数据结构的python实现,树之前
算法与数据结构,是为了更好的利用有限的资源干更有性价比的事情。
比如搜索,不要浪费算力,我懒,我找到了更快更好的方法去搜索,这就是算法,我改变数据结构,是为了方便算法的执行。
算法(algorithm)
时间复杂度,是拟合数学函数,寻找近似的用big O表示
要关注最坏时间复杂度。
时间复杂度的计算规则:
1,顺序结构 加法
2,循环结构 乘法
3,分支结构 取最大的时间复杂度
比较常见的时间复杂度(从小到大)
O(1) O(n) O(n2) O(logn) O(nlogn) O(n3) O(2n) O(n!) O(nn)

哈希结构的时间复杂度是O(1)
线性查找是O(n)
树状结构是O(log26n)
评价算法还要考虑空间复杂度,占用的内存太多就是空间复杂度高
python也有内置的timeit模块,里面有相应的方法能够判断时间
数据结构分为:
线性结构 树状结构 图状结构
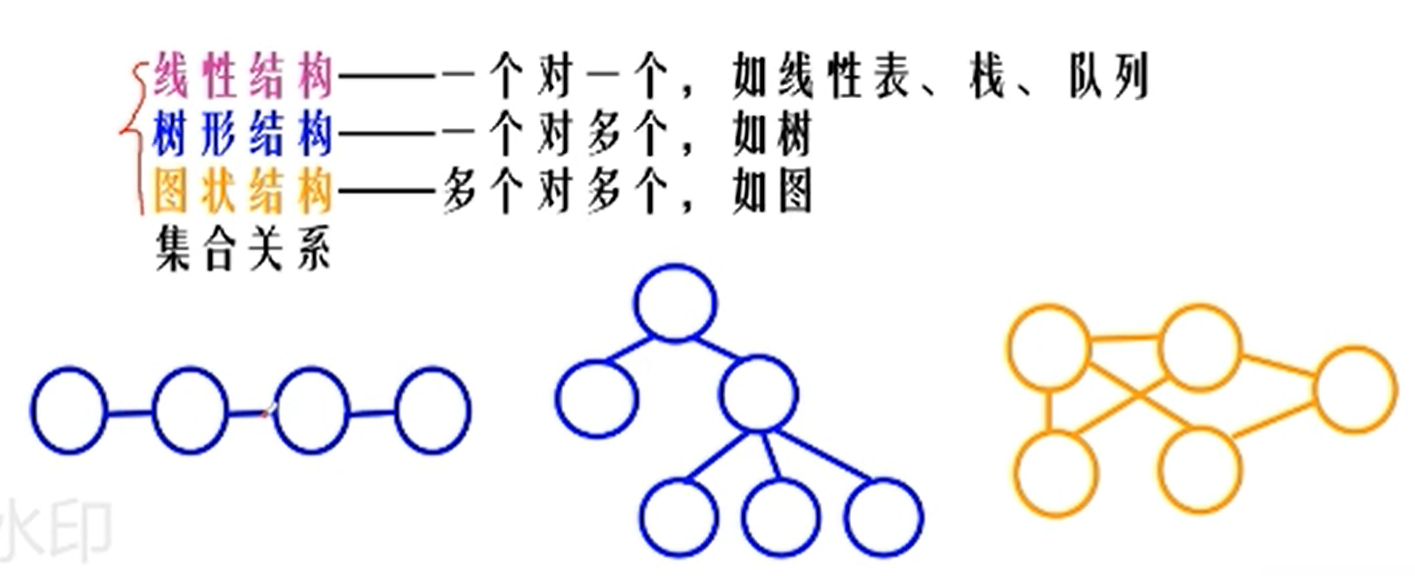
举个例子,
#线性结构
比如学生的学号,姓名,成绩,年级 这就是线性的结构构成的是线性表
线性表的操作主要有查找,修改,插入,删除
节点是一对一的关系
#树状结构
比如大学的专业类别,先分学院 再细分专业大类,再具体到xx专业。
树型结构的操作主要有查找,修改,插入,删除
节点是一对多的关系
#图状结构
比如通信网络问题,每个城市之间都有网络通路,通信距离和费用不同
节点是多对多的关系
这些是数据结构的逻辑表达
比较形象
我们的数据结构在计算机中,需要知道物理结构。
这也叫做数据的存储结构。
数据在内存中有两种存放形式:
顺序存储(元素在存储器中的相对位置)
链式存储(元素存储地址的指针)
#顺序存储
数组删除其中元素,会将元素所在的位置也删除,后一个元素补在这个位置上。这是为了保证数组元素是紧密相连的,为了维护数组。
现在如果要新增那个被删除的元素到原来的位置,要怎么办???
