SAC In JAX【个人记录向】
众所周知,SAC 是 RL 中的一种高效的 Off Policy 算法,在《动手学强化学习》中已经给出了比较完善的实现。而 JAX 是一种新兴的神经网络范式,以函数式编程为基础,这里将以《动手学强化学习》中的实现为范本,实现一个 SAC In JAX,同时配套 tensorboard 与 model save 以及 model load。
需要提前安装 stable_baselines3==2.1.0,jax[cuda12_pip]==0.4.33,flax==0.9.0,tensorboard==2.14.0,tensorflow-probability==0.21.0,protobuf==3.20.3,mujoco==2.3.7 其他的根据提示配置一下应该问题不大了。
代码:
import os
import jax
# import gym
import flax
import optax
import distrax
import random
import collections
import numpy as np
import flax.serialization
import jax.numpy as jnp
from tqdm import tqdm
import gymnasium as gym
from flax import linen as nn
from functools import partial
from datetime import datetime
from flax.training import train_state
from flax.training.train_state import TrainState
from stable_baselines3.common.logger import configure
class RLTrainState(TrainState): # type: ignore[misc]
target_params: flax.core.FrozenDict # type: ignore[misc]
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity)
def add(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
transitions = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = zip(*transitions)
return np.array(state), action, reward, np.array(next_state), done
def size(self):
return len(self.buffer)
def save_model_state(train_state, path, name, n_steps):
"""使用flax.serialization保存单个TrainState。"""
serialized_state = flax.serialization.to_bytes(train_state)
os.makedirs(path, exist_ok=True)
extended_path = os.path.join(path, f'{name}_{n_steps}.msgpack')
with open(extended_path, 'wb') as f:
f.write(serialized_state)
print(f" - 已保存: {extended_path}")
def load_state(path, name, n_steps, train_state):
"""使用flax.serialization从文件加载单个TrainState。"""
extended_path = os.path.join(path, f'{name}_{n_steps}.msgpack')
with open(extended_path, 'rb') as f:
train_state_loaded = f.read()
return flax.serialization.from_bytes(train_state, train_state_loaded)
class EntropyCoef(nn.Module):
ent_coef_init: float = 1.0
@nn.compact
def __call__(self, step) -> jnp.ndarray:
log_ent_coef = self.param("log_ent_coef", init_fn=lambda key: jnp.full((), jnp.log(self.ent_coef_init)))
return log_ent_coef
class Critic(nn.Module):
obs_dim: int
action_dim: int
hidden_dim: int
@nn.compact
def __call__(self, obs, action):
cat = jnp.concatenate([obs, action], axis=1)
x = nn.Dense(self.hidden_dim)(cat)
x = nn.relu(x)
x = nn.Dense(self.hidden_dim)(x)
x = nn.relu(x)
x = nn.Dense(1)(x)
# x = nn.relu(x)
return x
class VectorCritic(nn.Module):
obs_dim: int
action_dim: int
hidden_dim: int
n_critics: int
@nn.compact
def __call__(self, obs, action):
vmap_critic = nn.vmap(
Critic,
variable_axes={"params": 0},
split_rngs={"params": True},
in_axes=None,
out_axes=0,
axis_size=self.n_critics,
)
q_values = vmap_critic(
obs_dim=self.obs_dim,
action_dim=self.action_dim,
hidden_dim=self.hidden_dim,
)(obs, action)
return q_values
class Actor(nn.Module):
obs_dim: int
action_dim: int
hidden_dim: int
action_scale: float
@nn.compact
def __call__(self, obs):
x = nn.Dense(self.hidden_dim)(obs)
x = nn.relu(x)
mu = nn.Dense(self.action_dim)(x)
std = nn.Dense(self.action_dim)(x)
return mu, nn.softplus(std)
@staticmethod
@partial(jax.jit, static_argnames=["action_scale"])
def sample_action(params, key, obs, actor_state, action_scale):
mu, std = actor_state.apply_fn({"params": params}, obs)
dist = distrax.Normal(loc=mu, scale=std)
# tanh_dist = distrax.Transformed(dist, distrax.Block(distrax.Tanh(), ndims=1))
# action = tanh_dist.sample(seed=key)
# log_prob = tanh_dist.log_prob(action).sum(axis=-1)
action = dist.sample(seed=key)
log_prob = dist.log_prob(action)
action = jnp.tanh(action)
# log_prob = log_prob - jnp.log(1 - jnp.square(jnp.tanh(action)) + 1e-7)
log_prob = log_prob - jnp.log(1 - jnp.square(action) + 1e-7)
return action * action_scale, log_prob
class SAC:
def __init__(self, obs_dim, action_dim, hidden_dim, batch_size,
actor_lr, critic_lr, alpha_lr,
