
卷积神经网络
一、卷积神经网络的理论学习
- 卷积神经网络的基本应用
- 分类
- 检索
- 检测
- 分割
如人脸识别、图像生成、图像风格转化、自动驾驶... - 深度学习三部曲
①搭建神经网络结构
②找到一个合适的损失函数,如交叉熵损失、均方误差...
③找到一个合适的优化函数,更新参数,如反向传播、随机梯度下降...
![]()
全连接网络处理图像存在参数太多的问题,卷积神经网络的解决方式为局部关联,参数共享。
2.卷积神经网络的基本组成结构
一个典型的卷积网络是由卷积层、池化层、全连接层交叉堆叠而成
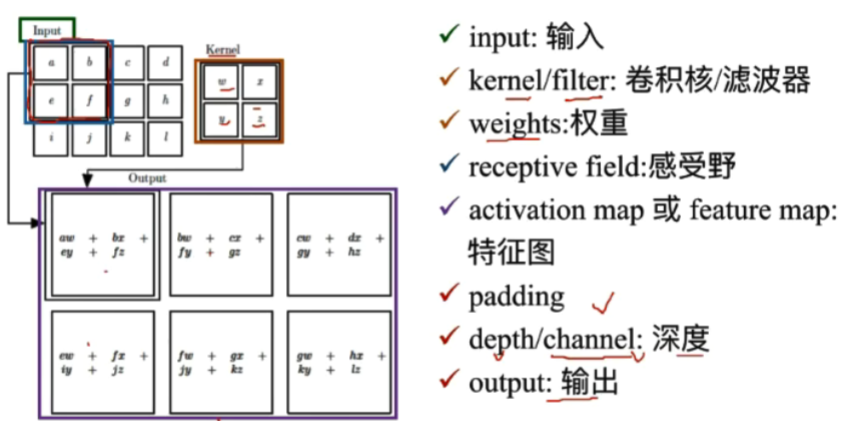
(1)卷积
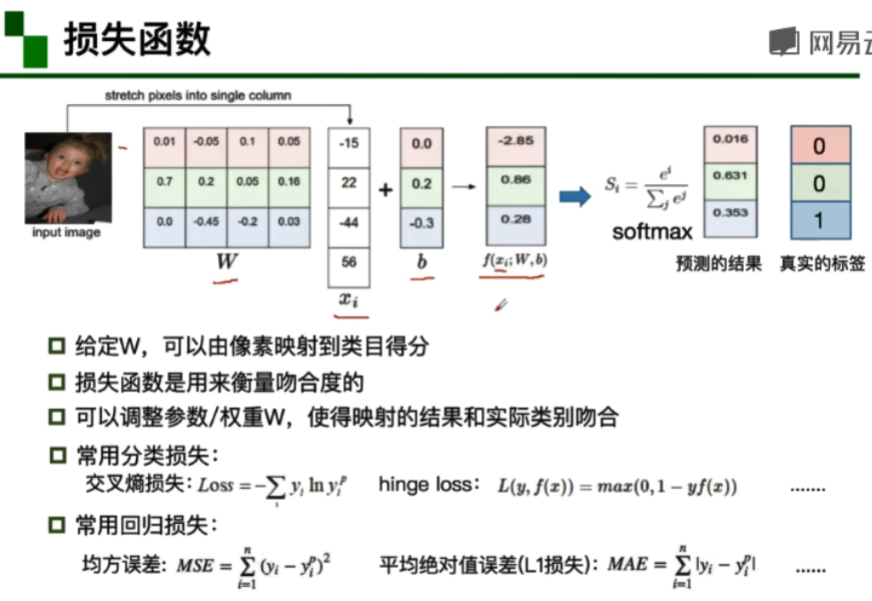
卷积是对两个实变函数的一种数学操作(求内积)

- 二维卷积:y=WX+b;W为卷积核里的参数,X为每次进行卷积的区域,b为偏置项。
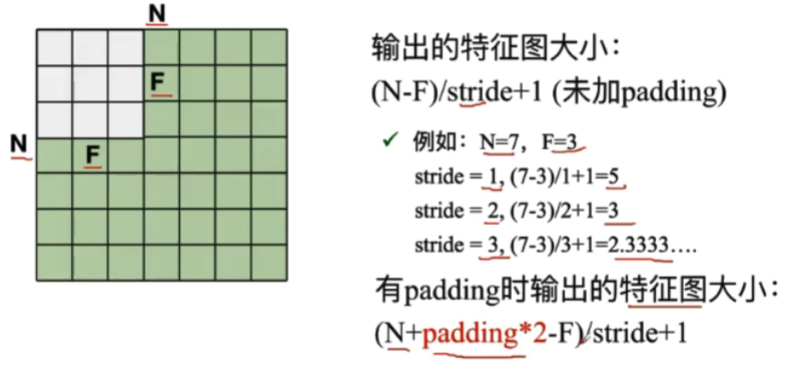
padding:卷积时进行0填充
(2)池化(Pooling Layer)
(对future map进行缩放)保留了主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力;它一般处于卷积层与卷积层之间,全连接层和全连接层之间。
模型:
- 最大值池化
- 平均值池化
(3)全连接(Fully Connected Layer)
全连接层: - 两层之间所有神经元都有权重链接
- 通常全连接层在卷积神经网络尾部
- 全连接层参数量通常最大
3.卷积神经网络的典型结构
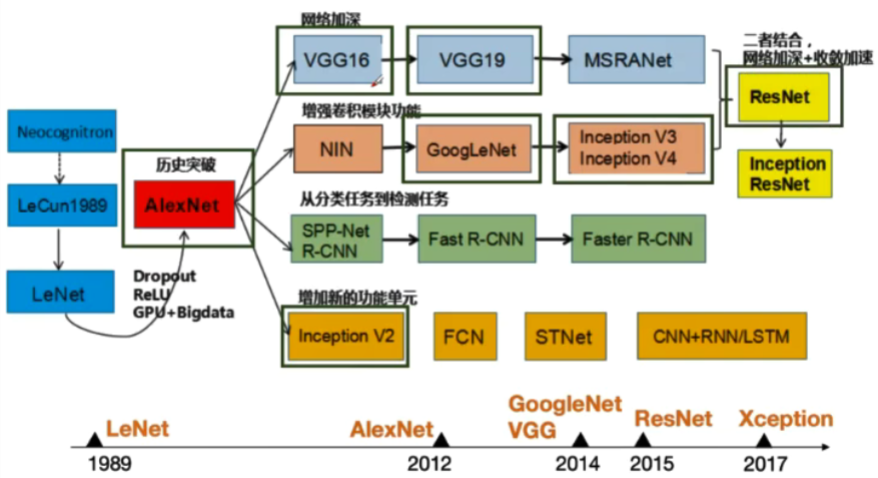
(1)AlexNet
(2)ZFNet
(3)VGG
(4)GoogleNet
(5)ResNet
二、卷积神经网络的代码练习
1.卷积神经网络
点击查看代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy
# 一个函数,用来计算模型中有多少参数
def get_n_params(model):
np=0
for p in list(model.parameters()):
np += p.nelement()
return np
①加载数据(MNIST)
在调用模块后加载数据,利用pytorch里包含的MNIST,CIFAR10等常用数据集,调用torchvision.datasets,把这些数据由远程下载到本地
点击查看代码
input_size = 28*28 # MNIST上的图像尺寸是 28x28
output_size = 10 # 类别为 0 到 9 的数字,因此为十类
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=1000, shuffle=True)
数据下载好后,显示数据集中的部分图像:
点击查看代码
plt.figure(figsize=(8, 5))
for i in range(20):
plt.subplot(4, 5, i + 1)
image, _ = train_loader.dataset.__getitem__(i)
plt.imshow(image.squeeze().numpy(),'gray')
plt.axis('off');
图像如下:

②创建网络
定义网络时,需要继承nn.Module,并实现它的forward方法,把网络中具有可学习参数的层放在构造函数init中。
只要在nn.Module的子类中定义了forward函数,backward函数就会自动被实现(利用autograd)。
点击查看代码
class FC2Layer(nn.Module):
def __init__(self, input_size, n_hidden, output_size):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Module.__init__(self)
super(FC2Layer, self).__init__()
self.input_size = input_size
# 这里直接用 Sequential 就定义了网络,注意要和下面 CNN 的代码区分开
self.network = nn.Sequential(
nn.Linear(input_size, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, output_size),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
# view一般出现在model类的forward函数中,用于改变输入或输出的形状
# x.view(-1, self.input_size) 的意思是多维的数据展成二维
# 在 DataLoader 部分,我们可以看到 batch_size 是64,所以得到 x 的行数是64
x = x.view(-1, self.input_size)