先找到需要被插入的位置,如果位置上已经有元素了,从最后一个元素先开始移动,依次腾出位置。
顺序存储是不适合做插入和删除操作的。123456789
#链式存储

2号学生的地址会存在1号那里。 13号学生的地址会存在12号那里。
我们想找任意的学生地址,我们要找1号学生才能找到别的学生在哪里。
如果说这个时候,我要删除4号元素,怎么做???
4号知道5号的地址,3号知道4号的地址
现在让3号知道5号的地址,就可以了
也就是让3号知道的内容(4号的地址)替换成5号点的地址就可以了
那么现在我想在3和5之间把4加回来
那么4号现在手里有自己的地址
4号要把自己的地址告诉3号学生,让3号存放;
3号把5号的地址告诉4号。让4号存放。
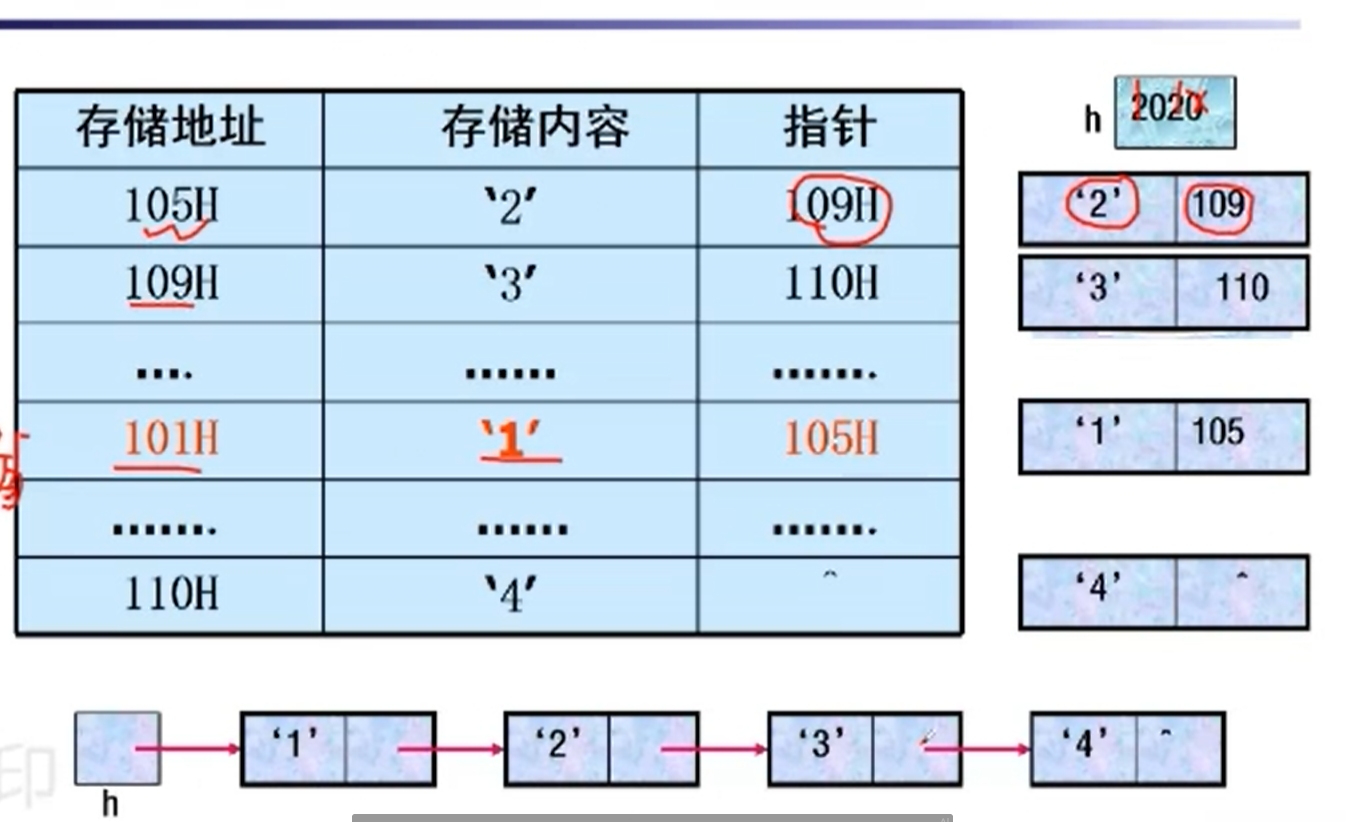
这就是链表结构,逻辑关系是通过指针的链接来实现的。
那么一个框就是一个结点(node)
这个存储空间的利用率低,因为每一个节点都存放地址。
