

04 Hadoop思想与原理,Hbase原理
1.
用图与自己的话,简要描述Hadoop起源与发展阶段。
Hadoop起源:Hadoop是道格·卡丁(Doug Cutting)创建的,Hadoop起源于开源网络搜索引擎Apache Nutch,后者本身也是Lucene项目的一部分。Nutch项目面世后,面对数据量巨大的网页显示出了架构的灵活性不够。当时正好借鉴了谷歌分布式文件系统,做出了自己的开源系统NDFS分布式文件系统。第二年谷歌又发表了论文介绍了MapReduce系统,Nutch开发人员也开发出了MapReduce系统。随后NDFS和MapReduce命名为Hadoop,成为了Apache顶级项目。
从Hadoop的发展历程来看,它的思想来自于google的三篇论文。
GFS:Google File System 分布式处理系统 ------“解决存储问题”
Mapreduce:分布式计算模型 ------“对数据进行计算处理”
BigTable:解决查询分布式存储文件慢的问题,把所有的数据存入一张表中,通过牺牲空间换取时间。
时间线发展阶段(部分):
发行版本的描述:
从与谷歌系统的关系,关键时间节点,1.x,2.x与3.x的区别,不同公司发行版本等方面来讲。
Hadoop是一个对海量数据存储和海量数据分析计算的分布式系统。
Hadoop 1.x
海量数据存储 ----> HDFS
海量数据分析计算 ----> MapReduce
Hadoop 2.x 增加
资源调度系统 ----> Yarn
从hadoop最初的原型来看,hadoop已经远远超过了本身的批处理。从广义上来说,hadoop现在可以是指更广泛的一个hadoop生态了,而不仅仅是HDFS,MapReduce和Yarn。例如Hive,Hbase,Flume,Sqoop等等项目都属于这个生态。
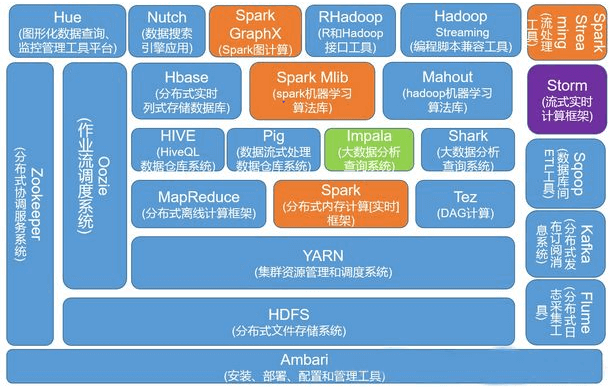
从与谷歌系统的关系,关键时间节点,1.x,2.x与3.x的区别,不同公司发行版本等方面来讲:
1.0版本和2.0版本,2011年11月,Hadoop 1.0.0版本正式发布,意味着可以用于商业化。但是,1.0版本中,存在一些问题:
(1)扩展性差,JobTracker负载较重,成为性能瓶颈。
(2)可靠性差,NameNode只有一个,万一挂掉,整个系统就会崩溃。
(3)仅适用MapReduce一种计算方式。
(4)资源管理的效率比较低。
所以,2012年5月,Hadoop推出了 2.0版本 。2.0版本中,在HDFS之上,增加了YARN(资源管理框架)层。它是一个资源管理模块,为各类应用程序提供资源管理和调度。此外,2.0版本还提升了系统的安全稳定性。所以,后来行业里基本上都是使用2.0版本。目前Hadoop又进一步发展到3.X版本。
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。
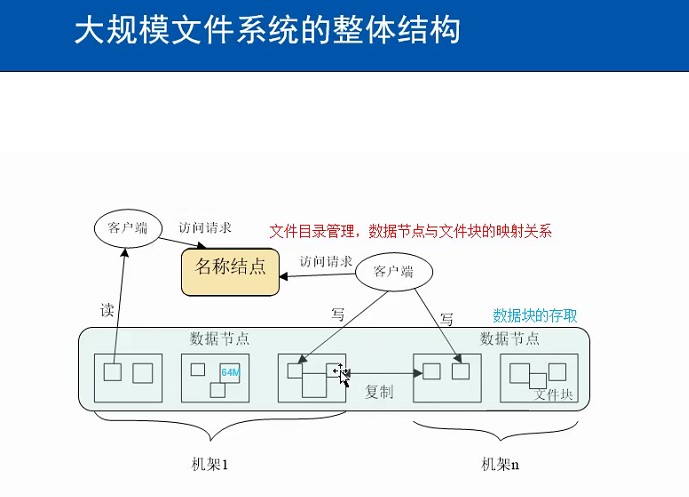
HDFS集群有两种节点,以管理者-工作者的模式运行,即一个名称节点(管理者)和多个数据节点(工作者)。名称节点管理文件系统的命名空间。它维护着这个文件系统树及这个树内所有的文件和索引目录。这些信息以两种形式将文件永久保存在本地磁盘上:命名空间镜像和编辑日志。名称节点也记录着每个文件的每个块所在的数据节点,但它并不永久保存块的位置,因为这些信息会在系统启动时由数据节点重建。
客户端代表用户通过与名称节点和数据节点交互来访问整个文件系统。客户端提供一个类似POSIX(可移植操作系统界面)的文件系统接口,因此用户在编程时并不需要知道名称节点和数据节点及其功能。
数据节点是文件系统的工作者。它们存储并提供定位块的服务(被用户或名称节点调用时),并且定时的向名称节点发送它们存储的块的列表。
没有名称节点,文件系统将无法使用。事实上,如果运行名称节点的机器被毁坏了,文件系统上所有的文件都会丢失,因为我们无法知道如何通过数据节点上的块来重建文件。因此,名称节点能够经受故障是非常重要的,Hadoop提供了两种机制来确保这一点。
第一种机制就是复制那些组成文件系统元数据持久状态的文件。Hadoop可以通过配置使名称节点在多个文件系统上写入其持久化状态。这些写操作是具同步性和原子性的。一般的配置选择是,在本地磁盘上写入的同时,写入一个远程NFS挂载(mount)。
另一种可行的方法是运行一个二级名称节点,虽然它不能作为名称节点使用。这个二级名称节点的重要作用就是定期的通过编辑日志合并命名空间镜像,以防止编辑日志过大。这个二级名称节点一般在其他单独的物理计算机上运行,因为它也需要占用大量CPU和内存来执行合并操作。它会保存合并后的命名空间镜像的副本,在名称节点失效后就可以使用。但是,二级名称节点的状态是比主节点滞后的,所以主节点的数据若全部丢失,损失仍在所难免。在这种情况下,一般把存在NFS上的主名称节点元数据复制到二级名称节点上并将其作为新的主名称节点运行。
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能。
- Zookeeper协同的功能.
- Client客户端的请求流程
- 四者之间的相系关系
- 与HDFS的关联