return self.network(x)
class CNN(nn.Module):
def __init__(self, input_size, n_feature, output_size):
# 执行父类的构造函数
super(CNN, self).__init__()
# 下面是网络里典型结构的一些定义,一般就是卷积和全连接
self.n_feature = n_feature
self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5)
self.conv2 = nn.Conv2d(n_feature, n_feature, kernel_size=5)
self.fc1 = nn.Linear(n_feature*4*4, 50)
self.fc2 = nn.Linear(50, 10)
# 下面的 forward 函数,定义了网络的结构,按照一定顺序,把上面构建的一些结构组织起来
# 意思就是,conv1, conv2 等等的,可以多次重用
def forward(self, x, verbose=False):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = x.view(-1, self.n_feature*4*4)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
定义训练函数和测试函数
点击查看代码
# 训练函数
def train(model):
model.train()
# 主里从train_loader里,64个样本一个batch为单位提取样本进行训练
for batch_idx, (data, target) in enumerate(train_loader):
# 把数据送到GPU中
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
# 把数据送到GPU中
data, target = data.to(device), target.to(device)
# 把数据送入模型,得到预测结果
output = model(data)
# 计算本次batch的损失,并加到 test_loss 中
test_loss += F.nll_loss(output, target, reduction='sum').item()
# get the index of the max log-probability,最后一层输出10个数,
# 值最大的那个即对应着分类结果,然后把分类结果保存在 pred 里
pred = output.data.max(1, keepdim=True)[1]
# 将 pred 与 target 相比,得到正确预测结果的数量,并加到 correct 中
# 这里需要注意一下 view_as ,意思是把 target 变成维度和 pred 一样的意思
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
accuracy))
③在小型全连接网络上训练
点击查看代码
n_hidden = 8 # number of hidden units
model_fnn = FC2Layer(input_size, n_hidden, output_size)
model_fnn.to(device)
optimizer = optim.SGD(model_fnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_fnn)))
train(model_fnn)
test(model_fnn)
训练结果如下:
点击查看代码
Number of parameters: 6442
(64, 784)
Train: [0/60000 (0%)] Loss: 2.292367
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [6400/60000 (11%)] Loss: 2.005609
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [12800/60000 (21%)] Loss: 1.637037
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [19200/60000 (32%)] Loss: 1.297722
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [25600/60000 (43%)] Loss: 1.026405
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [32000/60000 (53%)] Loss: 0.827517
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [38400/60000 (64%)] Loss: 0.545133
