
可视化阅读Kubelet(一):从宏观架构到启动全流程
前言
在深入研究Kubernetes(K8S)源代码的旅程中,许多技术文章都指引我们从API Server、Scheduler等控制平面的核心组件入手。遵循这一路径,我确实对K8S的声明式API和调度机制有了宏观的理解。
然而,我逐渐发现,这些组件如同运筹帷幄的“大脑”,它们下达指令,但并不亲自动手。真正将Pod的定义(Spec)转化为节点上一个个鲜活的、运行中的容器的,是那个默默无闻却至关重要的角色——Kubelet。
Kubelet是运行在每个Node上的“神经末梢”和“最终执行官”。它直接与容器运行时(Container Runtime)、存储(Storage)、网络(Network)打交道,是连接K8S控制平面与实际工作负载的桥梁。若不深入Kubelet,我们对K8S容器管理的理解将永远停留在抽象层面。
因此,我决定开启一个专门针对Kubelet源码的探索系列。我们不仅要看懂代码,更要理解其背后的设计哲学、演进历史以及它在庞大的K8S生态中的核心定位。本系列旨在从“执行者”的视角,重构我们对K8S容器技术的认知。
本篇作为开篇,我们将完成Kubelet源码阅读的环境准备,并从最高层级俯瞰其宏观架构。
Kubelet在K8S生态中的位置
在深入其内部构造之前,我们先通过一张宏观架构图来明确Kubelet的“江湖地位”。
这张图展示了Kubelet作为控制平面指令的最终落地点和执行者,如何将K8S的API对象翻译成底层的具体操作。

环境准备
要真正洞察Kubelet的内部运作,最好的方式莫过于亲自编译、运行并调试它。为此,我们需要一个相对真实的K8S环境。
为什么不推荐Minikube或Kind?
k8s-in-docker这类技术虽然便捷,但它们将Kubelet封装在容器内,使得替换和调试变得异常困难。
我们的目标是直接替换Node节点上由systemd管理的原生Kubelet,换上我们自己编译的、注入了追踪探针的版本。因此,一个通过kubeadm或kubekey等工具搭建的标准集群是最佳选择。
第一步:源码下载
git clone https://github.com/kubernetes/kubernetes
cd kubernetes
# 切换到对应的版本
git checkout v1.25.6
本篇文章基于v1.25.6 进行源码阅读
第二步:使用GoAnalysis注入追踪探针
注意k8s中是一个大仓库,所以我们只对kubelet目录,client-go目录进行插桩即可。
goanalysis rewrite -d <path>/<to>/kubernetes/cmd/kubelet
goanalysis rewrite -d <path>/<to>/kubernetes/pkg/kubelet
goanalysis rewrite -d <path>/<to>/kubernetes/staging/src/k8s.io/client-go
goanalysis rewrite -d <path>/<to>/kubernetes/staging/src/k8s.io/kubelet
第三步:缓存依赖
为了确保编译不受网络波动影响,并锁定依赖版本,我们使用Go Modules的vendor机制。
go mod tidy
go mod vendor
第四步:替换并启动Kubelet
这是最关键的一步。我们需要在目标Node上停止系统自带的Kubelet,然后手动启动我们编译的版本。
# 1. SSH登录到你的K8S Node节点
# 2. 找到现有Kubelet的启动参数,这将是我们手动运行的模板
ps -ef | grep kubelet
# 3. 停止系统Kubelet服务(请注意,这会导致该节点暂时失联,Pod无法管理)
systemctl stop kubelet
# 4. 进入Kubelet源码目录,使用第2步中获取的参数启动我们自己的版本
cd cmd/kubelet
go run . --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml --cgroup-driver=systemd --container-runtime=remote --container-runtime-endpoint=unix:///var/run/cri-dockerd.sock --pod-infra-container-image=registry.cn-beijing.aliyuncs.com/kubesphereio/pause:3.8 --node-ip=192.168.141.128 --hostname-override=node1 --v=2
运行成功后,goanalysis会生成一个可供分析的数据库文件。
通过其Web界面打开,我们就能看到Kubelet从启动到运行的完整调用链路图。
偷懒小贴士: 如果觉得环境搭建繁琐,可以直接访问 GitHub - toheart/analysis-db: Save all the db files that have analyzed the code.,这里有我已经分析好的源码缓存DB文件,可以直接下载使用。
思路梳理:从第一性原理
看Kubelet的职责在深入代码细节之前,让我们先进行一次思维实验。忘掉源码,作为一个系统设计师,如果让你来设计Kubelet,它需要具备哪些功能?
核心定位: Kubelet是运行在每个Node上的代理程序(Agent),是Pod生命周期的“首席执行官”。
当Scheduler决定一个Pod落在某个Node上后,Kubelet的使命就开始了。最核心的任务无疑是:根据Pod的规约,创建并管理容器。
这似乎很简单,主要就两件事:
- 拉取镜像(Image Pull)
- 通过CRI(Container Runtime Interface)启动容器
工作完成了吗?远没有。让我们从系统健壮性和功能完备性的角度,提出一系列追问:
- 资源管理:镜像拉取后会占用磁盘空间,谁来清理不再使用的旧镜像?容器日志会不断增长,谁来负责日志的轮转(Log Rotation)和清理,防止磁盘被占满?
