
完整教程:StarRocks 2.5.22 混合部署实战文档(CDH环境)
2026-01-14 12:53 tlnshuju 阅读(6) 评论(0) 收藏 举报目录
4.3 启动 Follower 节点 (nd12, nd13)
6. Hadoop/Paimon 集成配置 (及遇到的兼容性问题)
7. 部署过程中的故障排查 (Troubleshooting)
1. 项目背景与测试动因 基于当前 Paimon+OLAP 流批一体数仓架构的建设需求,项目组虽已识别出 Doris 在大字段(Large Field)处理上的优势,但为了保障技术选型的严谨性与全面性,仍需引入 StarRocks 作为对照组进行性能基准测试(Benchmarking)。
本次部署旨在构建一个与 Doris 架构平行的测试环境。考虑到项目启动时,业界主流的稳定版本均为 2.x 系列,因此选定 StarRocks 2.5.22(LTS 版本)与 Apache Doris 2.1.10 进行同代产品的横向对比,以客观评估两者在现代数据湖场景下的综合表现。
2. 测试目标 本次测试将聚焦于“数据湖分析(Data Lake Analytics)”场景,核心目标是量化对比 StarRocks 与 Doris 在以下维度的性能差异:
数据湖联邦查询性能:对比两者通过 External Catalog 挂载 Hive 数据源时的查询响应速度与资源消耗。
选型辅助决策:通过实测数据,明确 StarRocks 在非大字段场景下是否具备显著的性能优势,从而为数仓分层架构中不同业务场景的引擎选择提供数据支撑。
3.补充说明
StarRocks 2.x不支持对Paimon的操作,官网描述网址:Paimon catalog | StarRocks
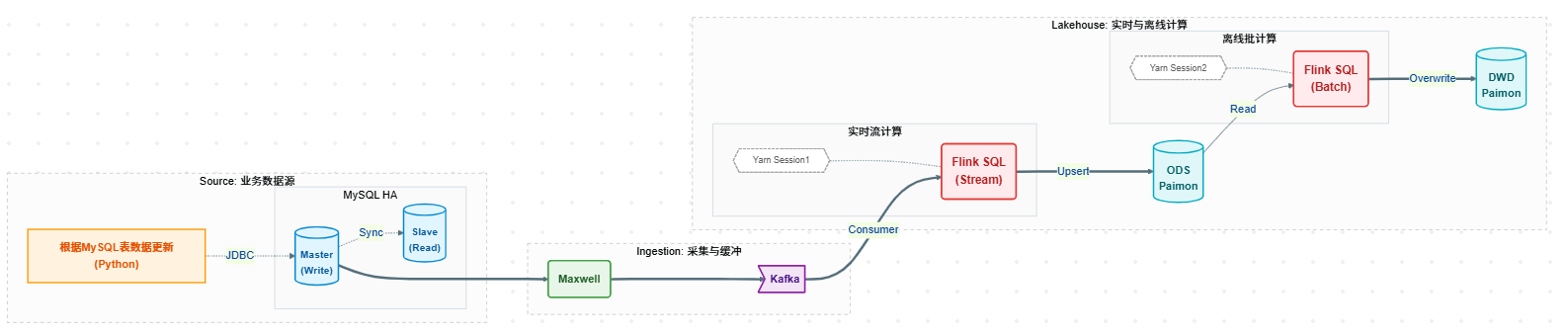
调研架构图如下:
1. 项目背景与环境
操作系统: CentOS 7 (CDH 6.3.2 环境混合部署)
节点配置:
CPU: 10核
内存: 14GB (资源紧缺,需精细调优)
存储: 400GB SSD
部署用户:
bigdataJava 环境:
/usr/java/jdk1.8.0_181-cloudera
节点分配
前置组件分配
| IP | 主机名 | 角色 | 版本 |
|---|---|---|---|
| 10.x.xx.201-10.x.xx.205 10.x.xx.215 10.x.xx.149 10.x.xx.151 10.x.xx.156 10.x.xx.157 10.x.xx.167 10.x.xx.206 | nd1-nd5 nd6 nd11 nd12 nd13 nd14 nd15 nd16 | CDH | 6.3.2 |
| 10.x.xx.201-10.x.xx.205 | nd1-nd5 | Paimon | 1.1.1 |
采用 FE (Frontend) + BE (Backend) 混合部署 模式,共 3 个节点。
| IP | Hostname | 角色 | 部署组件 |
|---|---|---|---|
| 10.x.xx.149 | nd11 | FE Leader + BE | Doris2.1.10 + StarRocks 2.5.22 |
| 10.x.xx.151 | nd12 | FE Follower + BE | Doris2.1.10 + StarRocks 2.5.22 |
| 10.x.xx.156 | nd13 | FE Follower + BE | Doris2.1.10 + StarRocks 2.5.22 |
2. 核心规划 (避坑关键)
由于 Doris 和 StarRocks 默认端口完全冲突,且同一节点 Doris 占用了部分 180xx 端口,必须严格规划 StarRocks 端口。
2.1 端口规划表
策略:基于默认端口 +10000。 特殊处理:由于 Doris BE 的 webserver_port 占用了 18040,StarRocks 若使用 default+10000 也会是 18040,因此将 StarRocks 的 BE Web 端口调整为 28040。
| 组件 | 配置文件参数 | StarRocks 默认 | StarRocks 2.5 实配 | 说明 |
|---|---|---|---|---|
| FE | http_port | 8030 | 18030 | FE Web 界面 |
| FE | rpc_port | 9020 | 19020 | FE 内部通信 |
| FE | query_port | 9030 | 19030 | MySQL 客户端连接 |
| FE | edit_log_port | 9010 | 19010 | BDBJE 高可用通信 |
| BE | be_port | 9060 | 19060 | Thrift Server |
