

实用指南:AI Agent 实战指南:LangChain/LangGraph 框架深度解析与项目落地
2025-12-15 16:11 tlnshuju 阅读(149) 评论(0) 收藏 举报
前言:为什么 AI Agent 是下一代智能应用的核心?
最近一年,AI Agent 从概念走向落地,成为继大语言模型(LLM)之后最热门的技术方向。简单来说,AI Agent 是具备自主决策、工具使用、环境交互能力的智能体,能像人类一样拆解复杂任务、调用资源、持续迭代。
而 LangChain 与 LangGraph 作为目前最成熟的 Agent 开发框架,已成为开发者的首选工具。本文将从核心概念出发,通过实战案例手把手教你掌握 Agent 开发,涵盖内置 Agent 调用、自定义工具、向量数据库集成等关键技能,最后通过一个完整项目案例展示如何构建生产级 AI Agent。
一、LangChain 核心概念:6 大组件搭建 Agent 基础
LangChain 之所以成为 Agent 开发的事实标准,源于其模块化的设计理念。掌握以下 6 大核心组件,就能理解 Agent 的工作原理:
1. Models:AI Agent 的 “大脑”
Models 是 Agent 的核心算力来源,主要包括:
- LLM(大语言模型):如 GPT-4、Claude、LLaMA 等,负责自然语言理解与决策
- 聊天模型(Chat Models):封装了对话格式的 LLM(如 OpenAI 的 ChatCompletion)
- 嵌入模型(Embedding Models):将文本转为向量,用于语义检索(如 OpenAI Embedding)
代码示例:初始化 OpenAI 模型
from langchain_openai import OpenAI, ChatOpenAI
# 初始化文本生成模型
llm = OpenAI(api_key="your_key", temperature=0) # temperature=0 表示确定性输出
# 初始化聊天模型
chat_model = ChatOpenAI(api_key="your_key", model_name="gpt-3.5-turbo")2. Prompts:引导 Agent 思考的 “指令”
Prompts 是与模型交互的输入模板,决定了 Agent 的行为方式。LangChain 提供了 PromptTemplate 工具简化提示词管理:
代码示例:定义提示词模板
from langchain.prompts import PromptTemplate
# 简单提示词模板
template = "请将以下文本总结为一句话:{text}"
prompt = PromptTemplate(input_variables=["text"], template=template)
# 填充变量并生成最终提示词
formatted_prompt = prompt.format(text="LangChain 是一个用于构建 AI Agent 的框架...")对于复杂场景(如 Agent 思考过程),可使用 ChatPromptTemplate 定义多轮对话模板。
3. Chains:串联组件的 “流水线”
Chains 用于将多个组件(模型、提示词、工具等)按逻辑串联。最基础的 LLMChain 可将提示词与模型绑定:
代码示例:使用 LLMChain 串联组件
from langchain.chains import LLMChain
# 绑定提示词与模型
chain = LLMChain(llm=llm, prompt=prompt)
# 执行链条
result = chain.run(text="LangChain 是一个用于构建 AI Agent 的框架...")
print(result) # 输出:LangChain 是构建 AI Agent 的框架。复杂场景可使用 SequentialChain(顺序执行)或 RouterChain(动态选择链条)。
4. Agents:具备决策能力的 “执行者”
Agents 是 LangChain 的核心,能根据目标自主决策:是否调用工具、调用哪些工具、如何处理结果。其核心逻辑是 “思考 - 行动 - 观察” 循环(Thought-Action-Observation)。
关键概念:
- Agent Type:Agent 的决策模式(如 ZERO_SHOT_REACT、OPENAI_FUNCTIONS)
- Tools:Agent 可调用的外部能力(如搜索、数据库查询)
- Executor:执行 Agent 决策的引擎
5. Tools:扩展 Agent 能力的 “双手”
Tools 是 Agent 与外部世界交互的接口,包括:
- 内置工具:如
SerpAPIWrapper(搜索)、PythonREPLTool(执行代码)- 自定义工具:根据业务需求开发的能力(如查询订单、操作数据库)
工具定义需包含:名称、描述、参数说明(帮助 Agent 判断何时调用)。
6. Memory:Agent 的 “记忆系统”
Memory 让 Agent 能记住历史交互,分为:
- 短期记忆:如
ConversationBufferMemory(存储完整对话)- 长期记忆:结合向量数据库存储结构化知识(如用户信息、产品数据)
组件关系图
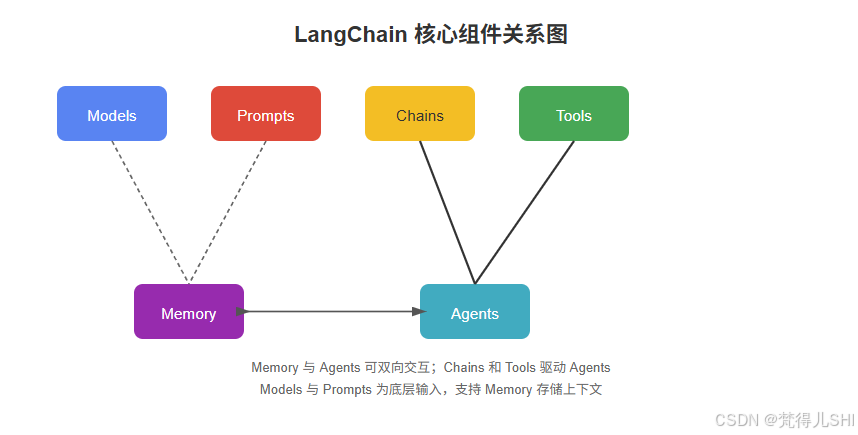
总结:Models 提供算力,Prompts 定义任务,Chains 串联流程,Tools 扩展能力,Memory 保留上下文,最终通过 Agents 实现自主决策 —— 这就是 LangChain 构建智能体的核心逻辑。