- 配置管理:Pod经常需要挂载ConfigMap和Secret。Kubelet如何将这些配置数据安全地注入到容器内部?当这些配置更新时,Kubelet又如何实现热加载?
- 健康检查:Pod定义了
livenessProbe和readinessProbe,Kubelet如何精确、准时地执行这些探针,并根据结果采取行动(如重启容器)? - 三驾马车:除了CRI(容器),Kubelet如何与CNI(网络)和CSI(存储)接口协同工作,为Pod准备好网络环境和持久化数据卷?
- 状态上报:Kubelet如何监控并向API Server汇报Node本身的资源状况(心跳)以及其上运行的所有Pod的状态?这是K8S实现“期望状态”与“实际状态”同步的基础。
被遗忘的角落:静态Pod (Static Pods)
除了上述通过API Server下发的Pod(我们称之为API Pod),Kubelet还有一个鲜为人知但极其重要的职责:管理静态Pod。
什么是静态Pod?
答:静态Pod是由Kubelet直接管理的Pod,其YAML定义文件存放在Node本地的一个指定目录(通常是/etc/kubernetes/manifests)。Kubelet会周期性地扫描这个目录,根据其中的文件来创建、删除或更新Pod。
它有什么用?
答:静态Pod不依赖于API Server,这意味着即使在整个控制平面宕机的情况下,Kubelet依然可以保证这些Pod在节点上运行。这个特性使得静态Pod成为引导和启动K8S控制平面组件(如API Server、Scheduler、Controller Manager自身)的完美选择。
在一个由kubeadm搭建的集群中,你会发现控制平面的组件正是以静态Pod的形式运行的。这个功能进一步强化了Kubelet作为独立节点代理的核心定位。
通过这场“头脑风暴”,我们可以推导出Kubelet必须包含的几个核心功能模块:
- 镜像管理器 (Image Manager): 负责镜像的拉取与垃圾回收。
- CRI管理器 (CRI Manager): 通过gRPC与容器运行时交互。
- 配置管理器 (ConfigMap/Secret Manager): 监听并同步配置数据。
