

python手写数字识别系统 CNN卷积神经网络算法 深度学习、pytorch 手写数字识别(建议收藏)✅ - 指南
2025-12-20 18:29 tlnshuju 阅读(0) 评论(0) 收藏 举报博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,任务以及论文编写等相关障碍都允许给我留言咨询,希望协助同学们顺利毕业 。
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、方案介绍
技术栈:
python语言、深度学习、pytorch、CNN卷积神经网络算法、手写数字识别、训练集、测试集
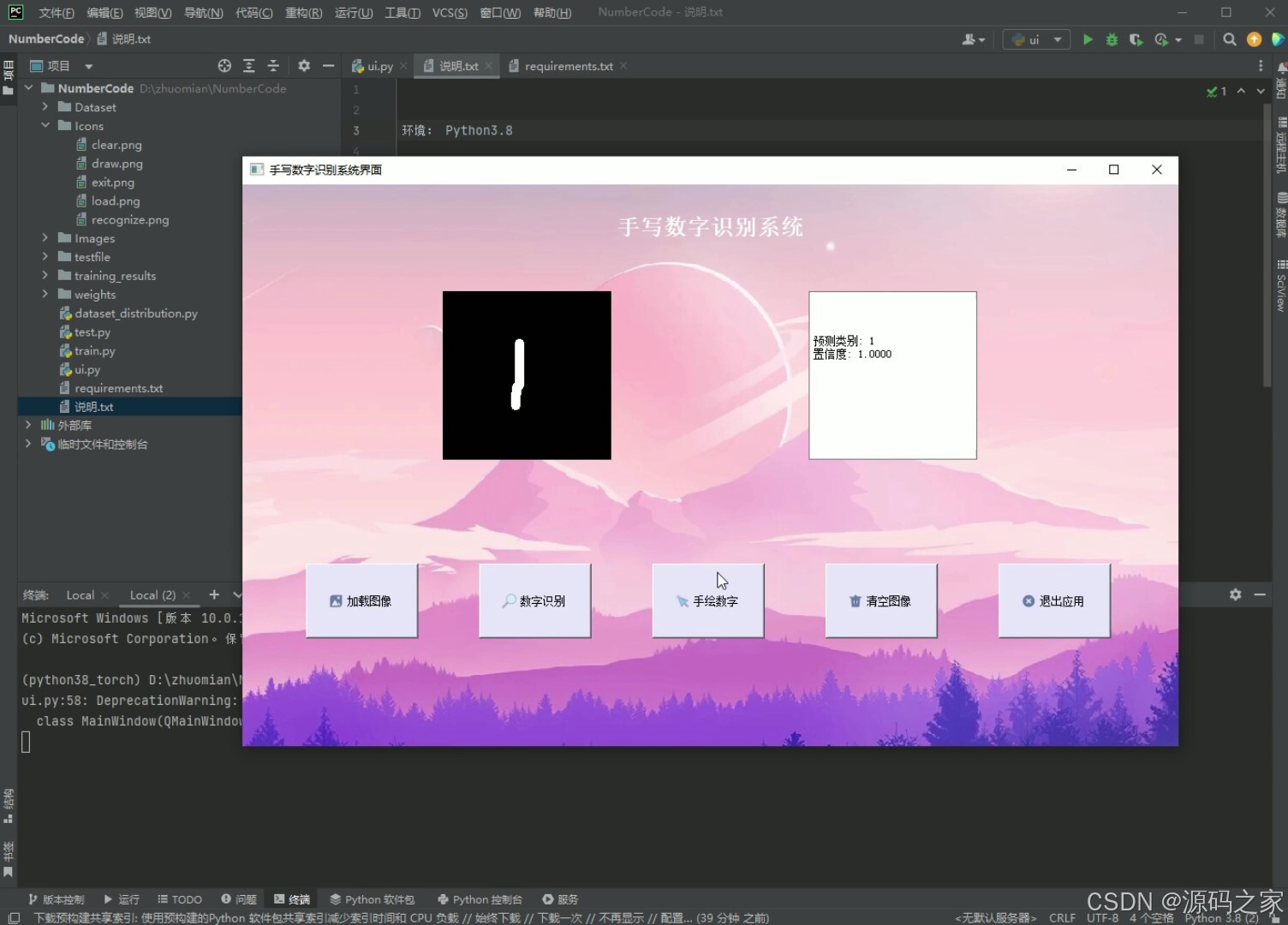
功能:加载图片、数字识别、手绘数字、清空图像、退出
2、任务界面
(1)手写数字识别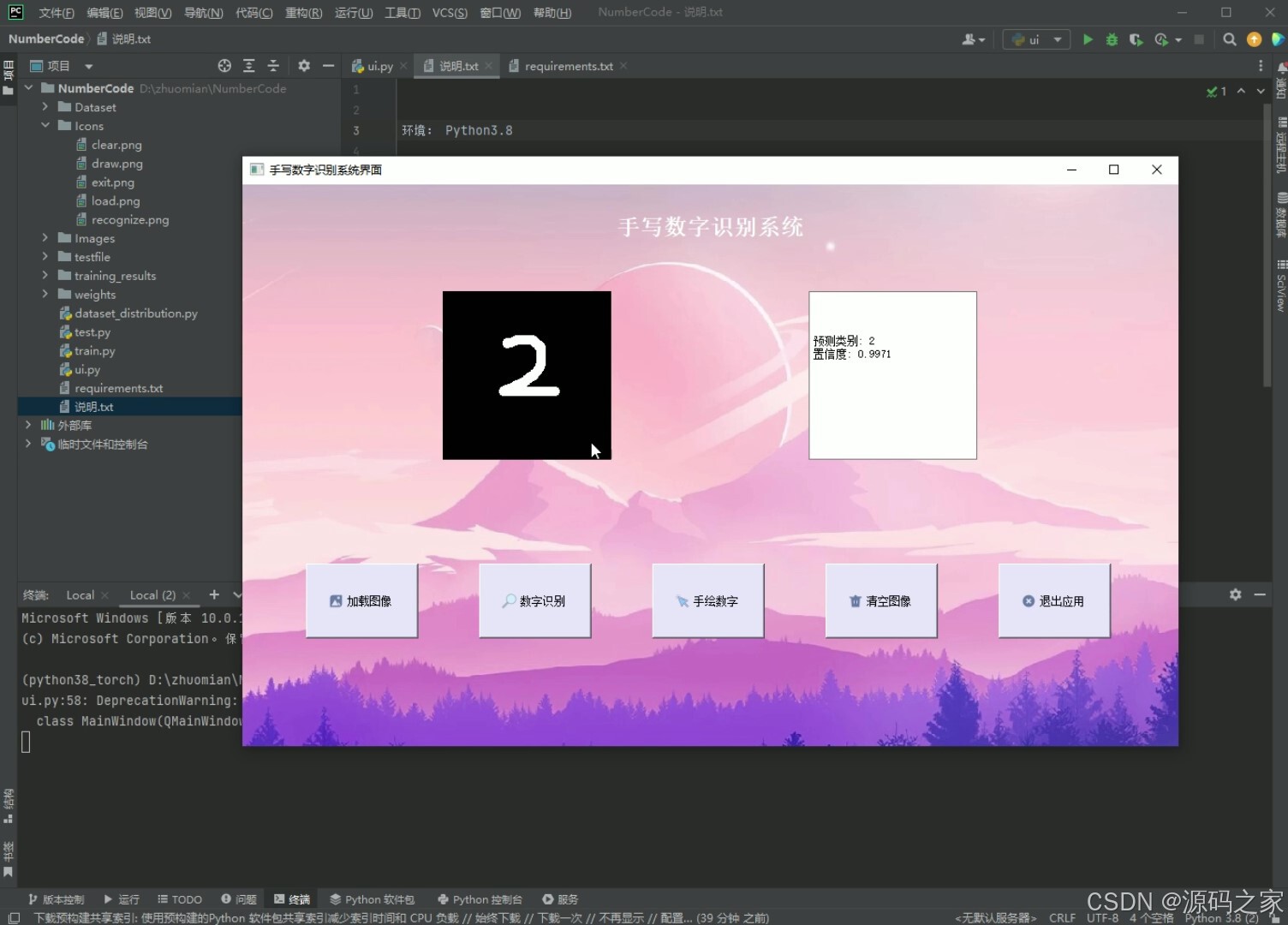
(2)手写数字识别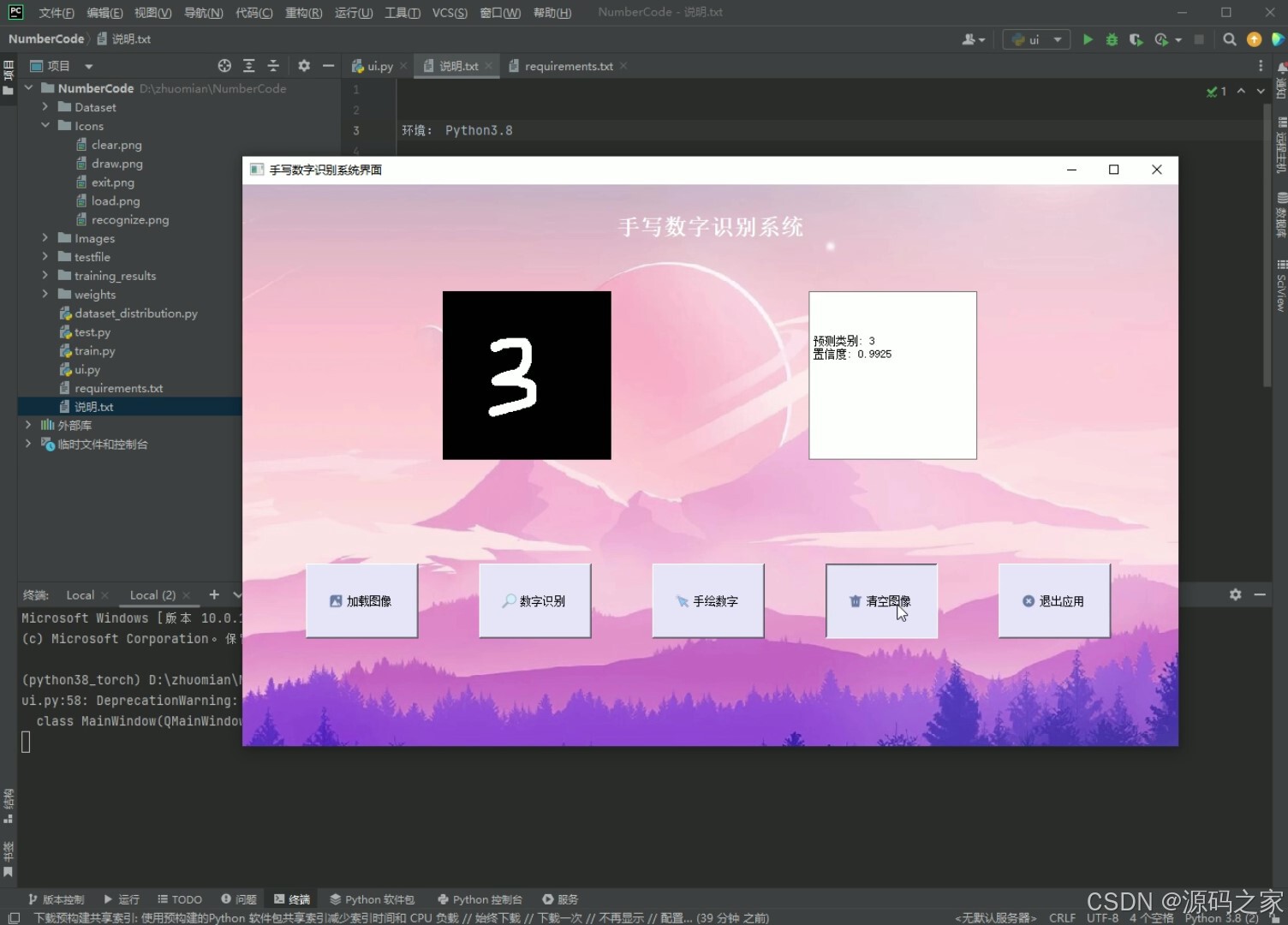
(3)手写数字识别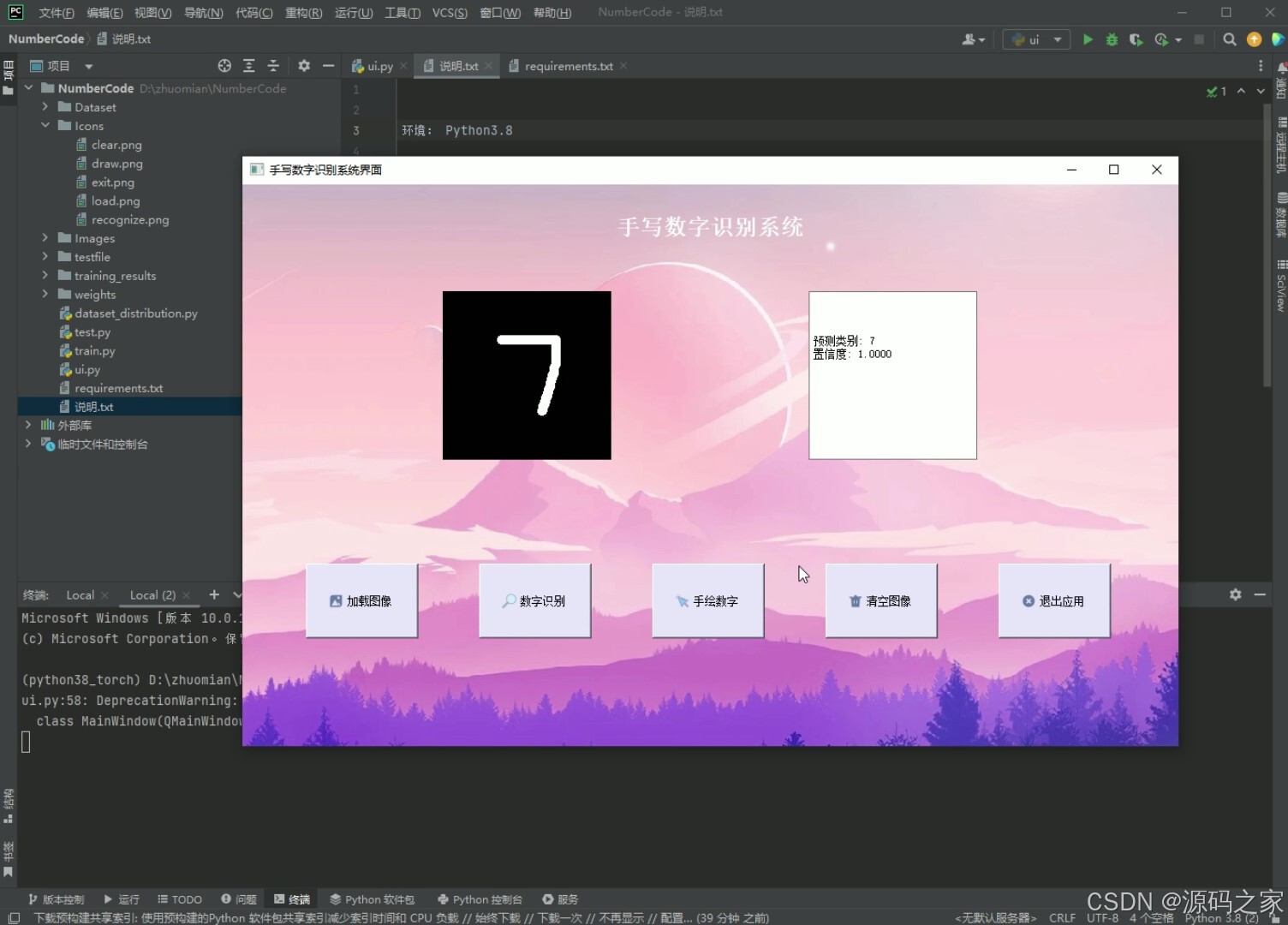
(4)上传图片数字识别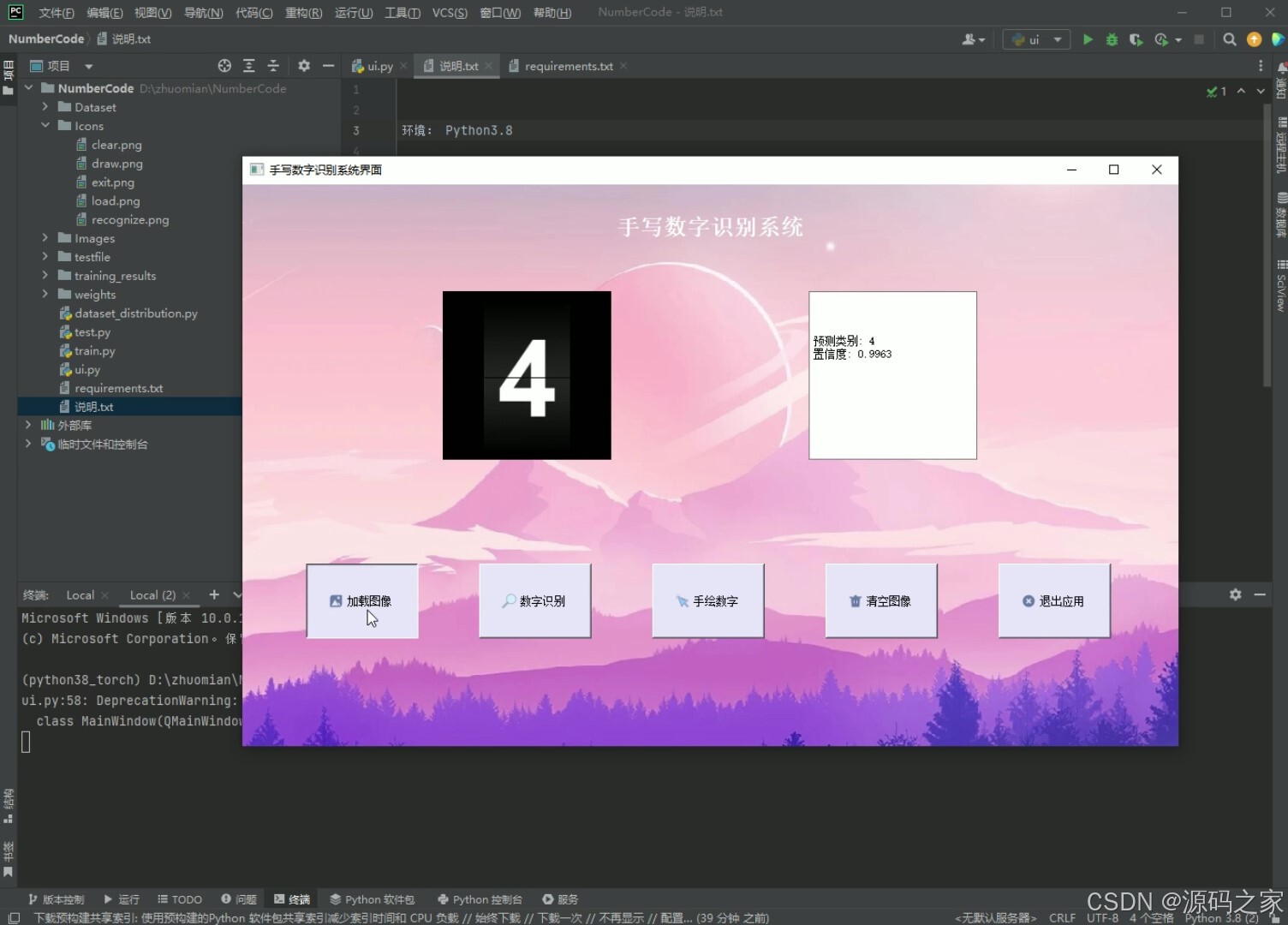
(5)手写数字识别