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [44800/60000 (75%)] Loss: 0.343346
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [51200/60000 (85%)] Loss: 0.391508
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [57600/60000 (96%)] Loss: 0.418873
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(32, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
Test set: Average loss: 0.4533, Accuracy: 8683/10000 (87%)
④在卷积神经网络上训练
点击查看代码
n_features = 6 # number of feature maps
model_cnn = CNN(input_size, n_features, output_size)
model_cnn.to(device)
optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_cnn)))
train(model_cnn)
test(model_cnn)
训练结果如下:
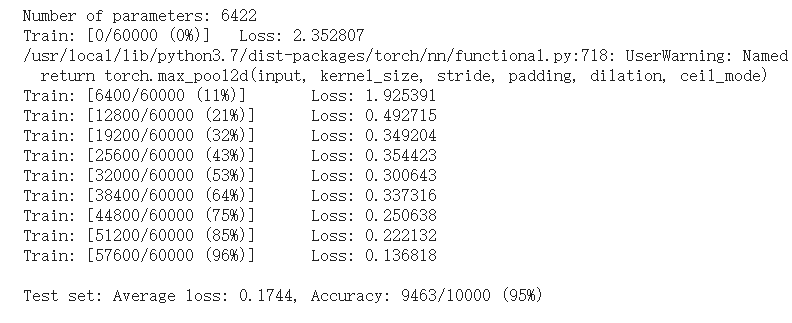
⑤打乱像素顺序再次在两个网络上训练与测试
考虑到CNN在卷积与池化上的优良特性,如果我们把图像中的像素打乱顺序,这样 卷积 和 池化 就难以发挥作用了,为了验证这个想法,我们把图像中的像素打乱顺序再试试。
首先下面代码展示随机打乱像素顺序后,图像的形态:
点击查看代码
perm = torch.randperm(784)
plt.figure(figsize=(8, 4))
for i in range(10):
image, _ = train_loader.dataset.__getitem__(i)
# permute pixels
image_perm = image.view(-1, 28*28).clone()
image_perm = image_perm[:, perm]
image_perm = image_perm.view(-1, 1, 28, 28)
plt.subplot(4, 5, i + 1)
plt.imshow(image.squeeze().numpy(), 'gray')
plt.axis('off')
plt.subplot(4, 5, i + 11)
plt.imshow(image_perm.squeeze().numpy(), 'gray')
plt.axis('off')

重新定义训练与测试函数, train_perm 和 test_perm,分别对应着加入像素打乱顺序的训练函数与测试函数。
与之前的训练与测试函数基本上完全相同,只是对 data 加入了打乱顺序操作。
点击查看代码
# 对每个 batch 里的数据,打乱像素顺序的函数
def perm_pixel(data, perm):
# 转化为二维矩阵
data_new = data.view(-1, 28*28)
# 打乱像素顺序
data_new = data_new[:, perm]
# 恢复为原来4维的 tensor
data_new = data_new.view(-1, 1, 28, 28)
return data_new
# 训练函数
def train_perm(model, perm):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
# 像素打乱顺序
data = perm_pixel(data, perm)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 测试函数
def test_perm(model, perm):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
# 像素打乱顺序
data = perm_pixel(data, perm)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
accuracy))
在全连接网络上训练与测试:
点击查看代码
perm = torch.randperm(784)
n_hidden = 8 # number of hidden units
model_fnn = FC2Layer(input_size, n_hidden, output_size)
model_fnn.to(device)
optimizer = optim.SGD(model_fnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_fnn)))
