


8gu-RPC框架
Rpc框架
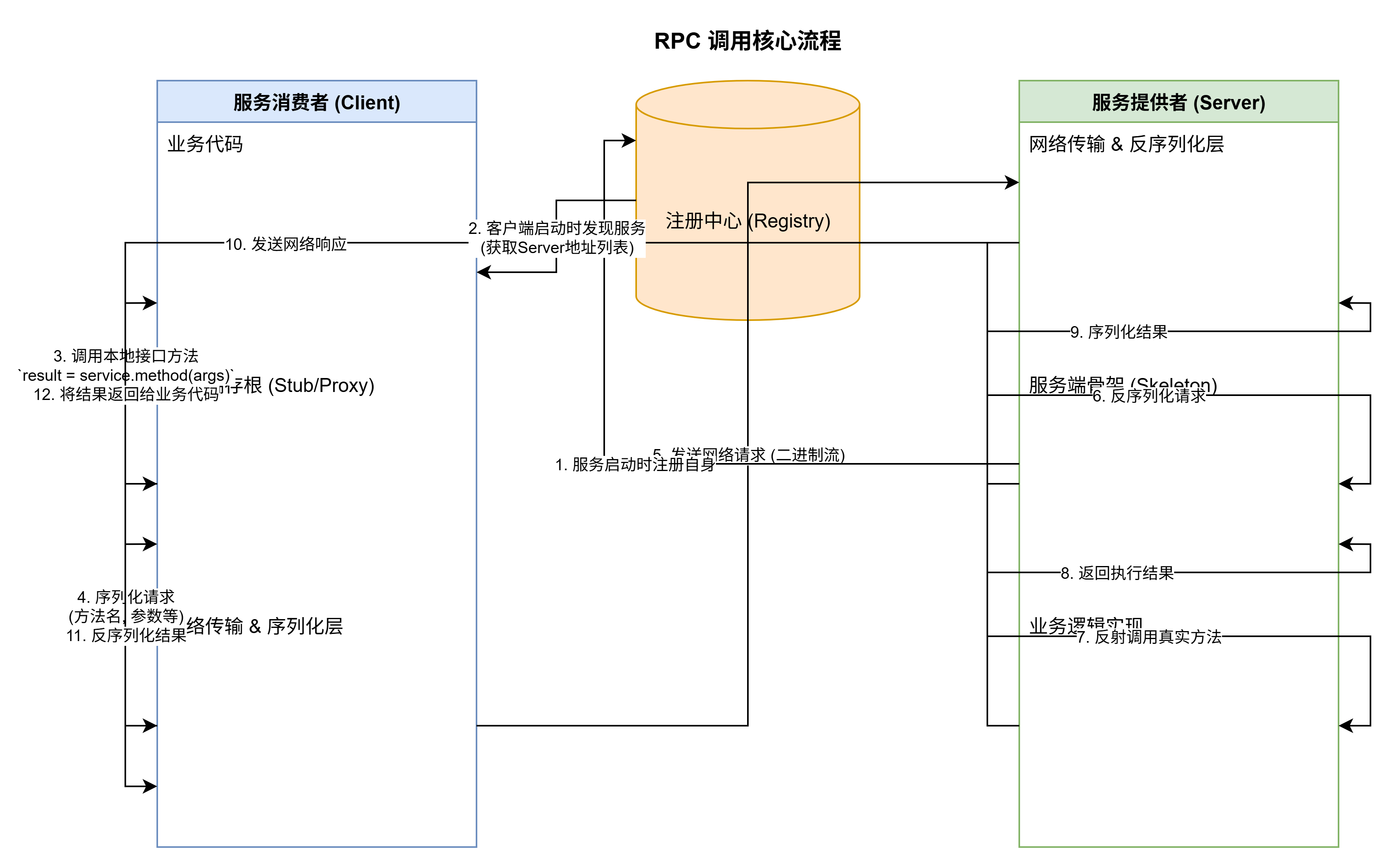
RPC框架的基本原理
RPC(Remote Procedure Call,远程过程调用)的核心目标是让调用远程服务(位于另一台机器或另一个进程中)就像调用本地方法一样简单,完全屏蔽底层的网络通信细节。为了实现这一点,RPC 框架主要依赖以下几个核心组件和流程。
核心组件
-
客户端存根 (Client Stub):
- 这是一个存在于客户端的代理对象。它实现了与远程服务完全相同的接口。
- 当开发者调用这个代理对象的方法时,它并不执行实际的业务逻辑。相反,它的任务是打包调用的信息(如方法名、参数),然后启动网络通信过程。
-
服务端骨架 (Server Skeleton):
- 存在于服务端,负责接收来自客户端的请求。
- 它的任务是解包请求数据,识别出客户端想要调用哪个具体的方法和传入的参数是什么。
- 然后,它会调用本地真正的业务逻辑实现,并将执行结果返回给客户端。
-
序列化与反序列化 (Serialization & Deserialization):
- 序列化:在客户端,将内存中的对象(如方法参数)转换成二进制字节流,以便在网络上传输。
- 反序列化:在服务端,将接收到的二进制字节流再转换回内存中的对象。返回结果时过程相反。
- 常见的协议有:Protobuf, JSON, Kryo, Hessian。
-
网络传输层 (Transport Layer):
- 负责在客户端和服务端之间可靠地传输二进制数据。
- 通常基于 TCP (for reliability) 或 HTTP/2 (like gRPC) 协议。管理网络连接的建立、维护和关闭。
-
服务注册与发现 (Service Registry & Discovery) (在分布式系统中至关重要):
- 服务注册:服务端启动时,将自己提供的服务名称及地址(IP:Port)注册到一个中心化的“注册中心”(如 Nacos, Zookeeper, Consul)。
- 服务发现:客户端启动时,向注册中心查询它所需要的服务地址列表。这样,客户端就不需要硬编码服务端的地址,实现了服务解耦和动态扩缩容。
工作流程
- 服务注册:服务提供方(Server)启动,并将其服务信息注册到注册中心。
- 服务发现:服务消费方(Client)启动,从注册中心订阅并获取所需服务的地址列表。
- 发起调用:客户端代码调用本地的接口方法,实际上调用的是客户端存根(Stub)的代理方法。
- 序列化:存根将方法名、参数等信息进行序列化,打包成一个二进制消息。
- 网络发送:客户端通过网络传输层将该消息发送到服务端的一个地址(可能会涉及负载均衡)。
- 网络接收:服务端骨架(Skeleton)接收到网络消息。
- 反序列化:骨架对消息进行反序列化,解析出方法名和参数。
- 本地调用:骨架通过反射等机制,调用本地的、真正的业务逻辑实现,并得到结果。
- 结果返回:骨架将执行结果(或异常)序列化,通过网络层发送回客户端。