- CSI/CNI协调器: 调用CSI/CNI插件完成存储和网络的配置。
- 日志管理器 (Log Manager): 管理容器日志的存储与轮转。
- 资源监控器 (Resource Monitor): 采集并上报Node和Pod的资源使用情况。
- 探针管理器 (Probe Manager): 独立、并行地执行健康检查。
- Pod同步控制器 (Pod Sync Loop): 核心工作循环,驱动Pod达到其期望状态。
- 静态Pod管理器 (Static Pod Manager): 监控本地文件,管理静态Pod。
带着这份架构蓝图,我们再去看Kubelet的启动流程,一切将变得清晰起来。
命令启动:Cobra与依赖注入
Kubelet的启动入口遵循了K8S组件的通用模式,使用Cobra库构建命令行界面。
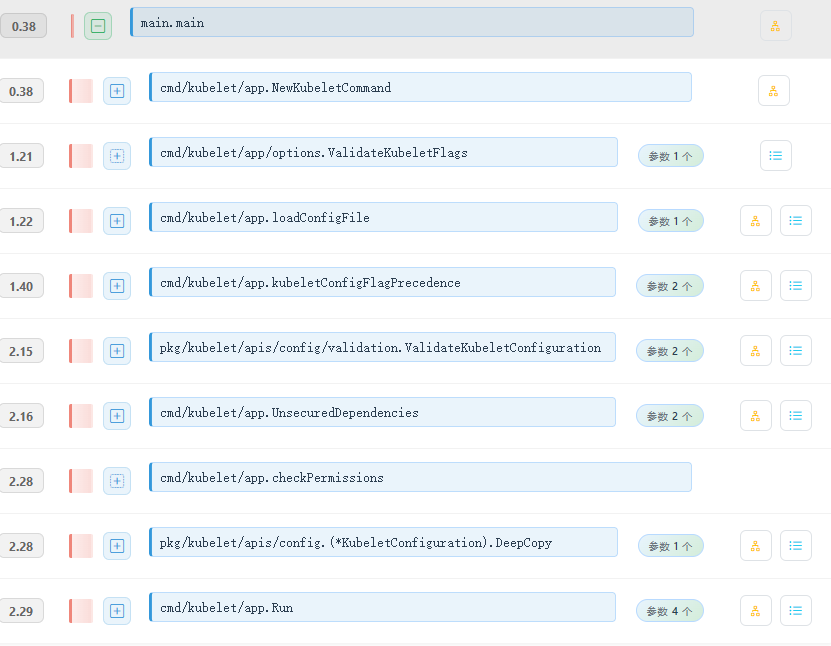
这个启动过程本身比较标准化,主要做了几件事:
- 参数解析与校验: 解析命令行标志和配置文件。
- 权限检查: 确保Kubelet以root权限运行(
os.Getuid() == 0),因为它需要操作底层系统资源。 - 构建
Dependencies对象: 这是最关键的一步。Kubelet将所有外部依赖(如CRI客户端、CAdvisor、认证授权模块等)统一封装到一个名为Dependencies的结构体中。这是一种典型的依赖注入(Dependency Injection)模式,极大地提高了代码的模块化和可测试性。
Dependencies结构体字段繁多,它像一个“工具箱”,装满了Kubelet运行所需的一切外部服务和配置。
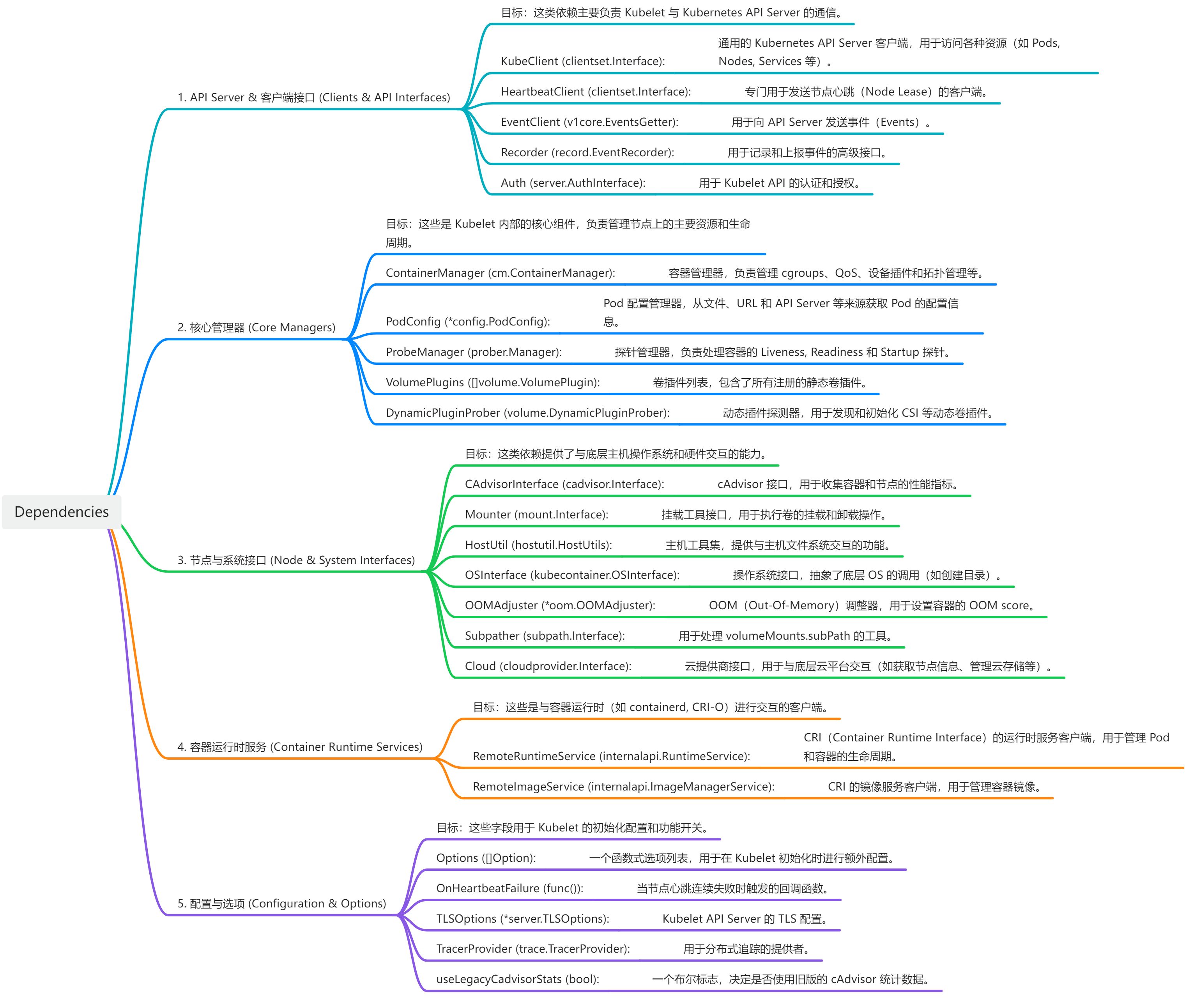 画板
画板
通过这个结构体,我们可以快速定位到关键接口的定义,例如
Container Runtime Services就指向了CRI API的定义位置:k8s.io/cri-api/pkg/apis/services.go。
关键配置剖析 (**config.yaml**)