二、Agent 实战:从内置类型到自定义工具
1. 快速上手:使用 LangChain 内置 Agent
LangChain 提供了多种开箱即用的 Agent 类型,最常用的是 ZERO_SHOT_REACT_DESCRIPTION(零样本推理)和 OPENAI_FUNCTIONS(函数调用)。
案例:用 ZERO_SHOT_REACT_DESCRIPTION 实现天气查询
步骤 1:安装依赖
pip install langchain langchain-openai python-dotenv serpapi步骤 2:配置环境变量创建 .env 文件:
OPENAI_API_KEY=your_openai_key
SERPAPI_API_KEY=your_serpapi_key # 用于搜索工具步骤 3:初始化工具与 Agent
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
from langchain_openai import OpenAI
from langchain.utilities import SerpAPIWrapper
from dotenv import load_dotenv
import os
# 加载环境变量
load_dotenv()
# 初始化搜索工具
search = SerpAPIWrapper()
tools = [
Tool(
name="Search",
func=search.run,
description="当需要获取实时信息(如天气、新闻、股票价格)时使用"
)
]
# 初始化 LLM
llm = OpenAI(temperature=0)
# 初始化 Agent(ZERO_SHOT_REACT 类型)
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True # 输出思考过程
)步骤 4:运行 Agent
# 执行任务:查询北京明天的天气
result = agent.run("北京明天的天气如何?")
print(result)输出解析(verbose=True 时可见):
> Entering new AgentExecutor chain...
我需要查询北京明天的天气,这是实时信息,应该用Search工具。
Action: Search
Action Input: 北京明天天气
Observation: 北京明天(11月8日)晴,气温-2~8℃,西北风3-4级。
Thought: 已获取天气信息,无需进一步操作。
Final Answer: 北京明天(11月8日)晴,气温-2~8℃,西北风3-4级。
> Finished chain.可以看到,Agent 完整执行了 “思考→调用工具→获取结果→整理回答” 的流程。
案例:用 OPENAI_FUNCTIONS 实现结构化输出
OPENAI_FUNCTIONS 类型依赖 LLM 的函数调用能力(如 GPT-3.5-turbo/4),适合需要结构化结果的场景:
from langchain.agents import AgentType, initialize_agent
from langchain_openai import ChatOpenAI
from langchain.tools import tool
# 定义工具(用 @tool 装饰器自动生成描述)
@tool
def get_weather(city: str, date: str) -> str:
"""获取指定城市和日期的天气"""
# 实际项目中可对接真实天气API
return f"{city}{date}晴,气温5~15℃"
# 初始化聊天模型(必须支持函数调用)
chat_model = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# 初始化 Agent(OPENAI_FUNCTIONS 类型)
agent = initialize_agent(
[get_weather],
chat_model,
agent=AgentType.OPENAI_FUNCTIONS,
verbose=True
)
# 运行:获取上海后天的天气
result = agent.run("上海后天的天气怎么样?")优势:工具调用格式更规范(通过 JSON 传递参数),适合生产环境。
2. 进阶:自定义 Tools 扩展 Agent 能力
内置工具无法满足业务需求时,可自定义工具。核心是明确工具的功能描述(帮助 Agent 判断何时调用)和参数格式。
案例:自定义 “订单查询” 工具
步骤 1:定义工具类
from langchain.tools import BaseTool
from pydantic import BaseModel, Field
from typing import Optional, Type
# 定义工具输入参数模型
class OrderQueryInput(BaseModel):
order_id: str = Field(description="订单编号,格式为ORD+数字,如ORD123456")
# 自定义工具
class OrderQueryTool(BaseTool):
name = "OrderQuery"
description = "用于查询订单状态,需要传入订单编号"
args_schema: Type[BaseModel] = OrderQueryInput # 绑定输入参数模型
def _run(self, order_id: str) -> str:
# 模拟查询数据库
if order_id.startswith("ORD") and len(order_id) == 9:
return f"订单{order_id}状态:已发货,预计3天后送达"
else:
return "无效的订单编号,请检查格式"
def _arun(self, order_id: str):
# 异步实现(可选)
raise NotImplementedError("暂不支持异步查询")步骤 2:集成到 Agent
# 初始化工具和 Agent
order_tool = OrderQueryTool()
agent = initialize_agent(
[order_tool],
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 测试:查询订单
result = agent.run("帮我查一下订单ORD123456的状态")关键点:
- 工具描述要精确(如 “需要传入订单编号”),避免 Agent 误用
- 通过
args_schema定义参数格式,确保输入规范- 实现
_run方法处理核心逻辑,_arun可选(异步场景)
3. 高级:集成向量数据库实现长期记忆
Agent 仅靠对话历史(短期记忆)无法处理大规模知识,需结合向量数据库存储长期记忆。常用向量库有 Chroma(轻量本地库)、Pinecone(云服务)。
案例:用 Chroma 存储产品知识,让 Agent 回答用户咨询
步骤 1:安装依赖
pip install chromadb langchain-community步骤 2:初始化向量库并加载数据
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
# 1. 加载产品知识文档(示例:产品说明书)
loader = TextLoader("product_info.txt") # 内容:"产品A支持30天无理由退货,保修期1年..."
documents = loader.load()
# 2. 分割文档(避免文本过长)
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# 3. 初始化向量库并存储文档
embeddings = OpenAIEmbeddings() # 用OpenAI Embedding生成向量
db = Chroma.from_documents(docs, embeddings, persist_directory="./chroma_db")
db.persist() # 持久化存储步骤 3:创建 “知识检索” 工具
@tool
def retrieve_knowledge(query: str) -> str:
"""检索产品知识,回答用户关于产品的问题(如退货政策、保修期)"""
# 从向量库中查询相关文档
docs = db.similarity_search(query)
return "\n".join([doc.page_content for doc in docs])步骤 4:集成工具到 Agent
# 组合工具:知识检索 + 搜索(可选)
tools = [retrieve_knowledge, search]
# 初始化 Agent
agent = initialize_agent(
tools,
chat_model,
agent=AgentType.OPENAI_FUNCTIONS,
verbose=True
)
# 测试:查询产品退货政策
result = agent.run("产品A支持多久无理由退货?")效果:Agent 会自动调用 retrieve_knowledge 工具,从向量库中获取产品信息并回答,无需硬编码知识。
三、LangGraph:构建更稳定的 Agent 工作流
LangGraph 是 LangChain 团队推出的新一代框架,基于 “状态机” 设计,更适合构建复杂、可追溯的 Agent 工作流。其核心优势是:
- 明确的状态管理(State)
- 可控的节点流转(Nodes)
- 支持循环与分支逻辑
案例:用 LangGraph 实现 “多轮分析” Agent
场景:让 Agent 分析用户问题,若需要补充信息则追问,否则生成答案。
步骤 1:安装 LangGraph
pip install langgraph步骤 2:定义状态与节点
from langgraph.graph import Graph, StateGraph
from pydantic import BaseModel, Field
from typing import List, Optional
# 1. 定义状态(保存对话历史、当前问题、是否需要追问)
class State(BaseModel):
messages: List[str] = Field(default_factory=list)
need_clarify: bool = False # 是否需要追问
final_answer: Optional[str] = None
# 2. 定义节点:分析问题
def analyze_node(state: State) -> State:
last_msg = state.messages[-1]
# 调用 LLM 判断是否需要追问(简化逻辑,实际需用 prompt 引导)
if "价格" in last_msg and "产品" not in last_msg:
state.need_clarify = True
state.messages.append("请问你想了解哪个产品的价格?")
else:
state.need_clarify = False
state.final_answer = f"已收到您的问题:{last_msg},正在处理..."