- 接收结果:客户端存根接收到响应消息,并反序列化得到最终结果。
- 返回调用方:存根将结果返回给最初调用它的业务代码,一次完整的 RPC 调用结束。
面试问题
1.美团牧羊人网关的实现流程
核心原理:协议转换与反向代理
整个过程可以概括为:牧羊人网关作为客户端和服务端之间的中间层,它对外暴露 HTTP 协议接口,对内则使用 RPC 协议调用后端微服务。它扮演了一个“翻译官”和“交通警察”的角色。
这个转换过程主要包含以下几个关键步骤和组件:
工作流程详解
假设一个移动 App 向美团发送一个 HTTP 请求,例如获取某个商家的外卖菜单,其流程如下:
1. 请求接收与路由分发 (Request Reception & Routing)
- 接收 HTTP 请求:用户的请求首先通过 DNS 解析、负载均衡(如 LVS/Nginx)到达牧羊人网关集群中的某一台机器。
- 路由匹配:牧羊人网关会根据请求的 URL 路径、域名、HTTP Method 等信息,去匹配预先配置好的路由规则。这个路由规则表会告诉网关:这个进来的 HTTP 请求应该由后端的哪一个 RPC 服务(例如
menu-service)的哪一个方法(例如getMenuItems)来处理。- 例子:HTTP 请求
POST /api/v1/menu/items可能会被路由到 RPC 服务com.meituan.food.MenuService的getMenuItems方法。路由配置是网关的核心。
- 例子:HTTP 请求
2. 参数解析与协议转换 (Parameter Parsing & Protocol Conversion)
这是转换的核心环节。
-
解析 HTTP 参数:网关会从 HTTP 请求中提取所需的数据。
- HTTP Body: 如果是
POST请求,网关会解析 Body 中的 JSON 或其他格式的数据。 - Query String: 解析 URL
?后面的查询参数(如shopId=123)。 - Path Variables: 解析 URL 路径中的变量(如
/shop/123中的123)。 - Headers: 解析 HTTP 请求头中的通用信息,如用户凭证(Token)、设备信息等。
- HTTP Body: 如果是
-
构建 RPC 请求:网关将上一步解析出来的松散的 HTTP 参数,按照后端 RPC 服务的接口定义(通常是 IDL,如 Thrift 或 Protobuf 定义),组装成一个结构化的 RPC 请求对象。
- 例子:网关会创建一个
GetMenuItemsRequest的 Java 对象(或等效的 RPC 请求结构),并将从 HTTP 请求中解析出的shopId、userId等值填充到这个对象的相应字段中。这个过程就像是数据格式的“重新打包”。
- 例子:网关会创建一个
3. 服务发现与负载均衡 (Service Discovery & Load Balancing)
