
【生成扩散模型】通过随机微分方程(SDE)构建 基于分数的生成建模
2026-01-24 08:05 tlnshuju 阅读(13) 评论(0) 收藏 举报文章目录
前言
扩散模型的核心是加噪和去噪的过程通过离散的,但它依然属于随机过程的范畴,而就是,这一过程里数据随时间(或步骤)的随机变化能够看作一个随机过程。虽然实际中扩散模型的时间SDE 作为描述随机过程的通用工具,能为这类 “连续时间 + 随机扰动” 的演化提供严谨的数学表达 ——大部分随机过程都可视为 SDE 的解,这让它能精准刻画扩散模型中数据从真实分布到噪声分布,再从噪声分布逆推回真实分布的全过程。
背景
基于朗之万动力学的去噪分数匹配(SMLD)
参考文章:基于分数的生成模型SMLD(score-Matching) ------- Langevin Dynamics(朗之万动力学)公式推导
设 p σ ( x ~ ∣ x ) : = N ( x ~ ; x , σ 2 I ) p_\sigma(\tilde{x} | x) := \mathcal{N}(\tilde{x}; x, \sigma^2 I)pσ(x~∣x):=N(x~;x,σ2I)为扰动核(perturbation kernel),p σ ( x ~ ) : = ∫ p data ( x ) p σ ( x ~ ∣ x ) d x p_\sigma(\tilde{x}) := \int p_{\text{data}}(x) p_\sigma(\tilde{x} | x) dxpσ(x~):=∫pdata(x)pσ(x~∣x)dx为扰动后的边缘分布 —— 其中p data ( x ) p_{\text{data}}(x)pdata(x)表示原始数据分布。
Perturbation kernel:扰动核 —— 用均值为 x、方差为σ 2 I \sigma^2 Iσ2I的高斯分布,生成带噪声的扰动样本x ~ \tilde{x}x~。
乘以 p data ( x ) p_{\text{data}}(x)pdata(x) 是为了 “加权平均”—— 原始数据 x 本身有概率分布(有的 x 出现频繁,有的出现少),必须按原始数据的出现概率加权,才能得到所有扰动样本的整体分布。
考虑一组递增的正噪声尺度序列σ min = σ 1 < σ 2 < ⋯ < σ N = σ max \sigma_{\text{min}} = \sigma_1 < \sigma_2 < \dots < \sigma_N = \sigma_{\text{max}}σmin=σ1<σ2<⋯<σN=σmax:
- σ min \sigma_{\text{min}}σmin足够小,使得p σ min ( x ) ≈ p data ( x ) p_{\sigma_{\text{min}}}(x) \approx p_{\text{data}}(x)pσmin(x)≈pdata(x)(扰动微弱,接近原始数据分布);
- σ max \sigma_{\text{max}}σmax足够大,使得p σ max ( x ) ≈ N ( x ; 0 , σ max 2 I ) p_{\sigma_{\text{max}}}(x) \approx \mathcal{N}(x; 0, \sigma_{\text{max}}^2 I)pσmax(x)≈N(x;0,σmax2I)(扰动强烈,接近零均值高斯噪声分布)。
Song & Ermon (2019) 提出训练一个噪声条件分数网络(Noise Conditional Score Network, NCSN)s θ ( x , σ ) s_\theta(x, \sigma)sθ(x,σ),其优化目标为去噪分数匹配(denoising score matching, Vincent, 2011)目标的加权和:
θ ⋆ = arg min θ ∑ i = 1 N σ i 2 E p data ( x ) E p σ i ( x ~ ∣ x ) [ ∥ s θ ( x ~ , σ i ) − ∇ x ~ log p σ i ( x ~ ∣ x ) ∥ 2 2 ] ( 1 ) \theta^\star = \arg\min_\theta \sum_{i=1}^N \sigma_i^2 \mathbb{E}_{p_{\text{data}}(x)} \mathbb{E}_{p_{\sigma_i}(\tilde{x} | x)} \left[ \left\| s_\theta(\tilde{x}, \sigma_i) - \nabla_{\tilde{x}} \log p_{\sigma_i}(\tilde{x} | x) \right\|_2^2 \right](1)θ⋆=argθmini=1∑Nσi2Epdata(x)Epσi(x~∣x)[∥sθ(x~,σi)−∇x~logpσi(x~∣x)∥22](1)
- 网络 s θ ( x ~ , σ i ) s_\theta(\tilde{x}, \sigma_i)sθ(x~,σi):输入是 “带噪声样本x ~ \tilde{x}x~” 和 “噪声尺度σ i \sigma_iσi”,输出是 “该样本在该尺度下的去噪方向”(分数函数近似);
- 真实条件分数函数∇ x ~ log p σ i ( x ~ ∣ x ) \nabla_{\tilde{x}} \log p_{\sigma_i}(\tilde{x} | x)∇x~logpσi(x~∣x):“带噪声样本x ~ \tilde{x}x~要还原回原始数据 x 的最优方向”
- 权重 σ i 2 \sigma_i^2σi2:给不同噪声尺度的训练分配权重,避免小噪声尺度(易学习)主导训练,确保大噪声尺度(难学习)也能充分训练;
- 双层期望 E p data ( x ) E p σ i ( x ~ ∣ x ) \mathbb{E}_{p_{\text{data}}(x)} \mathbb{E}_{p_{\sigma_i}(\tilde{x} | x)}Epdata(x)Epσi(x~∣x):对 “所有原始数据” 和 “每个素材在该尺度下的所有可能噪声样本” 求平均,保证模型泛化性。