| BE | webserver_port | 8040 | 28040 | BE Web 界面 (特殊) |
| BE | heartbeat_service_port | 9050 | 19050 | 心跳服务 |
| BE | brpc_port | 8060 | 18060 | 数据传输 |
2.2 目录规划
安装目录:
/home/bigdata/starrocks-2.5/StarRocks-2.5.22FE 元数据目录:
/home/bigdata/starrocks-2.5/metaBE 数据目录:
/home/bigdata/starrocks-2.5/storage
3. 部署前置准备 (nd11, nd12, nd13)
3.1 系统配置 (需 sudo 权限)
由于这三个节点部署了Doris 2.1.10,因此下述的配置我这里没有进行修改。
# 1. 关闭 Swap
sudo swapoff -a
# (可选) 永久关闭: sudo sed -i '/swap/s/^/#/' /etc/fstab
# 2. 修改文件句柄限制
sudo vim /etc/security/limits.conf
# 添加或修改以下内容:
* soft nofile 65535
* hard nofile 65535
* soft nproc 65535
* hard nproc 655353.2 检查 CPU AVX2 支持
StarRocks 2.x 默认需要 AVX2 指令集支持。
cat /proc/cpuinfo | grep avx2
# 如果有输出则支持。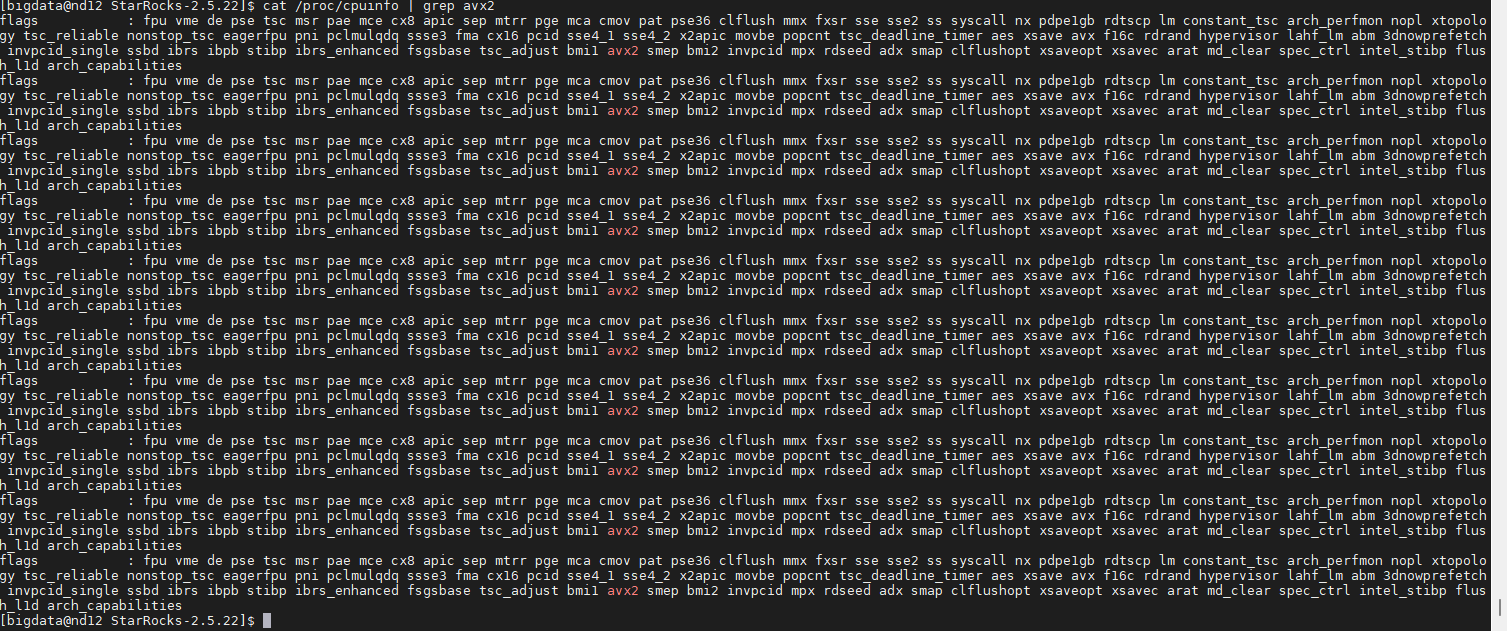
有输出:继续下一步。
无输出:您需要下载 Doris 的
x64-noavx2版本安装包,否则 BE 启动会报错Illegal instruction。
3.3 创建数据目录
mkdir -p /home/bigdata/starrocks-2.5/meta
mkdir -p /home/bigdata/starrocks-2.5/storage
3.4 准备安装包
将安装包上传并解压:
cd /home/bigdata/starrocks-2.5
tar -zxvf StarRocks-2.5.22.tar.gz经过漫长的解压,最终显示如下:
4. FE 部署步骤
4.1 修改 FE 配置
操作节点:nd11, nd12, nd13 文件路径:/home/bigdata/starrocks-2.5/StarRocks-2.5.22/fe/conf/fe.conf
vi /home/bigdata/starrocks-2.5/StarRocks-2.5.22/fe/conf/fe.conf# 1. 核心目录与端口
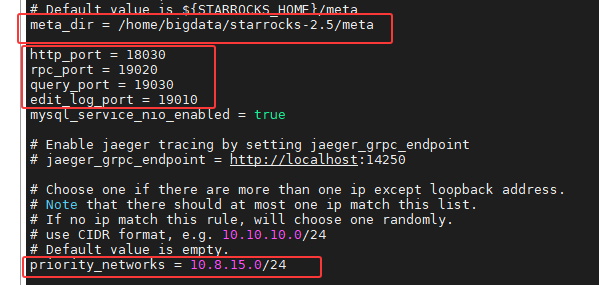
meta_dir = /home/bigdata/starrocks-2.5/meta
http_port = 18030
rpc_port = 19020
query_port = 19030
edit_log_port = 19010
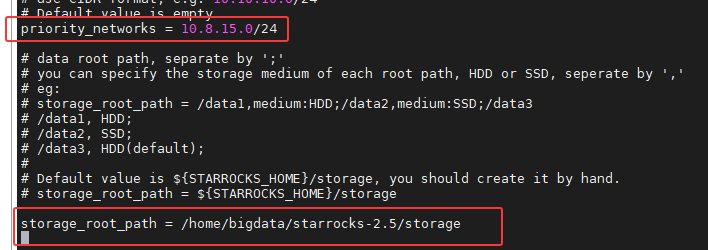
# 2. 网络绑定 (CDH多网卡环境必须配置)
priority_networks = 10.8.15.0/24
# 3. 指定 JDK (解决 CDH 默认 JDK 环境问题)
JAVA_HOME = /usr/java/jdk1.8.0_181-cloudera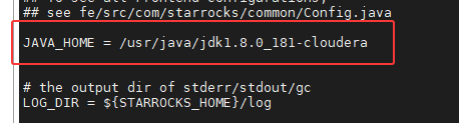
4.2 启动 Leader 节点 (nd11)
cd /home/bigdata/starrocks-2.5/StarRocks-2.5.22/fe
./bin/start_fe.sh --daemon
# ./bin/stop_fe.sh
上述Tip只是一个警告,可以使用如下命令进行查看
cat /home/bigdata/starrocks-2.5/StarRocks-2.5.22/fe/log/fe.out![]()
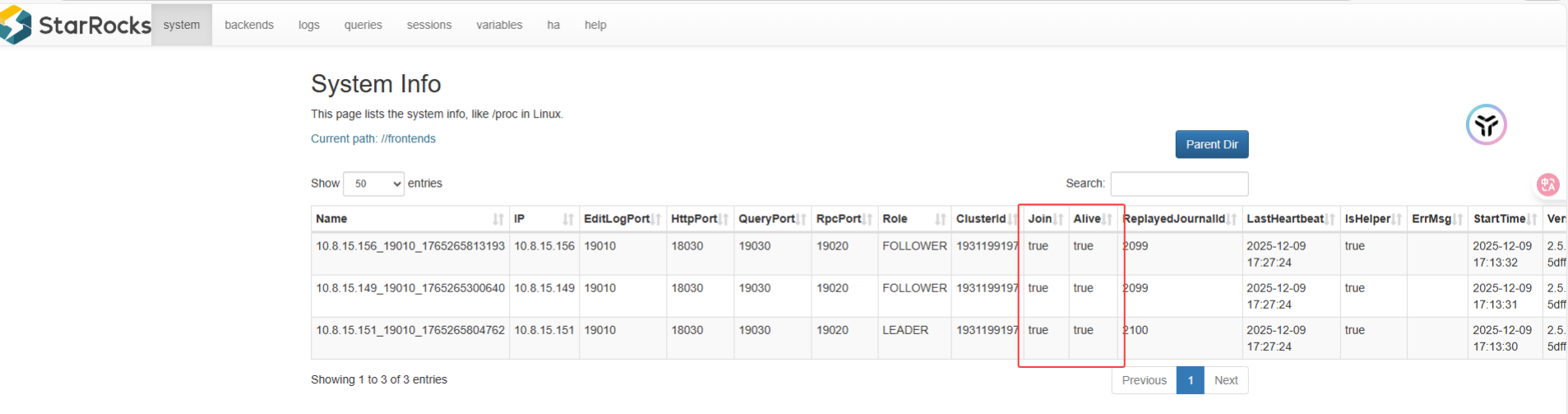
由截图看出 nd11 进程已经存活,并且成功加入集群,当前状态为 LEADE。
netstat -nltp | grep 19030
如果有输出,说明服务正常,可以继续后续操作。
4.3 启动 Follower 节点 (nd12, nd13)
关键:首次启动建议使用 --helper 指定 Leader 地址,防止网络隔离导致节点自选为 Master。
在 nd12 上执行:
/home/bigdata/starrocks-2.5/StarRocks-2.5.22/fe/bin/start_fe.sh --helper 10.x.xx.149:19010 --daemon在 nd13 上执行:
/home/bigdata/starrocks-2.5/StarRocks-2.5.22/fe/bin/start_fe.sh --helper 10.x.xx.149:19010 --daemon4.4 注册 Follower 节点
在 nd11 上通过 MySQL 客户端连接并注册另外两个节点。
# 连接 nd11
mysql -h 10.8.15.149 -P 19030 -u root-- SQL 执行
ALTER SYSTEM ADD FOLLOWER "10.x.xx.151:19010";
ALTER SYSTEM ADD FOLLOWER "10.x.xx.156:19010";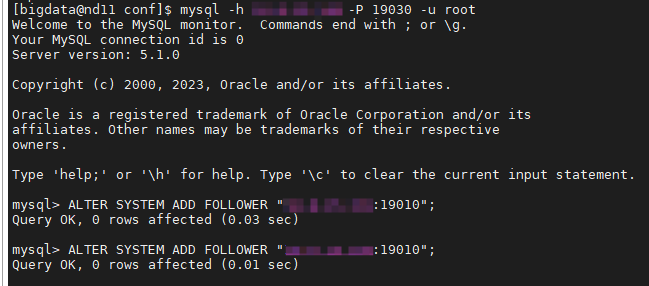
SHOW FRONTENDS;
网址查看:StarRocks Cluster
用户:root
密码:空
5. BE 部署步骤
5.1 修改 BE 配置
操作节点:nd11, nd12, nd13 文件路径:/home/bigdata/starrocks-2.5/StarRocks-2.5.22/be/conf/be.conf
vi /home/bigdata/starrocks-2.5/StarRocks-2.5.22/be/conf/be.conf# 1. 端口配置 (注意 webserver_port 为 28040)
be_port = 19060
webserver_port = 28040
heartbeat_service_port = 19050
brpc_port = 18060
# 2. 存储路径
storage_root_path = /home/bigdata/starrocks-2.5/storage
# 3. 网络绑定
priority_networks = 10.8.15.0/24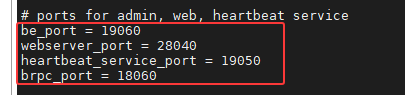
5.2 启动 BE
在三个节点依次执行:
/home/bigdata/starrocks-2.5/StarRocks-2.5.22/be/bin/start_be.sh --daemon5.3 注册 BE 节点
回到 nd11 的 MySQL 客户端执行:
ALTER SYSTEM ADD BACKEND "10.x.xx.149:19050";
ALTER SYSTEM ADD BACKEND "10.x.xx.151:19050";
ALTER SYSTEM ADD BACKEND "10.x.xx.156:19050";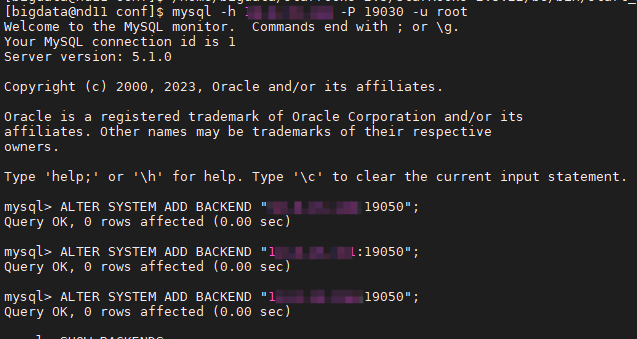
SHOW FRONTENDS;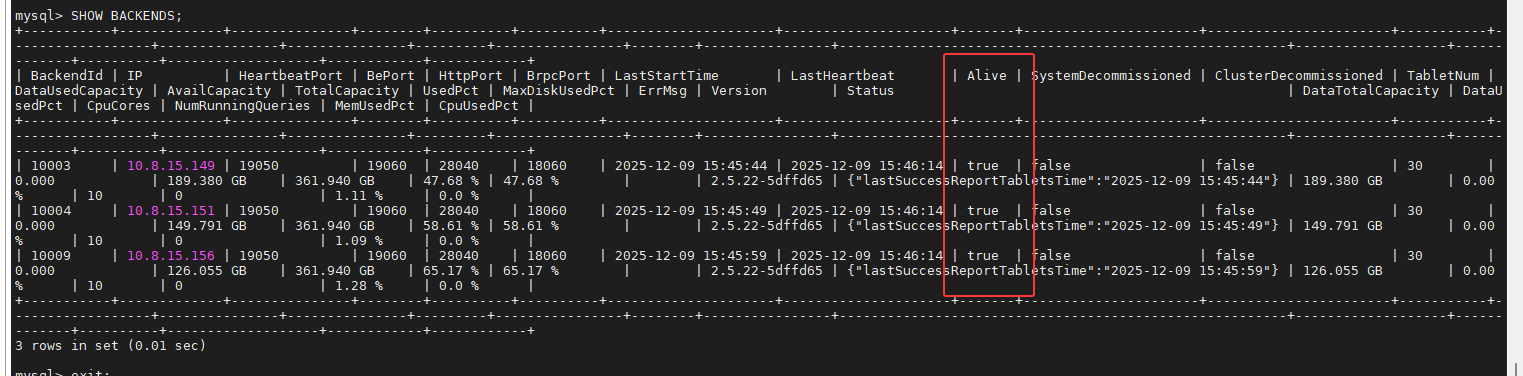
网址查看:StarRocks Cluster
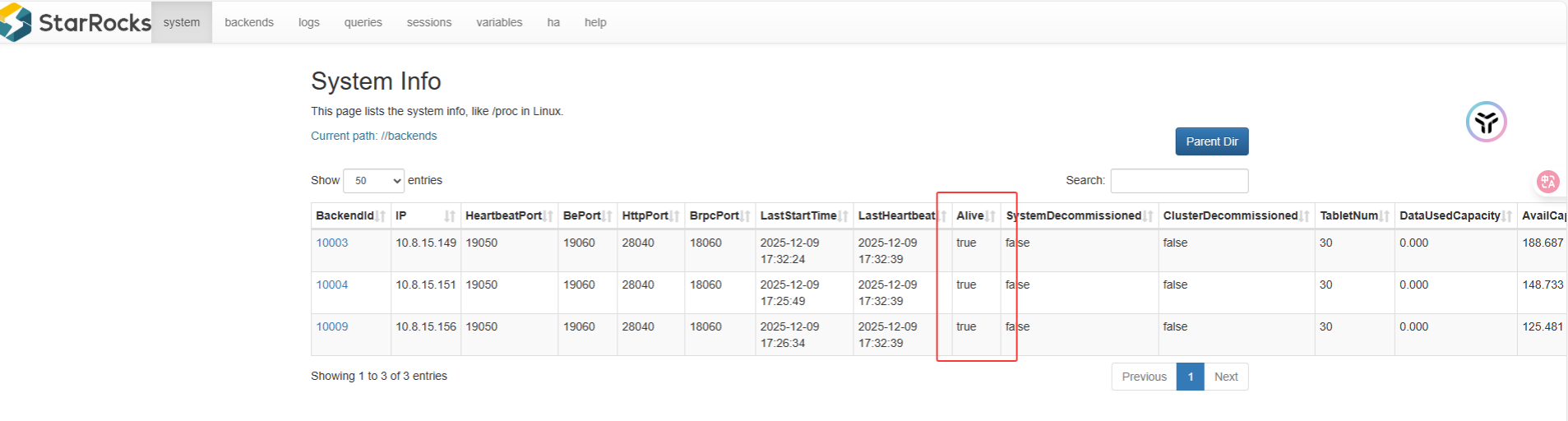
5.4 关闭 FE/BE 服务
# 启动 FE:
sh fe/bin/start_fe.sh --daemon
# 停止 FE:
sh fe/bin/stop_fe.sh
# 启动 BE:
sh be/bin/start_be.sh --daemon
#停止 BE:
sh be/bin/stop_be.sh6. Hadoop/Paimon 集成配置 (及遇到的兼容性问题)
为了让 StarRocks 读取 HDFS 上的数据,必须分发 Hadoop 配置文件。
6.1 分发配置文件
将 CDH 的核心配置复制到 StarRocks 的 conf 目录:
# 在 nd11, nd12, nd13 上分别执行
# FE
cp /home/bigdata/doris/conf/cdh_conf/core-site.xml /home/bigdata/starrocks-2.5/StarRocks-2.5.22/fe/conf/
cp /home/bigdata/doris/conf/cdh_conf/hive-site.xml /home/bigdata/starrocks-2.5/StarRocks-2.5.22/fe/conf/
cp /home/bigdata/doris/conf/cdh_conf/hdfs-site.xml /home/bigdata/starrocks-2.5/StarRocks-2.5.22/fe/conf/
# BE
cp /home/bigdata/doris/conf/cdh_conf/core-site.xml /home/bigdata/starrocks-2.5/StarRocks-2.5.22/be/conf/
cp /home/bigdata/doris/conf/cdh_conf/hive-site.xml /home/bigdata/starrocks-2.5/StarRocks-2.5.22/be/conf/
