

python字符编码与解码 unicode,str
解释以下几个问题:
(1)python2中str和unicode是两种字符串类型,与字符编码方式是什么关系?
(2)str和unicode是怎么相互转换的?
(3)'\x...';'\u...', '\U...'; u'...',u'\u...',u'\U...'这些都是什么意思?
(4)字符“汉”在str类型下显示为 '\xe6\xb1\x89',在unicode类型下为啥是这样: u'\u6c49',两者之间什么关系?
(5)unicode-escape又是啥?
回答如下:
一、字符编码
首先一点是“字符编码”(charcater coding)问题,即每个字符与某个数值(编码)的一一映射,
称为码位值(code point or code position)。早期的ASCII编码用8位二进制(一个字节),
即数值0~255范围编码了128个字符,因为英文字母就那26个,加上大小写以及一些标点符号,也够用了。
但是各国语言符号多种多样,0~255范围显然不够用,于是又有了GBK等各种编码,
最后,为了编码所有的字符,产生了统一标准:Unicode(此Unicode非pyhton中的unicode类型),
各种字符都能在Unicode中找到对应的码位值。
注:在下文中,各种进制用英文缩写代替:十进制:DEC,十六进制:HEX, 二进制:BIN。
比如,汉字字符“汉”在Unicode下的码位值为:
| DEC | 27721 |
| HEX | 6c49 |
| BIN | 0110 1100 0100 1001 |
接下来的问题就是,Unicode具体怎样存储和传输,如果用两个字节,最大就是65535,汉字据说有超过十万个,
再加上其他语言的字符,这显然不够,需要更多字节。Unicode有两种格式:UCS-2和UCS-4,UCS-2就是用2个字节,
UCS-4用4个字节,4个字节最大可达42亿,应该是够了。但是,假如为了涵盖各种字符编码,每个字符都用4个字节,
那在存储和传输中就浪费了大量空间,比如英文字母只需一个字节,而字符“汉”只需两个字节。为了节省空间,
变长编码应运而生,但是计算机在读取二进制编码时,怎么知道一个字符该读几个字节,这就需要把字符所需字节数的信息
也编码到二进制中,UTF-8就是这样的编码。
在UTF-8中,对于单字节字符,UTF-8兼容ASCII,两者编码相同;对于多字节字符,字节数的信息编码在第一个字节中,
字节数用1的个数表示,再用0隔开,接着是原来的Unicode编码,后面每个字节均以10开头,具体如下所示:
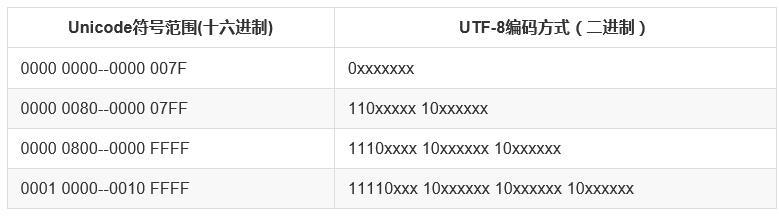
还是以字符“汉”为例,来对比下Unicode编码和UTF-8编码,
其中,utf8二进制前4个数为1110,即表示此字符占用三个字节:
| Unicode(HEX) | 6c 49 |
| Unicode(BIN) | 0110 1100, 0100 1001 |
| UTF-8(BIN) | 1110 0110, 1011 0001, 1000 1001 |
| UTF-8(HEX) | e6 b1 89 |
二、str和unicode
python2中的str和unicode是两种字符串类型(class)。
unicode就是以Unicode编码为基础的字符串类型,赋值格式为u'xxx',
相较于一般的字符串赋值,多了一个前缀"u",还是以字符“汉”为例,我看到的格式有三种:
# === 第一种,直接是字符 === In [10]: u'汉' Out[10]: u'\u6c49' In [11]: print u'汉' 汉 # === 第二种,双字节十六进制,\u小写 === In [14]: u'\u6c49' Out[14]: u'\u6c49' In [15]: print u'\u6c49' 汉 # === 第三种,四字节十六进制,\U大写 === In [16]: u'\U00006c49' Out[16]: u'\u6c49' In [17]: print u'\U00006c49' 汉
注意如果把第三种中的4个0省掉,会报错。
str是另一种字符串,用于存储和传输的编码字符串,因此不同于unicode类型,
unicode类型字符串需要经过再次编码(encode)得到str类型字符串。
In [19]: su = u'汉' In [20]: su Out[20]: u'\u6c49' In [21]: s = su.encode('utf8') In [22]: s Out[22]: '\xe6\xb1\x89' # 三个字节构成 In [23]: print s 汉 In [24]: sg = su.encode('gbk') In [25]: sg Out[25]: '\xba\xba' # 两个字节构成 In [26]: print sg ºº # 环境默认编码不是gbk,因此显示乱码 In [30]: len(su) Out[30]: 1 In [31]: len(s) Out[31]: 3 In [32]: len(sg) Out[32]: 2
反过来,str也可以解码(decode)得到unicode类型。(这里的“\x”是十六进制转义的意思,后面跟的是十六进制数字)
In [34]: s.decode('utf8') Out[34]: u'\u6c49' In [35]: print s.decode('utf8') 汉 In [36]: sg.decode('gbk') Out[36]: u'\u6c49' In [37]: print sg.decode('gbk') 汉
即:
str -- (decode) --> unicode
unicode -- (encode) --> str
还有一个问题,字符串'\u6c49'是什么意思,注意这里的'\u6c49'是str类型。
In [40]: ss = '\u6c49' In [41]: ss Out[41]: '\\u6c49' In [42]: print ss \u6c49 In [44]: ss.decode('unicode-escape') Out[44]: u'\u6c49' In [45]: print ss.decode('unicode-escape') 汉
这其实表示的是unicode-escape编码的str变量,类似的还有'\U00006c49':
In [52]: ss = '\U00006c49' In [55]: ss.decode('unicode-escape') Out[55]: u'\u6c49' In [56]: print ss.decode('unicode-escape') 汉
完毕。
参考文章
【1】字符编码笔记:ASCII,Unicode和UTF-8 by 阮一峰
【2】 https://www.zhihu.com/question/31833164 关注刘志军的回答
【3】 http://www.pitt.edu/~naraehan/python2/unicode.html handling unicode.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号