当数据量和模型容量足够时,最优基于分数的模型s θ ⋆ ( x , σ ) s_{\theta^\star}(x, \sigma)sθ⋆(x,σ),在所有 σ ∈ { σ i } i = 1 N \sigma \in \{\sigma_i\}_{i=1}^Nσ∈{σi}i=1N下,几乎处处匹配目标分数函数∇ x log p σ ( x ) \nabla_x \log p_\sigma(x)∇xlogpσ(x)。—— 即网络学会了 “在任意噪声强度下,如何判断带噪声样本的去噪方向”。
采样阶段,Song & Ermon (2019) 采用朗之万马尔可夫链蒙特卡洛(Langevin MCMC) 算法,对每个分布p σ i ( x ) p_{\sigma_i}(x)pσi(x)依次执行 M 步迭代采样:
x i m = x i m − 1 + ϵ i s θ ⋆ ( x i m − 1 , σ i ) + 2 ϵ i z i m , m = 1 , 2 , … , M ( 2 ) x_i^m = x_i^{m-1} + \epsilon_i s_{\theta^\star}(x_i^{m-1}, \sigma_i) + \sqrt{2\epsilon_i} z_i^m,\quad m = 1, 2, \dots, M(2)xim=xim−1+ϵisθ⋆(xim−1,σi)+2ϵizim,m=1,2,…,M(2)
其中:
- ϵ i > 0 \epsilon_i > 0ϵi>0 为步长;
- z i m z_i^mzim服从标准正态分布( z i m ∼ N ( 0 , I ) (z_i^m \sim \mathcal{N}(0, I)(zim∼N(0,I))。
采样过程按噪声尺度从大到小依次执行( i = N , N − 1 , … , 1 (i = N, N-1, \dots, 1(i=N,N−1,…,1):
- 初始采样:x N 0 ∼ N ( x ; 0 , σ max 2 I ) x_N^0 \sim \mathcal{N}(x; 0, \sigma_{\text{max}}^2 I)xN0∼N(x;0,σmax2I)(从最大噪声尺度的高斯分布开始);
- 尺度衔接:当 (i < N) 时,前一尺度的最终采样结果作为当前尺度的初始值,即x i 0 = x i + 1 M x_i^0 = x_{i+1}^Mxi0=xi+1M。
在一定正则性条件下,当所有尺度的迭代步数M → ∞ M \to \inftyM→∞ 且步长 ϵ i → 0 \epsilon_i \to 0ϵi→0 时,最小噪声尺度对应的最终采样结果x 1 M x_1^Mx1M 成为 p σ min ( x ) ≈ p data ( x ) p_{\sigma_{\text{min}}}(x) \approx p_{\text{data}}(x)pσmin(x)≈pdata(x)的精确样本(即原始数据分布的样本)。
去噪扩散概率模型(DDPM)
Sohl-Dickstein 等人(2015)、Ho 等人(2020)提出考虑一组正噪声尺度序列0 < β 1 , β 2 , … , β N < 1 0 < \beta_1, \beta_2, \dots, \beta_N < 10<β1,β2,…,βN<1。对于每个服从数据分布的训练样本x 0 ∼ p data ( x ) x_0 \sim p_{\text{data}}(x)x0∼pdata(x),构造离散马尔可夫链{ x 0 , x 1 , … , x N } \{x_0, x_1, \dots, x_N\}{x0,x1,…,xN},满足:
- 转移概率 ( p ( x i ∣ x i − 1 ) = N ( x i ; 1 − β i x i − 1 , β i I ) (p(x_i | x_{i-1}) = \mathcal{N}(x_i; \sqrt{1 - \beta_i}x_{i-1}, \beta_i I)(p(xi∣xi−1)=N(xi;1−βixi−1,βiI)(从 x i − 1 x_{i-1}xi−1 到 x i x_ixi的单步扰动规则);
通俗理解:比如 x i − 1 x_{i-1}xi−1是 “轻度模糊的照片” (保留 x i − 1 x_{i-1}xi−1 的核心特征),乘以 1 − β i \sqrt{1 - \beta_i}1−βi 后 “稍微缩小特征幅值” ,再加方差为β i \beta_iβi的噪声,得到 “更模糊一点的照片x i x_ixi” (β i \beta_iβi越小,噪声越弱)。
- 由此可推导得累积转移概率p α i ( x i ∣ x 0 ) = N ( x i ; α i x 0 , ( 1 − α i ) I ) p_{\alpha_i}(x_i | x_0) = \mathcal{N}(x_i; \sqrt{\alpha_i}x_0, (1 - \alpha_i)I)pαi(xi∣x0)=N(xi;αix0,(1−αi)I)(从 x 0 x_0x0 直接到 x i x_ixi的多步累积扰动),其中α i : = ∏ j = 1 i ( 1 − β j ) \alpha_i := \prod_{j=1}^i (1 - \beta_j)αi:=∏j=1i(1−βj)(累积保持系数,随 i 增大而减小)。-----------(由于该过程是马尔科夫链,从初始数据x 0 x_0x0到最终噪声x T x_TxT的完成轨迹的的联合概率分布,可以表示为所有单步转移概率的连乘)
由于每一步扰动都是独立高斯噪声,N 步累积后仍服从高斯分布(高斯分布的可加性);
α i \sqrt{\alpha_i}αi 是原始数据 x 0 x_0x0经过 i 步扰动后的 “特征保留比例”,1 − α i 1 - \alpha_i1−αi 是 “累积噪声比例”.