在启动命令中,--config参数指向了一个至关重要的config.yaml文件。它定义了Kubelet的大部分行为。虽然参数众多,但以下几个对于理解Kubelet和保障节点稳定性至关重要:
cgroupDriver: 必须与容器运行时的cgroup驱动(通常是systemd或cgroupfs)保持一致。配置错误会导致Kubelet无法正确地进行资源核算和限制。evictionHard: 定义了硬驱逐阈值。例如,memory.available: "100Mi"意味着当节点可用内存低于100Mi时,Kubelet会立即开始驱逐Pod以回收内存,防止节点自身因OOM而崩溃。这是保障节点稳定性的生命线。kubeReserved/systemReserved: 用于为Kubernetes系统组件(如Kubelet、容器运行时)和操作系统核心进程预留资源。这可以防止业务Pod耗尽所有资源,从而导致节点失联。featureGates: 用于开启或关闭特定的实验性功能。通过它可以一窥K8S未来的发展方向。
理解这些配置项,能帮助我们更好地从运维和管理的角度看待Kubelet。
初始化步骤:启动先行服务
在Kubelet的核心逻辑开始前,一些辅助性的、必须长期运行的服务被率先启动。
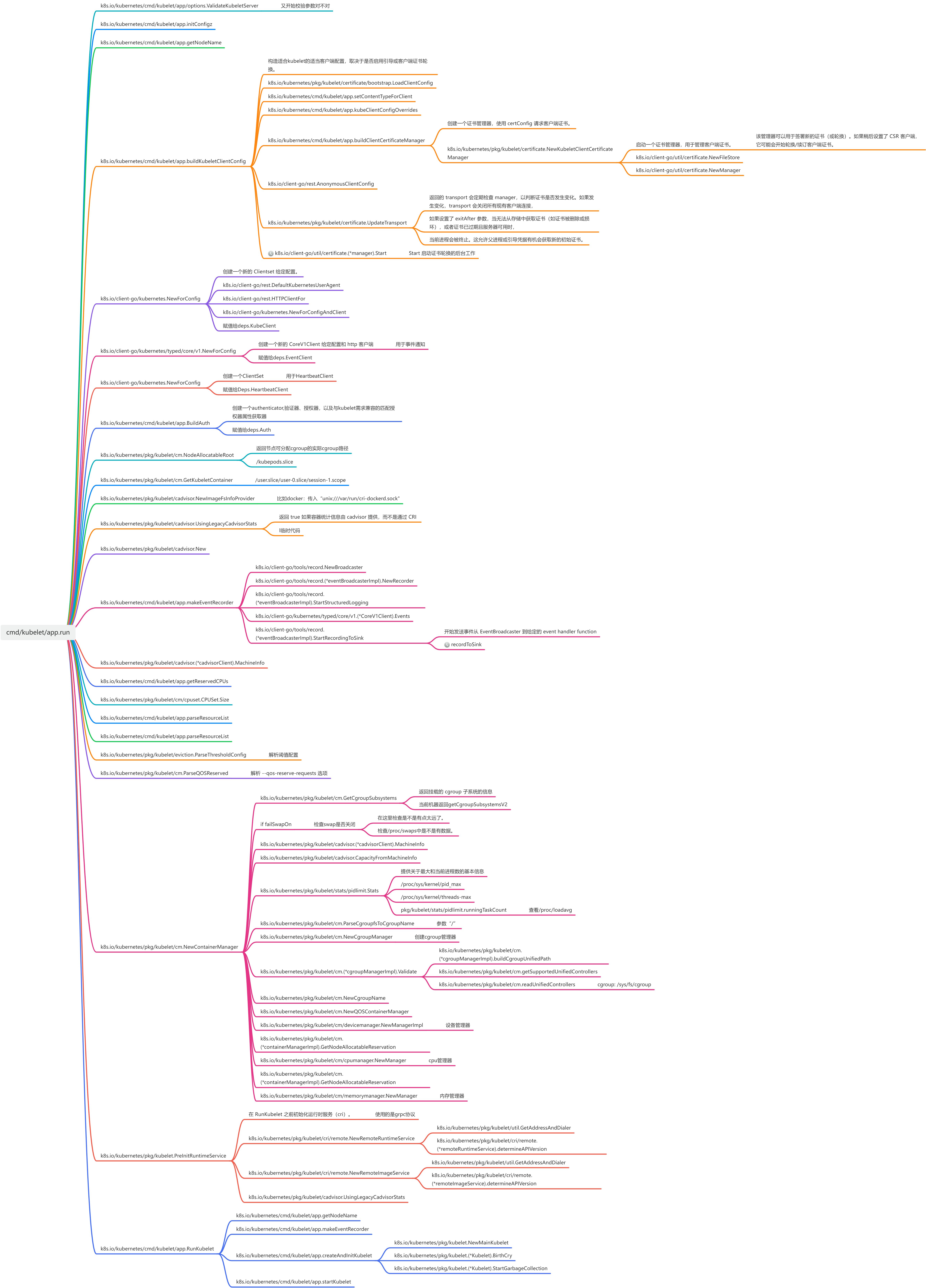 画板
画板
从调用链中可以看到,在app.Run的早期阶段,就已经通过go关键字启动了两个重要的后台协程:
- 证书轮换管理器 (Certificate Rotation Manager): 负责Kubelet与API Server通信所用TLS证书的自动续期,是保障安全通信的关键。
- 事件上报器 (Event Recorder): 创建一个客户端,用于向API Server发送各种事件(Events),例如Pod启动失败、镜像拉取成功等,是K8S中重要的可观测性手段。
创建Kubelet结构:一个“巨无霸”的诞生
初始化的核心是调用NewMainKubelet函数,这个函数堪称Kubelet源码中的“奇观”。
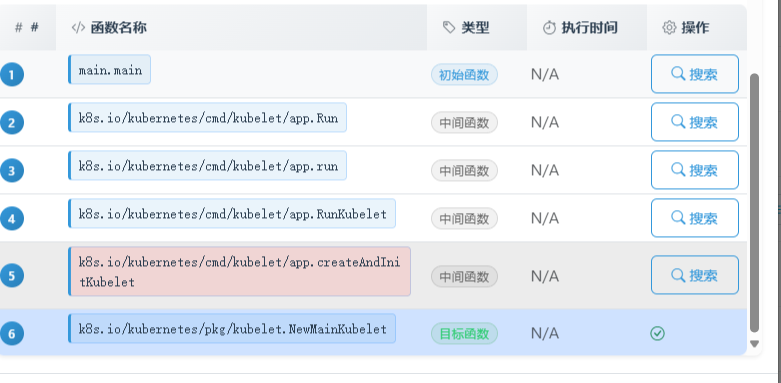
它的函数签名有28个参数之多,而它返回的`kubelet``结构体,定义长达323行!

