

hive-3.0.0 版本中遇到的bug 汇总
目前公司用的hive 版本是 hive-3.0.0 bug 较多,这里汇总整理下,以备查阅 (如有缺失欢迎补充)
1.表单属性bucket_version 不同,导致join数据异常
1.1 自查方式
1.用spark-sql和hive 的结果数据对比
2.用hive引擎对比有无 hive.optimize.joinreducededuplication=false 参数时的结果
目前生产环境发生数据丢失过的场景有
1.2 发生的场景有
- 多个不同 bucketing_version属性的表单进行join,且reduce个数大于2时,存在数据丢失
- 两个不同 bucketing_version 属性的表进行join时,且 有子查询里有group by时存在数据丢失
- presto 创建的表单,create table xxx like语句创建的表单都因缺失bucketing_version属性,在和其他hive 表关联计算时都有这个数据丢失的风险
1.3 修复方式
如果有出现数据异常的,可以根据实际情况自愿选择3种修复方式
- hive-site.xml 中设置表的默认建表属性值 hive.table.parameters.default = 'bucketing_version=2';
- 设置优化参数: set hive.optimize.joinreducededuplication=false ;
- 修改表结构属性: alter table [tablename] set tblproperties('bucketing_version'='2');
- 先用create table as select xxxx 创建临时表的方式将不同bucket_version的取数结果分别用临时表来封装,再来join
1.4 相关社区文档
在一些特殊场景join 时存在数据丢失的情况,相关文档
https://issues.apache.org/jira/browse/HIVE-24033
https://issues.apache.org/jira/browse/HIVE-22098
2.group by和distinct 字段个数不能超过64个, 否则报错异常
2.1 异常确认
关键字:
SemanticException [Error 10411]: Grouping sets size cannot be greater than 64

2.2 避坑说明
这类场景毕竟少见,可以将string类型的字段通过 concat_ws 拼接起来group by,然后拆分
2.3 社区相关链接
到 4.0 版本有修复,可以考虑合入该patch
https://issues.apache.org/jira/browse/HIVE-21018
3.container 重用导致的bug,多个dag 共用一个container导致, 导致container 的输出文件异常
3.1 异常确认
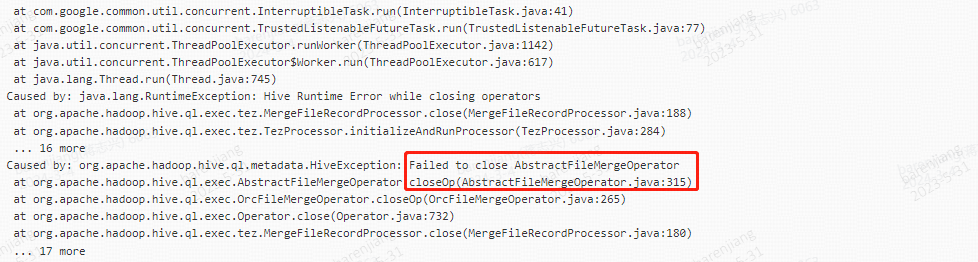
3.2 避坑参数说明
该类异常仅发生在hql文件中有多个sql语句(会生成tez任务的ddl语句),或者有小文件合并参数中,因不是必现的,小概率会发生,且设置到为true 时会,每个语句会多消耗一个container,没有在集群层面设置, 有出现过错误的或者任务比较重要的可以设置该参数避免出现该类错误