与 SMLD 类似,扰动后的数据分布可表示为 p α i ( x ~ ) : = ∫ p data ( x ) p α i ( x ~ ∣ x ) d x p_{\alpha_i}(\tilde{x}) := \int p_{\text{data}}(x) p_{\alpha_i}(\tilde{x} | x) dxpαi(x~):=∫pdata(x)pαi(x~∣x)dx(所有原始数据经 i 步扰动后,扰动样本的整体分布)。噪声尺度的设置需满足:最终状态x N x_NxN近似服从标准高斯分布N ( 0 , I ) \mathcal{N}(0, I)N(0,I)(完全噪声状态)。
反向过程中,变分马尔可夫链经过以下概率分布参数化:
p θ ( x i − 1 ∣ x i ) = N ( x i − 1 ; 1 1 − β i ( x i + β i s θ ( x i , i ) ) , β i I ) p_\theta(x_{i-1} | x_i) = \mathcal{N}\left(x_{i-1}; \frac{1}{\sqrt{1 - \beta_i}} \left(x_i + \beta_i s_\theta(x_i, i)\right), \beta_i I\right)pθ(xi−1∣xi)=N(xi−1;1−βi1(xi+βisθ(xi,i)),βiI)
模型训练采用证据下界(ELBO)的重加权变体,优化目标为:
θ ⋆ = arg min θ ∑ i = 1 N ( 1 − α i ) E p data ( x ) E p α i ( x ~ ∣ x ) [ ∥ s θ ( x ~ , i ) − ∇ x ~ log p α i ( x ~ ∣ x ) ∥ 2 2 ] ( 3 ) \theta^\star = \arg\min_\theta \sum_{i=1}^N (1 - \alpha_i) \mathbb{E}_{p_{\text{data}}(x)} \mathbb{E}_{p_{\alpha_i}(\tilde{x} | x)} \left[ \left\| s_\theta(\tilde{x}, i) - \nabla_{\tilde{x}} \log p_{\alpha_i}(\tilde{x} | x) \right\|_2^2 \right](3)θ⋆=argθmini=1∑N(1−αi)Epdata(x)Epαi(x~∣x)[∥sθ(x~,i)−∇x~logpαi(x~∣x)∥22](3)
经过公式(3)求得最优模型s θ ⋆ ( x , i ) s_{\theta^\star}(x, i)sθ⋆(x,i)后,生成样本的过程如下:
- 从标准高斯分布x N ∼ N ( 0 , I ) x_N \sim \mathcal{N}(0, I)xN∼N(0,I)中采样初始噪声样本;
- 沿估计的反向马尔可夫链从后向前迭代( i = N , N − 1 , … , 1 (i = N, N-1, \dots, 1(i=N,N−1,…,1):
x i − 1 = 1 1 − β i ( x i + β i s θ ⋆ ( x i , i ) ) + β i z i ( 4 ) x_{i-1} = \frac{1}{\sqrt{1 - \beta_i}} \left( x_i + \beta_i s_{\theta^\star}(x_i, i) \right) + \sqrt{\beta_i} z_i(4)xi−1=1−βi1(xi+βisθ⋆(xi,i))+βizi(4)
其中 z i ∼ N ( 0 , I ) z_i \sim \mathcal{N}(0, I)zi∼N(0,I)为标准正态噪声。
- s θ ⋆ ( x i , i ) = ∇ x log p α i ( x i ) s_{\theta^\star}(x_i, i) = \nabla_x \log p_{\alpha_i}(x_i)sθ⋆(xi,i)=∇xlogpαi(xi),即 “噪声样本 x i x_ixi所在分布的梯度方向”—— 这个方向就是 “概率密度增加最快的方向”,也就是 “最可能的去噪方向”.
- 正向过程中,β i \beta_iβi是 “第 i 步加的噪声强度”;反向过程中,去噪幅度必须和加噪强度对应—— 加的噪声越多( β i (\beta_i(βi越大),去噪幅度就越大;
- 当前噪声样本x i x_ixi 包含 “噪声 + 少量原始特征”,加上 “校准后的去噪调整幅度”,相当于 “减去噪声带来的偏差”。
- 正向过程中,单步转移概率的均值是 1 − β i ⋅ x i − 1 \sqrt{1 - \beta_i} \cdot x_{i-1}1−βi⋅xi−1(即 “清晰样本x i − 1 x_{i-1}xi−1乘以小于 1 的系数,再叠加噪声得到x i x_ixi”);反向过程中,需要除以这个系数,把 “初步去噪后的样本” 还原到原始幅值范围,避免样本数值被过度压缩。
我们将该采样方法称为祖先采样(ancestral sampling)—— 其本质是对概率图模型∏ i = 1 N p θ ( x i − 1 ∣ x i ) \prod_{i=1}^N p_\theta(x_{i-1} | x_i)∏i=1Npθ(xi−1∣xi)执行祖先采样。公式(3)对应的目标函数即为 Ho 等人(2020)中的L simple L_{\text{simple}}Lsimple去噪分数匹配目标的加权和,这意味着最优模型就是,此处采用与公式(1)更具相似性的形式书写。与公式(1)类似,公式(3)也s θ ⋆ ( x ~ , i ) s_{\theta^\star}(\tilde{x}, i)sθ⋆(x~,i)会匹配扰动数据分布的分数函数∇ x log p α i ( x ) \nabla_x \log p_{\alpha_i}(x)∇xlogpαi(x)。
值得注意的是,公式(1)和(3)中第 i 项求和的权重(分别为σ i 2 \sigma_i^2σi2 和 ( 1 − α i ) (1 - \alpha_i)(1−αi)),与对应扰动核的函数形式存在相同关联:σ i 2 ∝ 1 / E [ ∥ ∇ x log p σ i ( x ~ ∣ x ) ∥ 2 2 ] \sigma_i^2 \propto 1 / \mathbb{E}\left[ \left\| \nabla_x \log p_{\sigma_i}(\tilde{x} | x) \right\|_2^2 \right]σi2∝1/E[∥∇xlogpσi(x~∣x)∥22],且 ( 1 − α i ) ∝ 1 / E [ ∥ ∇ x log p α i ( x ~ ∣ x ) ∥ 2 2 ] (1 - \alpha_i) \propto 1 / \mathbb{E}\left[ \left\| \nabla_x \log p_{\alpha_i}(\tilde{x} | x) \right\|_2^2 \right](1−αi)∝1/E[∥∇xlogpαi(x~∣x)∥22](权重与条件分数函数的二阶矩成反比)。