在真正发起 RPC 调用之前,网关需要知道 menu-service 这个服务具体在哪台机器上运行。
- 服务发现:网关会去查询一个服务注册中心(美团早期使用自研的 MNS,现在可能使用其他组件如 Zookeeper、Nacos 等)。它向注册中心询问:“请告诉我
menu-service所有健康实例的 IP 地址和端口列表”。 - 负载均衡:注册中心返回一个地址列表后,网关的客户端会根据内置的负载均衡策略(如轮询、随机、加权等),从中选择一台具体的后端服务器来发送接下来的 RPC 请求。
4. RPC 调用与序列化 (RPC Invocation & Serialization)
- 序列化:网关将第二步中构建好的 RPC 请求对象,通过 RPC 框架的序列化机制(如 Thrift、Protobuf)转换成二进制字节流。
- 网络传输:网关作为 RPC 客户端,通过底层的网络协议(通常是 TCP 长连接),将这个二进制字节流发送到上一步选定的后端服务器上。
5. 后端服务处理 (Backend Service Processing)
- 后端的
menu-service服务器接收到 RPC 请求,反序列化成对象,执行其业务逻辑,然后将执行结果(GetMenuItemsResponse对象)返回给牧羊人网关。
6. 结果转换与 HTTP 响应 (Result Conversion & HTTP Response)
- 接收 RPC 响应:牧羊人网关接收到后端服务返回的 RPC 响应数据(二进制流)。
- 反序列化:网关将其反序列化为 RPC 响应对象。
- 构建 HTTP 响应:网关从 RPC 响应对象中提取数据,将其转换成前端需要的格式(通常是 JSON),并构建一个标准的 HTTP 响应。这包括:
- HTTP Status Code: 如 200 (成功), 404 (未找到), 500 (后端错误) 等。
- HTTP Headers: 设置
Content-Type: application/json等。 - HTTP Body: 将转换后的 JSON 数据放入响应体中。
- 返回给客户端:最后,网关将这个构建好的 HTTP 响应发送回给最初发起请求的移动 App。
流程图
下面是一个简化的流程图,清晰地展示了整个转换过程:
总结
美团牧羊人网关的核心作用就是解耦。它让前端开发者(移动/Web)可以继续使用他们熟悉的、无状态的、标准的 HTTP/JSON 协议进行开发,而后端微服务团队则可以专注于使用高性能、强类型的 RPC 框架(如 Thrift)来构建服务。网关承担了两者之间协议和数据格式转换的全部复杂工作,同时还集中处理了路由、认证、限流、监控等通用功能。
2.rpc架构中,注册与发现,客户端每次调用都需要去注册中心去查服务端的信息吗?
这是一个非常棒的 RPC 架构核心问题!
答案是:绝对不是。客户端每次调用都去查询注册中心,会带来灾难性的性能问题和可用性风险。
正确的做法是“首次查询 + 本地缓存 + 订阅更新”的模式。
1. 为什么不能每次都查询?
