一样,之所以耦合度很高,是因为每个类方法都需要频繁调用下级类的方法来判断,如果采用更好的数据存储方式,我认为应该可以较为有效地降低耦合。
优缺点分析
- 对于第一次作业,对于面向对象的理解十分浅显。导致了实际上以为的面向对象仅仅只是把不同的方法按照对象进行了分类,从样子上进行模仿。这样去做的好处在于能够为之后的工作打下一定的基础,对类的关系以及调用来说,是一次经验尝试。但是缺点十分明显,由于并没有采用Hashmap等结构,还进行了程序之间的分割,导致不同方法间的传输成本大大升高,既增加了方法分支复杂度,又增加了耦合度。
bug分析
-
由于本题较为基础,在强测和互测均没有被hack出来bug。
-
对于别人的hack,初次尝试了构建评测机。利用python的xeger生成表达式,利用subprocess运行jar包,利用sympy求导化简。完成了简易的对拍器以及评测机,在互测中也确实找出了别人的bug。
第二次作业
程序结构
- 本次homework一共有一个主类,三个对象类,两个运算类。代码总量有450行左右。
类以及方法
- 由于本次任务直接加入了 sin(x) 和 cos(x) ,他们本身如同 x 支持系数和幂次。还支持了嵌套——表达式本身可以作为一个因子,参与项和表达式的运算。前者其实比较好说,相当于引入了新的未知数 y ,但是后者就将此次任务的难度提高了一个层次。因为当表达式支持嵌套之后,整个表达式就不是一个线性的关系了,而是树状的,无法简简单单地遍历分析。
- 面对如此对于架构的考验,我想到了上学期数据结构所学的 倒序表达式树 应该是可以解决这一个任务,但是他其实并不具有面向对象的思想,仍然是面向过程,以上帝视角来完成表达式的解析,缺乏必要的可拓展性。于是经过苦思冥想,我想到了运用递归的思想来完成表达式的解析。
(后来才知道这原来是叫做递归下降)
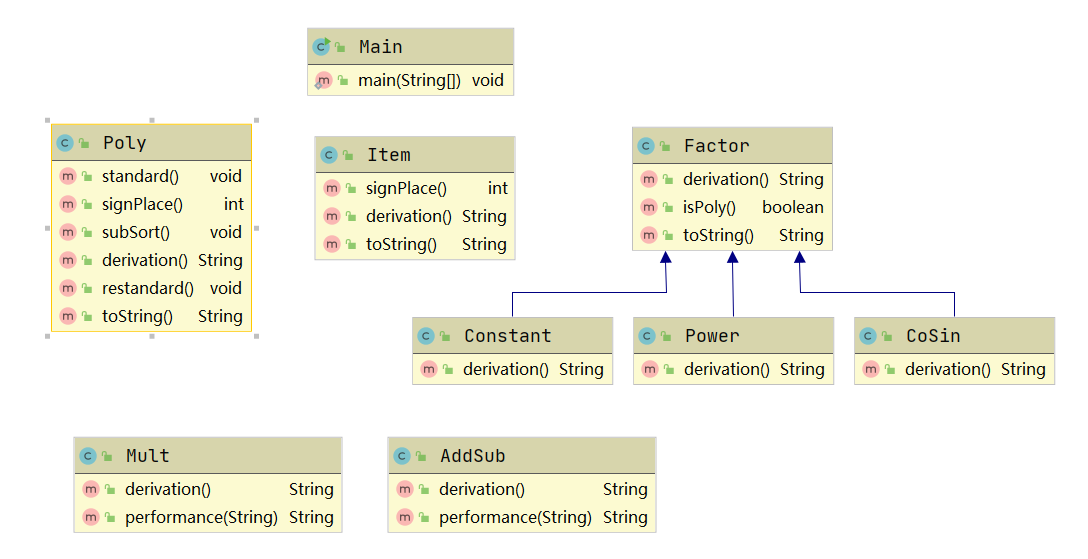
复杂度分析
if (m.end() == 1) {
power = BigInteger.valueOf(0);
} else if (String.valueOf(m.group(3)).equals("1")) {
power = BigInteger.valueOf(0);
} else {
cons = new BigInteger(String.valueOf(m.group(3)));
power = new BigInteger(String.valueOf(m.group(3)));
power = power.subtract(BigInteger.valueOf(1));
}
if (String.valueOf(m.group(1)).equals("s")) {
oldfunc = "s";
newfunc = "c";
} else {
oldfunc = "c";
newfunc = "-1*s";
}
if (power.equals(BigInteger.valueOf(0))) {
return newfunc;
} else if (power.equals(BigInteger.valueOf(1))) { //性能优化
return newfunc + "*" + cons + "*" + oldfunc;
} else {
return newfunc + "*" + cons + "*" + oldfunc + "^" + power;
- 个人认为这里的条件判断在可接受范围内,但是仍然可以通过比如三目运算符等工具进行简化,下次应当注意。
耦合度分析