| 特征 | DDPM | NCSN |
|---|---|---|
| 噪声尺度表示 | 步数 i + 累积保持系数α i \alpha_iαi | 直接用噪声尺度σ i \sigma_iσi |
| 正向过程 | 离散马尔可夫链(逐步轻微加噪) | 单步固定尺度加噪(多尺度并行) |
| 反向采样算法 | 祖先采样(固定方差高斯分布) | 朗之万 MCMC(梯度引导 + 随机探索) |
| 训练目标来源 | 变分推断 ELBO(等价分数匹配) | 直接去噪分数匹配 |
| 核心优势 | 采样速度快(固定步数迭代) | 生成样本多样性更好 |
运用SDE扰动材料
将数据通过无限多个噪声尺度进行连续扰动,使得扰动后的分布随噪声强度增加而遵循 SDE 演化,最终从原始数据分布转化为易于采样的先验分布 “分数扩散模型”(Score-Based Diffusion Models)的核心思想。就是。这
“生成模型要造出自带‘真实感’的扰动数据,关键是得有不同强度的噪声 —— 不是只加一次固定噪声,而是用随机微分方程(SDE)让噪声‘连续加码’。
为啥要这么做呢?原来的数据里,有的地方信息点挤得密(密度高),有的地方稀稀拉拉(密度低)。倘若直接在原始数据里瞎采样,大概率会抽到那些稀疏的‘冷门区域’,很难覆盖到大家想要的目标点。而用SDE 让噪声慢慢增强,就像给数据点‘逐步松绑’:随着噪声强度一点点变大,原本集中在高密度区的数据会慢慢扩散开来,稀疏区也能被均匀覆盖,这样采样时就更容易碰到我们需要的目标点,最后还能让内容从原始分布平滑变成好采样的纯噪声分布,为后续生成真实数据打基础。”
扩散过程的定义:构造一个由连续时间变量t ∈ [ 0 , T ] t \in [0, T]t∈[0,T]索引的扩散过程{ x ( t ) } t = 0 T \{x(t)\}_{t=0}^T{x(t)}t=0T,满足:
- x ( 0 ) ∼ p 0 x(0) \sim p_0x(0)∼p0:初始状态服从原始数据分布(p 0 p_0p0),即我们有独立同分布(i.i.d.)的样本数据集;
- x ( T ) ∼ p T x(T) \sim p_Tx(T)∼pT:最终状态服从先验分布(p T p_TpT),这是一种易于高效生成样本的 “便捷分布”(如高斯分布)。
直观理解:随着时间 t 从 0 增加到 T,数据x ( t ) x(t)x(t)逐渐被噪声 “污染”,从真实数据分布p 0 p_0p0平滑过渡到先验分布p T p_TpT(如纯噪声分布)。
- p t ( x ) p_t(x)pt(x):状态 x ( t ) x(t)x(t)在时间 t 的概率密度函数,描述 t 时刻数据的分布;p s → t ( x ( t ) ∣ x ( s ) ) p_{s \to t}(x(t) | x(s))ps→t(x(t)∣x(s)):
- 转移核(transition kernel)—— 描述从时间 s 的状态x ( s ) x(s)x(s)演化到时间 t 的状态x ( t ) x(t)x(t)的条件概率分布(0 ≤ s < t ≤ T 0 \leq s < t \leq T0≤s<t≤T)。
该扩散过程被建模为伊藤型随机微分方程(Ito SDE):
d x = f ( x , t ) d t + g ( t ) d w dx = f(x, t)dt + g(t)dwdx=f(x,t)dt+g(t)dw
- w:标准维纳过程(Wiener Process,即布朗运动)—— 核心随机源,引入噪声扰动;
- f ( ⋅ , t ) : R d → R d f(\cdot, t) : \mathbb{R}^d \to \mathbb{R}^df(⋅,t):Rd→Rd:漂移系数(drift coefficient)—— 向量值函数,描述系统的确定性演化趋势;
- g ( ⋅ ) : R → R g(\cdot) : \mathbb{R} \to \mathbb{R}g(⋅):R→R:扩散系数(diffusion coefficient)—— 标量函数,描述随机扰动的强度,仅与时间 t 相关
只要系数 f 和 g 在状态和时间上满足全局利普希茨条件(Lipschitz condition),SDE 就存在唯一强解(ksendal, 2003)—— 若不满足利普希茨条件:比如f ( x , t ) = x 2 f(x,t) = x^2f(x,t)=x2(变化率无上限),SDE 可能出现 “解爆炸”((x(t)) 随时间趋于无穷大)或 “解不唯一”(同一噪声下,数据可能扩散到两个完全不同的方向)。
全局利普希茨条件(Lipschitz condition):函数的变化率有明确上限,不会 “突变”。
对 SDE 中的系数f ( x , t ) f(x,t)f(x,t)(漂移系数)和g ( x , t ) g(x,t)g(x,t)(扩散系数),全局利普希茨条件要求:存在一个固定常数 (L > 0)(利普希茨常数),对任意两个状态 (x_1、x_2) 和任意时间t ∈ [ 0 , T ] t \in [0,T]t∈[0,T],都满足:
∥ f ( x 1 , t ) − f ( x 2 , t ) ∥ ≤ L ⋅ ∥ x 1 − x 2 ∥ \|f(x_1,t) - f(x_2,t)\| \leq L \cdot \|x_1 - x_2\|∥f(x1,t)−f(x2,t)∥≤L⋅∥x1−x2∥∣ g ( x 1 , t ) − g ( x 2 , t ) ∥ ≤ L ⋅ ∥ x 1 − x 2 ∥ |g(x_1,t) - g(x_2,t)\| \leq L \cdot \|x_1 - x_2\|∣g(x1,t)−g(x2,t)∥≤L⋅∥x1−x2∥不管在什么状态、什么时间,两个状态的 “距离” 乘以 L,总能 “管住” 系数 f(或 g)在这两个状态下的 “差值”。
强解(Strong Solution)SDE 的解是 “随机过程 (x(t))”.