让我们先分析一下如果每次调用都去查询注册中心,会发生什么:
-
性能瓶颈:
- 增加网络开销: 每一次 RPC 调用都会变成两次网络请求(客户端 -> 注册中心 -> 服务端)。这使得 RPC 的网络延迟至少增加了一倍。
- 注册中心压力过大: 注册中心会成为整个系统的核心瓶颈。假设有 1000 个客户端实例,每个实例每秒调用 100 次某个服务,那么注册中心每秒就要承受
1000 * 100 = 10万次的查询请求。这对于任何一个注册中心来说都是巨大的压力。
-
可用性风险:
- 引入单点故障: 如果注册中心发生抖动或宕机,哪怕只有一秒钟,那么这段时间内所有的 RPC 调用都会失败,即使后端的服务提供方是完全健康的。这极大地降低了系统的整体可用性。
把注册中心想象成一个“电话信息查询台(114)”。你肯定不会每次想给朋友打电话时,都先打 114 去查询他的号码。你会在第一次查询后,把号码存到你的手机通讯录里,下次直接从通讯录里找。这个“通讯录”就是本地缓存。
2. 标准的实现方式:缓存与订阅
一个健壮的 RPC 框架通常采用以下流程来解决这个问题:
核心步骤:
-
启动时拉取 (Pull on Startup):
- 当客户端(服务消费者)应用首次启动时,或者第一次调用某个服务时,它会向注册中心发起一次查询请求,获取该服务当前所有健康的服务提供者实例列表(比如 IP 地址和端口号)。
-
建立本地缓存 (Local Cache):
- 客户端会将拉取到的服务列表缓存到自己的内存中。这个列表就是后续进行负载均衡的基础。
-
后续调用使用缓存 (Invoke from Cache):
- 当客户端再次发起 RPC 调用时,它不再查询注册中心,而是直接从本地缓存的服务列表中,根据负载均衡策略(如随机、轮询、一致性哈希等)选择一个服务实例,然后直接与该实例建立连接并发送请求。
-
订阅变更通知 (Subscribe for Updates):
- 在首次拉取服务列表的同时,客户端会在注册中心上对该服务注册一个“监听器”或“Watcher”。这是一种订阅发布模式。
- 当注册中心检测到该服务的实例列表发生变化时(例如有新服务实例上线、有实例下线或宕机),它会主动地将这个变更事件推送 (Push) 给所有订阅了该服务的客户端。
-
动态更新缓存 (Update Cache Dynamically):
- 客户端的监听器收到变更通知后,会异步地更新自己的本地缓存。
- 例如,收到“实例A下线”的通知,就从缓存列表中移除实例A;收到“实例C上线”的通知,就向缓存列表中添加实例C。
通过这种方式,既保证了客户端调用的高性能(直接访问本地缓存),又保证了服务列表的准实时一致性(通过订阅推送机制动态更新)。
3. 结构示意图 (Mermaid)
这个时序图清晰地展示了整个过程:
4. 另一种备选方案:定期轮询 (Periodic Polling)
除了“订阅推送”模型,还有一种简化的模型是定期轮询。
- 工作方式: 客户端不与注册中心建立长连接或监听器,而是启动一个后台线程,每隔一个固定的时间(例如 30 秒)主动去注册中心拉取最新的服务列表来更新本地缓存。
- 优点:
- 实现相对简单,对客户端和注册中心的连接管理负担较小。
- 缺点:
- 实时性差: 服务变更的感知有延迟。在轮询间隔内,客户端可能会调用到一个已经下线的服务实例。
- 无意义的请求: 即使服务列表没有变化,客户端也会定期发送查询请求,造成一定的网络和服务器资源浪费。
在现代的 RPC 框架中(如 Dubbo、gRPC 结合 Zookeeper/Nacos),“缓存 + 订阅”是绝对的主流和最佳实践。
3.详细的介绍下thrift与dubbo的工作原理
好的,这是一个非常经典的技术选型对比。Thrift 和 Dubbo 都是顶级的 RPC 框架,但它们的设计哲学、核心目标和工作原理有着本质的区别。
简单来说:
- Thrift 是一个跨语言 RPC 工具箱,它的核心是IDL (接口定义语言),目标是让不同语言的服务能轻松地相互通信。
- Dubbo 是一个面向 Java 的高性能服务治理框架,它的核心是服务治理(注册发现、负载均衡、容错等),目标是构建健壮的、可大规模扩展的微服务体系。
下面我们来详细剖析它们各自的工作原理。
一、Apache Thrift 的工作原理 (跨语言的“瑞士军刀”)
Thrift 的哲学是“定义一次,到处使用”。它通过一个中立的 .thrift 文件来定义服务接口和数据结构,然后通过代码生成器生成不同语言的客户端和服务端代码。
1. 核心组件 (Thrift 技术栈)
