06 Spark SQL 及其DataFrame的基本操作
1.Spark SQL出现的 原因是什么?
Spark SQL是Spark中用于结构化数据处理的组件,Spark2.0中我们使用的就是sparkSQL,是后继的全新产品,解除了对Hive的依赖。
对于SQL来说,Spark SQL受众面广和易学易用。使用大数据的手段来进行处理日益增长的数据量Spark SQLS是相对容易也是较为完善的第一选择。Spark SQL自从使用以来不仅接过了shark的接力棒,并且独立于Hive,为spark用户提供高性能的SQL on hadoop的解决方案,他还为spark带来了通用的高效的,多元一体的结构化的数据处理能力。
park SQL能运行SQL以及hive ql的查询,还能运行UDFs、UDAFs以及序列化和反序列化
2.用spark.read 创建DataFrame
创建DataFrame可以使用spark.read操作: spark.read.text('people.txt')。
spark.read.json('people.json')。
spark.read.parquet('people.parquet')。
spark.read.format('text).load('people.txt')。
spark.read.format('json).load('people.json')。
spark.read.format('parquet).load('people.parquet')
3.观察从不同类型文件创建DataFrame有什么异同?
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?
RDD虽然以Person为类型参数,但Spark框架本身不了解 person类的内部结构而DataFrame却提供了详细的结构信息,使得SparkSQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。RDD是分布式的 。
Spark SQL DataFrame的基本操作
创建:
spark.read.text()
spark.read.json()


打印数据
df.show()默认打印前20条数据,df.show(n)
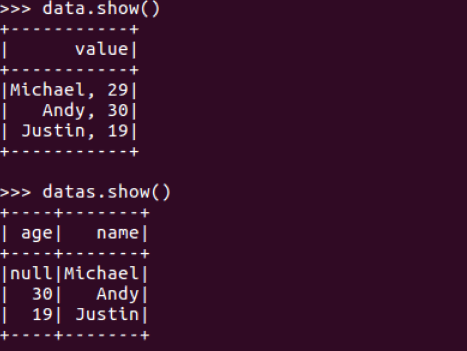
打印概要
df.printSchema()
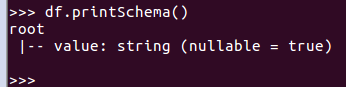
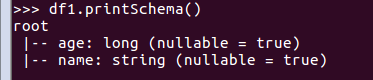
查询总行数
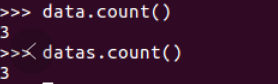
df.count()
df.head(3) #list类型,list中每个元素是Row类

输出全部行
df.collect() #list类型,list中每个元素是Row类

查询概况
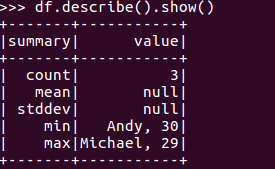
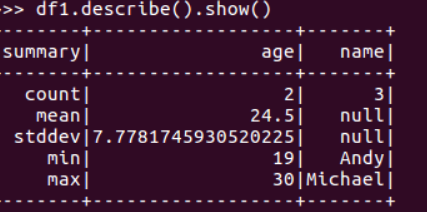
df.describe().show()
取列
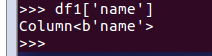
df[‘name’]
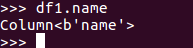
df.name
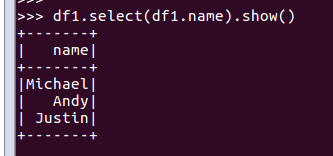
df.select()
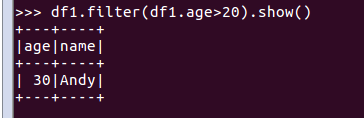
df.filter()
df.groupBy()
df.sort()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号