链式存储插入和删除很方便。
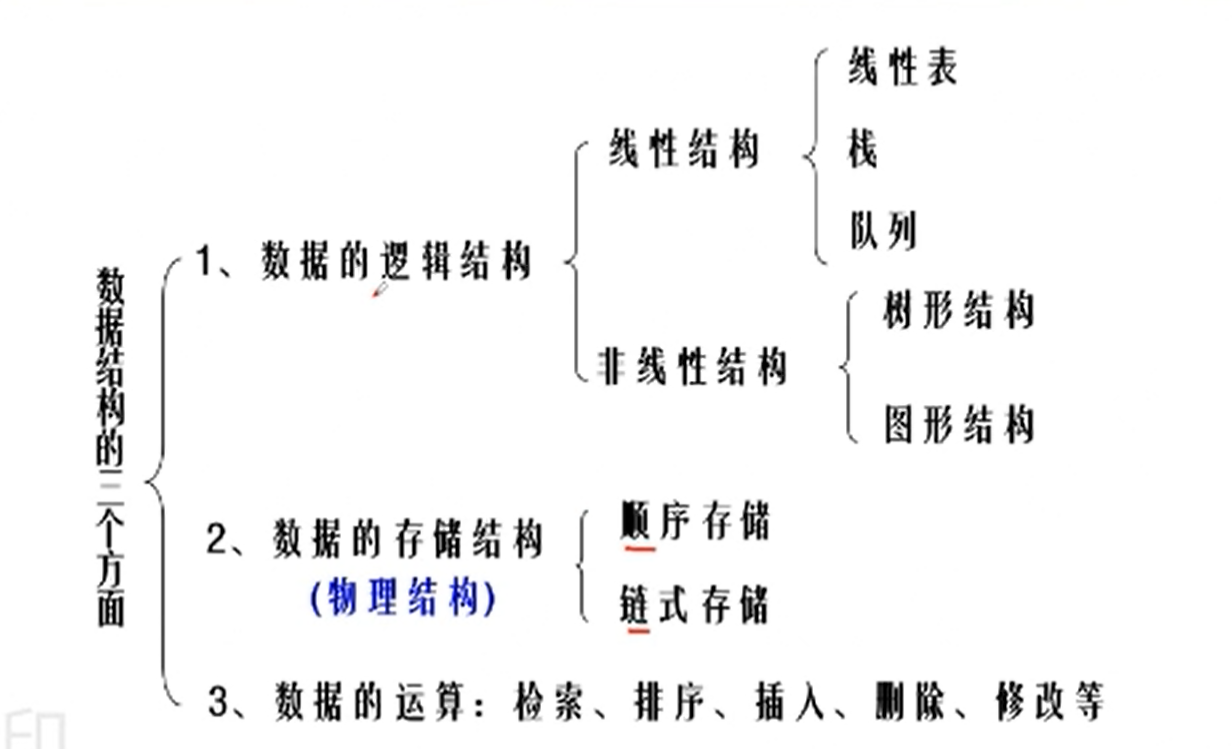
我们要知道数据的逻辑结构是怎么样的存储方式。
线性结构有顺序存储和链式存储两种方式。
我们存进去以后,他们的增删改查方式是不同的,要学它们。
我们遇到一个问题。
第一步,对问题进行思考。它适合什么样的逻辑结构,建立数学模型,选择合适的逻辑结构来抽象。
第二步,有了逻辑结构,思考怎么在计算机里面存储,顺序存储还是链式存储,还是两者复合的。
#线性表
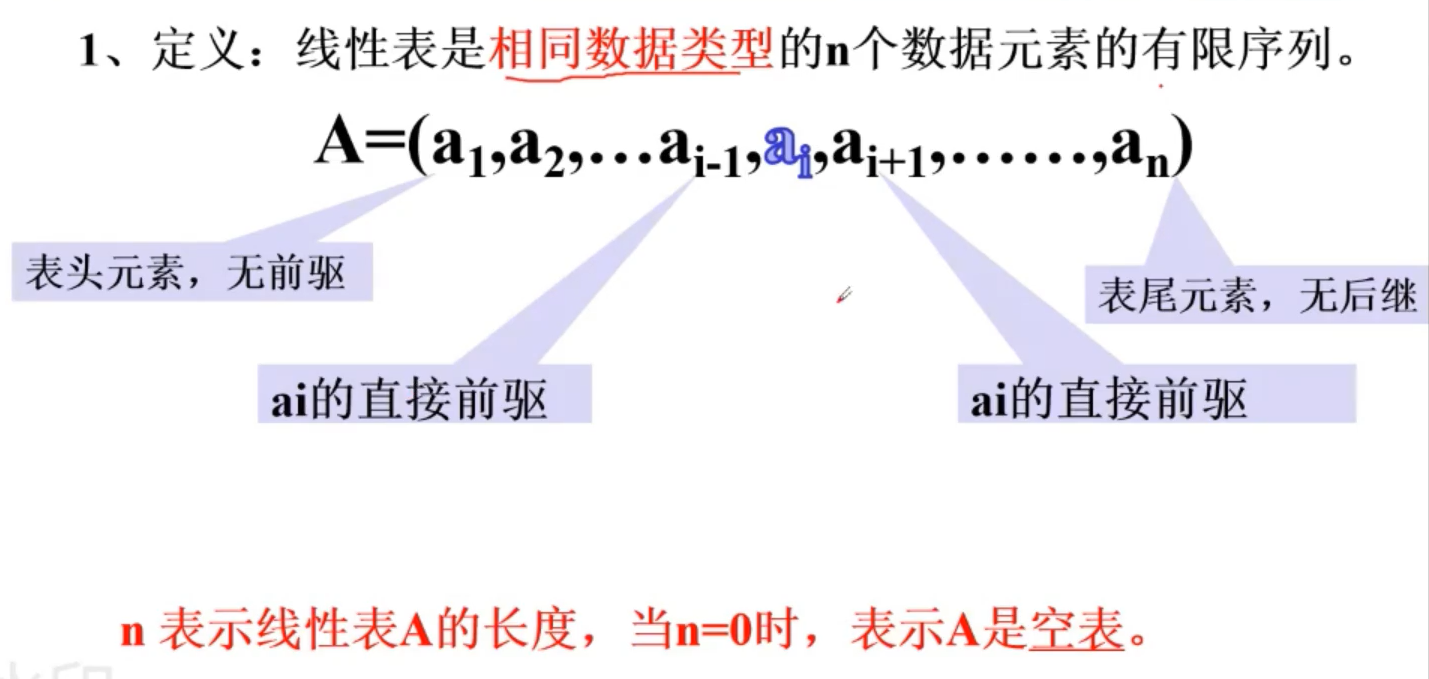
举例子,比如
L1=(1,2,5,4,3,6,4)
L2=(“阿斯顿”,“阿斯顿啥的”,“高峰会上”)
L3=((“张明”,18),(“私单”,93),(“南山”,938))
线性表基础操作
在python里面,顺序表的实现是使用list和tuple实现的
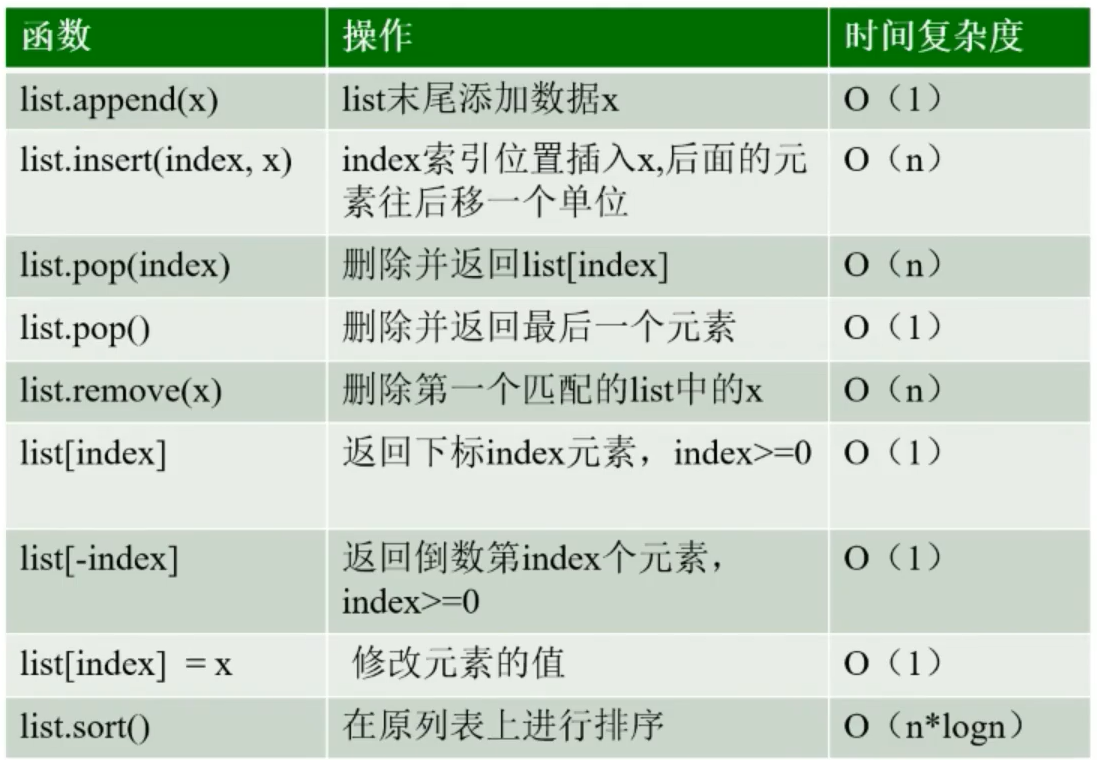