cp /home/bigdata/doris/conf/cdh_conf/hdfs-site.xml /home/bigdata/starrocks-2.5/StarRocks-2.5.22/be/conf/复制完成后重启所有 FE 和 BE。
6.2 尝试创建 Paimon Catalog (失败)
参考 Doris 的写法,尝试在 StarRocks 2.5 中创建 Catalog:
CREATE EXTERNAL CATALOG paimon_catalog PROPERTIES (
"type" = "paimon",
"paimon.catalog.type" = "filesystem",
"paimon.catalog.warehouse" = "hdfs://nd1:8020/user/hive/warehouse"
);结果报错:ERROR 1064 (HY000): [type : paimon] is not supported
结论:StarRocks 2.5 版本不支持原生的 Paimon Catalog。该功能在 StarRocks 3.1+ 版本才发布。 建议:如需使用 Paimon,建议升级至 StarRocks 3.2 LTS 版本。
7. 部署过程中的故障排查 (Troubleshooting)
故障 1:JDK 版本警告
现象:启动 FE 时提示 Tips: JAVA_UPDATE_VER is 181...。 原因:环境中使用的是 jdk1.8.0_181。StarRocks 2.5 默认开启 G1GC,而低于 1.8.0_192 的版本在 G1GC 上存在严重 Bug。 解决:
短期方案:若进程能启动,可暂时忽略(如日志所示)。
长期方案:在
fe.conf中配置JAVA_HOME指向更高版本的 JDK (如 JDK 11 或 JDK 8u202+)。
故障 2:nd13 节点脑裂 (Alive: false)
现象:
nd13 启动后,在
SHOW FRONTENDS中状态为Alive: false,ErrMsg: got exception。查看
fe.log发现报错:failed to read after retried 1 times! ... Got RestartRequiredException, will exit.日志中该节点曾短暂宣称自己是
LEADER。
原因: nd13 的元数据(BDBJE 日志)与当前集群 Leader (nd12) 不一致,发生了“脑裂”或数据损坏。通常是由于配置错误时多次重启或未指定 Helper 启动导致的。
解决方案:
停止进程:
kill掉 nd13 的 FE 进程。清空元数据:
rm -rf /home/bigdata/starrocks-2.5/meta/*(注意:仅删除 meta 目录下的内容,不要删目录本身)
重新加入:指定 Helper 强制同步 Leader 数据。
/home/bigdata/starrocks-2.5/StarRocks-2.5.22/fe/bin/start_fe.sh --helper 10.x.xx.151:19010 --daemon验证:再次查看
SHOW FRONTENDS,nd13 恢复正常 (Alive: true)。
8. 总结
本次部署成功实现了在 CDH 集群上 StarRocks 2.5.22 与 Doris 2.1.10 的共存。
端口管理:通过 "+10000" 策略及特殊处理 webserver 端口,完美避开了冲突。
稳定性:解决了 JDK 版本告警及 FE 脑裂问题。
局限性:确认 StarRocks 2.5 版本无法直接通过 External Catalog 支持 Paimon,后续计划升级至 StarRocks 3.x 以获得完整的湖仓分析能力。
9. 基础测试(增删改查)
将下述测试代码保存为starrocks2_test.py【python解释器:3.8.20、windows系统:11】
# -*- coding: utf-8 -*-
import pymysql
import random
import time
import logging
import functools
from sshtunnel import SSHTunnelForwarder
# ================= 配置信息 =================
# 1. SSH 连接信息 (保持不变,连接 nd11)
SSH_HOST = '10.x.xx.149' # StarRocks FE Leader IP (nd11)
SSH_PORT = 22
SSH_USER = 'xxxxx'
SSH_PASSWORD = 'xxxxxxxxxxxxxxxxx'