这种代码规模反映了Kubelet在十余年发展中不断累积的复杂性。虽然从软件工程角度看有改进空间,但它也像一张“活地图”,忠实记录了Kubelet的所有职责。
这个庞大的kubelet结构体,正是我们之前“头脑风暴”出的所有功能模块的最终载体。我们可以用思维导图将其中的关键字段与我们的功能模块对应起来:
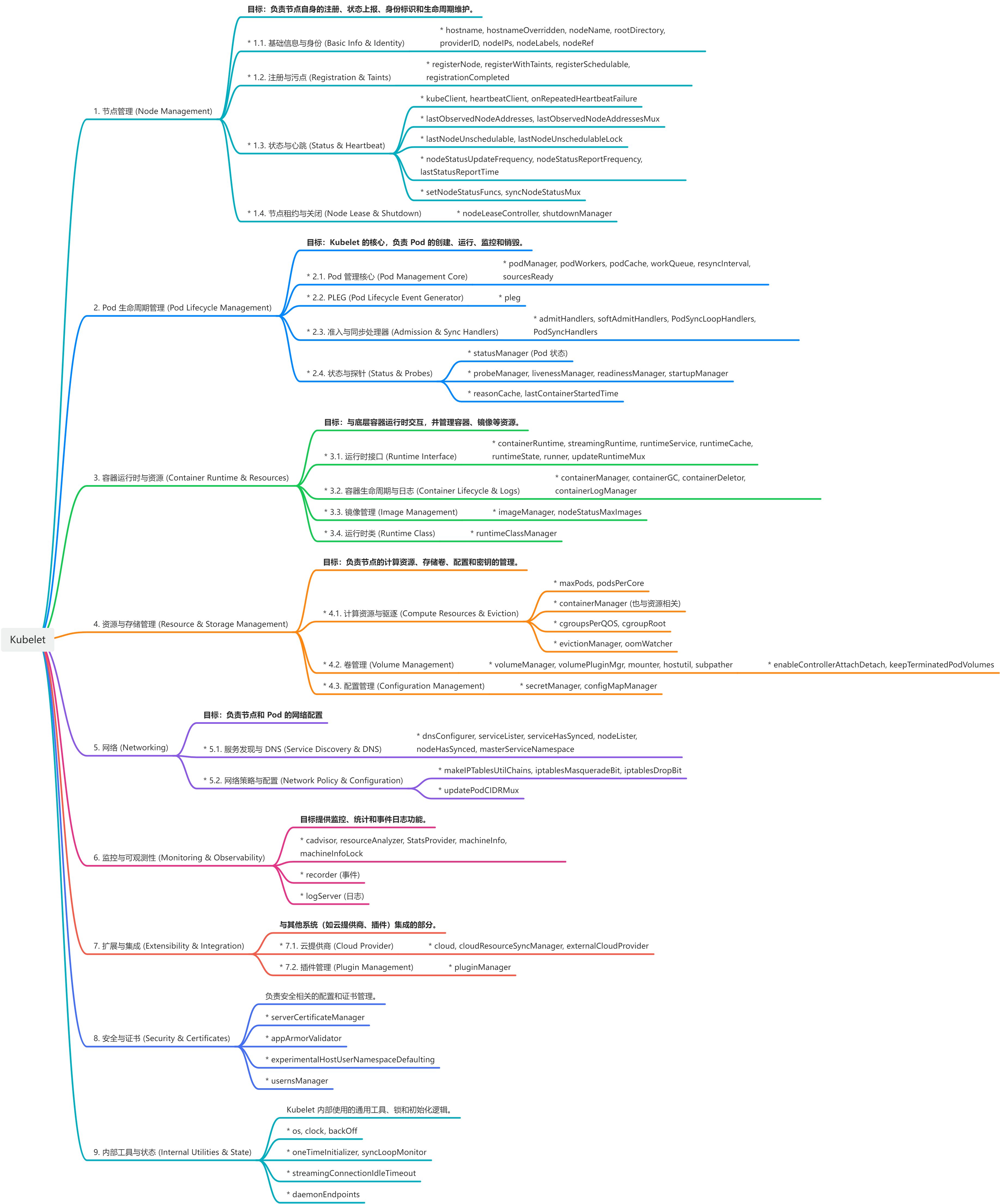 画板
画板
从中可以看出,非常之庞大的结构体。所以后续我们将从多篇文章逐个击破;
startKubelet:发射指令
当kubelet这个“巨无霸”对象被创建并填充完毕后,startKubelet函数就负责按下“发射按钮”,启动Kubelet的各个主要服务。
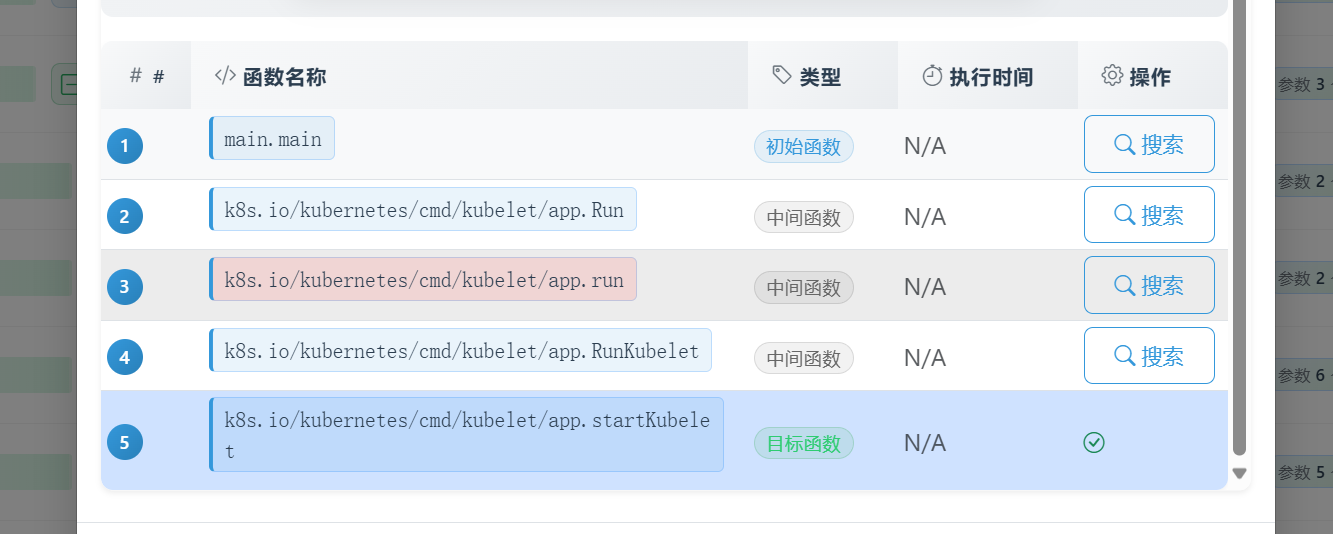
并且通过插桩的方式,能够查看到其只有一个子函数:pkg/kubelet/config.(*PodConfig).Updates。通过源码进一步分析后续的流程:
func startKubelet(k kubelet.Bootstrap, podCfg *config.PodConfig, kubeCfg *kubeletconfiginternal.KubeletConfiguration, kubeDeps *kubelet.Dependencies, enableServer bool) {
// 启动核心工作循环
go k.Run(podCfg.Updates())
// 启动对外的HTTPS API服务
if enableServer {
go k.ListenAndServe(kubeCfg, kubeDeps.TLSOptions, kubeDeps.Auth, kubeDeps.TracerProvider)
}
// 启动只读端口(如果配置)
if kubeCfg.ReadOnlyPort > 0 {
go k.ListenAndServeReadOnly(netutils.ParseIPSloppy(kubeCfg.Address), uint(kubeCfg.ReadOnlyPort))