列表是动态的顺序表,会自动扩容
单链表
头插法。就是给列表的头元素加内容。,现在先创造想要插入的结点,让列表的next结点等于原来的head结点,再让head等于新插入的那个结点。这样就在head结点位置上插入了新的结点
我们遍历一下我们加完结点的单链表:
就是用一个游标来遍历,currentpin=head
然后看currentpin指针指向的地址存放的内存是不是空,如果不是,就print currentpin.data,也就是指针指向的这个节点的数据域,然后让这个指针变成指针的值的部分,这样也就是下一个结点的数据域部分了。
求链表的长度,也可以用这个游标指针来计算,移动一次,计数就加一
尾插法。就是在链表的末尾添加元素。先用游标移动到最后一个结点,指着最后一个元素的数据域。然后新建一个结点s,让这个currentpin.next=新建的结点s
双链表
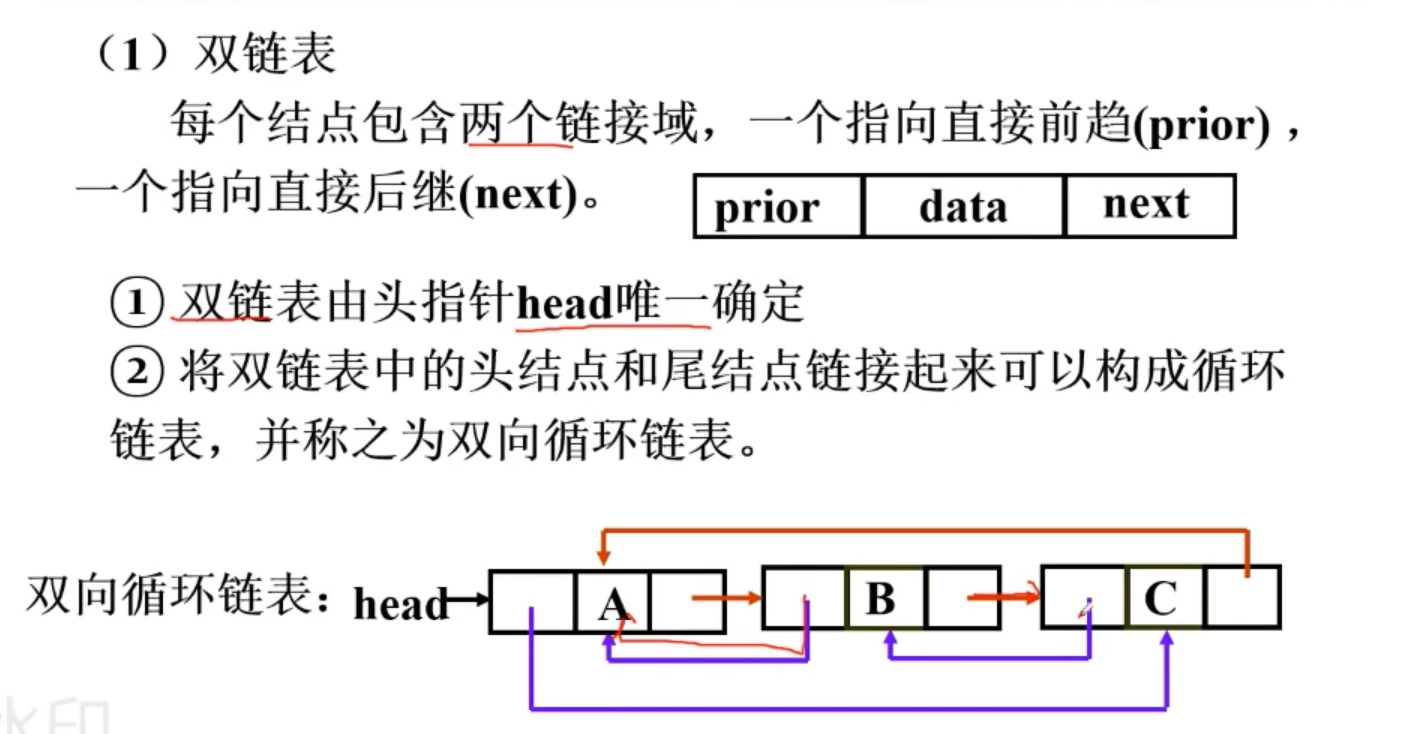