强解的核心是:解 (x(t)) 完全由随机源(布朗运动 (w(t)))决定。通俗理解:给定一个固定的布朗运动轨迹(比如 “某一次噪声的具体建立”),对应的 SDE 解是唯一的 “解和布朗运动一起被确定”,同一噪声轨迹可能对应多个解,无法直接用于数值计算(所以生成模型、工程场景都必须强解)。就是。反之,“弱解” 则
通过反向随机微分方程生成样本
从服从先验分布x ( T ) ∼ p T x(T) \sim p_Tx(T)∼pT的样本出发,反向执行上述扩散过程,即可得到服从原始数据分布x ( 0 ) ∼ p 0 x(0) \sim p_0x(0)∼p0 的样本。
Anderson (1982) 的一项关键研究结果表明:扩散过程的反向过程同样是一个扩散过程—— 该过程沿时间反向运行,由反向时间随机微分方程(reverse-time SDE) 描述:
d x = [ f ( x , t ) − g ( t ) 2 ∇ x log p t ( x ) ] d t + g ( t ) d w ˉ ( 6 ) dx = \left[ f(x, t) - g(t)^2 \nabla_x \log p_t(x) \right] dt + g(t)d\bar{w}(6)dx=[f(x,t)−g(t)2∇xlogpt(x)]dt+g(t)dwˉ(6)
其中:
- w ˉ \bar{w}wˉ:当时间从 T 反向流向 0 时的标准维纳过程(布朗运动);
- dt:无穷小的负时间步长(体现 “时间反向”);
- ∇ x log p t ( x ) \nabla_x \log p_t(x)∇xlogpt(x):各边缘分布p t ( x ) p_t(x)pt(x) 的分数函数(score function),即对数概率密度关于状态 x 的梯度。只要已知所有时间 t 下边缘分布的分数函数∇ x log p t ( x ) \nabla_x \log p_t(x)∇xlogpt(x),就能通过公式(6)推导得到反向扩散过程,并通过模拟该过程从先验分布p T p_TpT中采样得到原始数据分布p 0 p_0p0 的样本。
核心差异在于漂移项多了 “分数函数修正项”− g ( t ) 2 ∇ x log p t ( x ) -g(t)^2 \nabla_x \log p_t(x)−g(t)2∇xlogpt(x),这是反向过程能 “去噪声、还原数据” 的核心:在正向趋势基础上,用分数函数 “修正方向”,引导样本从噪声向数据的高密度区域移动(即 “去模糊”)。
若 (x(t)) 是模糊照片中的一个像素,分数函数会引导该像素向 “清晰照片中对应像素的位置” 移动。
反向过程没有 “真实数据标签”,全靠分数函数给予 “去噪声的方向指引”,这也是 “基于分数的生成模型” 名称的由来。
基于分数的生成模型(通过SDE实现)“正向扩散-逆向生成”双过程,如下图所示: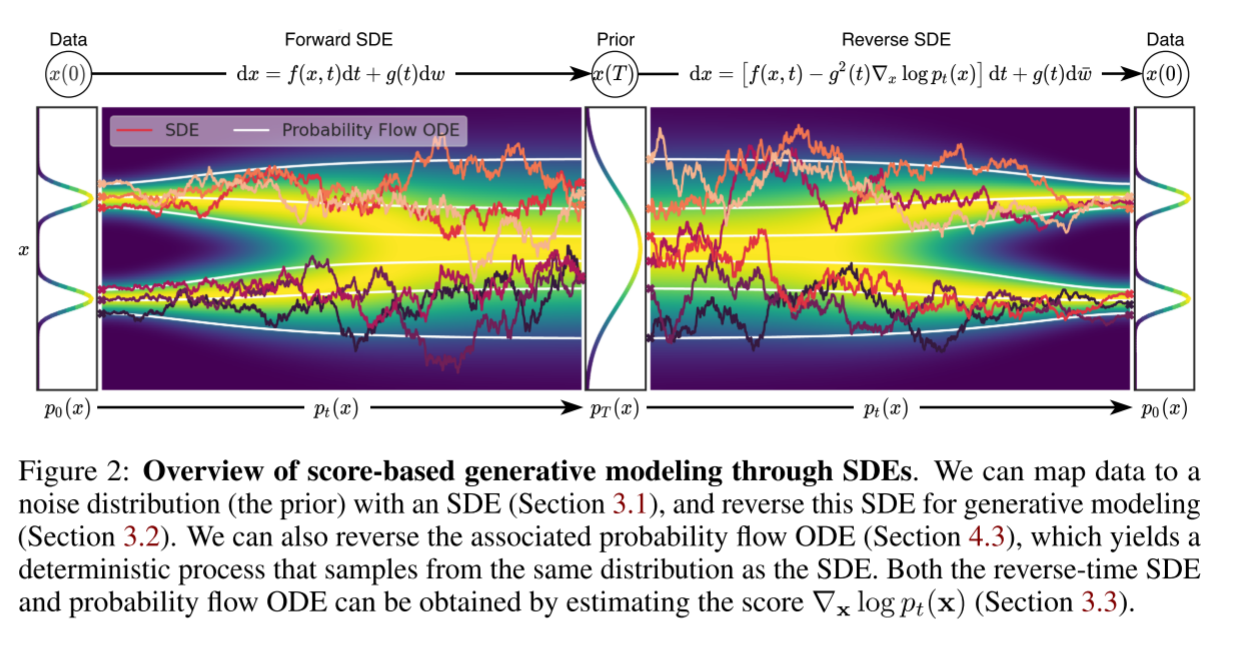
评估SDE的分数
分布的分数函数可通过分数匹配(score matching) 办法,在样本上训练基于分数的模型来估计(Hyvärinen, 2005; Song et al., 2019a)。为估计∇ x log p t ( x ) \nabla_x \log p_t(x)∇xlogpt(x),我们可通过对公式(1)和(3)的连续时间推广,训练一个依赖时间的基于分数的模型s θ ( x , t ) s_\theta(x, t)sθ(x,t),其优化目标为:
θ ⋆ = arg min θ E t { λ ( t ) E p 0 ( x ) E p 0 → t ( x ( t ) ∣ x ( 0 ) ) [ ∥ s θ ( x ( t ) , t ) − ∇ x ( t ) log p 0 → t ( x ( t ) ∣ x ( 0 ) ) ∥ 2 2 ] } ( 7 ) \theta^\star = \arg\min_\theta \mathbb{E}_t \left\{ \lambda(t) \mathbb{E}_{p_0(x)} \mathbb{E}_{p_{0 \to t}(x(t) | x(0))} \left[ \left\| s_\theta(x(t), t) - \nabla_{x(t)} \log p_{0 \to t}(x(t) | x(0)) \right\|_2^2 \right] \right\}(7)θ⋆=argθminEt{λ(t)Ep0(x)Ep0→t(x(t)∣x(0))[sθ(x(t),t)−∇x(t)logp0→t(x(t)∣x(0))22]}(7)
其中:
λ : [ 0 , T ] → R > 0 \lambda: [0, T] \to \mathbb{R}_{>0}λ:[0,T]→R>0:正权重函数;
t:在 [ 0 , T ] [0, T][0,T]上均匀采样的时间;
x ( 0 ) ∼ p 0 ( x ) x(0) \sim p_0(x)x(0)∼p0(x):原始数据样本(服从数据分布p 0 p_0p0);
x ( t ) ∼ p 0 → t ( x ( t ) ∣ x ( 0 ) ) x(t) \sim p_{0 \to t}(x(t) | x(0))x(t)∼p0→t(x(t)∣x(0)):从 x ( 0 ) x(0)x(0)经正向 SDE 演化到 t 时刻的扰动样本(服从正向转移核p 0 → t p_{0 \to t}p0→t);
∇ x ( t ) log p 0 → t ( x ( t ) ∣ x ( 0 ) ) \nabla_{x(t)} \log p_{0 \to t}(x(t) | x(0))∇x(t)logp0→t(x(t)∣x(0)):条件分布 p 0 → t ( x ( t ) ∣ x ( 0 ) ) p_{0 \to t}(x(t) | x(0))p0→t(x(t)∣x(0)) 关于 x ( t ) x(t)x(t)的对数概率密度梯度(即 “条件分数函数”)。
当数据量和模型容量足够时,分数匹配可保证公式(7)的最优解s θ ⋆ ( x , t ) s_{\theta^\star}(x, t)sθ⋆(x,t),在几乎所有 x 和 t 下都等于目标分数函数∇ x log p t ( x ) \nabla_x \log p_t(x)∇xlogpt(x)。与 SMLD 和 DDPM 类似,权重函数通常可选择λ ( t ) ∝ 1 / E [ ∥ ∇ x ( t ) log p 0 → t ( x ( t ) ∣ x ( 0 ) ) ∥ 2 2 ] \lambda(t) \propto 1 / \mathbb{E} \left[ \left\| \nabla_{x(t)} \log p_{0 \to t}(x(t) | x(0)) \right\|_2^2 \right]λ(t)∝1/E[∇x(t)logp0→t(x(t)∣x(0))22](即与条件分数函数的二阶矩成反比)。