# 2. StarRocks 数据库信息
SR_LOCAL_HOST = '127.0.0.1' # 在服务器看来,StarRocks 是跑在本地的
SR_QUERY_PORT = 19030 # 【关键修改】StarRocks FE MySQL 端口
SR_DB_USER = 'root'
SR_DB_PWD = '' # 默认无密码
DB_NAME = 'python_perf_test_sr' # 改个名字区分 Doris
TABLE_NAME = 'student_scores_perf_sr'
LOG_FILE = 'starrocks2_test_report.log'
# ================= 日志与工具模块 (通用) =================
def setup_logger():
logger = logging.getLogger("StarRocksTester")
logger.setLevel(logging.INFO)
if logger.hasHandlers():
logger.handlers.clear()
file_handler = logging.FileHandler(LOG_FILE, mode='w', encoding='utf-8')
console_handler = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter)
console_handler.setFormatter(formatter)
logger.addHandler(file_handler)
logger.addHandler(console_handler)
return logger
logger = setup_logger()
def measure_time(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
logger.info(f"正在执行: [{func.__name__}] ...")
try:
result = func(*args, **kwargs)
duration = time.time() - start_time
logger.info(f"执行完成: [{func.__name__}] | 耗时: {duration:.4f} 秒")
return result
except Exception as e:
duration = time.time() - start_time
logger.error(f"执行失败: [{func.__name__}] | 耗时: {duration:.4f} 秒 | 错误: {e}")
raise e
return wrapper
# ================= 业务逻辑 =================
@measure_time
def init_db_and_table(cursor):
cursor.execute(f"CREATE DATABASE IF NOT EXISTS {DB_NAME}")
cursor.execute(f"USE {DB_NAME}")
# 【关键修改】StarRocks 建表语法
# 使用 Primary Key 模型 (适合频繁更新/删除)
# 注意: Primary Key 列必须是 NOT NULL
create_sql = f"""
CREATE TABLE IF NOT EXISTS {TABLE_NAME} (
id INT NOT NULL COMMENT "用户ID",
name VARCHAR(50) COMMENT "姓名",
age INT COMMENT "年龄",
score INT COMMENT "分数",
update_time DATETIME COMMENT "更新时间"
)
PRIMARY KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 3
PROPERTIES (
"replication_num" = "1"
);
"""
# 说明:
# 1. replication_num = 1: 保证即使之前 nd11 挂了,只要有一个节点活着也能建表成功。
# 如果是生产环境建议设为 3。
# 2. BUCKETS 3: 对应你的节点数。
cursor.execute(create_sql)
cursor.execute(f"TRUNCATE TABLE {TABLE_NAME}")
logger.info(f"数据库 {DB_NAME} 和表 {TABLE_NAME} 已初始化 (Primary Key 模型)")
@measure_time
def insert_data_batch(cursor, count=10):
data = []