这边解释一下,prior data next分别是怎么用的:
比如说p指针指着ai,那么p.prior就等于ai-1, p.next就等于ai+1
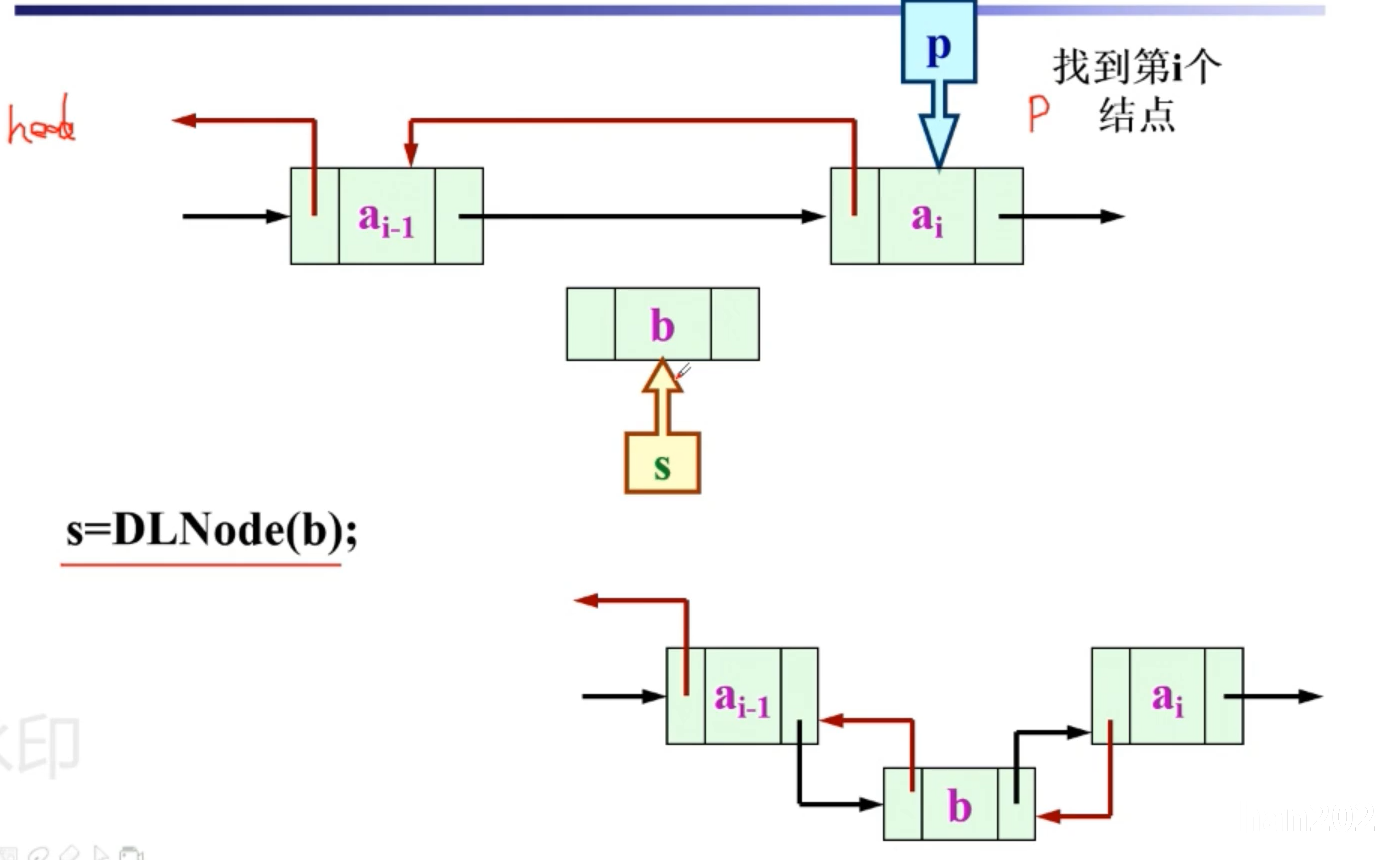
我们在双向循环链表中添加元素的话,我们只使用指针p和新结点s来添加s结点进去
第一步:p.prior.next=s#就是让p-1的next部分指向s,而不是指向p
第二步:s.prior=p.prior#让s的prior部分指向p-1
第三步:p=s.next#让s的next部分指向p
第四步:p.prior=s#让p的prior部分指向s
其实就是把这个结点通过前后的连接部分缝上了四根线
删除结点的时候,还是只用p来描述
p.prior.next=p.next
p.next.prior=p.prior
顺序表的合并
比如我有两个顺序表
L1=(1,3,4,7,8)
L2=(2,5,6,9,10)