tau=0.005, gamma=0.99, action_scale=1, target_entropy=0.01, train_alpha=False,
save_path=" ", base_name=" "):
self.obs_dim, self.action_dim, self.hidden_dim = obs_dim, action_dim, hidden_dim
self.batch_size = batch_size
self.actor_lr, self.critic_lr, self.alpha_lr = actor_lr, critic_lr, alpha_lr
self.tau, self.gamma, self.action_scale = tau, gamma, action_scale
self.train_alpha = train_alpha
self.save_path = save_path
self.base_name = base_name
self.actor = Actor(self.obs_dim, self.action_dim, self.hidden_dim, self.action_scale)
self.critic = VectorCritic(self.obs_dim, self.action_dim, self.hidden_dim, n_critics=2)
self.log_alpha = EntropyCoef(0.01)
self.target_entropy = target_entropy
self.key = jax.random.PRNGKey(0)
self.key, actor_key, critic_key, alpha_key = jax.random.split(self.key, 4)
actor_params = self.actor.init(actor_key, jnp.ones((self.batch_size, obs_dim)))['params']
critic_params = self.critic.init(critic_key, jnp.ones((self.batch_size, obs_dim)), jnp.ones((self.batch_size, action_dim)))['params']
critic_target_params = self.critic.init(critic_key, jnp.ones((self.batch_size, obs_dim)), jnp.ones((self.batch_size, action_dim)))['params']
alpha_params = self.log_alpha.init(alpha_key, 0.0)['params']
actor_optx = optax.adam(actor_lr)
critic_optx = optax.adam(critic_lr)
alpha_optx = optax.adam(alpha_lr)
self.actor_model_state = train_state.TrainState.create(apply_fn=self.actor.apply, params=actor_params, tx=actor_optx)
self.critic_model_state = RLTrainState.create(apply_fn=self.critic.apply, params=critic_params, target_params=critic_target_params, tx=critic_optx)
self.alpha_model_state = train_state.TrainState.create(apply_fn=self.log_alpha.apply, params=alpha_params, tx=alpha_optx)
def take_action(self, state):
self.key, actor_key = jax.random.split(self.key, 2)
obs = jnp.array([state])
action, _ = Actor.sample_action(self.actor_model_state.params, actor_key, obs, self.actor_model_state, self.action_scale)
return action[0]
def update(self, transition_dict):
(self.actor_model_state, self.critic_model_state, self.alpha_model_state, self.key), metrics = self._train_step(self.actor_model_state, self.critic_model_state,
self.alpha_model_state, self.key, transition_dict, self.action_scale, self.gamma, self.tau, self.target_entropy, self.train_alpha)
return metrics
@staticmethod
@partial(jax.jit, static_argnames=["action_scale", "gamma", "tau", "target_entropy", "train_alpha"])
def _train_step(actor_model_state, critic_model_state, alpha_model_state, key, transition, action_scale, gamma, tau, target_entropy, train_alpha):
states = jnp.array(transition['states'])
actions = jnp.array(transition['actions'])
rewards = jnp.array(transition['rewards']).reshape(-1, 1)
next_states = jnp.array(transition['next_states'])
dones = jnp.array(transition['dones']).reshape(-1, 1)
# rewards = (rewards + 8.0) / 8.0
critic_loss, q1_loss, q2_loss, critic_model_state, key = SAC.update_critic(states, actions, rewards, next_states, dones
, actor_model_state, critic_model_state, alpha_model_state, action_scale, gamma, key)
actor_loss, actor_model_state, key = SAC.update_actor(states, actor_model_state, critic_model_state, alpha_model_state, action_scale, key)
if train_alpha:
alpha_loss, alpha_model_state, key = SAC.update_alpha(states, actor_model_state, alpha_model_state, action_scale, target_entropy, key)
critic_model_state = SAC.soft_update(tau, critic_model_state)
metrics = {
"critic_loss": critic_loss,
"actor_loss": actor_loss,
"alpha_loss": alpha_loss if train_alpha else 0
}
return (actor_model_state, critic_model_state, alpha_model_state, key), metrics
@staticmethod
@partial(jax.jit, static_argnames=["action_scale", "gamma"])
def update_critic(states, actions, rewards, next_states, dones, actor_model_state, critic_model_state, alpha_model_state, action_scale, gamma, key):
def loss_fn(params):