for i in range(1, count + 1):
name = f"User_{i:03d}"
age = random.randint(18, 30)
score = random.randint(50, 100)
data.append((i, name, age, score))
# SQL 语法与 MySQL/Doris 兼容
sql = f"INSERT INTO {TABLE_NAME} (id, name, age, score, update_time) VALUES (%s, %s, %s, %s, NOW())"
cursor.executemany(sql, data)
logger.info(f"成功插入 {count} 条数据")
@measure_time
def query_and_log(cursor, stage_name):
# StarRocks 默认会对主键排序,但为了保险加上 ORDER BY
sql = f"SELECT * FROM {TABLE_NAME} ORDER BY id"
cursor.execute(sql)
results = cursor.fetchall()
logger.info(f"--- [{stage_name}] 当前总行数: {len(results)} ---")
if results:
# 只打印前3条
for row in results[:3]: logger.info(f"Row: {row}")
@measure_time
def update_random_data(cursor, update_count=3):
cursor.execute(f"SELECT id FROM {TABLE_NAME}")
all_ids = [row['id'] for row in cursor.fetchall()]
if not all_ids: return
target_ids = random.sample(all_ids, min(len(all_ids), update_count))
for uid in target_ids:
new_score = random.randint(95, 100)
# StarRocks Primary Key 模型支持高性能 UPDATE
sql = f"UPDATE {TABLE_NAME} SET score = %s, update_time = NOW() WHERE id = %s"
cursor.execute(sql, (new_score, uid))
logger.info(f" -> 更新 ID={uid}, New Score={new_score}")
@measure_time
def delete_random_data(cursor, delete_count=2):
cursor.execute(f"SELECT id FROM {TABLE_NAME}")
all_ids = [row['id'] for row in cursor.fetchall()]
if not all_ids: return
target_ids = random.sample(all_ids, min(len(all_ids), delete_count))
for uid in target_ids:
# StarRocks Primary Key 模型支持高性能 DELETE
sql = f"DELETE FROM {TABLE_NAME} WHERE id = %s"
cursor.execute(sql, (uid,))
logger.info(f" -> 删除 ID={uid}")
# ================= 主流程 =================
def main_process():
server = None
conn = None
try:
logger.info(">>> 1. 正在建立 SSH 隧道 ...")
# 建立 SSH 隧道
server = SSHTunnelForwarder(
(SSH_HOST, SSH_PORT),
ssh_username=SSH_USER,
ssh_password=SSH_PASSWORD,
# 【关键】映射远程的 19030 (StarRocks 端口) 到本地
remote_bind_address=(SR_LOCAL_HOST, SR_QUERY_PORT)
)
server.start()
logger.info(f">>> SSH 隧道建立成功! 映射 StarRocks 端口 {SR_QUERY_PORT} -> 本地 {server.local_bind_port}")
# 2. 连接数据库
logger.info(">>> 正在连接 StarRocks ...")
conn = pymysql.connect(
