

【C语言进阶】字符函数与字符串函数1-万字解说 - 教程
2025-12-09 08:16 tlnshuju 阅读(4) 评论(0) 收藏 举报长风破浪会会有时,直挂云帆济沧海,今天哟又是适合学习的一天~
我们在编写C语言代码的时候,经常要处理有关字符和字符串的问题,那么本篇文章就来总结一下我们常用到的字符和字符串函数吧~
目录
一、字符分类函数
在C语言的库中,给我们创建好了这些字符分类函数,如下图所示:

想要了解更多详细内容的小伙伴可以通过这个<cctype> (ctype.h) - C++ Reference链接去访问,由于要素过多,同时出场率没有接下来的几位出场律这么高,我就不一一赘述了。
二、字符转换函数
字符转换函数,顾名思义,就是将字符的一个形态转换到另外一个形态,C语言给我们提供了两种字符的转换函数:
int tolower(int c);
int toupper(int c);看名字就是知道,这两个函数,一个是将大写转换为小写,一个是将小写转换成大写,我们可以通过下面这一段代码来体会一下他们的效果:
#include
#include
#include
int main()
{
char arr1[] = "Hello,WORld!";
char* pa = arr1;
while (*pa != '\0')
{
if (islower(*pa)) //判断是不是小写字母
*pa = toupper(*pa); //是的话就将其准换成大写字母
else if (isupper(*pa))
*pa = tolower(*pa); //同上
pa++;
}
printf("%s", arr1);
return 0;
} 这是使用库函数的方法来实现大小写的转换,当然,还有一种古老的方法可以实现大小写的转换:
#include
#include
#include
int main()
{
char arr1[] = "HeLLo,WoRld";
char* pa = arr1;
while (*pa != '\0')
{
if (islower(*pa))
*pa = *pa - 32; //减32,将小写字母转换成大写字母
else if (isupper(*pa))
*pa = *pa + 32; //加32,将大写字母转换成小写字母
pa++;
}
printf("%s", arr1);
return 0;
} 大写A的ASCII码是65,小写a的ASCII码值是97,一个字母的大小写的差值正好是32,所以加减32就可以将字母转换成大写或者是小写。
三、字符串的库函数
1.strlen函数
对于strlen函数,我们再熟悉不过了,前面都有起到过,这个函数的功能是求字符串在'\0'之前出现的字符个数,下面是这个函数的定义

strlen()函数的功能:
#include
#include
#include
int main()
{
const char* str1 = "hello my school!";
size_t len = strlen(str1);
printf("%u", len);
return 0;
} 运行结果为: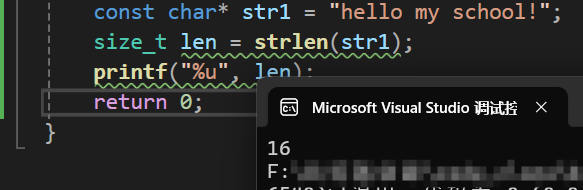
但是想要更加细致地了解这个函数的功能,我们就要自己来实现一遍这个函数的功能,那么就来自己实现一遍strlen函数吧:
方法一:
指针+计数器
#include
#include
int my_strlen(const char* arr)
{
const char* temp = arr;
int count = 0;
while (*temp != '\0')
{
count++;
temp++;
}
return count;
}
int main()
{
const char* arr = "hello world!!!";
int len = my_strlen(arr);
printf("%u \n", len);
return 0;
} 运行结果如下:

方法二:
不创建临时变量,使用递归的方式
#include
#include
#include
size_t my_strlen(const char* str)
{
assert(str);
if (*str == '\0')
return 0;
else
return 1 + my_strlen(str + 1);
}
int main()
{
const char* str = "I am IronMan!!";
size_t len = my_strlen(str);
printf("%u", len);
return 0;
} 运行结果如下:
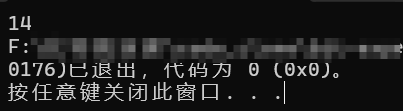
方法三:
指针-指针
#include
#include
#include
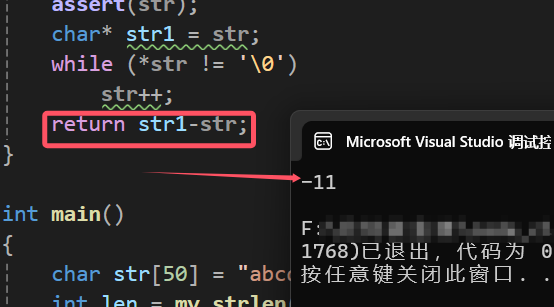
int my_strlen(char* str)
{
assert(str);
char* str1 = str;
while (*str != '\0')
str++;
return str - str1; //这里需要注意一下
}
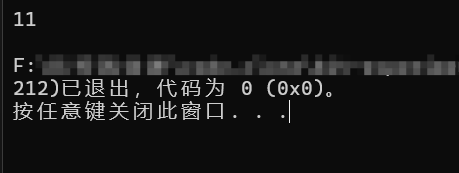
int main()
{
char str[50] = "abcdefghijk";
int len = my_strlen(str);
printf("%d\n", len);
return 0;
} 在这段代码中,我们的my_strlen函数最后返回的结果是尾指针减去头指针,所以结果是整数:
当我们将返回的类型改成头指针减去尾指针,那么结果将会是负数:
这是我们用指针-指针这种方法的时候需要注意的问题
使用时要注意的地方:
我们在使用strlen函数时,经常会将两个strlen计算出来的值进行相加相减,这里我们就要对这种操作进行一些了解:
加法:
#include
#include
#include
int main()
{
const char* str1 = "I am a student";
const char* str2 = "I love you";
assert(str1);
assert(str2);
size_t str1_num = strlen(str1);
size_t str2_num = strlen(str2);
//现在进行加法操作
printf("%u", str1_num + str2_num);
return 0;
} 运行结果为:
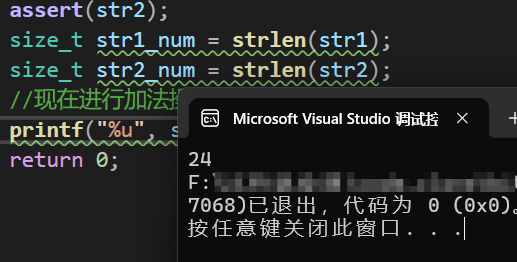
对于加法一般是没有太大问题的,即数学上与物理上都保持一致。
减法:
#include
#include
#include
int main()
{
const char* str1 = "hello world";
const char* str2 = "114514";
size_t str1_num = strlen(str1);
size_t str2_num = strlen(str2);
printf("%u", str1_num - str2_num);
return 0;
} 在现在得代码中,str1明显是·比str2要长的,那么str1-str2的结果自然符合我们的预期,运行结果如下:
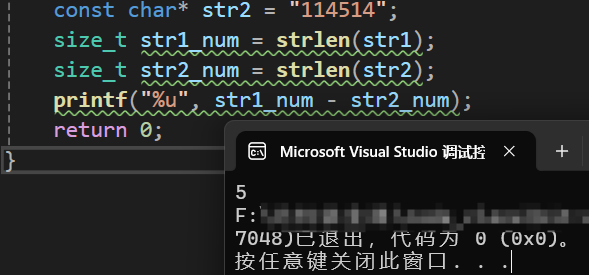
可以看到,在做减法时,当str1>str2的时候,减法所得的结果是符合数学与物理逻辑的
但如果str1<str2(或者是str2-str1)的时候呢?结果真的还是像我们像的那样,输出的是负数吗?,我们来试试看:
#include
#include
#include
int main()
{
const char* str1 = "hello world";
const char* str2 = "114514";
size_t str1_num = strlen(str1);
size_t str2_num = strlen(str2);
printf("%u", str2_num - str1_num); //这里将str1与str2的位置调换了一下
return 0;
} 运行结果如下:
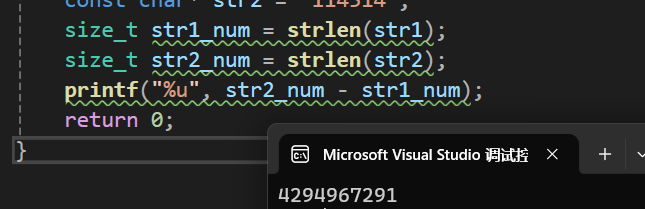
由此可见,当strlen(str1)(被减数)<strlen(str2)(减数)的时候,输出的值会是一个非常大的数,为什么?
这就涉及到了strlen所返回的数据在内存中的存储:strlen()这个函数所返回的值是%u ,也就是无符号整型(unsigned int / unsigned long),当%u被赋予了有符号整型,如现在代码里的-5,那么编译器就会认为-5应该是个正整数,详细请看下图:

所以当我们在进行strlen()的减法运算时,要注意被减数和减数的大小,否则结果会不尽人意
以上是strlen()函数的基本用法以及模拟实现和需要注意的点
2.strcpy与strncpy函数
strcpy:
strcpy与strncpy,顾名思义,就是string copy,起到复制字符串的作用,他俩可以说是一对孪生兄弟。
strcpy对于字符串的要求是:
- 源字符串必须以'\0'结束,
- 目标字符串的空间必须足够大
这是strcpy的定义:

下面就来看看他们的作用:
strcpy:
#include
#include
#include
int main()
{
const char str1[50] = "hello 6";
char str2[60] = "world";
strcpy(str2, str1); //将str1的内容复制到str2中
printf("%s", str2);
return 0;
} 运行结果为:
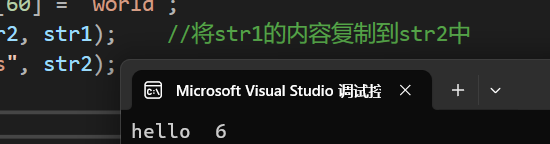
由此可见,strcpy会将字符串中所有数据都复制过来,但是,既然是可以复制字符串的函数,那么我们要想一个问题:strcpy会不会将字符串后面的'\0'赋值过来呢?
下面我们使用vs2022来进行调试看看结果:
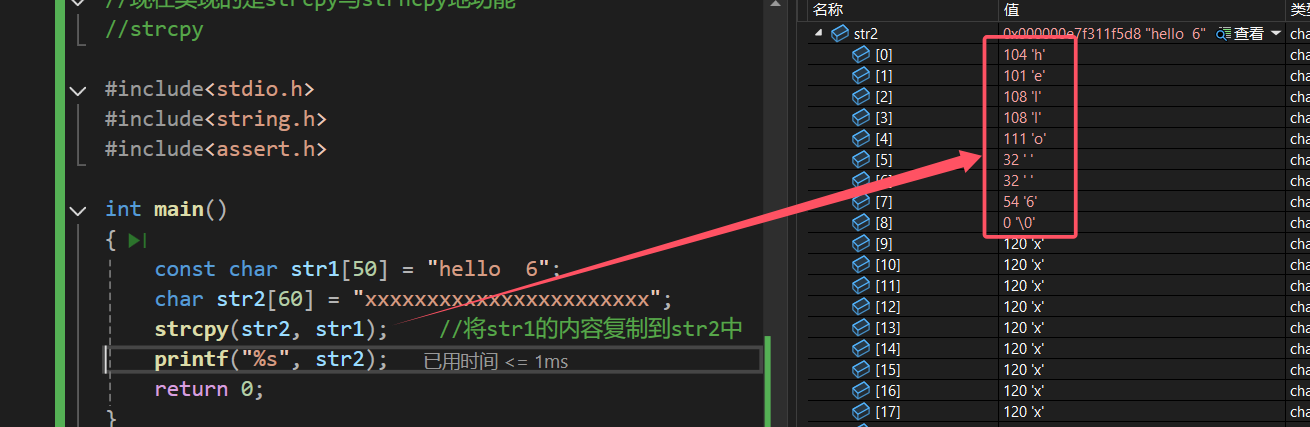
由此可见,在使用strcpy对字符串进行赋值的时候,是会将字符串最后的'\0'给复制过来的,这就是为什么strcpy会要求源字符串要以'\0'结尾的原因。
既然知道了strcpy会复制'\0',那如果源字符串中本身就有'\0'呢?这又会出现什么样的事情呢?我们通过下面的代码来看看:
#include
#include
#include
int main()
{
const char str1[50] = "hell\0o 6"; //字符串中本身就带有'\0'
char str2[60] = "xxxxxxxxxxxxxxxxxxxxxxx";
strcpy(str2, str1);
printf("%s", str2);
return 0;
} 运行结果为:
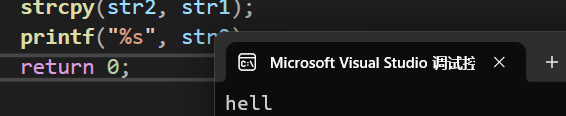
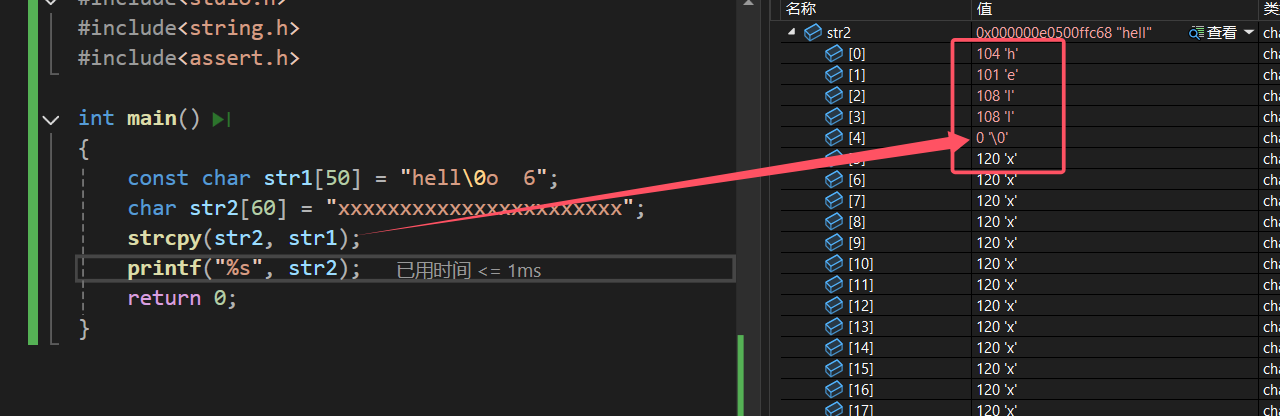
由此可见,strcpy只会复制第一个'\0'之前的字符串,同时也会复制第一个'\0'。
总结:
strcpy会完全复制源字符串中第一次出现的'\0'之前所有的内容以及'\0'本身
在知道了strcpy的功能之后,我们来自己实现一下这个字符串函数:
#include
#include
#include
char* my_strcpy(char* destination, const char* source)
{
assert(destination != NULL); //断言两个指针是否为NULL
assert(source != NULL);
char* temp2; //因为strcpy返回的是destination的地址,所以头地址
//最好不要改变,用另外一个变量来替dest往下走
temp2 = destination;
while (*source != '\0')
{
*temp2 = *source;
source++;
temp2++;
}
*temp2 = *source; //这句代码是将最后的'\0'复制过来
return destination;
}
int main()
{
const char str1[50] = "I am good at creating BUG";
char str2[100] = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";
my_strcpy(str2,str1);
printf("%s", str2);
return 0;
} 运行结果为: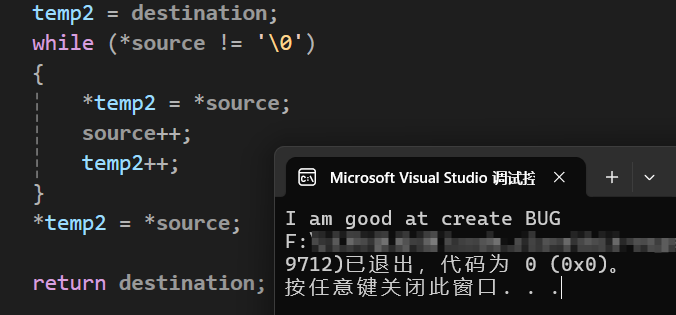
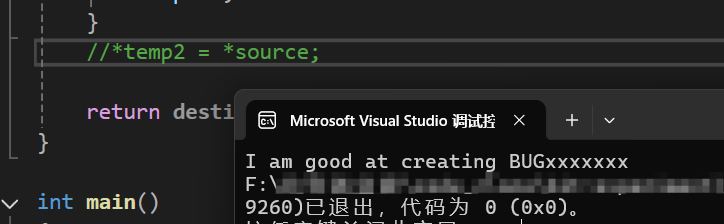
由此可见,复制的非常成功,我们的函数将'\0'也复制了过来,因为将'\0'复制过来之后,在输出时碰到了'\0',才不会继续输出后面的’xxxxx',如果没有复制'\0'的程序运行结果应该是这样的:
对于我们现在模拟实现的代码来说,还是太繁琐了,是否可以简化一点呢?我们来试试看:
//对于模拟实现函数这部分,我们可以将赋值与++这两部合并
char* my_strcpy(char* destination, const char* source)
{
assert(destination != NULL&& source != NULL);
char* temp = destination;
while (*temp && *source)
{
*temp++ = *source++;
}
*temp = *source;
return destination;
}这显然优化了一点点,但还是不够好,那我们试试将while()语句里面的语句一定到判断条件里呢?
char* my_strcpy(char* destination, const char* source)
{
assert(destination != NULL && source != NULL);
char* temp = destination;
while (*temp++ = *source++)
{
;
}
return destination;
}这样就完成了while()循环中内容的终极优化,下面是优化后的完整代码,我们来试着运行一下,看看功能是不是跟之前的保持相同:
#include
#include
#include
char* my_strcpy(char* destination, const char* source)
{
assert(destination != NULL && source != NULL);
char* temp = destination;
while (*temp++ = *source++)
{
;
}
return destination;
}
int main()
{
const char str1[50] = "I am good at creating BUG";
char str2[100] = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";
my_strcpy(str2, str1);
printf("%s", str2);
return 0;
} 运行结果为:
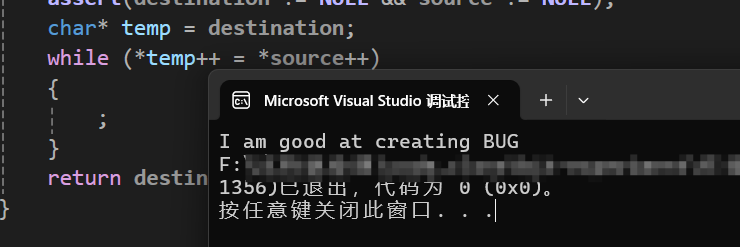
可以看见,我们优化后的代码功能与之前的是相同的,也将'\0'给复制了过来,但为什么这样写也能复制'\0'呢?因为在*source指向'\0'的时候,会将'\0'赋值给*temp,此时整个表达式的值变为'\0'='\0',而且'\0'的ACSII码是0,导致表达式的值为0,这就会让while()在结束循环之前将'\0'给复制了过来。
strncpy:
在对strcpy有了一定了解之后,我们理解strncpy就步困难了,由名字就不难猜出:strncpy的功能是复制规定n个字符到目标字符串中,下面是这个函数的定义:

