

SQL优化分析学习 - 教程
2025-09-13 22:00 tlnshuju 阅读(12) 评论(0) 收藏 举报前言
我知道的分析SQL的指令有4个,但我用的一直比较迷糊,今天有时间,决定学习、记录一下。
SET STATISTICS PROFILE ON --1、统计信息概况
SET STATISTICS IO ON --2、统计输入/输出
SET STATISTICS TIME ON --3、统计时间
SET SHOWPLAN_XML ON --4、查询执行计划2和3 并没有什么出彩的地方。主要是1、4的分析
一、STATISTICS PROFILE 执行方式
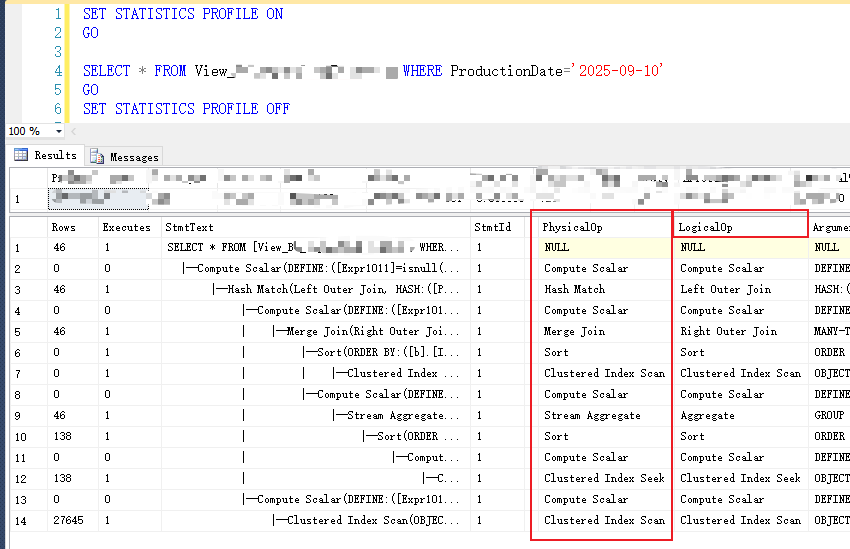
⚠️这是一个统计性质的视图,能够体现查询复杂性。
可以看出 PROFILE 给的字段虽然多,但有用的就几个
PhysicalOp列 和 LogicalOp列 : 分别表示物理操作符和逻辑操作符。逻辑操作符表示优化器的意图,物理操作符表示实际执行方式。
这里主要看PhysicalOp就行了,我将类型挨个解读:
1. Compute Scalar: 计算标量
如数学运算、函数调用、类型转换等
UnitPrice * Quantity AS Total, -- 计算表达式
CONVERT(VARCHAR, OrderDate) -- 类型转换。2、Hash Match: 哈希匹配
大表 JOIN(尤其无合适索引时)
GROUP BY 聚合
UNION / DISTINCT 去重3、Merge Join: 合并连接
中到大表 JOIN(双方均有索引排序)
需要有序输出的查询(如 ORDER BY 与 JOIN 键一致)4、Sort: 排序
ORDER BY 子句
为 Merge Join 或 Stream Aggregate 准备有序输入5、Clustered Index Scan: 聚集索引扫描
无可用索引的查询(如 SELECT * FROM table)
WHERE 条件无法使用索引(如函数操作列)6、Stream Aggregate: 流聚合
排序后 数据流上进行聚合(如 SUM/COUNT/GROUP BY)。7、Clustered Index Seek: 聚集索引查找
SELECT * FROM Orders WHERE OrderID = 10248 -- OrderID是聚集索引键8、Index Scan :索引扫描