host='127.0.0.1', # 连接本机
port=server.local_bind_port, # 使用隧道端口
user=SR_DB_USER,
password=SR_DB_PWD,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor,
autocommit=True
)
cursor = conn.cursor()
# 3. 执行测试逻辑
init_db_and_table(cursor)
insert_data_batch(cursor, count=100)
time.sleep(1) # 等待数据可见(StarRocks 通常是准实时的)
query_and_log(cursor, "插入后")
update_random_data(cursor, update_count=5)
time.sleep(1)
query_and_log(cursor, "更新后")
delete_random_data(cursor, delete_count=5)
time.sleep(1)
query_and_log(cursor, "删除后")
logger.info(">>> StarRocks 基本功能测试全部通过 <<<")
except Exception as e:
logger.error(f"主流程发生错误: {e}")
finally:
# 清理资源
if conn:
conn.close()
logger.info("数据库连接已关闭")
if server:
server.stop()
logger.info("SSH 隧道已关闭")
if __name__ == "__main__":
main_process()对应的log文件内容如下:
2025-12-09 17:47:37,910 - INFO - >>> 1. 正在建立 SSH 隧道 ...
2025-12-09 17:47:38,440 - INFO - >>> SSH 隧道建立成功! 映射 StarRocks 端口 19030 -> 本地 60970
2025-12-09 17:47:38,440 - INFO - >>> 正在连接 StarRocks ...
2025-12-09 17:47:38,969 - INFO - 正在执行: [init_db_and_table] ...
2025-12-09 17:47:39,187 - INFO - 数据库 python_perf_test_sr 和表 student_scores_perf_sr 已初始化 (Primary Key 模型)
2025-12-09 17:47:39,187 - INFO - 执行完成: [init_db_and_table] | 耗时: 0.2184 秒
2025-12-09 17:47:39,188 - INFO - 正在执行: [insert_data_batch] ...
2025-12-09 17:47:49,567 - INFO - 成功插入 100 条数据
2025-12-09 17:47:49,567 - INFO - 执行完成: [insert_data_batch] | 耗时: 10.3799 秒
2025-12-09 17:47:50,568 - INFO - 正在执行: [query_and_log] ...
2025-12-09 17:47:53,689 - INFO - --- [插入后] 当前总行数: 100 ---
2025-12-09 17:47:53,689 - INFO - Row: {'id': 1, 'name': 'User_001', 'age': 24, 'score': 72, 'update_time': datetime.datetime(2025, 12, 9, 17, 47, 39)}
2025-12-09 17:47:53,689 - INFO - Row: {'id': 2, 'name': 'User_002', 'age': 28, 'score': 87, 'update_time': datetime.datetime(2025, 12, 9, 17, 47, 43)}
2025-12-09 17:47:53,690 - INFO - Row: {'id': 3, 'name': 'User_003', 'age': 30, 'score': 73, 'update_time': datetime.datetime(2025, 12, 9, 17, 47, 43)}
2025-12-09 17:47:53,690 - INFO - 执行完成: [query_and_log] | 耗时: 3.1219 秒
2025-12-09 17:47:53,690 - INFO - 正在执行: [update_random_data] ...
