

pyspark 针对Elasticsearch的读写操作
1.创建spark与Elasticsearch的连接
为了对Elasticsearch进行读写操作,需要添加Elasticsearch的依赖包,其中,添加依赖包(org.elasticsearch_elasticsearch-spark-20_2.11-6.8.7.jar)有下面的三种方式:
1)将依赖包直接放在安装spark目录下面的jars目录下,即可;
2) 在提交任务时,利用spark submit --jars 的方式
3)在创建spark对象时,添加依赖,如下图所示
spark = SparkSession \
.builder \
.appName('es connection') \
.config('spark.jars.packages', "org.elasticsearch_elasticsearch-spark-20_2.11-6.8.7") \
.getOrCreate()
2.spark 读取Elasticsearch的数据
df3 = spark.read \
.format("org.elasticsearch.spark.sql") \
.option("es.nodes", '节点') \
.option('es.port', '端口') \
.option("es.resource", '索引/索引类型') \
.option('es.query', '?q=*') \
.option('es.nodes.wan.only','true') \
.option("es.nodes.discovery", "false") \
.option("es.index.auto.create", "true") \
.option("es.write.ignore_exception", "true") \
.option("es.read.ignore_exception","true") \
.load()
3.spark 写入elasticsearch
df.write.format('org.elasticsearch.spark.sql') \
.option('es.nodes', '节点') \
.option('es.port', '9200') \
.option('es.nodes.wan.only', 'true') \
.option("es.nodes.discovery", "false") \
.option('es.resource', '索引/索引类型') \
.save(mode='append')
备注:
当spark读写elasticsearch的过程中,elasticsearch包含Array类型的字段,就会出现下面错误:
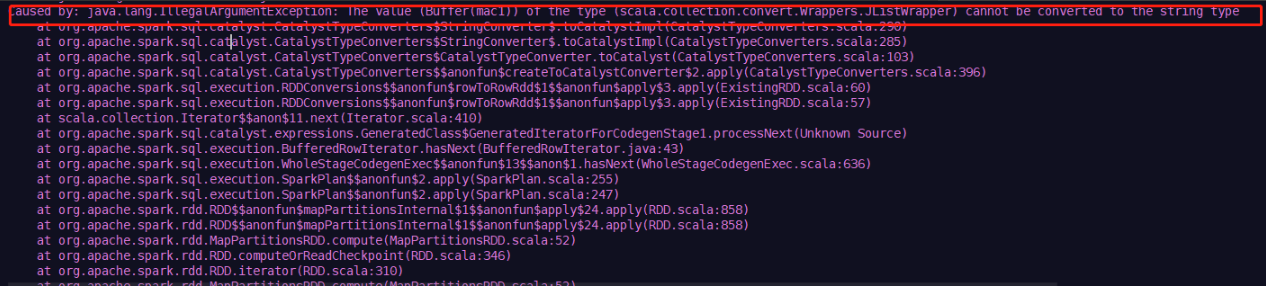
无法将List类型数据写入到es, 或者从es读出list类型数据
解决方案:
在option 中添加一个es.read.field.as.array.include属性,value为list Schema的字段名
posted on 2020-10-27 17:10 random_boy 阅读(2236) 评论(4) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号