train_perm(model_fnn, perm)
test_perm(model_fnn, perm)
训练结果如下:
点击查看代码
Number of parameters: 6442
(64, 784)
Train: [0/60000 (0%)] Loss: 2.301584
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [6400/60000 (11%)] Loss: 1.733259
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [12800/60000 (21%)] Loss: 1.202302
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [19200/60000 (32%)] Loss: 0.828418
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [25600/60000 (43%)] Loss: 0.478002
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [32000/60000 (53%)] Loss: 0.469630
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [38400/60000 (64%)] Loss: 0.395304
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [44800/60000 (75%)] Loss: 0.469129
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [51200/60000 (85%)] Loss: 0.403815
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
Train: [57600/60000 (96%)] Loss: 0.508558
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(64, 784)
(32, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
(1000, 784)
Test set: Average loss: 0.4099, Accuracy: 8810/10000 (88%)
在卷积神经网络上训练与测试:
点击查看代码
perm = torch.randperm(784)
n_features = 6 # number of feature maps
model_cnn = CNN(input_size, n_features, output_size)
model_cnn.to(device)
optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_cnn)))
train_perm(model_cnn, perm)
test_perm(model_cnn, perm)
训练结果如下:

从打乱像素顺序的实验结果来看,全连接网络的性能基本上没有发生变化,但是 卷积神经网络的性能明显下降。
这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
2.CIFAR10数据分类
首先,加载并归一化 CIFAR10 使用 torchvision 。torchvision 数据集的输出是范围在[0,1]之间的 PILImage,我们将他们转换成归一化范围为[-1,1]之间的张量 Tensors。
点击查看代码
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 注意下面代码中:训练的 shuffle 是 True,测试的 shuffle 是 false
# 训练时可以打乱顺序增加多样性,测试是没有必要
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=8,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def imshow(img):
plt.figure(figsize=(8,8))
img = img / 2 + 0.5 # 转换到 [0,1] 之间
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 得到一组图像
images, labels = iter(trainloader).next()
# 展示图像
imshow(torchvision.utils.make_grid(images))
# 展示第一行图像的标签
for j in range(8):
print(classes[labels[j]])