3、项目说明
摘要
随着人工智能和机器学习技术的快速发展,计算机视觉在各个领域的应用越来越广泛。手写数字识别作为计算机视觉的一个经典问题,具有关键的研究价值和实际应用前景。传统的手写数字识别方法依赖于复杂的特征提取和分类算法,而深度学习科技的出现极大地简化了这一过程,并显著提高了识别精度。因此,开发一个高效、准确的手写数字识别系统具有重要的现实意义。
一个基于深度学习技术的应用程序,旨在通过计算机视觉技术自动识别手写数字。该系统可以广泛应用于各种场景,如邮政编码识别、银行支票处理、教育评估等。就是手写数字识别系统
在技术完成方面,本项目使用 MNIST 数据集作为训练和测试数据。数据预处理包括灰度转换、随机旋转、随机水平翻转和随机裁剪等操作,以增加训练数据的多样性,提高模型的泛化能力。模型构建采用了卷积神经网络(CNN),并通过 PyTorch 框架实现。模型训练过程中,通过设置合理的超参数和优化算法,确保模型能够高效收敛。模型评估通过绘制损失和准确率曲线图、混淆矩阵和分类报告表,全面评估模型的性能。
最终,本项目成功构建了一个高效且准确的手写数字识别系统,并凭借用户友好的图形界面提供了多种机制,包括加载图像、手绘数字、数字识别、清空图像和退出应用等,确保系统的稳定性和可靠性。。
关键字:图像识别;卷积神经网络CNN;手写数字识别;