权重函数 λ ( t ) \lambda(t)λ(t):解决 “不同时间分数函数难度差异”问题:不同时间 t 下,条件分数函数∇ x ( t ) log p 0 → t ( x ( t ) ∣ x ( 0 ) ) \nabla_{x(t)} \log p_{0 \to t}(x(t) | x(0))∇x(t)logp0→t(x(t)∣x(0)) 的 “波动幅度” 不同(比如 t 接近 0 时,内容扰动小,分数函数波动大;t 接近 T 时,内容接近噪声,分数函数波动小)--------------- 给波动大的 t 分配更大权重,波动小的 t 分配更小权重,避免模型被 “容易学习的时间步” 主导;-------------λ ( t ) \lambda(t)λ(t)与条件分数函数的二阶矩成反比(即λ ( t ) ∝ 1 / E [ ∥ ⋅ ∥ 2 2 ] \lambda(t) \propto 1 / \mathbb{E}[\|\cdot\|_2^2]λ(t)∝1/E[∥⋅∥22]),相当于 “难学的时间步多花精力,易学的少花精力”。
公式(7)采用的是去噪分数匹配(denoising score matching), 为高效求解公式(7),我们通常得已知正向转移核p 0 → t ( x ( t ) ∣ x ( 0 ) ) p_{0 \to t}(x(t) | x(0))p0→t(x(t)∣x(0))
- 当漂移系数 f ( ⋅ , t ) f(\cdot, t)f(⋅,t)为仿射函数(affine function,如线性函数加常数项)时,转移核p 0 → t p_{0 \to t}p0→t高斯分布,其均值和方差通常具有闭合解(解析表达式),可通过标准办法求得;就是始终
- 对于更一般的 SDE,可借助求解柯尔莫哥洛夫前向方程(Kolmogorov’s forward equation, Øksendal, 2003) 得到p 0 → t p_{0 \to t}p0→t;此外,也可直接模拟正向 SDE 从p 0 → t p_{0 \to t}p0→t中采样,并用切片分数匹配替代公式(7)中的去噪分数匹配进行模型训练 —— 此种方式可绕过条件分数函数∇ x ( t ) log p 0 → t ( x ( t ) ∣ x ( 0 ) ) \nabla_{x(t)} \log p_{0 \to t}(x(t) | x(0))∇x(t)logp0→t(x(t)∣x(0))的计算(见附录 A)。
为什么用条件分数函数?:
因为 p 0 → t ( x ( t ) ∣ x ( 0 ) ) p_{0 \to t}(x(t) | x(0))p0→t(x(t)∣x(0)) 的解析形式更容易获取(比如漂移系数为仿射函数时是高斯分布),而p t ( x ) p_t(x)pt(x)难以直接计算 —— 用条件分数函数作为训练目标,是一种 “迂回逼近” 真实分数函数的策略;
| 获取方式 | 适用场景 | 核心特点 |
|---|---|---|
| 闭合解(解析形式) | 漂移系数 f ( ⋅ , t ) f(\cdot,t)f(⋅,t)为仿射函数(如线性函数) | 最快最精准,直接写出均值和方差(如高斯分布) |
| 求解柯尔莫哥洛夫前向方程 | 一般形式的 SDE(无解析解) | 偏微分方程求解,数学严谨但计算复杂 |
| 直接模拟 SDE 采样 | 所有 SDE(尤其是无解析解的情况) | 工程上最常用,通过数值方法(如欧拉 - 马尔可夫)生成扰动样本,无需计算分布解析形式 |
示例: VE, VP SDES AND BEYOND
SMLD 和 DDPM 中使用的噪声扰动可视为两种不同随机微分方程(SDE)的离散化形式。以下进行简要讨论,更多细节请参见附录 B。
当使用共 N 个噪声尺度时,SMLD 的每个扰动核p σ i ( x ∣ x 0 ) p_{\sigma_i}(x | x_0)pσi(x∣x0)对应如下马尔可夫链中x i x_ixi 的分布:
x i = x i − 1 + σ i 2 − σ i − 1 2 z i − 1 , i = 1 , … , N ( 8 ) x_i = x_{i-1} + \sqrt{\sigma_i^2 - \sigma_{i-1}^2} z_{i-1},\ i = 1, \dots, N(8)xi=xi−1+σi2−σi−12zi−1,i=1,…,N(8)
SMLD 的通过递增的噪声尺度逐步扰动内容就是核心,最终让数据分布变为纯噪声。公式(8)的推导基于高斯噪声的方差可加性:
为了从 x i − 1 x_{i-1}xi−1(方差 σ i − 1 2 \sigma_{i-1}^2σi−12)过渡到 x i x_ixi(方差 σ i 2 \sigma_i^2σi2),要求添加 “方差增量” 为 σ i 2 − σ i − 1 2 \sigma_i^2 - \sigma_{i-1}^2σi2−σi−12的高斯噪声。根据高斯分布的可加性:若x i − 1 ∼ N ( x 0 , σ i − 1 2 I x_{i-1} \sim \mathcal{N}(x_0, \sigma_{i-1}^2 Ixi−1∼N(x0,σi−12I),且添加独立噪声σ i 2 − σ i − 1 2 z i − 1 \sqrt{\sigma_i^2 - \sigma_{i-1}^2} z_{i-1}σi2−σi−12zi−1(其中 z i − 1 ∼ N ( 0 , I ) z_{i-1} \sim \mathcal{N}(0, I)zi−1∼N(0,I)),则:x i = x i − 1 + σ i 2 − σ i − 1 2 z i − 1 x_i = x_{i-1} + \sqrt{\sigma_i^2 - \sigma_{i-1}^2} z_{i-1}xi=xi−1+σi2−σi−12zi−1此时 x i x_ixi 的方差为:Var ( x i ) = Var ( x i − 1 ) + Var ( σ i 2 − σ i − 1 2 z i − 1 ) = σ i − 1 2 + ( σ i 2 − σ i − 1 2 ) = σ i 2 \text{Var}(x_i) = \text{Var}(x_{i-1}) + \text{Var}\left( \sqrt{\sigma_i^2 - \sigma_{i-1}^2} z_{i-1} \right) = \sigma_{i-1}^2 + (\sigma_i^2 - \sigma_{i-1}^2) = \sigma_i^2Var(xi)=Var(xi−1)+Var(σi2−σi−12zi−1)=σi−12+(σi2−σi−12)=σi2即 x i ∼ N ( x 0 , σ i 2 I ) x_i \sim \mathcal{N}(x_0, \sigma_i^2 I)xi∼N(x0,σi2I),满足设计目标。