得到一组图像:

接下来定义网络,损失函数和优化器:
点击查看代码
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 网络放到GPU上
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
训练网络:
点击查看代码
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
训练结果如下:
点击查看代码
Epoch: 1 Minibatch: 1 loss: 2.289
Epoch: 1 Minibatch: 101 loss: 2.007
Epoch: 1 Minibatch: 201 loss: 1.848
Epoch: 1 Minibatch: 301 loss: 1.737
Epoch: 1 Minibatch: 401 loss: 1.591
Epoch: 1 Minibatch: 501 loss: 1.514
Epoch: 1 Minibatch: 601 loss: 1.595
Epoch: 1 Minibatch: 701 loss: 1.304
Epoch: 2 Minibatch: 1 loss: 1.775
Epoch: 2 Minibatch: 101 loss: 1.328
Epoch: 2 Minibatch: 201 loss: 1.464
Epoch: 2 Minibatch: 301 loss: 1.392
Epoch: 2 Minibatch: 401 loss: 1.346
Epoch: 2 Minibatch: 501 loss: 1.334
Epoch: 2 Minibatch: 601 loss: 1.475
Epoch: 2 Minibatch: 701 loss: 1.293
Epoch: 3 Minibatch: 1 loss: 1.465
Epoch: 3 Minibatch: 101 loss: 1.214
Epoch: 3 Minibatch: 201 loss: 1.150
Epoch: 3 Minibatch: 301 loss: 1.385
Epoch: 3 Minibatch: 401 loss: 1.390
Epoch: 3 Minibatch: 501 loss: 1.471
Epoch: 3 Minibatch: 601 loss: 1.247
Epoch: 3 Minibatch: 701 loss: 1.087
Epoch: 4 Minibatch: 1 loss: 1.227
Epoch: 4 Minibatch: 101 loss: 1.039
Epoch: 4 Minibatch: 201 loss: 1.168
Epoch: 4 Minibatch: 301 loss: 1.062
Epoch: 4 Minibatch: 401 loss: 1.185
Epoch: 4 Minibatch: 501 loss: 1.230
Epoch: 4 Minibatch: 601 loss: 1.123
Epoch: 4 Minibatch: 701 loss: 1.065
Epoch: 5 Minibatch: 1 loss: 1.008
Epoch: 5 Minibatch: 101 loss: 0.993
Epoch: 5 Minibatch: 201 loss: 0.971
Epoch: 5 Minibatch: 301 loss: 1.349
Epoch: 5 Minibatch: 401 loss: 0.989
Epoch: 5 Minibatch: 501 loss: 1.038
Epoch: 5 Minibatch: 601 loss: 0.818
Epoch: 5 Minibatch: 701 loss: 1.115
Epoch: 6 Minibatch: 1 loss: 1.091
Epoch: 6 Minibatch: 101 loss: 1.134
Epoch: 6 Minibatch: 201 loss: 1.125
Epoch: 6 Minibatch: 301 loss: 0.843
Epoch: 6 Minibatch: 401 loss: 1.114
Epoch: 6 Minibatch: 501 loss: 0.891
Epoch: 6 Minibatch: 601 loss: 0.804
Epoch: 6 Minibatch: 701 loss: 1.085
Epoch: 7 Minibatch: 1 loss: 0.932
Epoch: 7 Minibatch: 101 loss: 0.941
Epoch: 7 Minibatch: 201 loss: 1.037
Epoch: 7 Minibatch: 301 loss: 0.963
Epoch: 7 Minibatch: 401 loss: 0.792
Epoch: 7 Minibatch: 501 loss: 1.034
Epoch: 7 Minibatch: 601 loss: 1.072