-
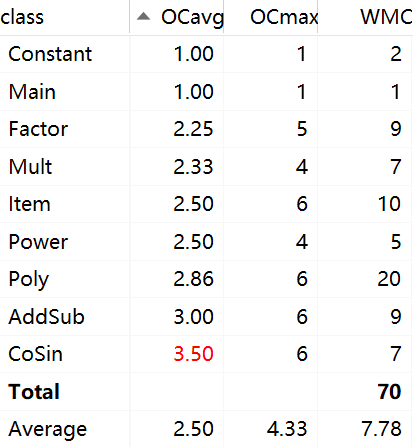
method CogC ev(G) iv(G) v(G) AddSub.AddSub(String,String,String) 0.0 1.0 1.0 1.0 AddSub.derivation() 7.0 1.0 7.0 7.0 AddSub.performance(String) 2.0 2.0 1.0 2.0 Constant.Constant(String) 0.0 1.0 1.0 1.0 Constant.derivation() 0.0 1.0 1.0 1.0 CoSin.CoSin(String) 0.0 1.0 1.0 1.0 CoSin.derivation() 8.0 3.0 4.0 6.0 Factor.derivation() 7.0 5.0 5.0 5.0 Factor.Factor(String) 0.0 1.0 1.0 1.0 Factor.isPoly() 2.0 2.0 1.0 2.0 Factor.toString() 0.0 1.0 1.0 1.0 Item.derivation() 2.0 2.0 2.0 2.0 Item.Item(String) 0.0 1.0 1.0 1.0 Item.signPlace() 8.0 6.0 4.0 6.0 Item.toString() 0.0 1.0 1.0 1.0 Main.main(String[]) 0.0 1.0 1.0 1.0 Mult.derivation() 5.0 2.0 5.0 6.0 Mult.Mult(String,String) 0.0 1.0 1.0 1.0 Mult.performance(String) 2.0 2.0 1.0 2.0 Poly.derivation() 2.0 2.0 2.0 2.0 Poly.Poly(String) 0.0 1.0 1.0 1.0 Poly.restandard() 0.0 1.0 1.0 1.0 Poly.signPlace() 10.0 6.0 7.0 8.0 Poly.standard() 11.0 1.0 7.0 7.0 Poly.subSort() 4.0 1.0 3.0 3.0 Poly.toString() 0.0 1.0 1.0 1.0 Power.derivation() 5.0 4.0 3.0 4.0 Power.Power(String) 0.0 1.0 1.0 1.0 -
由于递归下降 的架构很好的将不同对象的任务分开了,所以这次任务的类之间的耦合度不是很高。仅仅是由于Factor类回合Poly类递归,所以两类之间有一定的耦合,但总体都可以接受。
优缺点分析
- 这一次任务真的让我学到了很多。
(不过就是阶梯貌似还是有点太大了)从任务一的纯纯c语言,经过一天的冥思苦想,完成了一个有大部分面向对象特征的递归架构,不得不说这让我对于面向对象有了更深的思考。封装性、各取所需、各司其职,都在代码中得到了体现。而且这种架构的求导十分简便(无脑),出错率真的很小很小。 - 但是二叉树式的递归求导带来的最大的问题就是根本无法化简。二叉树带来的是无穷无尽的括号的嵌套,无法合并同类项。我所做的化简工作,只有判断0,判断+-1等十分初级的化简,这叫导致我的强测性能分基本全都丢掉了。
bug分析
hacked
-
这一次作业被hack的bug真的给我上了一课。两个强测点,两个互测点,居然都出现了TLE,这是我真的没有料到的。经过分析,我锁定了问题代码,如下:
String result = new String(); //性能优化 if ((poly1.derivation().equals("0")) && (poly2.derivation().equals("0"))) { result = "0"; } else if (poly1.derivation().equals("0")) { result = sign + none.performance(poly2.derivation()); } else if (poly2.derivation().equals("0")) { result = none.performance(poly1.derivation()); } else if (sign.equals("+")) { result = none.performance(poly1.derivation()) + "+" + none.performance(poly2.derivation()); } else { result = none.performance(poly1.derivation()) + "-" + none.performance(poly2.derivation()); } return result; -
这是AddSub类的derivaiton的一部分代码,可以看到,短短的几行之内,居然调用了10次基本相同的poly的derivation函数,由于加减法的嵌套,这会导致代码的derivation函数调用次数呈指数级增加,导致TLE。只需要将代码改成如下所示,即可完全解决掉:
String result = new String(); //性能优化 String p1d = poly1.derivation(); String p2d = poly2.derivation(); if ((p1d.equals("0")) && (p2d.equals("0"))) { result = "0"; } else if (p1d.equals("0")) { result = sign + none.performance(p2d); } else if (p2d.equals("0")) { result = none.performance(p1d); } else if (sign.equals("+")) { result = none.performance(p1d) + "+" + none.performance(p2d); } else { result = none.performance(p1d) + "-" + none.performance(p2d); } return result;
hack
- 这一次任务我将任务一的评测机简单改进即可继续使用,并且完成了 9/42 的 hack。发现的问题大多都是处在了计算错误,例如符号忘记取反,例如忘加括号等等原因导致的错误
第三次作业
- 这一次作业 一共写了700行代码,一共有一个主类,六个对象类,两个运算类。
程序结构
类以及方法
- 而对于格式错误检查,则是考虑用两种方法解决。一是在Poly类里写了很多函数来识别格式错误,二是在求导程序里捕捉因为格式错误产生的异常,报格式错误。之所以如此安排,是因为我
懒想最大限度的使用原任务二的程序。但事实证明,这种识别格式错误的架构完全是建立在bug上的屎堆,改起来贼烦,还难以覆盖测试。
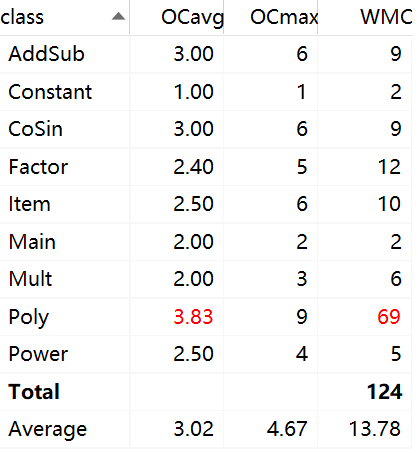
复杂度分析
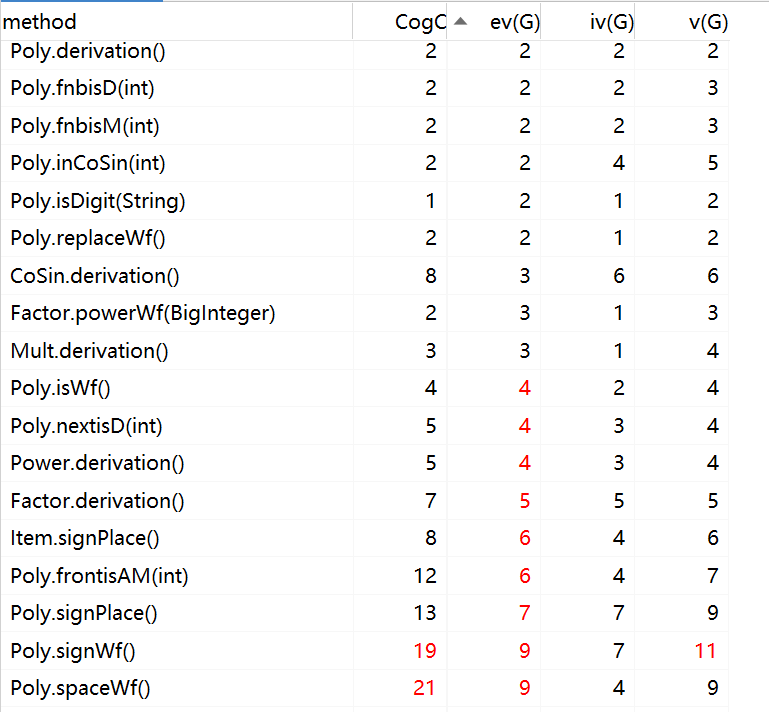