经过本次手写数字识别项目的个人课程设计作业,我在技术、挑战应对、项目管理和自我提升等多个方面都取得了显著的进步。构建和训练卷积神经网络(CNN)的过程不仅加深了我对深度学习模型设计和优化手段的理解,同时也让我掌握了多项关键技术,这些技术对于提高模型的鲁棒性和泛化能力至关重要。
起初,在技术层面,我深入了解了卷积神经网络的工作原理及其在图像识别任务中的应用。通过本工程的实践,我熟练掌握了如何使用 PyTorch 框架构建 CNN 模型,包括定义模型结构、设置超参数、编写训练循环等核心步骤。此外,我还学习了数据预处理与增强工艺,如灰度转换、随机旋转、随机水平翻转、随机裁剪等,这些方式能有用增加训练数据的多样性,协助模型更好地适应不同的输入情况,提高其在实际应用中的表现。
在问题解决方面,面对模型在某些类别上的性能不佳的问题,我学会了运用混淆矩阵和分类报告表等应用进行细致的性能评估,并根据评估结果采取相应的措施进行模型优化。
此外,本项目的实施过程中,我还学会了如何使用 Anaconda 创建和管理虚拟环境,安装和配置所需的库和软件,以及如何在 PyCharm 中导入和调试代码。这些技能不仅对完成当前项目有帮助,也为我未来的学习和研究提供了便利。
值得一提的是,本次工程还让我深刻意识到了持续学习的价值。随着技术的不断发展,新的算法和工具层出不穷。只有保持好奇心,积极学习最新的知识和手艺,才能在这个敏捷变化的领域中保持竞争力。为此,我利用业余时间阅读了大量的相关文献,参加了多个在线课程,并积极参与社区交流,不断提升自己的专业素养。