(1)Master主服务器的功能
管理用户对Table表的增、删、改、查操作;
管理HRegion服务器的负载均衡,调整HRegion分布;
(2)Region服务器的功能
HRegion部分由很多的HRegion组成,存储的是实际的数据。每一个HRegion又由很多的Store组成,每一个Store存储的实际上是一个列簇(ColumnFamily)下的数据。
(3)Zookeeper协同的功能
zookeeper是hbase集群的"协调器"。由于zookeeper的轻量级特性,因此我们可以将多个hbase集群共用一个zookeeper集群,以节约大量的服务器.
(4)Client客户端的请求流程
Client请求Zookeeper确定meta表所在的RegionServer所在的地址,接着根据Rowkey找到数据所归属的RegionServer;用户提交put或delete请求时HbaseClient会将put或delete请求添加到本地buffer中,符合一定条件会通过异步批量提交服务器处理。
(5)与HDFS的关联
HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的,Hadoop HDFS为HBase提供了高可靠性的底层存储支持。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统
5.理解并描述Hbase表与Region与HDFS的关系。
HBase 在 HDFS 之上提供了:
①、高并发实时随机写,通过 LSM(内存+顺序写磁盘)的方式提供了 HDFS 所不拥有的实时随机写及修改功能
②、高并发实时点读及扫描了解一下 LSM 算法,在文件系统之上有数据库,在业务层面,HBase 完全可以独立于 HDFS 来理解
6.理解并描述Hbase的三级寻址。

7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
Hbase表最大为:(2GB/1KB)*(2GB/1KB)=2^42GB即4ZB。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号