def calc_target(rewards, next_states, dones, key): # 计算目标Q值
now_key, actor_key, critic_key = jax.random.split(key, 3)
next_actions, log_prob = Actor.sample_action(actor_model_state.params, actor_key, next_states, actor_model_state, action_scale)
entropy = -log_prob
q_value = critic_model_state.apply_fn({"params": critic_model_state.target_params}, next_states, next_actions)
log_alpha = alpha_model_state.apply_fn({"params": alpha_model_state.params}, 0)
log_alpha = jax.lax.stop_gradient(log_alpha)
# log_alpha = jnp.log(0.01)
q1_value, q2_value = q_value[0], q_value[1]
next_value = jax.lax.stop_gradient(jnp.min(jnp.stack([q1_value, q2_value], axis=0), axis=0) + jnp.exp(log_alpha) * entropy)
td_target = rewards + gamma * next_value * (1 - dones)
return td_target, now_key
td_target, now_key = calc_target(rewards, next_states, dones, key)
current_q = critic_model_state.apply_fn({"params": params}, states, actions)
current_q1, current_q2 = current_q[0], current_q[1]
q1_loss = jnp.mean(jnp.square(td_target - current_q1))
q2_loss = jnp.mean(jnp.square(td_target - current_q2))
critic_loss = q1_loss + q2_loss
return critic_loss, (q1_loss, q2_loss, now_key)
(critic_loss, (q1_loss, q2_loss, now_key)), grads = jax.value_and_grad(loss_fn, has_aux=True)(critic_model_state.params)
critic_model_state = critic_model_state.apply_gradients(grads=grads)
return critic_loss, q1_loss, q2_loss, critic_model_state, now_key
@staticmethod
@partial(jax.jit, static_argnames=["action_scale"])
def update_actor(states, actor_model_state, critic_model_state, alpha_model_state, action_scale, key):
def loss_fn(params):
now_key, actor_key = jax.random.split(key, 2)
next_actions, log_prob = Actor.sample_action(params, actor_key, states, actor_model_state, action_scale)
entropy = -log_prob
q_value = critic_model_state.apply_fn({"params": critic_model_state.params}, states, next_actions)
log_alpha = alpha_model_state.apply_fn({"params": alpha_model_state.params}, 0)
log_alpha = jax.lax.stop_gradient(log_alpha)
# log_alpha = jnp.log(0.01)
q1_value, q2_value = q_value[0], q_value[1]
actor_loss = jnp.mean(-jnp.exp(log_alpha) * entropy - jnp.min(jnp.stack([q1_value, q2_value], axis=0), axis=0))
return actor_loss, now_key
(actor_loss, now_key), grads = jax.value_and_grad(loss_fn, has_aux=True)(actor_model_state.params)
actor_model_state = actor_model_state.apply_gradients(grads=grads)
return actor_loss, actor_model_state, now_key
@staticmethod
@partial(jax.jit, static_argnames=["action_scale", "target_entropy"])
def update_alpha(states, actor_model_state, alpha_model_state, action_scale, target_entropy, key):
def loss_fn(params):
now_key, actor_key = jax.random.split(key, 2)
next_actions, log_prob = Actor.sample_action(actor_model_state.params, actor_key, states, actor_model_state, action_scale)
entropy = -log_prob
log_alpha = alpha_model_state.apply_fn({"params": params}, 0)
alpha_loss = jnp.mean(jax.lax.stop_gradient((entropy - target_entropy)) * jnp.exp(log_alpha))
return alpha_loss, now_key
(alpha_loss, now_key), grads = jax.value_and_grad(loss_fn, has_aux=True)(alpha_model_state.params)
alpha_model_state = alpha_model_state.apply_gradients(grads=grads)
return alpha_loss, alpha_model_state, now_key
@staticmethod
@partial(jax.jit, static_argnames=["tau"])
def soft_update(tau, model_state):
model_state = model_state.replace(
target_params=optax.incremental_update(model_state.params, model_state.target_params, tau))
return model_state
def save(self, n_steps):
print(f"正在保存模型至 {self.save_path} ...")
save_model_state(self.actor_model_state, self.save_path, f"{self.base_name}_actor", n_steps)
save_model_state(self.critic_model_state, self.save_path, f"{self.base_name}_critic", n_steps)
save_model_state(self.alpha_model_state, self.save_path, f"{self.base_name}_alpha", n_steps)
def load(self, n_steps):
print(f"正在从 {self.save_path} 加载模型...")