2025-12-09 17:47:53,897 - INFO - -> 更新 ID=22, New Score=97
2025-12-09 17:47:53,970 - INFO - -> 更新 ID=69, New Score=99
2025-12-09 17:47:54,033 - INFO - -> 更新 ID=52, New Score=95
2025-12-09 17:47:54,104 - INFO - -> 更新 ID=64, New Score=98
2025-12-09 17:47:54,168 - INFO - -> 更新 ID=9, New Score=96
2025-12-09 17:47:54,168 - INFO - 执行完成: [update_random_data] | 耗时: 0.4779 秒
2025-12-09 17:47:55,168 - INFO - 正在执行: [query_and_log] ...
2025-12-09 17:47:55,184 - INFO - --- [更新后] 当前总行数: 100 ---
2025-12-09 17:47:55,185 - INFO - Row: {'id': 1, 'name': 'User_001', 'age': 24, 'score': 72, 'update_time': datetime.datetime(2025, 12, 9, 17, 47, 39)}
2025-12-09 17:47:55,185 - INFO - Row: {'id': 2, 'name': 'User_002', 'age': 28, 'score': 87, 'update_time': datetime.datetime(2025, 12, 9, 17, 47, 43)}
2025-12-09 17:47:55,185 - INFO - Row: {'id': 3, 'name': 'User_003', 'age': 30, 'score': 73, 'update_time': datetime.datetime(2025, 12, 9, 17, 47, 43)}
2025-12-09 17:47:55,185 - INFO - 执行完成: [query_and_log] | 耗时: 0.0168 秒
2025-12-09 17:47:55,185 - INFO - 正在执行: [delete_random_data] ...
2025-12-09 17:47:55,270 - INFO - -> 删除 ID=44
2025-12-09 17:47:55,333 - INFO - -> 删除 ID=24
2025-12-09 17:47:55,396 - INFO - -> 删除 ID=46
2025-12-09 17:47:55,466 - INFO - -> 删除 ID=53
2025-12-09 17:47:55,536 - INFO - -> 删除 ID=90
2025-12-09 17:47:55,537 - INFO - 执行完成: [delete_random_data] | 耗时: 0.3513 秒
2025-12-09 17:47:56,537 - INFO - 正在执行: [query_and_log] ...
2025-12-09 17:47:56,552 - INFO - --- [删除后] 当前总行数: 95 ---
2025-12-09 17:47:56,552 - INFO - Row: {'id': 1, 'name': 'User_001', 'age': 24, 'score': 72, 'update_time': datetime.datetime(2025, 12, 9, 17, 47, 39)}
2025-12-09 17:47:56,552 - INFO - Row: {'id': 2, 'name': 'User_002', 'age': 28, 'score': 87, 'update_time': datetime.datetime(2025, 12, 9, 17, 47, 43)}
2025-12-09 17:47:56,553 - INFO - Row: {'id': 3, 'name': 'User_003', 'age': 30, 'score': 73, 'update_time': datetime.datetime(2025, 12, 9, 17, 47, 43)}
2025-12-09 17:47:56,553 - INFO - 执行完成: [query_and_log] | 耗时: 0.0154 秒
2025-12-09 17:47:56,553 - INFO - >>> StarRocks 基本功能测试全部通过 <<<
2025-12-09 17:47:56,553 - INFO - 数据库连接已关闭
2025-12-09 17:47:56,617 - INFO - SSH 隧道已关闭去nd11执行下述语句进行查看:
mysql -h 10.x.xx.149 -P 19030 -u rootshow databases;
use python_perf_test_sr;
show tables;
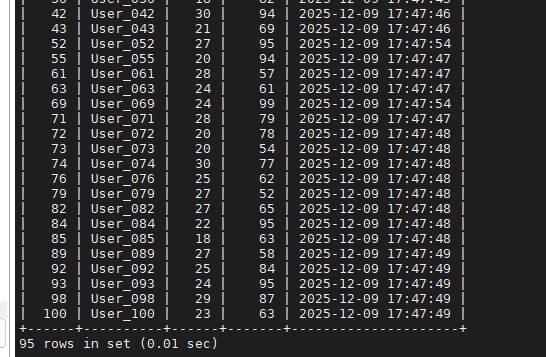
select * from student_scores_perf_sr;7.1 插入数据
这里展示部分数据,可以看出插入了100条测试数据:
7.2 更新数据
控制台打印结果如下:
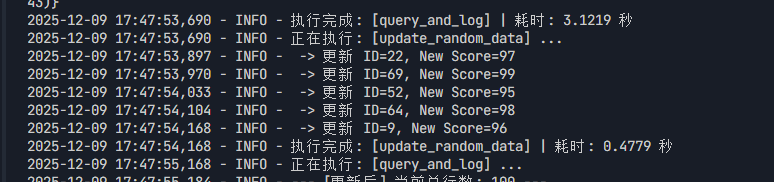
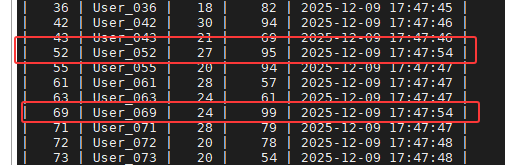
终端验证,部分数据展示如下:

7.3 删除数据
控制台打印结果如下:

终端验证,部分数据展示如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号