}
// 启动Pod资源gRPC服务(如果启用)
if utilfeature.DefaultFeatureGate.Enabled(features.KubeletPodResources) {
go k.ListenAndServePodResources()
}
}
此函数清晰地启动了3-4个并行的顶级协程,每个协程都承载着Kubelet的一项核心职能。接下来,我们将逐一剖析。
在分析这几个协程之前,所有配置封装过程已经结束,那么我们可以从参数中读取到一些细节点:
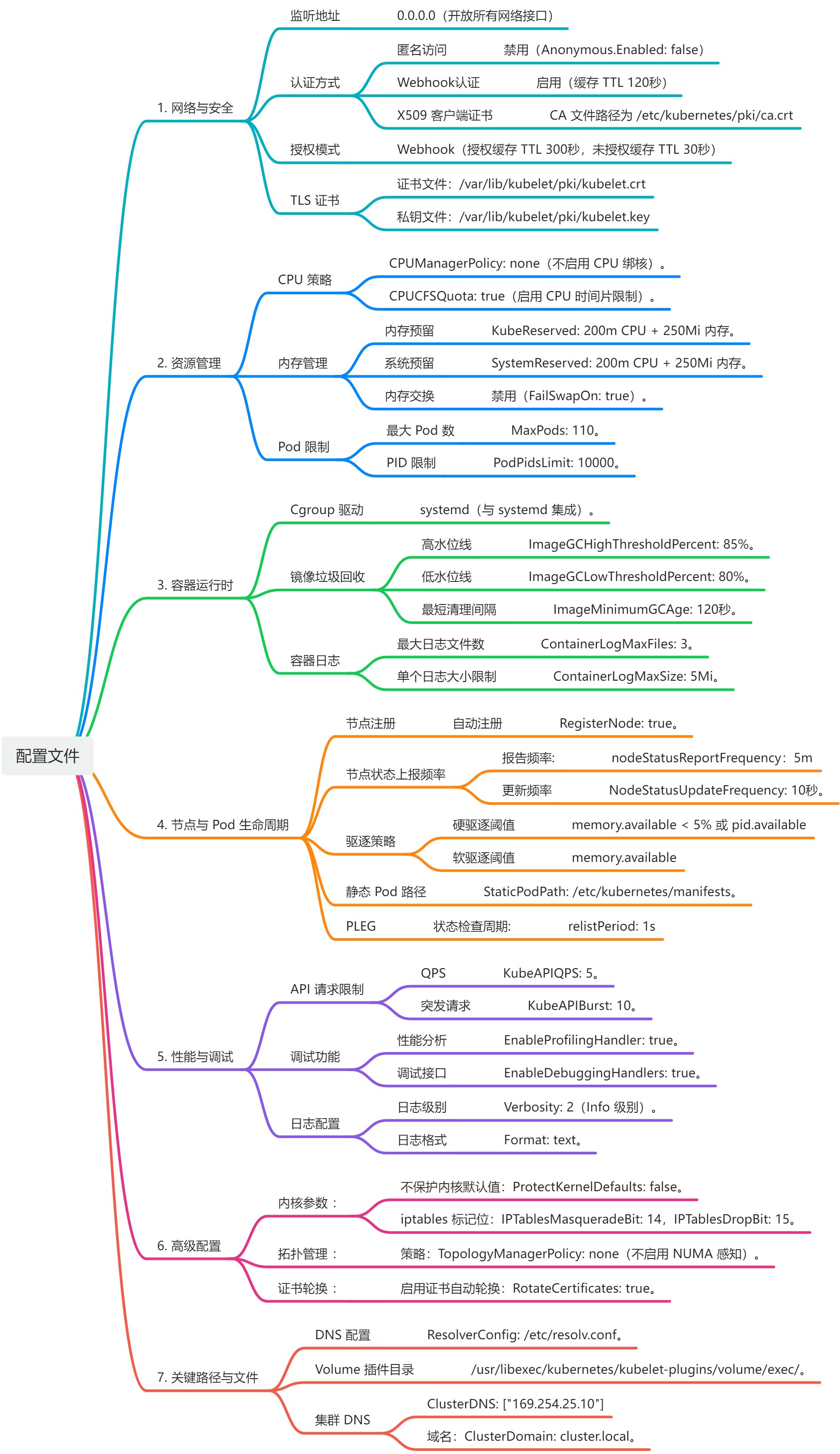 画板
画板
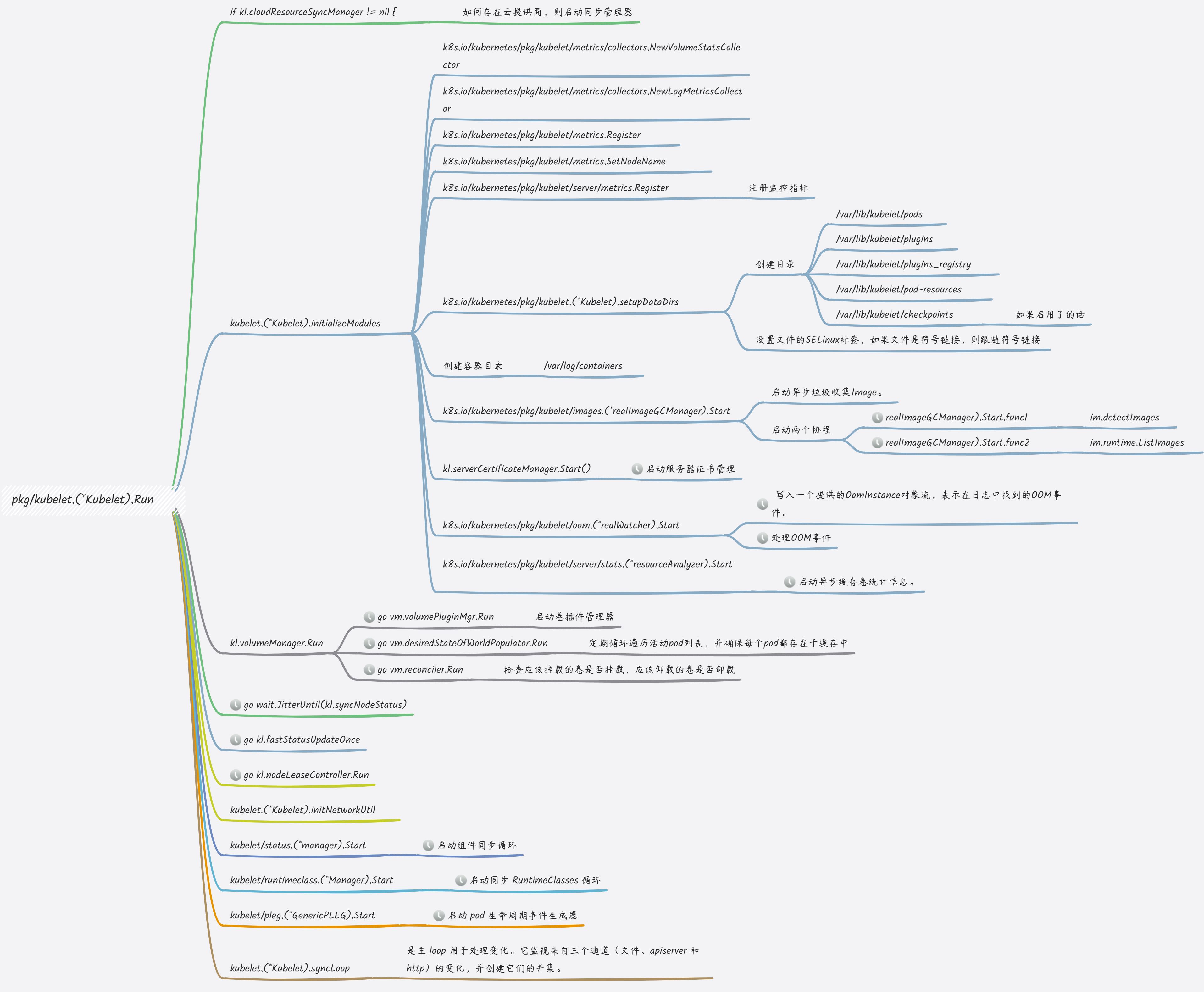
Kubelet.Run:总包工头的智慧
Kubelet.Run是Kubelet最核心的协程,但我们的调用链追踪显示,它的直接执行函数很少。这恰恰说明,它内部通过go关键字派生出了大量的“子协程”来分担工作。
思维模型:将 Kubelet 想象成一个“总包工头”
想象一下,Kubelet 是一个负责管理工地上所有建筑任务(运行 Pod)的“总包工头”。这个工地(Node 节点)上有很多事情需要同时发生,如果包工头“单线程”工作,效率将极其低下。一个环节的卡顿(如网络慢导致拉取镜像卡住)会阻塞所有其他工作。
聪明的Kubelet采用了“协程化”的组织方式,雇佣了很多“小工”(Goroutines),各司其职,实现了高效的**关注点分离 **(Separation of Concerns)。
 画板
画板
Run()函数内部启动了大约17个关键的后台管理器和循环,每个都在自己的协程中独立运行:
- 与“开发商”(API Server)的沟通
- PodConfig:一个“信使”,持续监听(Watch)API Server,接收新的Pod、ConfigMap、Secret分配指令。
- Node/Pod状态上报:两个独立的“汇报员”,定期向API Server报告节点健康状况和所有Pod的当前状态。
- 核心工作循环 (Pod Sync Loop)
- Kubelet的核心是一个由