耦合度分析
优缺点分析
- 这次作业架构的优点可以说是没有。
- 在最后一次作业给出这样的架构毫无疑问是有遗憾的。我认为,一方面是由于我对于接口等结构的不熟悉,不敢使用,怕出bug;另一方面是因为我有些懒惰了,不想大改,只想着套用,结果bug一波接一波地来,耗费了比原来更多的时间。现在要我在此基础上修改架构,我应该会把求导和判断格式错误做成接口,以此降低耦合。
bug分析
hacked
- 第三次任务hack出了同组三个人的过度优化,还hack出了一位同学的求导错误。由于hack的重点应该放在误判WrongFormat上(因为毕竟经过任务二后求导的正确性应该不会有什么太大问题),评测机感觉并不能很好地胜任,所以这次互测并没有能发现太多的bug。老师课上说hack出的bug数其实和对题目的理解成正比,确实如此。
hack
- 强测和互测都崩了。强测错了sin(+ 5)的格式错误,互测错了1\t的格式错误,输出++++++5的输出错误,(null)*4的误判错误。全面崩盘。
- 究其原因,有如下几点。一是在于架构时太过依赖捕捉异常识别格式错误;二是采用了枚举特判格式,考虑不全面;三是在操作index时没有考虑OutOfRange;四是测试不全面,盲目自信。
- 另外一方面,确实bug出在了圈复杂度和条件复杂度最高的地方,开始考虑以直接枚举的方式来做格式判断就应该预料到这种情况的发生。
重构经历总结
- 总的来说,本单元我只重构了一次。就是第二次作业时候利用递归下降来进行架构。当时没有采用倒序表达式树是正确的,否则第三次应该还需要去重构。并且,这应该是我第一次整个项目全部用递归的写法来架构,真的学到了很多。
- 这是第一次和重构完后第二次代码复杂度的对比,可以看到使用 递归下降 架构,不同类的分工是很明确的。简洁度、正确性、可读性都有明显的提升。
心得体会
- 首先是对于架构能力的提高是显而易见的。从开始的伪面向对象,到现在理解了不少要点,找到了选取对象的感觉,进步很大。并且,通过之后的迭代,更是认识到了好的架构对于一个项目来说真的是必要的,没有好的架构,不仅写的烦且慢,而且bug很多,不具有拓展能力,debug极其容易产生裙带bug。而当花更多的时间做一个好的架构,这些都会迎刃而解了。
- 其次是对于代码能力的提高。两次实验课上练习了HashMap,Factory和Interface,虽然练习了,但我并没有在作业中使用过,实在是埋了雷。
(有预感之后这些会使用场景很多)一定得进一步研究。其次是对于递归,递归下降,继承,tostring等都有较多的练习,使用起来越发的顺手了。 - 然后是写评测机的能力。第一单元我相当于一共写了两个评测机,效果都很不错。从上学期计组开始我就领略到了评测机的威力,而有机会在现在自己亲自动手写感觉很有成就感。
- 当然对于代码风格,git使用,题目理解等等隐形提高是很多的。
- 当然问题也不少。最关键的是一定要熟悉实验课教的内容,在之后的单元中应该更加注重把老师理论课的内容应用到作业中。(毕竟这次没有按照老师的“运算类继承Poly类”)。接口、工厂模式、哈希表一定得再看看,消化吸收一波。
- 另外第二次作业的TLE和第三次作业的WFbug都令人印象颇深。
(不能再当懒狗了555)
- 总的来说,这次作业有一定收获,在入门的路上有了一定的进展,也看到了班级上的大佬们是怎么分析问题
(熬夜爆肝)的,也尝到了被同组大佬hack爆的恐惧,希望能持续进步,也希望能在之后有机会在研讨课能给大家做展示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号