

Hive学习笔记——在Hive中使用AvroSerde
Hive支持使用avro serde作为序列化的方式,参考:
https://cwiki.apache.org/confluence/display/hive/avroserde https://www.docs4dev.com/docs/zh/apache-hive/3.1.1/reference/AvroSerDe.html https://github.com/jghoman/haivvreo
以及CDH官方的文档
https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/cdh_ig_avro_usage.html
1.定义avro schema,kst.avsc
{
"namespace": "com.linkedin.haivvreo",
"name": "test_serializer",
"type": "record",
"fields": [
{ "name":"string1", "type":"string" },
{ "name":"int1", "type":"int" },
{ "name":"tinyint1", "type":"int" },
{ "name":"smallint1", "type":"int" },
{ "name":"bigint1", "type":"long" },
{ "name":"boolean1", "type":"boolean" },
{ "name":"float1", "type":"float" },
{ "name":"double1", "type":"double" },
{ "name":"list1", "type":{"type":"array", "items":"string"} },
{ "name":"map1", "type":{"type":"map", "values":"int"} },
{ "name":"struct1", "type":{"type":"record", "name":"struct1_name", "fields": [
{ "name":"sInt", "type":"int" }, { "name":"sBoolean", "type":"boolean" }, { "name":"sString", "type":"string" } ] } },
{ "name":"union1", "type":["float", "boolean", "string"] },
{ "name":"enum1", "type":{"type":"enum", "name":"enum1_values", "symbols":["BLUE","RED", "GREEN"]} },
{ "name":"nullableint", "type":["int", "null"] },
{ "name":"bytes1", "type":"bytes" },
{ "name":"fixed1", "type":{"type":"fixed", "name":"threebytes", "size":3} }
] }
将schema文件其放到HDFS上
hadoop fs -ls /user/hive/schema Found 1 items -rw-r--r-- 3 hive hive 1131 2021-12-04 13:53 /user/hive/schema/kst.avsc
2.建Hive表
CREATE TABLE default.kst
PARTITIONED BY (ds string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
TBLPROPERTIES (
'avro.schema.url'='hdfs:///user/hive/schema/kst.avsc');
或者直接在TBLPROPERTIES中指定schema
CREATE TABLE default.kst
PARTITIONED BY (ds string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
TBLPROPERTIES (
'avro.schema.literal'='{
"namespace": "com.linkedin.haivvreo",
"name": "test_serializer",
"type": "record",
"fields": [
{ "name":"string1", "type":"string" },
{ "name":"int1", "type":"int" },
{ "name":"tinyint1", "type":"int" },
{ "name":"smallint1", "type":"int" },