其中 z i − 1 ∼ N ( 0 , I ) z_{i-1} \sim \mathcal{N}(0, I)zi−1∼N(0,I),且为简化符号引入σ 0 = 0 \sigma_0 = 0σ0=0。当 N → ∞ N \to \inftyN→∞ 时,{ σ i } i = 1 N \{\sigma_i\}_{i=1}^N{σi}i=1N 变为函数 σ ( t ) \sigma(t)σ(t),z i z_izi 变为 z ( t ) z(t)z(t),马尔可夫链 { x i } i = 1 N \{x_i\}_{i=1}^N{xi}i=1N变为连续随机过程{ x ( t ) } t = 0 1 \{x(t)\}_{t=0}^1{x(t)}t=01(此处用连续时间变量t ∈ [ 0 , 1 ] t \in [0, 1]t∈[0,1]索引,而非整数 i)。该过程由以下 SDE 描述:
d x = d [ σ 2 ( t ) ] d t d w ( 9 ) dx = \sqrt{\frac{d[\sigma^2(t)]}{dt}} dw(9)dx=dtd[σ2(t)]dw(9)
Δ x i = x i − x i − 1 = σ i 2 − σ i − 1 2 ⋅ z i − 1 \Delta x_i = x_i - x_{i-1} = \sqrt{\sigma_i^2 - \sigma_{i-1}^2} \cdot z_{i-1}Δxi=xi−xi−1=σi2−σi−12⋅zi−1
当 N → ∞ N \to \inftyN→∞时,时间步长Δ t = 1 N → 0 \Delta t = \frac{1}{N} \to 0Δt=N1→0,此时:
- σ i 2 − σ i − 1 2 ≈ d [ σ 2 ( t ) ] d t ⋅ Δ t \sigma_i^2 - \sigma_{i-1}^2 \approx \frac{d[\sigma^2(t)]}{dt} \cdot \Delta tσi2−σi−12≈dtd[σ2(t)]⋅Δt(函数的微分近似,即d f ( t ) ≈ f ′ ( t ) Δ t df(t) \approx f'(t) \Delta tdf(t)≈f′(t)Δt);
- z i − 1 ⋅ Δ t ≈ d w ( t ) z_{i-1} \cdot \sqrt{\Delta t} \approx dw(t)zi−1⋅Δt≈dw(t)(布朗运动的增量性质:w ( t + Δ t ) − w ( t ) ∼ N ( 0 , Δ t I w(t + \Delta t) - w(t) \sim \mathcal{N}(0, \Delta t Iw(t+Δt)−w(t)∼N(0,ΔtI),因此 z i − 1 Δ t z_{i-1} \sqrt{\Delta t}zi−1Δt 是 d w ( t ) dw(t)dw(t)的离散近似)。
将上述近似代入增量式Δ x i \Delta x_iΔxi,得到:Δ x ≈ d [ σ 2 ( t ) ] d t ⋅ Δ t ⋅ d w ( t ) Δ t = d [ σ 2 ( t ) ] d t ⋅ d w ( t ) \Delta x \approx \sqrt{\frac{d[\sigma^2(t)]}{dt} \cdot \Delta t} \cdot \frac{dw(t)}{\sqrt{\Delta t}} = \sqrt{\frac{d[\sigma^2(t)]}{dt}} \cdot dw(t)Δx≈dtd[σ2(t)]⋅Δt⋅Δtdw(t)=dtd[σ2(t)]⋅dw(t)当 Δ t → 0 \Delta t \to 0Δt→0时,增量形式过渡为微分形式,即:d x = d [ σ 2 ( t ) ] d t d w dx = \sqrt{\frac{d[\sigma^2(t)]}{dt}} \, dwdx=dtd[σ2(t)]dw
类似地,对于 DDPM 的扰动核{ p α i ( x ∣ x 0 ) } i = 1 N \{p_{\alpha_i}(x | x_0)\}_{i=1}^N{pαi(x∣x0)}i=1N,其离散马尔可夫链为:
x i = 1 − β i x i − 1 + β i z i − 1 , i = 1 , … , N ( 10 ) x_i = \sqrt{1 - \beta_i} x_{i-1} + \sqrt{\beta_i} z_{i-1},\ i = 1, \dots, N (10)xi=1−βixi−1+βizi−1,i=1,…,N(10)
DDPM 的核心是通过 “保留特征 + 添加噪声” 的方式逐步扰动数据,最终让数据分布变为纯高斯噪声。
第 i 步的扰动后分布p α i ( x i ∣ x 0 ) p_{\alpha_i}(x_i | x_0)pαi(xi∣x0) 是方差为 1 − α i 1 - \alpha_i1−αi的高斯分布(其中α i = ∏ j = 1 i ( 1 − β j ) \alpha_i = \prod_{j=1}^i (1 - \beta_j)αi=∏j=1i(1−βj),初始 α 0 = 1 \alpha_0 = 1α0=1)。
为了从 x i − 1 x_{i-1}xi−1(满足 x i − 1 ∼ N ( α i − 1 x 0 , ( 1 − α i − 1 ) I ) x_{i-1} \sim \mathcal{N}(\sqrt{\alpha_{i-1}} x_0, (1 - \alpha_{i-1}) I)xi−1∼N(αi−1x0,(1−αi−1)I))过渡到 x i x_ixi,需对 x i − 1 x_{i-1}xi−1 做 “缩放 + 加噪声” 操作:x i = 1 − β i x i − 1 + β i z i − 1 x_i = \sqrt{1 - \beta_i} \, x_{i-1} + \sqrt{\beta_i} \, z_{i-1}xi=1−βixi−1+βizi−1其中 z i − 1 ∼ N ( 0 , I ) z_{i-1} \sim \mathcal{N}(0, I)zi−1∼N(0,I)。