我怎么合并这两个顺序表,并且是升序排列的???
就是提取L1中的第一个元素和L2中的第一个元素,比较两个元素的大小,把小的那个数添加到新顺序表L3中,假设这里是L1的第一个元素更小
然后提取L1中的第二个元素,再和L2中的第二个元素比较,谁小就添加到L3中.........
python中是使用list的下标索引,来比较list的index指向的值比较
循环比较结束的条件就是短的那个列表已经遍历完的时候。
链表的合并
方法1:
不改变链表a和链表b
将两个链表的指针指向的data部分比较,谁的data小,就把这个结点添加到新的链表c中,比如说比较完以后数据1比较小
我们生成一个新的结点叫s,让s的数据域等于1,然后让链表c指向这个新节点s,让lc的尾指针指向链表c的最后一个结点
然后其中一个链表指针移动,比较后,还是生成s,s.data等于那个小的值。让s.next指向s然后让tail指向s
方法2:
采摘结点法:
链表c有一个头指针lc和尾指针tail,分别都是空,tail和lc都是结点。然后两个链表的指针对比,谁的data小,让tail指向那个链表的指针,那个链表的指针往后移动1位
然后比较完以后,让tail.next等于那个链表的指针
栈和队列
栈和队列是指插入和删除只能在表的一端进行的线性表
所以栈和队列是操作受限的线性表
栈:只能在线性表的末尾删除元素,只能在线性表的末尾添加元素
队列:只能在线性表的末尾添加元素,只能在线性表的表头删除元素
#栈
可以用汉诺塔距离,最后来的最先取出,后进先出。
python实现顺序栈使用列表list
有list.append()方法和list.pop()方法,分别代表入栈和出栈的功能
如果是链栈的话,
#队列
先进的先出,
循环队列
用一个front指针,
front指针指的人出队了,front指针往后移一个
rear指针始终指向队尾,元素入队了,那么rear指针往后移一个
如果说队列长度是M,front是0,rear是m-1,这个时候队满了,不能再进了,真的溢出了
如果说队列长度是M,front不等于0,rear是m-1,这个时候队满了,能再进,是假的溢出
为了避免这种出队了但是入队被判断假溢出,将front和rear连接,形成循环队列
也就是说当front或者rear加一以后等于M了,那么就让front或者rear等于0
我们用python里面的取余符号可以简写成
入队的话:rear=(rear+1)%M
出队的话:front=(front+1)%M
怎么判断循环队列的队是空的还是满的,都是指针重合的情况,
这里判断队空还是看指针重合,front==rear
队满的话,在入队之前,也就是front+1之前,先看一下front+1会不会等于rear,如果会的话,就表示这个时候是队满的了。#这里的话是牺牲了一个空的空间,其实这个时候队是有一个空的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号