self.actor_model_state = load_state(self.save_path, f"{self.base_name}_actor", n_steps, self.actor_model_state)
self.critic_model_state = load_state(self.save_path, f"{self.base_name}_critic", n_steps, self.critic_model_state)
self.alpha_model_state = load_state(self.save_path, f"{self.base_name}_alpha", n_steps, self.alpha_model_state)
print("模型加载完毕。")
def train_off_policy_agent(env, agent, num_episodes, replay_buffer, minimal_size, batch_size, logger):
return_list = []
total_steps = 0
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
state, _ = env.reset()
done = False
while not done:
# print(state)
action = agent.take_action(state)
next_state, reward, done, _, info = env.step(action)
done = done or _
replay_buffer.add(state, action, reward, next_state, done)
state = next_state
episode_return += reward
total_steps += 1
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {'states': b_s, 'actions': b_a, 'next_states': b_ns, 'rewards': b_r,
'dones': b_d}
metrics = agent.update(transition_dict)
return_list.append(episode_return)
if replay_buffer.size() > minimal_size:
if (i_episode + 1) % 5 == 0:
metrics_to_log = {
"return": episode_return,
**{f"loss/{k}": v for k, v in metrics.items()} # Add a prefix to loss names
}
# TODO: 将metrics_to_log 的内容写到logger中
for key, value in metrics_to_log.items():
logger.record(key, value)
logger.dump(step=total_steps)
# if (i_episode + 1) % 10 == 0:
# agent.save(total_steps)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({'episode': '%d' % (num_episodes / 10 * i + i_episode + 1),
'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
return return_list
# env_name = 'Pendulum-v1'
env_name = "Walker2d-v4"
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
action_scale = env.action_space.high[0]
random.seed(0)
# exit(0)
actor_lr = 3e-4
critic_lr = 7e-4
alpha_lr = 3e-4
num_episodes = 20000
hidden_dim = 256
gamma = 0.99
tau = 0.005 # 软更新参数
buffer_size = 1000000
minimal_size = 10000
batch_size = 256
train_alpha = True
target_entropy = -env.action_space.shape[0]
start_time = datetime.now().strftime('%Y%m%d_%H%M%S')
# start_time = "20250910_132225"
# steps = 10263
log_path = f"logs/sac_{env_name}_{start_time}/"
logger = configure(log_path, ["stdout", "tensorboard"])
replay_buffer = ReplayBuffer(buffer_size)
model_save_path = "logs/models"
model_base_name = f"sac_{env_name}_{start_time}"
agent = SAC(obs_dim=state_dim, action_dim=action_dim, hidden_dim=hidden_dim, batch_size=batch_size, actor_lr=actor_lr, critic_lr=critic_lr
, alpha_lr=alpha_lr, tau=tau, gamma=gamma, action_scale=action_scale, target_entropy=target_entropy, train_alpha=train_alpha
, save_path=model_save_path, base_name=model_base_name)
# agent.load(steps)
return_list = train_off_policy_agent(env, agent, num_episodes, replay_buffer, minimal_size, batch_size, logger)
实验结果(In Walker2d-v4)
训练基于一块 RTX 4090,训练 timesteps 1.855M,训练总时长 15.4h。
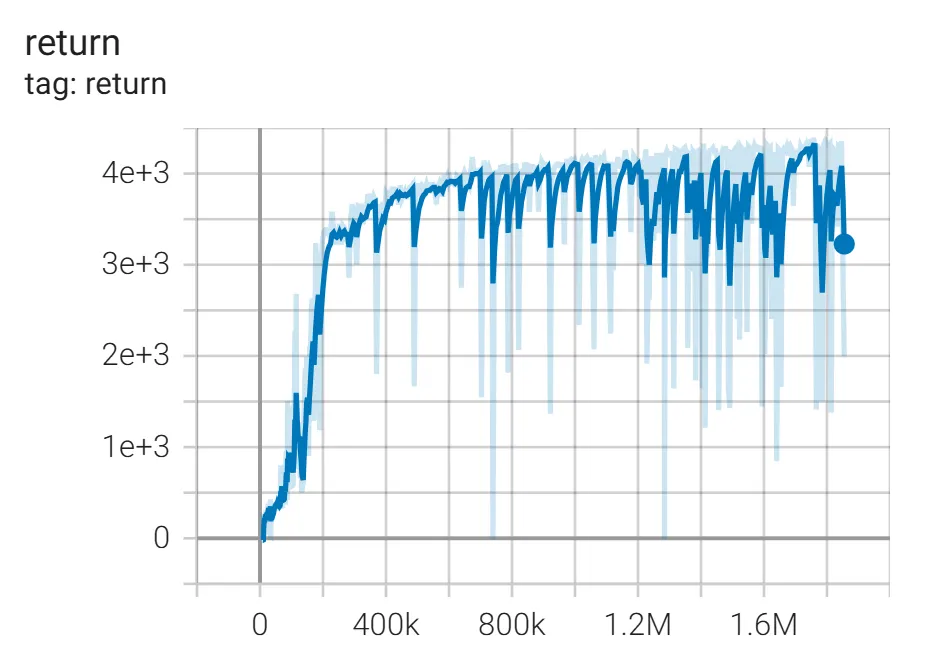
配环境+写代码+调+实验用了将近两天,能不能给个赞/kel

 浙公网安备 33010602011771号
浙公网安备 33010602011771号