Thrift 的工作原理可以理解为一个分层的“协议栈”,从上到下依次是:
- Processor (处理器): 由生成的代码实现,它从底层协议中读取数据,并将处理委托给你自己实现的服务逻辑 (Handler)。它扮演着分发器的角色。
- Protocol (协议层): 负责数据的序列化和反序列化。它定义了数据(如字符串、整数、结构体)如何在网络中以二进制格式进行编码和解码。
TBinaryProtocol: 标准的二进制格式。TCompactProtocol: 高效的、压缩的二进制格式。TJSONProtocol: JSON 格式,易于调试。
- Transport (传输层): 负责网络数据的读写。它定义了如何从网络中读取字节流以及如何将字节流写入网络。
TSocket: 使用阻塞式 TCP/IP Sockets。TFramedTransport: 以帧为单位传输,用于非阻塞服务器。TMemoryBuffer: 使用内存进行传输(用于测试)。
- Server (服务模型): 将以上所有组件整合起来,负责监听网络端口,接收客户端请求,并将其分发给 Processor 处理。
TSimpleServer: 单线程阻塞式,仅用于测试。TThreadPoolServer: 多线程阻塞式,使用线程池处理连接。TNonblockingServer: 多线程非阻塞式,使用 NIO。
组件关系图:
2. 工作流程
- 定义 IDL: 开发者首先创建一个
.thrift文件,用中立的语法定义服务接口、方法、参数和数据结构。// calculator.thrift service Calculator { i32 add(1:i32 num1, 2:i32 num2), // ... other methods } - 代码生成: 使用 Thrift 编译器,为目标语言(如 Java, Python, C++)生成代码。
这会生成:thrift --gen java calculator.thriftCalculator.java: 包含客户端存根 (Stub)Calculator.Client和服务端骨架 (Skeleton)Calculator.Processor的接口。
- 服务端实现: 开发者编写一个类,实现生成的服务接口的业务逻辑。
public class CalculatorHandler implements Calculator.Iface { public int add(int num1, int num2) { return num1 + num2; } } - 服务端启动: 将 Handler、Processor、Protocol 和 Transport 组合起来,启动一个 TServer 监听端口。
- 客户端调用:
- 客户端创建一个 Transport (如 TSocket) 连接到服务端。
- 创建一个 Protocol 封装这个 Transport。
- 使用生成的
Calculator.Client(Stub) 类发起调用,就像调用一个本地方法一样。 client.add(1, 2);
- 调用过程:
- 客户端的 Stub 将方法调用 (
add) 和参数 (1,2) 通过 Protocol 序列化成二进制数据。 - Transport 将这些二进制数据通过网络发送出去。
- 服务端的 Transport 接收到数据。
- 服务端的 Protocol 将二进制数据反序列化,解析出方法名和参数。
- Processor 根据方法名,调用 Handler 中对应的
add方法来执行业务逻辑。 - 执行结果沿着相反的路径序列化并返回给客户端。
- 客户端的 Stub 将方法调用 (
二、Apache Dubbo 的工作原理 (微服务治理的“集大成者”)
Dubbo 的设计目标远不止于完成一次 RPC 调用,它旨在提供一个完整的微服务生态。它的工作原理是分层的,并以注册中心为核心。
1. 核心组件与角色
- Registry (注册中心): 整个架构的“通讯录”,负责服务的注册和发现。Provider 在此注册地址,Consumer 在此发现地址。常用 Zookeeper、Nacos。
- Provider (服务提供者): 暴露服务的业务方。
- Consumer (服务消费者): 调用远程服务的业务方。
- Container (服务容器): 服务运行的容器,如 Spring Boot。
- Monitor (监控中心): 统计服务的调用次数和调用时间等信息(可选)。
2. 核心架构 (分层模型)