验证 x i x_ixi 的分布:
均值:E [ x i ] = 1 − β i ⋅ α i − 1 x 0 = ( 1 − β i ) α i − 1 x 0 = α i x 0 \mathbb{E}[x_i] = \sqrt{1 - \beta_i} \cdot \sqrt{\alpha_{i-1}} x_0 = \sqrt{(1 - \beta_i) \alpha_{i-1}} x_0 = \sqrt{\alpha_i} x_0E[xi]=1−βi⋅αi−1x0=(1−βi)αi−1x0=αix0(因为 α i = ( 1 − β i ) α i − 1 \alpha_i = (1 - \beta_i) \alpha_{i-1}αi=(1−βi)αi−1);
方差:Var ( x i ) = ( 1 − β i ) ⋅ ( 1 − α i − 1 ) + β i ⋅ 1 = 1 − β i − ( 1 − β i ) α i − 1 + β i = 1 − ( 1 − β i ) α i − 1 = 1 − α i \text{Var}(x_i) = (1 - \beta_i) \cdot (1 - \alpha_{i-1}) + \beta_i \cdot 1 = 1 - \beta_i - (1 - \beta_i) \alpha_{i-1} + \beta_i = 1 - (1 - \beta_i) \alpha_{i-1} = 1 - \alpha_iVar(xi)=(1−βi)⋅(1−αi−1)+βi⋅1=1−βi−(1−βi)αi−1+βi=1−(1−βi)αi−1=1−αi
因此,x i ∼ N ( α i x 0 , ( 1 − α i ) I ) x_i \sim \mathcal{N}(\sqrt{\alpha_i} x_0, (1 - \alpha_i) I)xi∼N(αix0,(1−αi)I),满足设计目标。
当 N → ∞ N \to \inftyN→∞时,公式(10)收敛到如下 SDE:
d x = − 1 2 β ( t ) x d t + β ( t ) d w ( 11 ) dx = -\frac{1}{2}\beta(t) x\ dt + \sqrt{\beta(t)}\ dw(11)dx=−21β(t)xdt+β(t)dw(11)
Δ x i = x i − x i − 1 = ( 1 − β i − 1 ) x i − 1 + β i z i − 1 \Delta x_i = x_i - x_{i-1} = \left( \sqrt{1 - \beta_i} - 1 \right) x_{i-1} + \sqrt{\beta_i} \, z_{i-1}Δxi=xi−xi−1=(1−βi−1)xi−1+βizi−1
当 β i ≪ 1 \beta_i \ll 1βi≪1(因 N → ∞ N \to \inftyN→∞,β i = β ( t ) Δ t ≪ 1 \beta_i = \beta(t) \Delta t \ll 1βi=β(t)Δt≪1),利用泰勒展开1 − ϵ ≈ 1 − ϵ 2 − ϵ 2 8 − … \sqrt{1 - \epsilon} \approx 1 - \frac{\epsilon}{2} - \frac{\epsilon^2}{8} - \dots1−ϵ≈1−2ϵ−8ϵ2−…,取一阶近似:1 − β i − 1 ≈ − β i 2 = − β ( t ) Δ t 2 \sqrt{1 - \beta_i} - 1 \approx -\frac{\beta_i}{2} = -\frac{\beta(t) \Delta t}{2}1−βi−1≈−2βi=−2β(t)Δt
布朗运动的增量满足w ( t + Δ t ) − w ( t ) ∼ N ( 0 , Δ t I ) w(t + \Delta t) - w(t) \sim \mathcal{N}(0, \Delta t I)w(t+Δt)−w(t)∼N(0,ΔtI),因此 z i − 1 Δ t ≈ d w ( t ) z_{i-1} \sqrt{\Delta t} \approx dw(t)zi−1Δt≈dw(t)(即 z i − 1 ≈ d w ( t ) Δ t z_{i-1} \approx \frac{dw(t)}{\sqrt{\Delta t}}zi−1≈Δtdw(t))。代入得:β i z i − 1 = β ( t ) Δ t ⋅ d w ( t ) Δ t = β ( t ) d w ( t ) \sqrt{\beta_i} \, z_{i-1} = \sqrt{\beta(t) \Delta t} \cdot \frac{dw(t)}{\sqrt{\Delta t}} = \sqrt{\beta(t)} \, dw(t)βizi−1=β(t)Δt⋅Δtdw(t)=β(t)dw(t)
将上述近似代入Δ x i \Delta x_iΔxi:
Δ x i ≈ − β ( t ) Δ t 2 x i − 1 + β ( t ) d w ( t ) \Delta x_i \approx -\frac{\beta(t) \Delta t}{2} \, x_{i-1} + \sqrt{\beta(t)} \, dw(t)Δxi≈−2β(t)Δtxi−1+β(t)dw(t)
当 Δ t → 0 \Delta t \to 0Δt→0 时,x i − 1 ≈ x ( t ) x_{i-1} \approx x(t)xi−1≈x(t)(连续过程的近似),增量Δ x i \Delta x_iΔxi过渡为微分 dx,因此:d x = − 1 2 β ( t ) x d t + β ( t ) d w ( t ) dx = -\frac{1}{2} \beta(t) x \, dt + \sqrt{\beta(t)} \, dw(t)dx=−21β(t)xdt+β(t)dw(t)
因此,SMLD 和 DDPM 中启用的噪声扰动分别对应公式(9)和(11)这两种 SDE 的离散化形式。
结尾
好文推荐:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号