9、Index Seek:索引查找
关键性能对比
| 操作符 | 适用场景 | 资源消耗 | 优化目标 |
|---|---|---|---|
Clustered Index Seek | 精确查找 | ⭐️⭐️⭐️⭐️⭐️ (低) | 首选操作 |
Hash Match | 大表JOIN/聚合 | ⭐️⭐️ (高) | 避免内存溢出 |
Merge Join | 有序数据JOIN | ⭐️⭐️⭐️ (中) | 确保输入已排序 |
Clustered Index Scan | 全表访问 | ⭐️ (极高) | 转化为Seek或非聚集索引 |
⚠️ 聚合是没办法,但全表扫描应该尽量避免
二、STATISTICS PROFILE主要字段
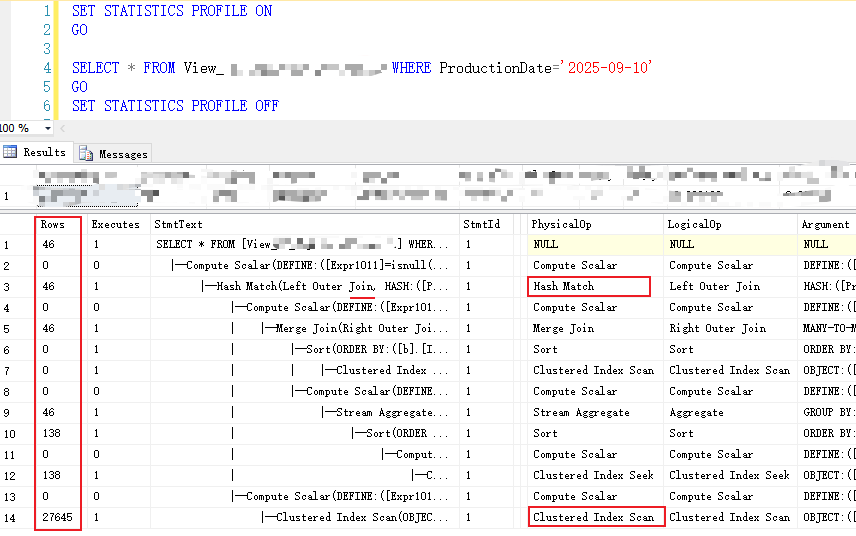
了解了PhysicalOp执行方式,倒回来再看。
Hash Match、Index Scan已经算高效操作了,
sort排序、Compute Scalar运算、Join(Merge Join),往往不可避免
但Clustered Index Scan 的全表扫描,则需优化索引。
还好这里的子表只有27642行,并不离谱。但也是数据优化的突破口。
其他字段
- ROW:实际处理的物理行数 ( 当然越少越好)
- Executes: 实际被执行的次数 (大于1,就需要注意是否冗余操作)
- Argument: 详细信息,(便于对PhysicalOp的判断)
三、SHOWPLAN_XML 执行计划
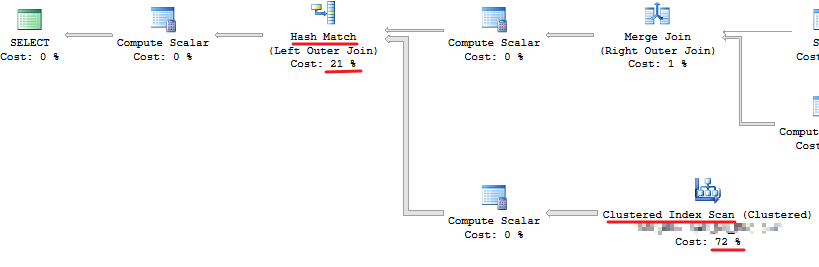
点开查询给的链接,主要是 21%+72% 占用了93%的资源。
Hash Match的聚合算高效操作,所以 Clustered Index Scan的全部操作有很大的优化空间。
换句话说,扫描全表,占行锁,也会影响其他人的读写。
四、总结
STATISTICS PROFILE ON ,优化方向在:减少查询行数、执行次数、优化执行方式(走索引减少全表扫描)
SET SHOWPLAN_XML ON ,是同数据下的,另外一种直观体现,优化方向更多在计划顺序、资源占用。
这两种方式,数据一致、但各有侧重。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号