Dubbo 官方将其架构分为 10 层,但为了便于理解,我们可以简化为以下核心层次:
- Business Layer (业务层): 就是我们自己编写的接口和实现。
- RPC Layer (RPC 抽象层):
- Proxy: 服务代理层,为 Consumer 生成动态代理,让远程调用看起来像本地调用。
- Cluster: 集群容错层,封装了负载均衡 (
LoadBalance) 和容错策略 (Failover,Failfast等)。当有多个 Provider 时,它决定调用哪一个,以及调用失败后该怎么办。
- Remoting Layer (远程通信层):
- Protocol: 协议层,封装了 RPC 的核心调用逻辑。Dubbo 默认使用自己的
dubbo协议,但也支持 RMI、Hessian 甚至 Thrift 协议。 - Exchange: 信息交换层,封装了请求-响应模型。
- Transport: 网络传输层,默认使用 Netty 进行 NIO 通信。
- Protocol: 协议层,封装了 RPC 的核心调用逻辑。Dubbo 默认使用自己的
3. 工作流程 (以注册中心为核心)
时序图:
详细步骤:
-
服务启动与注册:
- Provider 在 Spring 等容器中启动。
- 启动过程中,Dubbo 框架会通过代理和反射,将需要暴露的服务连接到注册中心。
- Provider 将自己的服务名、IP、端口、配置等元数据注册到 Registry。
-
服务订阅与发现:
- Consumer 在容器中启动。
- 启动时,Dubbo 框架会扫描需要注入的远程服务。
- Consumer 向 Registry 订阅它所需要的服务。
- Registry 收到订阅后,将该服务所有 Provider 的地址列表推送给 Consumer。
- Consumer 将地址列表缓存到本地内存。
-
服务调用:
- 当 Consumer 的代码调用远程接口时,实际上调用的是 Dubbo 通过 动态代理 (Proxy) 生成的一个本地对象。
- 这个代理会将调用请求转发给 Dubbo 的 Cluster 模块。
- Cluster 模块根据负载均衡 (LoadBalance) 策略(如随机、轮询)从本地缓存的地址列表中选择一个 Provider 实例。
- 选定 Provider 后,通过通信协议 (Protocol)(如 Dubbo 协议)将请求进行序列化,并通过网络传输 (Transport)(如 Netty)发送给目标 Provider。
-
动态感知:
- Registry 与 Consumer 之间通常保持长连接。
- 当有 Provider 上线或下线时,Registry 会实时地将变更通知推送给所有订阅的 Consumer。
- Consumer 收到通知后,动态更新本地的地址缓存,从而实现了服务地址的自动管理,无需人工干预。
三、核心差异总结
| 特性 | Apache Thrift | Apache Dubbo |
|---|---|---|
| 核心定位 | 跨语言 RPC 通信工具箱 | Java 微服务治理框架 |
| 核心依赖 | IDL (.thrift 文件),强类型 schema | 注册中心 (Zookeeper/Nacos) |
| 跨语言能力 | 核心优势,支持 C++, Java, Python, Go 等几十种语言 | 以 Java 为主,逐步通过 Dubbo-Go, Dubbo-Py 等支持多语言,但生态不如 Thrift 成熟 |
| 服务治理 | 不提供。注册发现、负载均衡、容错等需自行实现或集成第三方库 | 核心功能。内置强大的负载均衡、集群容错、服务降级、路由规则等治理能力 |
| 协议 | 自带一套协议栈 (TBinary, TCompact) | 默认使用 dubbo 协议,但可插拔,支持 RMI, Hessian, HTTP, 甚至可以集成 Thrift 作为其通信协议之一 |
| 易用性 | 需要 IDL 定义和代码生成步骤,有一定学习曲线 | 对 Java 开发者透明,像调用本地方法一样,配置简单,开箱即用 |
结论:
- 选择 Thrift: 当你的首要任务是解决异构语言服务之间的通信问题时,或者当你需要一个高性能、轻量级、可高度定制的 RPC 通信底层时。
- 选择 Dubbo: 当你主要在 Java 技术栈中构建微服务体系,并且高度关注服务的治理能力(如服务的自动注册发现、优雅下线、流量调度、故障转移等)时。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号