set tez.am.container.reuse.enabled=false;
3.3 社区相关链接
到 4.0 版本有修复,可以考虑合入该patch
https://issues.apache.org/jira/browse/HIVE-22373
4.container 重用导致的bug
4.1 异常确认
出现如下关键字
Was expecting dummy store operator but found:
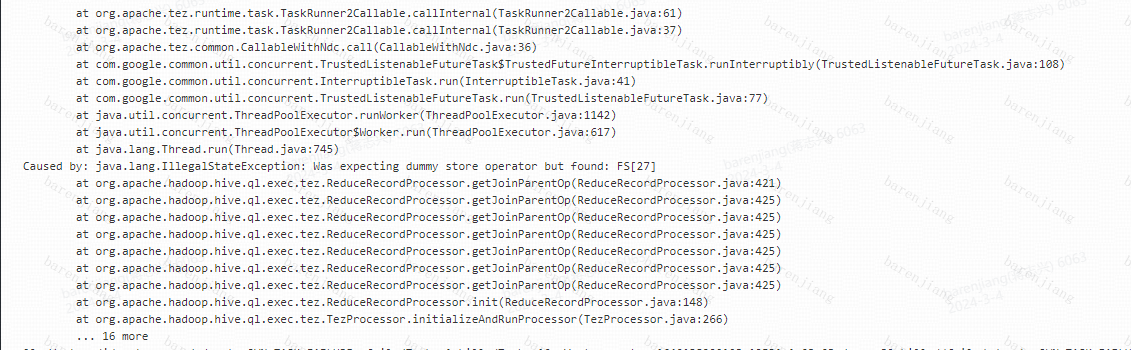
Tez的bug导致,container复用打开后,同一container在成功运行完mergejoin/groupby reduce任务后,执行同一个vertex的其他reduce任务时可能触发报错。
4.2 避坑参数说明
set tez.am.container.reuse.enabled=false;
4.3 相关社区链接
https://issues.apache.org/jira/browse/HIVE-23010
5.merge task跑到了default队列
5.1 异常确认
在任务的运行日志中如果有 File Merge的profile,找到对应appid,在tez-ui 中可以看到运行队列
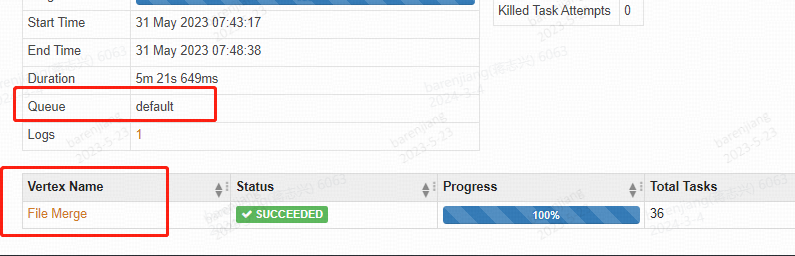
5.2 避坑参数说明
目前没有合适的参数避免该问题,且该问题影响面较小, 暂时不用做特殊处理,后续考虑合入社区patch
5.3 相关社区链接
https://issues.apache.org/jira/browse/HIVE-22527
6.sort-merge semijoin导致的异常
6.1 异常确认,报错中含有如下关键字
Attempting to overwrite nextKeyWritables[1]

6.2 避坑参数说明
在启用sortmerge join 时会偶尔发生该类问题,关闭sortmerge join即可
set hive.auto.convert.sortmerge.join=false;
6.3 相关社区链接
https://issues.apache.org/jira/browse/HIVE-24073
7.查询结果为空的情况下,目标表/分区数据并不会被清理
7.1 异常确认
如题,查询结果为空的情况下,insert overwrite 不会清空目标表里的数据和目录, 理论上目标目录下的数据应该要被清空的
7.2 避坑说明
目前还没有好的避坑方法, 后面可以考虑合并此类patch,社区已有相关jira单
7.3 相关社区链接
https://issues.apache.org/jira/browse/HIVE-21714
8.mapjoin 导致的数据丢失
8.1 异常确认
任务没有报错,查询语句中有lateral view explode 关键字,结果数据不写入结果表的情况下正常查询,在写入到结果表后数据丢失
可以尝试使用 set hive.auto.convert.join=false,再执行一次,如果查询结果返回正常 说明是mapjoin 导致的bug
8.2 参数避坑说明
1.设置参数 hive.auto.convert.join=false, 避免出现此类问题