return state
# 3. 定义节点:等待用户输入(仅示例,实际为外部交互)
def user_input_node(state: State) -> State:
user_input = input("请输入:") # 模拟用户输入
state.messages.append(user_input)
return state
# 4. 定义条件分支:是否需要追问
def should_continue(state: State) -> str:
if state.need_clarify:
return "user_input" # 流转到用户输入节点
else:
return "end" # 结束流程步骤 3:构建并运行工作流
# 初始化状态机
workflow = StateGraph(State)
# 添加节点
workflow.add_node("analyze", analyze_node) # 分析节点
workflow.add_node("user_input", user_input_node) # 用户输入节点
# 定义流转逻辑
workflow.set_entry_point("analyze") # 入口节点
workflow.add_edge("user_input", "analyze") # 用户输入后回到分析节点
workflow.add_conditional_edges(
"analyze",
should_continue,
{
"user_input": "user_input",
"end": "end"
}
)
# 编译并运行
app = workflow.compile()
initial_state = State(messages=["这个产品的价格是多少?"])
result = app.invoke(initial_state)
print(result.final_answer)优势:相比 LangChain 内置 Agent,LangGraph 的工作流更清晰,可通过状态机可视化工具查看节点流转,便于调试复杂逻辑。
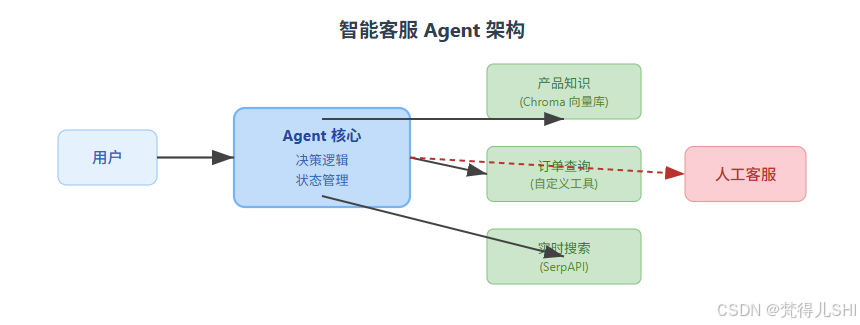
四、项目实战:构建 “智能客服 Agent”
结合上述知识,我们来构建一个完整的智能客服 Agent,具备以下能力:
- 回答产品知识(基于向量库)
- 查询订单状态(自定义工具)
- 调用搜索获取实时信息(如活动公告)
- 无法回答时转接人工
1. 架构设计
2. 核心代码实现
# 整合工具
tools = [retrieve_knowledge, OrderQueryTool(), search]
# 初始化 Agent(使用 LangGraph 确保流程可控)
class SupportAgent:
def __init__(self):
self.agent = initialize_agent(
tools,
ChatOpenAI(model_name="gpt-4", temperature=0),
agent=AgentType.OPENAI_FUNCTIONS,
verbose=True
)
self.escalate_keywords = ["人工", "转接", "投诉"] # 需要转接人工的关键词
def handle_query(self, user_query: str) -> str:
# 检测是否需要转接人工
if any(keyword in user_query for keyword in self.escalate_keywords):
return "已为您转接人工客服,正在接入..."
# 正常处理
try:
return self.agent.run(user_query)
except Exception as e:
return f"处理失败:{str(e)},请稍后再试"
# 测试
if __name__ == "__main__":
agent = SupportAgent()
print(agent.handle_query("产品A的保修期是多久?")) # 调用知识检索
print(agent.handle_query("查一下订单ORD123456")) # 调用订单工具
print(agent.handle_query("转人工")) # 转接人工五、总结与扩展
本文从 LangChain 核心组件出发,通过实战案例讲解了 Agent 开发的关键技能:
- 内置 Agent 类型的选择(ZERO_SHOT_REACT 适合快速验证,OPENAI_FUNCTIONS 适合生产)
- 自定义工具的开发要点(清晰描述、规范参数)
- 向量数据库集成(实现长期记忆)
- LangGraph 工作流(复杂场景的最佳选择)
进阶方向:
- 多 Agent 协作(用 LangGraph 实现分工)
- 工具权限控制(限制 Agent 调用敏感工具)
- 错误处理与重试机制(提升稳定性)
- 结合 RAG 优化知识检索精度
AI Agent 正处于快速发展期,掌握 LangChain/LangGraph 等工具,能让你在智能应用开发中抢占先机。动手实践吧 —— 最好的学习方式就是用代码实现一个属于自己的 Agent!
互动讨论:你在开发 Agent 时遇到过哪些坑?有哪些实用技巧?欢迎在评论区分享~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号