{ "name":"bigint1", "type":"long" },
{ "name":"boolean1", "type":"boolean" },
{ "name":"float1", "type":"float" },
{ "name":"double1", "type":"double" },
{ "name":"list1", "type":{"type":"array", "items":"string"} },
{ "name":"map1", "type":{"type":"map", "values":"int"} },
{ "name":"struct1", "type":{"type":"record", "name":"struct1_name", "fields": [
{ "name":"sInt", "type":"int" }, { "name":"sBoolean", "type":"boolean" }, { "name":"sString", "type":"string" } ] } },
{ "name":"union1", "type":["float", "boolean", "string"] },
{ "name":"enum1", "type":{"type":"enum", "name":"enum1_values", "symbols":["BLUE","RED", "GREEN"]} },
{ "name":"nullableint", "type":["int", "null"] },
{ "name":"bytes1", "type":"bytes" },
{ "name":"fixed1", "type":{"type":"fixed", "name":"threebytes", "size":3} }
] }');
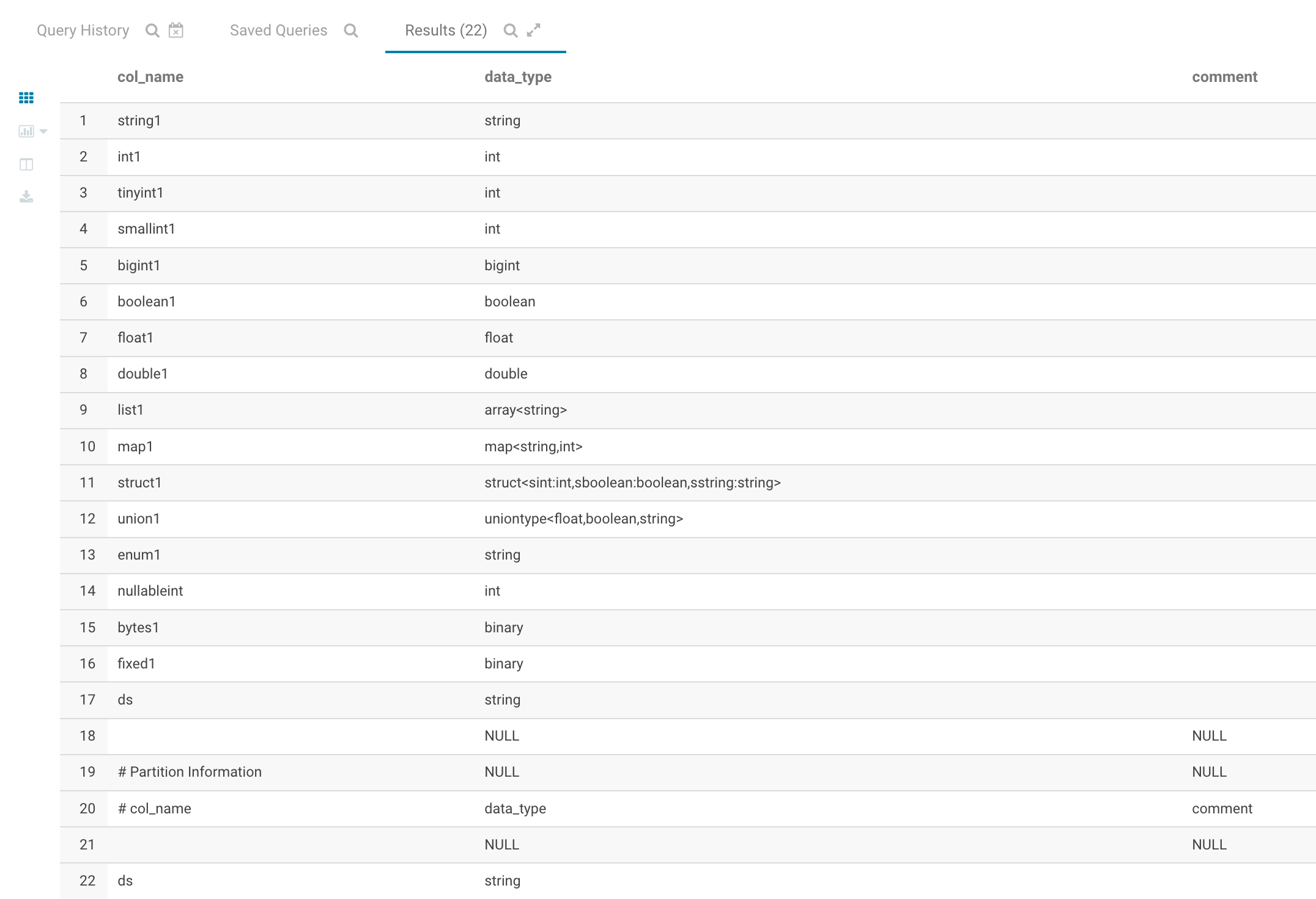
3.查看Hive表的schema
describe kst;
使用show create table查看表结构
CREATE TABLE `default.kst`( `string1` string COMMENT '', `int1` int COMMENT '', `tinyint1` int COMMENT '', `smallint1` int COMMENT '', `bigint1` bigint COMMENT '', `boolean1` boolean COMMENT '', `float1` float COMMENT '', `double1` double COMMENT '', `list1` array<string> COMMENT '', `map1` map<string,int> COMMENT '', `struct1` struct<sint:int,sboolean:boolean,sstring:string> COMMENT '', `union1` uniontype<float,boolean,string> COMMENT '', `enum1` string COMMENT '', `nullableint` int COMMENT '', `bytes1` binary COMMENT '', `fixed1` binary COMMENT '') PARTITIONED BY ( `ds` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' LOCATION 'hdfs://master:8020/user/hive/warehouse/kst' TBLPROPERTIES ( 'avro.schema.url'='hdfs:///user/hive/schema/kst.avsc',
4.插入数据
insert into table default.kst partition(ds="2019-08-20") select "test",2,1Y,2S,1000L,true,1.111,2.22222,array("test1","test2","test3"),map("test123",2222,"test321",4444),
named_struct('sInt',123,'sBoolean',true, 'sString','London') as struct1,create_union(0,cast(0.2 as float),false,"test3"),"BLUE",12345,"00008DAC",'111';
5.查看刚刚insert的数据

本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/5241954.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号