可以看到,strncpy的参数比strcpy多了一个(size_t num),下面我们先来使用一下库函数的strncpy看看具体的功能:
#include
#include
#include
int main()
{
const char str1[100] = "hello world";
char str2[100] = "xxxxxxxxxxxxxxxxxx";
assert(str1 && str2);
strncpy(str2, str1, 3);
printf("%s", str2);
return 0;
} 运行结果为: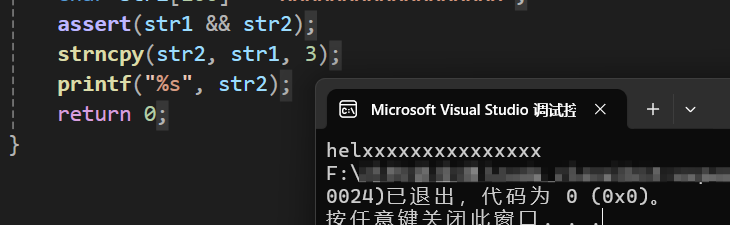
可以看到,真的就只复制了str1中前三个字符而已,但这只是其中一种情况,另外一种情况是深恶么呢?那就是,如果想要复制的num的个数大于source中的字符个数会怎么样?我们依旧通过代码调试来看看怎么个事儿:
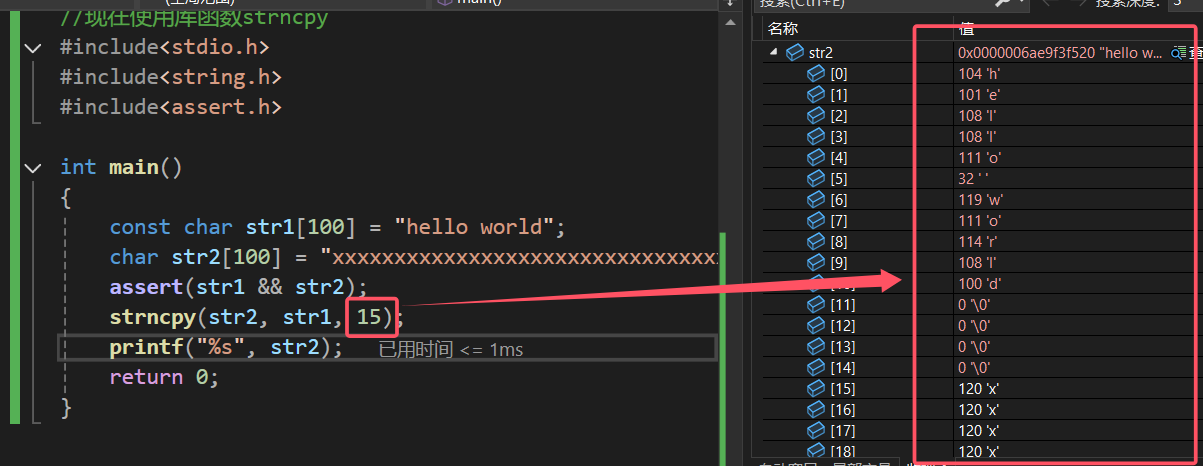
运行结果为: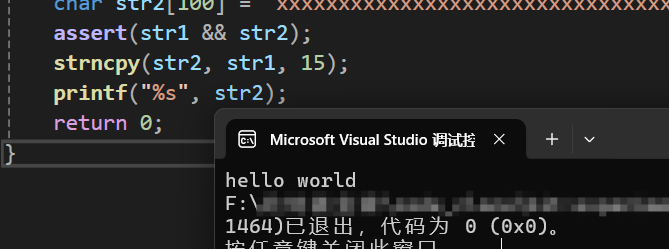
这样就一目了然了,可以看出,在num>strlen(source)时,会自动在复制的结果后面补上0('\0')。这就对应上了这个函数的概念:

翻译过来就是:

现在我们对strncpy有了一定的了解,那么我们自己来实现一遍这个函数吧~~~:
#include
#include
#include
char* my_strncpy(char* destination, const char* source, size_t num)
{
char* temp = destination;
size_t len1 = strlen(source); //这里先计算源字符串的长度,用于后面判断num与源字符串长 度的关系
if (len1 >= num)
{
while (num--)
{
*temp = *source;
temp++;
source++;
}
}
else
{
size_t len2 = len1;
while (len2--)
{
*temp = *source;
temp++;
source++;
}
len2 = len1; //当source的字符都复制了之后,就要重新将len2的值重置,以便于给多余的空间赋值'\0'
size_t num_sub = num - len2;
for (int i = 0; i < num_sub; i++)
{
*temp = '\0';
temp++;
}
}
return destination;
} 运行结果为:
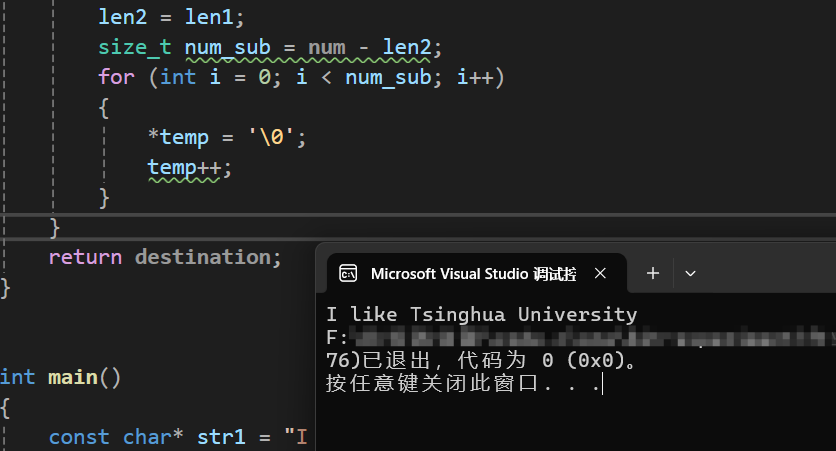
调试的结果为:
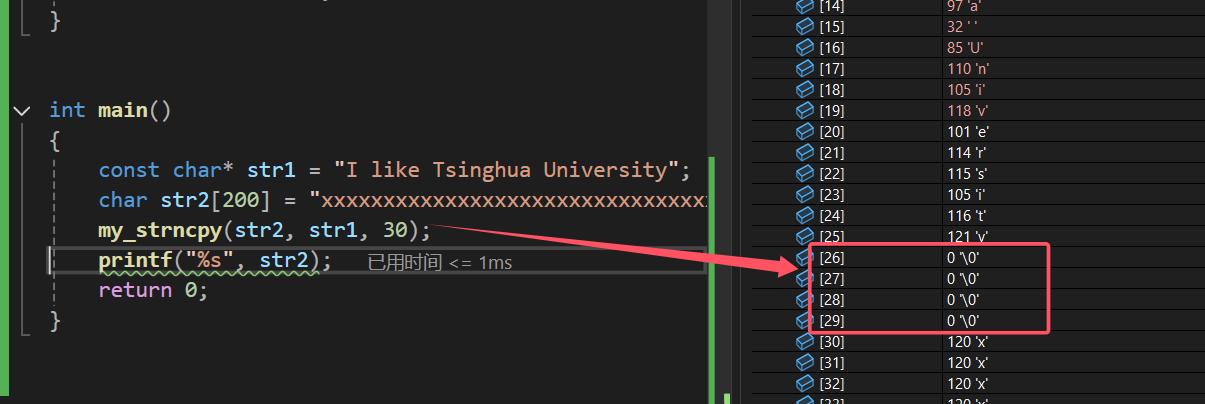
由此可见,我们的模拟函数时非常成功的,但是,这样的代码是不是太繁琐了呢?能不能简化一下?能的兄弟,能的,下面就来优化一下:
char* my_strncpy(char* destination, const char* source, size_t num)
{
assert(destination && source);
char* temp = destination;
size_t len = strlen(source);
for (int i = 0; i < num; i++)
{
if (i < len)
{
*temp = *source;
source++;
}
else
{
*temp = '\0';
}
temp++;
}
}这是优化之后的代码,可以看到,这个版本的代码将源字符串的长度与num的大小比较给去掉了,使得时间复杂度得以优化。
以上就是strcpy与strncpy的基本基本介绍
3.strcmp与strncmp函数
strcmp/strncmp看名字就知道,(string compare)这两个函数的功能是将两个字符串进行比较。
strcmp:
这是strcmp的定义:

翻译之后的结果:

strcmp的比较规则是:比较两个字符串对应位置上字符的ASCII码的大小
现在来看看这个函数怎么使用:
#include
#include
int main()
{
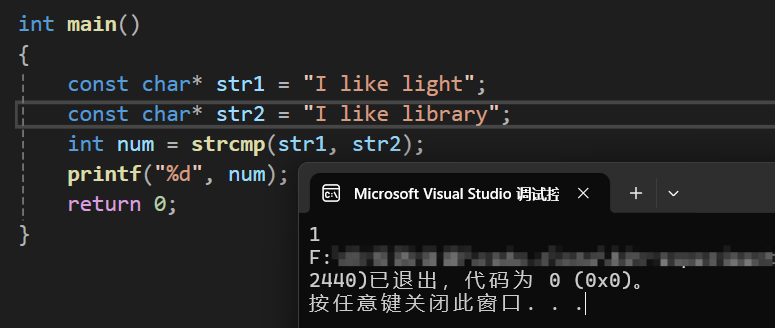
const char* str1 = "I like library";
const char* str2 = "I like light";
int num = strcmp(str1, str2); //由此可见,b的ASCII码小于g
printf("%d", num);
return 0;
} 运行结果为:
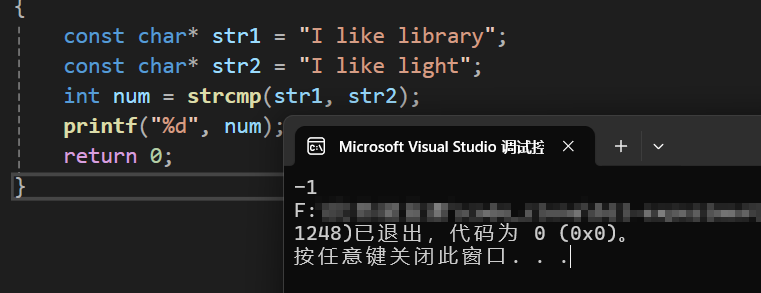
为什么会是-1呢?这就跟strcmp的返回值有关了
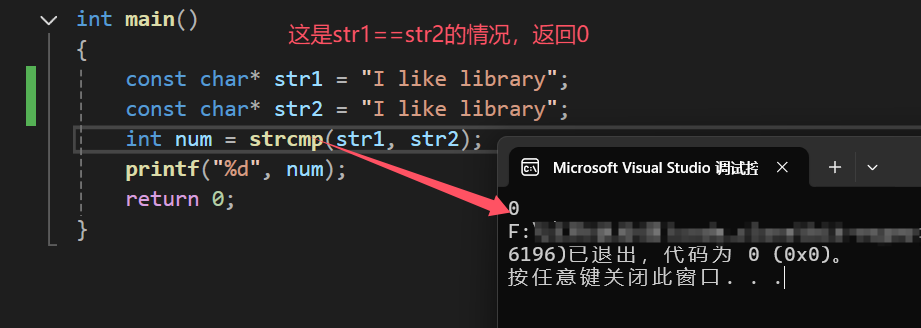
- 当str1>str2的时候,函数返回1
- 当str1 == str2的时候,函数返回0
- 当str1<str2的时候,函数返回-1
看下图:
在了解strcmp的基本用法以及概念的时候,我们来自己模拟实现一下:
#include
#include
#include
int my_strcmp(const char* str1, const char* str2)
{
assert(str1 && str2); //依旧断言
while (str1 && str2)
{
if (str1 > str2)
return 1;
else if (str1 == str2)
return 0;
else if (str1 < str2)
return -1; //符合标准返回值
str1++;
str2++;
}
}
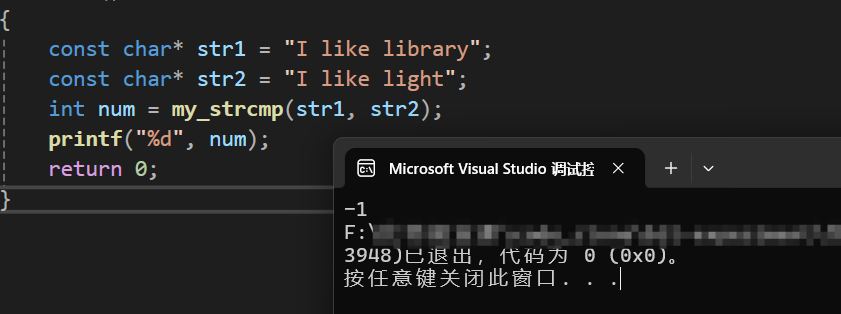
int main()
{
const char* str1 = "I like library";
const char* str2 = "I like light";
int num = my_strcmp(str1, str2);
printf("%d", num);
return 0;
} 运行结果为:
这只是第一个版本,还可以继续优化:
int my_strcmp(const char* str1, const char* str2)
{
assert(str1 && str2); //依旧断言
while (*str1 == *str2 && str1 != '\0')
{
str1++;
str2++;
}
return *str1 - *str2;
}在这段函数代码中,只要*str1不等于*str2或者是str1到头了,就可以退出循环然后返回所判断的值了,这里返回的是两个字符的ASCII码的差值。
strncmp:

翻译过来就是:

这个函数,类比于strncpy就可以知道,是比较str1与str2的前num个字符是否相等,依旧先使用一遍库函数看看功能:
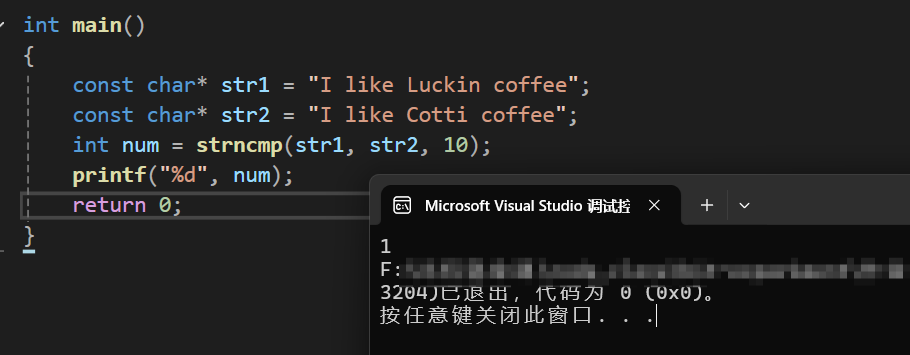
在前十个字符中,最先不一样的是'L'和'C',由此可以得出1这个结果;如果将10改成5,结果会是什么呢?
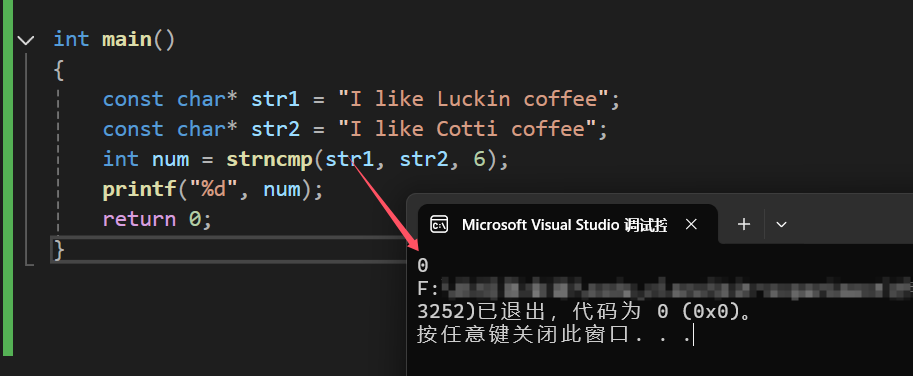
可见,前五个字符是相同的,那么就会返回0,并不会受到后面字符的影响
现在来自己模拟实现一遍:
#include
#include
#include
int my_strncmp(const char* str1, const char* str2,size_t num)
{
assert(str1 && str2);
if (num == 0)
return 0;
while (num--&&*str1==*str2&&*str1!='\0') //此处的判断条件与strcmp几乎一致,只是加上了num--这个判断条件而已
{
str1++;
str2++;
}
return *str1 - *str2;
}
int main()
{
const char* str1 = "I like Luckin coffee";
const char* str2 = "I like Cotti coffee";
int num = my_strncmp(str1, str2, 6);
printf("%d", num);
return 0;
} 运行结果为:
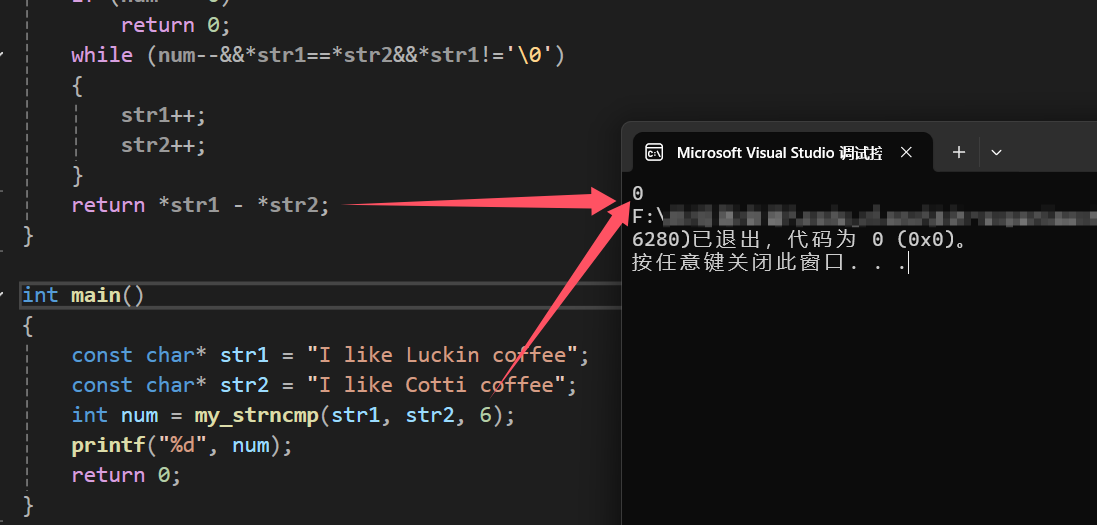
总结:
strcmp与strncmp的功能基本一致,strcmp比较的是整个字符串,而strncmp比较的是部分(前num个)字符串
4.strcat与strncat函数
这两个字符串就有点意思了,依旧是看名字,string concatenate(字符串拼接);
strcat:

翻译过来就是:

我们先使用库函数来看看功能是什么样的:
#include
#include
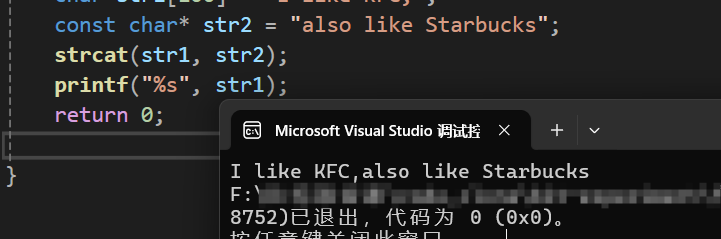
int main()
{
char str1[100] = "I like KFC,";
const char* str2 = "also like Starbucks";
strcat(str1, str2);
printf("%s", str1);
return 0;
} 运行结果如下:
我们来调试看看,str1中的'\0'是否真的被覆盖掉了?
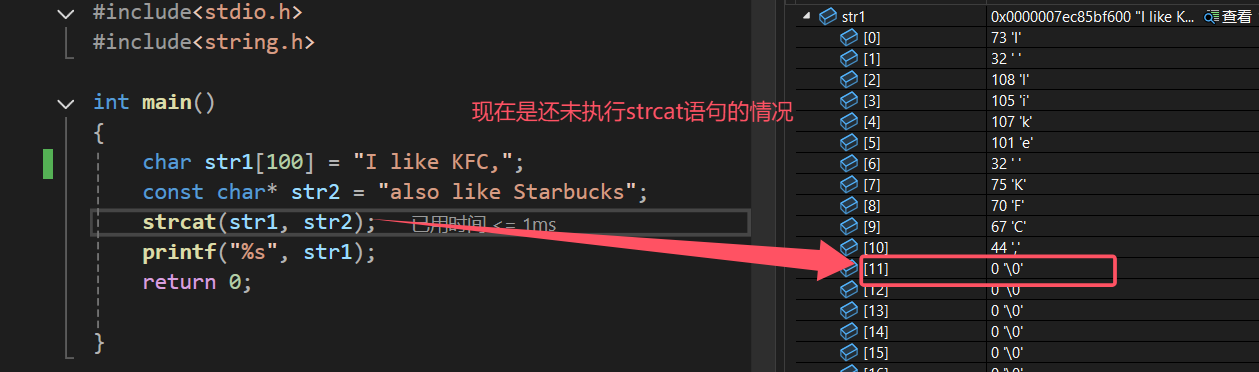
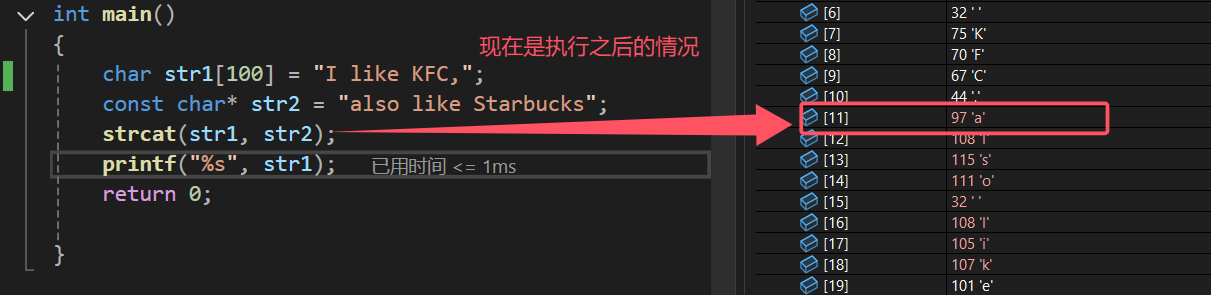
可以看到,在str1[11]这个元素里面,原本的'\0'被str2的逗号替代了。下面我们来自己实现以下这个函数:
#include
#include
#include
char* my_strcat(char* destination, const char* source)
{
assert(destination && source);
char* temp = destination;
while (*temp)
temp++;
//其实strcat的本质就是先将destination的指针移动到最后,然后再使用strcpy的方法将str2给复制过来
while ((*temp++ = *source++))
{
;
}
return destination;
}
int main()
{
char str1[100] = "I like KFC,";
const char* str2 = "also like Starbucks";
my_strcat(str1, str2);
printf("%s", str1);
return 0;
} 现在我们来看看运行结果是不是跟原库函数一样:
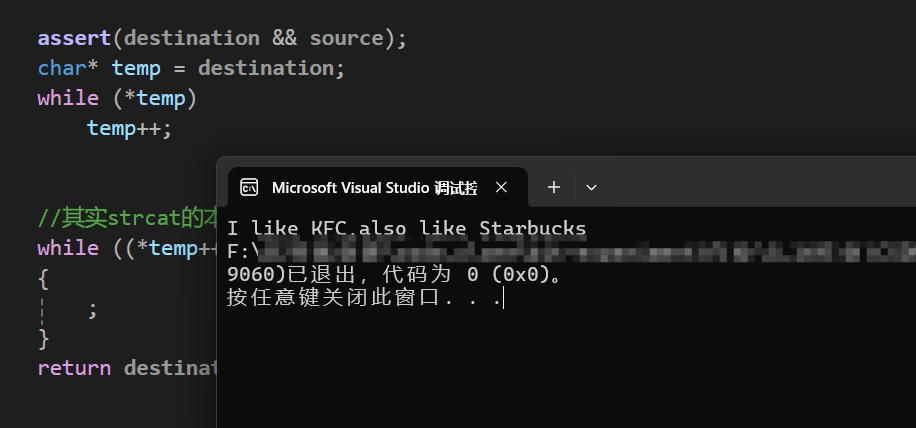
由此可见,这样模拟实现函数是成功的,同时也在str2后面赋值上了'\0'。
strncat:
根据类比法,strncat的作用是将*source指向的字符串的前n个字符拼接到destination后面

翻译过来就是:

由于功能与strcat相似,这里就直接上我们模拟实现的代码:
#include
#include
#include
char* my_strncat(char* destination, const char* source, size_t num)
{
assert(destination && source);
char* temp = destination;
while (*temp != '\0')
temp++;
while ((*temp++ = *source++)&&num--)
{
;
}
*temp = '\0'; //给结尾强制加上'\0'使得行为与原函数保持一致
return destination;
}
int main()
{
char str1[100] = "I like KFC,";
const char* str2 = "also like Starbucks";
my_strncat(str1, str2,6);
printf("%s", str1);
return 0;
} 运行结果为:
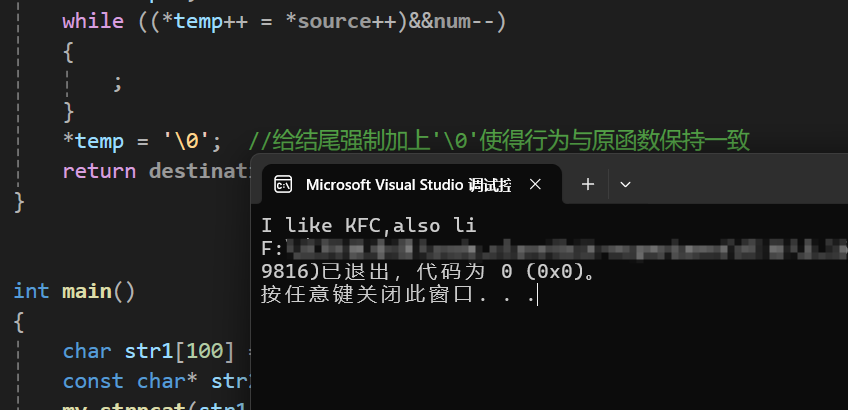
总结:
strcat与strncat都是实现将source复制到destination的'\0'及其之后的空间。
5.strstr函数
strstr函数,这个就比较有意思了,先上定义:

翻译如下:

也就是说,在比较的过程当中,'\0'不参与,但是会在遇到'\0'的时候停止,下面我们先通过使用库函数来看看这个函数的具体作用:
#include
#include
int main()
{
//我喜欢蜜雪冰城
const char* str1 = "I like Mixue Ice Cream & Tea,and Mixue Ice Cream & Tea is good";
char* str2 = "Mixue Ice Cream & Tea";
char* ans = strstr(str1, str2);
printf("子串第一次出现的位置:%s", ans);
return 0;
} 运行结果为: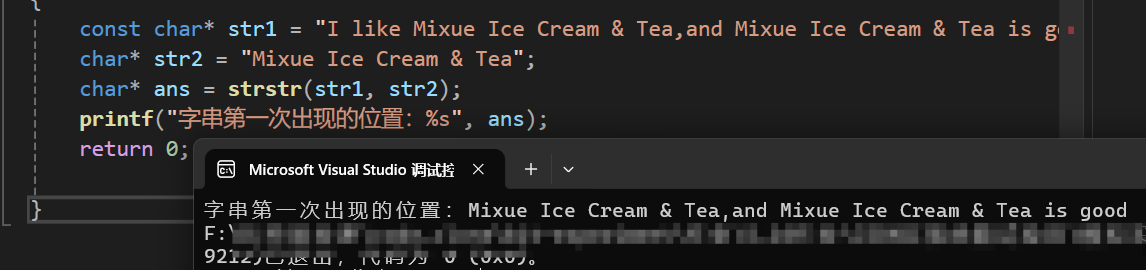
也就是说,strstr返回的是目标字符串在母串中第一次出现的位置的首地址,下面我们来自己实现一下这个函数:
#include
#include
#include
const char* my_strstr(const char* destination, const char* source)
{
//先对指针进行判空
assert(destination != NULL && source != NULL);
//再对子串进行判空
if (source == '\0')
{
return ((char*)destination);
}
//如果不为空:
const char* p = destination;
const char* s1 = NULL;
const char* s2 = NULL;
while (*p) //只要指向主串的指针的内容不是'\0',就继续循环下去寻找
{
s1 = p;
s2 = source;
while (*s1 && *s2 && (*s1 == *s2)) //当出现一个相同的字符后,就继续往下比较,如果满足主串和子串都不为尾部并且其中的字符都相同的时候,就往下继续
{
s1++;
s2++;
}
//如果是因为子串s2到尾部而停止,那就说明之前比较的字符都相等,即主串中含有子串,那就返回p的地址,即子串第一次出现的地址
if (*s2 == '\0')
{
return p;
}
//如果是s1到尾部或者是出现不相同字符的情况而停止,说明不相等,那就让p继续往下寻找
p++;
}
//当大循环结束后都没有发现相等的,那就返回NULL
return NULL;
}
int main()
{
const char* str1 = "I like Mixue,and it is excellent!";
const char* str2 = " Mixue";
char* ans = my_strstr(str1, str2);
if (ans != '\0')
{
printf("%s", ans);
}
else
{
printf("母串中不存在子串!\n");
}
return 0;
} 总结:
strstr()函数是用于查找字串的函数,返回值是字串第一次出现在母串中的的地址
6.strtok函数
strtok函数的名字看起来就比较抽象了,不想前面几个那么好理解,下面是C语言官网对其的定义:

翻译如下:

下面是strtok()函数的用法:
#include
#include
#include
int main()
{
char str[] = "congratulations,execllent;book'student RTX5090";
char sep[] = ",;' ";
char* ans = NULL;
for (ans = strtok(str, sep); ans != NULL; ans = strtok(NULL , sep))
{
printf("%s\n", ans);
}
return 0;
} 运行结果为:
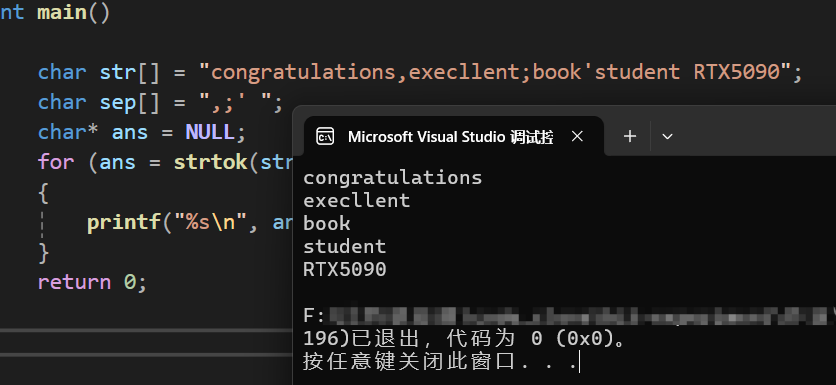
从运行结果可以看出,strtok函数会按照我们给的sep集合划分str中的字符,就拿最后两个单词来讲举例:student RTX5090,这两个单词中间有一个空格,这两个单词会被划分是因为sep数组中含有空格,现在我们把空格从sep中给取掉,看看结果会是什么样的:
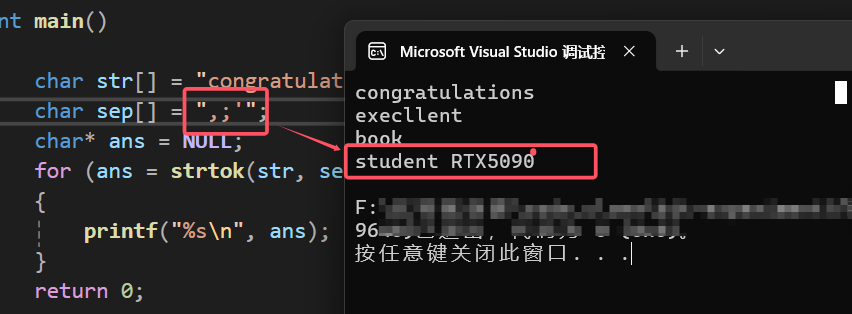
运行结果是:stiudent 与 RTX5090不会被划分,而是在同一行,这就是因为sep中没有空格所导致的。
关于strtok函数还有一个需要注意的点就是,第一次使用strtok函数时,参数中的
char* strtok(char* str,const char* delimiters)的char*str要使用字符串的名字,而第二次使用时,则需要把字符串的名字替换成NULL,即
char* strtok(NULL,const char* delimiters);
刚才上面的代码是为了展示strtok的大概功能,下面的代码则是对strtok使用的简单说明:
#include
#include
#include
int main()
{
char str[] = "congratulations,execllent;book'student RTX5090";
char sep[] = ",;' ";
char* ans = NULL;
ans = strtok(str, sep); //这里只调用一次strtok函数
printf("%s\n", ans);
return 0;
}
//运行结果为:
//congretulations 也就是说,strtok使用一次,单次输出只会输出第一个根据sep中的标志所划分的字符(串),如果想要划分出第二个字符(串),则要这样写:
#include
#include
#include
int main()
{
char str[] = "congratulations,execllent;book'student RTX5090";
char sep[] = ",;' ";
char* ans = NULL;
ans = strtok(str, sep); //这里只调用一次strtok函数
printf("%s\n", ans);
ans = strtok(NULL, sep); //这里是第二次调用strtok函数,要将字符串名字该成NULL
printf("%s\n", ans);
return 0;
}
//输出结果:
//congratulations
//excellent 所以只要加上判断(ans!=NULL),就可以写出第一次展示strtok代码中的for循环语句
总结:
strtok是用sep中的标志对str中的字符串进行划分,假如str中不含有sep中的标志,那么就会返回NULL;
第一次调用strtok是,要将第一个参数写成字符串名字,而第二次调用时就要将第一个参数写成NULL
7.strerror与perror函数
strerror:
这是C语言官网对strerror的定义:
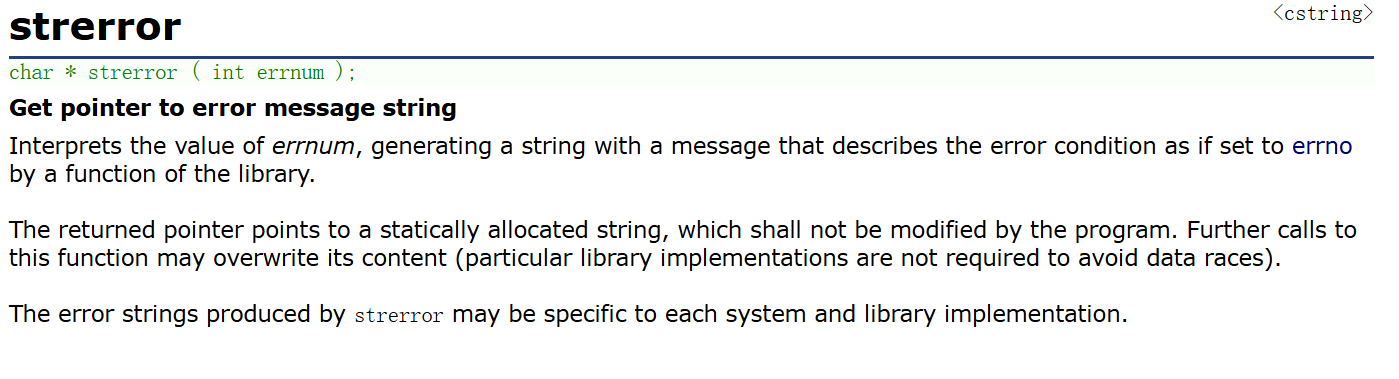
翻译结果如下:

也就是说,这玩意可以找出错误码为errnum的错误信息:
#include
#include
int main()
{
int num = 0;
for (int i = 0; i < 10; i++)
{
printf("%s\n", strerror(i)); //打印错误码为0~9的报错信息
}
return 0;
} 运行结果为:
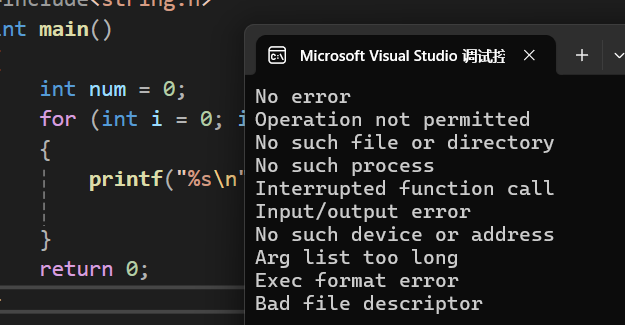
这只是这个函数的功能,那我们具体会用在哪些场景呢?那就看看下面的例子:
#include
#include
#include
int main()
{
FILE* pfile;
pfile = fopen("man.txt", "r");
if (pfile == NULL)
{
printf("打不开 man.txt这个文件的原因是:%s\n", strerror(errno));
}
return 0;
} 代码中的errno是一个C语言程序自动启动的一个全局变量,记录的是出现错误的错误码,这些错误码被存储在<errno.h>这个头文件中,像上面这个代码的功能是在"r"路径下打开一个名为"man.txt"的文件,但是这文件不存在,就会出现这运行结果:
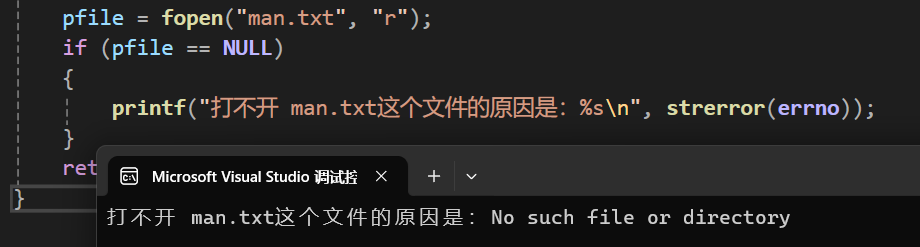
这就是strerror的使用场景。
perror:
这是C语言官网对perror的定义:

翻译过来就是:

perror与strerror相似,可以说功能比strerror全面一点点,perror会直接打印错误信息,就拿刚才那个使用场景来举例:
#include
#include
#include
int main()
{
FILE* pfile;
pfile = fopen("man.txt", "r");
if (pfile == NULL)
{
perror("打不开 man.txt 的原因是:");
}
return 0;
} 运行结果为:
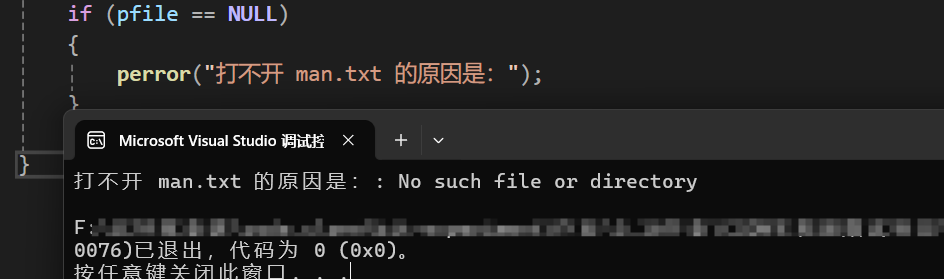
总结:
strerror会提取出错误码的信息,但不会主动打印,perror会提取出错误码的信息,会自动打印
以上就是我们在编写代码时经常会用到的有关字符串的函数
文章是自己写的哈,有啥描述不对的、不恰当的地方,恳请大佬指正,看到后会第一时间修改,感谢您的阅读。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号