syncLoop驱动的事件循环。所有Pod的变更(增、删、改)都会被推入一个工作队列。 - 多个“工人协程”从队列中取出Pod,执行核心的
syncPod逻辑,实现任务的解耦和并发处理。
- Kubelet的核心是一个由
- 子系统管理器 (Managers)
- PLEG (Pod Lifecycle Event Generator): 一个至关重要的“巡视员”,它不依赖API Server,而是直接与容器运行时(CRI)对话,定期检查节点上容器的“真实状态”,然后生成生命周期事件。它是维持“期望”与“现实”同步的关键。
- 探针管理器 (Probe Manager): 为每个Pod的Liveness、Readiness、Startup探针分别启动独立的、定时的“医生协程”。
- 卷管理器 (Volume Manager): “仓管员”,异步处理存储卷的Attach/Detach/Mount/Unmount等I/O密集型操作。
- 镜像管理器 (Image Manager): “物料管理员”,异步处理镜像的拉取和垃圾回收(Image GC)。
- 驱逐管理器 (Eviction Manager): “保安”,时刻监控节点资源,当资源紧张时,独立决策并驱逐Pod。
这种高度并发的架构,是Kubelet能够在繁忙的Node上保持响应和效率的根本原因。
Kubelet.ListenAndServe:节点上的API网关
当我们在终端敲下**kubectl exec或kubectl logs**时,请求是如何最终触达目标容器的?答案就在Kubelet.ListenAndServe启动的HTTPS服务中。
这个服务是API Server与特定Node上容器交互的桥梁,为一系列调试和监控功能提供了服务端点。
 画板
画板
其注册的路由可以分为几大类:
- 核心API (默认启用)
/pods: 获取本节点所有Pod的信息。/healthz: 健康检查端点。/stats: 提供节点和容器的资源使用统计(cAdvisor)。/metrics: 提供Prometheus格式的监控指标。
- 调试API (需