2.将 有lateral view explode 部分的子查询改为先写入到临时表,再最后mapjoin时
8.3 社区相关链接
https://issues.apache.org/jira/browse/HIVE-11576
9.dynamic semijoin导致的异常
9.1 异常确认
执行任务时,编译解析sql报错:java.lang.NullPointerException at org.apache.hadoop.hive.ql.parse.TezCompiler.removeSemijoinOptimizationByBenefit
且sql 中存在join情况
9.2 参数避坑说明
set hive.tez.dynamic.semijoin.reduction=false;
这个配置可以禁用semi join优化,从而规避该问题,但需注意不建议集群全局加上这类配置,会导致本该优化的semi join失效。
9.3 社区相关
https://issues.apache.org/jira/browse/HIVE-24671
https://issues.apache.org/jira/browse/HIVE-22572
10.cube 数据重复异常
10.1 异常确认
执行的sql语句中有 cube关键字,cube字段中有常量值
查询验证,相同的组合有两天相同的记录
10.2 避坑说明
初步判断是和cube 中有常量字段有关,将常量字段移除cube,或者先写入到临时表中可以避免此类问题
10.3 社区相关说明
https://issues.apache.org/jira/browse/HIVE-17499
11.hiveserver2 因频繁加载临时函数导致的内存泄漏问题
11.1 异常确认
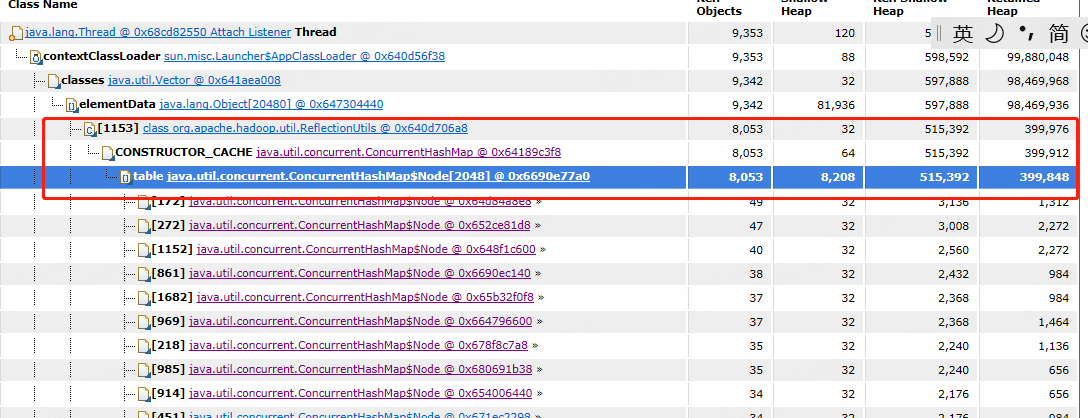
11.2 避坑说明
目前还没有参数设置可以避免此类问题,只能通过patch修复这类问题
11.3 社区相关说明
https://issues.apache.org/jira/browse/HIVE-11408
https://issues.apache.org/jira/browse/HIVE-24636?focusedWorklogId=558506&page=com.atlassian.jira.plugin.system.issuetabpanels%3Aworklog-tabpanel#worklog-558506
12.hive 在join时或者语句中存在exists时,且有非等值得过滤时,cbo会将谓词下推到join时导致结果异常
12.1 异常确认
检查执行语句结果出现数据异常
12.2 避坑说明
关闭cbo优化器即可
set hive.cbo.enable=false;
12.3 社区相关说明
https://issues.apache.org/jira/browse/HIVE-18490
13.在left join 的语句中,如果子查询中有union 和group by时,会导致查询结果异常
12.1 异常确认
可以对比 presto/spark 和hive 的结果
12.2 避坑说明
子查询中尽量避免同时使用 union和 group by 语句,目前社区还没有解决方案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号