总的来说,本次手写数字识别项目的顺利完成,不仅是我个人科技能力的一次重要提升,更是我职业生涯中的一次宝贵历练。它不仅锻炼了我的编程技能和问题解决能力,更重要的是培养了我的项目管理和自我提升能力。在未来的工作和学习中,我将继续发扬这些优点,不断挑战自我,追求更高的成就。我相信,这段经历将成为我职业道路上的一块坚实的基石,为我未来的成长和发展提供强有力的支持。
4、核心代码
1.# 训练轮数
2.num_epochs = 30
3.
4.# 定义损失函数和优化器
5.criterion = nn.CrossEntropyLoss()
6.optimizer = optim.Adam(model.parameters(), lr=0.001)
7.
8.# 初始化训练记录
9.train_losses = []
10.train_accuracies = []
11.test_losses = []
12.test_accuracies = []
1. with tqdm(total=len(train_loader), desc=f'Epoch {epoch+1}/{num_epochs}', unit='batch') as pbar:
2. for images, labels in train_loader:
3. images, labels = images.to(device), labels.to(device)
4. optimizer.zero_grad()
5. outputs = model(images)
6. loss = criterion(outputs, labels)
7. loss.backward()
8. optimizer.step()
9.
10. running_loss += loss.item()
11. _, predicted = torch.max(outputs.data, 1)
12. total += labels.size(0)
13. correct += (predicted == labels).sum().item()
14.
15. pbar.set_postfix({
16. 'Train Loss': running_loss / (pbar.n + 1),
17. 'Train Acc': correct / total
18. })
19. pbar.update(1)
20.
21.train_loss = running_loss / len(train_loader)
22.train_acc = correct / total
23.train_losses.append(train_loss)
24.train_accuracies.append(train_acc)
3.2.3 模型保存
在训练完成后,可以将模型的状态保存到文件中,以便后续使用或继续训练。
1. # 保存最佳模型
2. if epoch == 0 or test_acc > max(test_accuracies[:-1]):
3. torch.save(model.state_dict(), './weights/new_best_model.pth')
4.
5.# 保存最终的模型
6.torch.save(model.state_dict(), './weights/final_model.pth')✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多任务可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!✌
5、源码获取方式
由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。
点赞、收藏、关注,不迷路,下方查看获取联系方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号