EnableDebuggingHandlers=true开启)/run,/exec,/attach,/portForward: 分别对应kubectl run,exec,attach,port-forward命令的后端实现。/containerLogs:kubectl logs的后端。
- 系统与Profiling API
/logs: 查看Kubelet自身日志。/debug/pprof: Go语言标准的性能分析端点。
Kubelet.ListenAndServePodResources:为性能监控而生
这是一个相对较新的gRPC服务,它通过Unix Socket向节点上的其他特权进程(如监控Agent、网络插件)暴露精细化的Pod资源分配信息。
- 作用: 提供一个API,允许查询到每个Pod、每个容器具体分配到了哪些CPU核心、NUMA节点、GPU或其他设备。
- 消费者: 这对于需要进行性能调优、资源拓扑感知的监控系统或第三方应用(如DPDK)至关重要。
总结:Kubelet的宏观世界
通过对Kubelet启动过程的追溯,我们已经绘制出了一幅宏观的架构图。关键要点如下:
- 高度并发: Kubelet是一个由海量Goroutine构成的并发系统,通过“关注点分离”原则,将不同职责委托给独立的管理器和工作循环。
- 依赖注入: 通过
Dependencies结构体,实现了核心逻辑与外部服务的解耦,保证了代码的可测试性和可扩展性。 - 控制器模式: 其核心
syncLoop是一个典型的控制器模式,不断地将“实际状态”调整为“期望状态”。 - 双重身份: Kubelet既是控制平面的“执行者”,也是一个对外的“API服务器”,为
kubectl等客户端提供了与容器交互的桥梁。
至此,我们已经对Kubelet的“骨架”有了清晰的认识。在下一篇文章中,我们将深入其“血肉”,聚焦最核心的工作流——Pod的生命周期管理(syncPod),探索一个Pod从无到有的完整历程。
如果觉得文章能够帮助到您,可以一键三连,或者关注“小唐的技术日志”,支持一下,您的反馈是我不断前进的动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号