Epoch: 7 Minibatch: 701 loss: 0.856
Epoch: 8 Minibatch: 1 loss: 0.752
Epoch: 8 Minibatch: 101 loss: 0.774
Epoch: 8 Minibatch: 201 loss: 0.951
Epoch: 8 Minibatch: 301 loss: 0.945
Epoch: 8 Minibatch: 401 loss: 1.046
Epoch: 8 Minibatch: 501 loss: 0.908
Epoch: 8 Minibatch: 601 loss: 0.922
Epoch: 8 Minibatch: 701 loss: 0.907
Epoch: 9 Minibatch: 1 loss: 0.876
Epoch: 9 Minibatch: 101 loss: 0.811
Epoch: 9 Minibatch: 201 loss: 0.914
Epoch: 9 Minibatch: 301 loss: 1.036
Epoch: 9 Minibatch: 401 loss: 0.968
Epoch: 9 Minibatch: 501 loss: 0.982
Epoch: 9 Minibatch: 601 loss: 0.832
Epoch: 9 Minibatch: 701 loss: 0.910
Epoch: 10 Minibatch: 1 loss: 0.595
Epoch: 10 Minibatch: 101 loss: 0.893
Epoch: 10 Minibatch: 201 loss: 0.813
Epoch: 10 Minibatch: 301 loss: 0.780
Epoch: 10 Minibatch: 401 loss: 0.817
Epoch: 10 Minibatch: 501 loss: 0.881
Epoch: 10 Minibatch: 601 loss: 0.650
Epoch: 10 Minibatch: 701 loss: 0.877
Finished Training
现在我们从测试集中取出8张图片:
点击查看代码
# 得到一组图像
images, labels = iter(testloader).next()
# 展示图像
imshow(torchvision.utils.make_grid(images))
# 展示图像的标签
for j in range(8):
print(classes[labels[j]])
如下:

我们把图片输入模型,看看CNN把这些图片识别成什么:
点击查看代码
outputs = net(images.to(device))
_, predicted = torch.max(outputs, 1)
# 展示预测的结果
for j in range(8):
print(classes[predicted[j]])
预测结果:

可以看到,有两个识别错了; 让我们看看网络在整个数据集上的表现:
点击查看代码
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
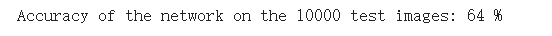
准确率还可以,通过改进网络结构,性能还可以进一步提升。在 Kaggle 的LeaderBoard上,准确率高的达到95%以上。
3.用VGG16进行CIFAR10分类
①定义dataloader
点击查看代码
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
②VGG网络定义
点击查看代码
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
self.features = self._make_layers(self.cfg)
self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(-1, 512)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
初始化网络,根据实际需要,修改分类层。因为 tiny-imagenet 是对200类图像分类,这里把输出修改为200。
点击查看代码
net = VGG().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
③网络训练
点击查看代码
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
训练结果如下:
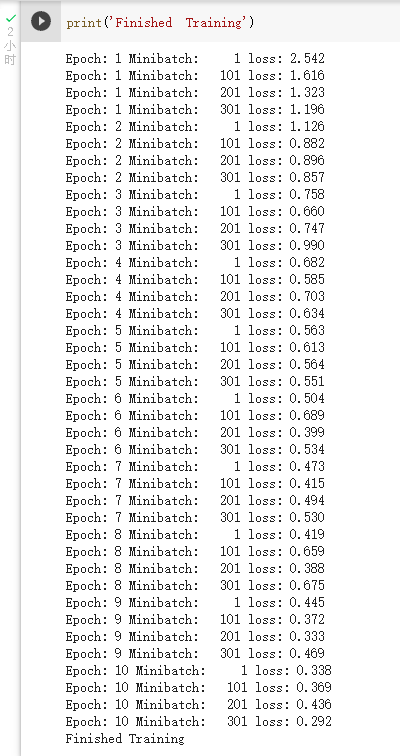
④测试验证准确率
点击查看代码
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))

可以看到,使用一个简化版的 VGG 网络,就能够显著地将准确率由 64%,提升到 84.57%

 浙公网安备 33010602011771号
浙公网安备 33010602011771号