机器学习数据操作
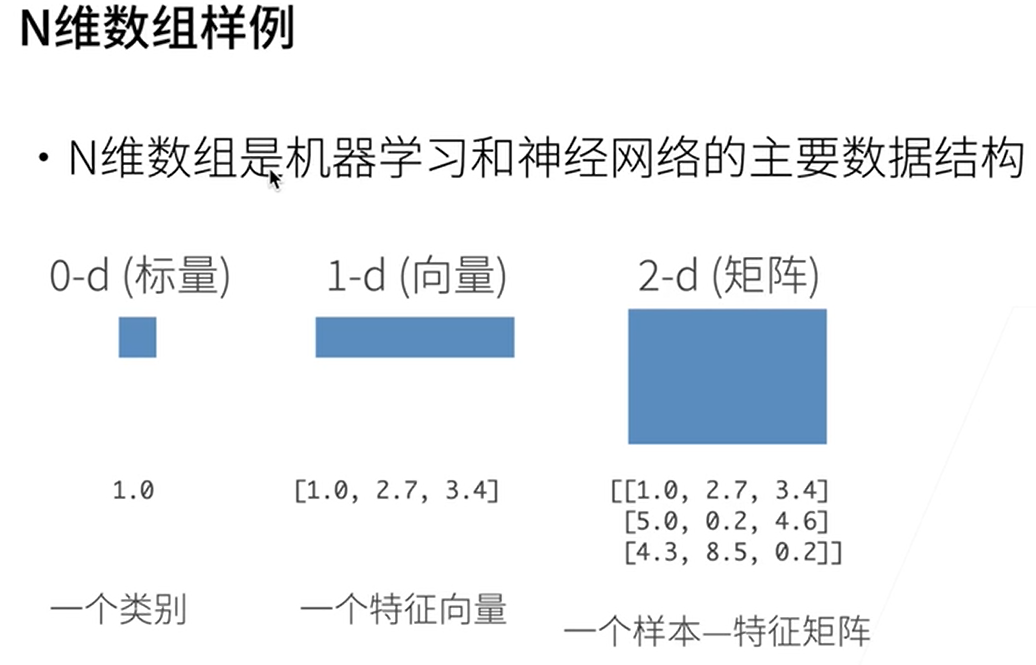
0维-一个类别
1维-一个特征向量
2维一个样本的特征矩阵,每一行表示一个样本,每一列表示一个特征
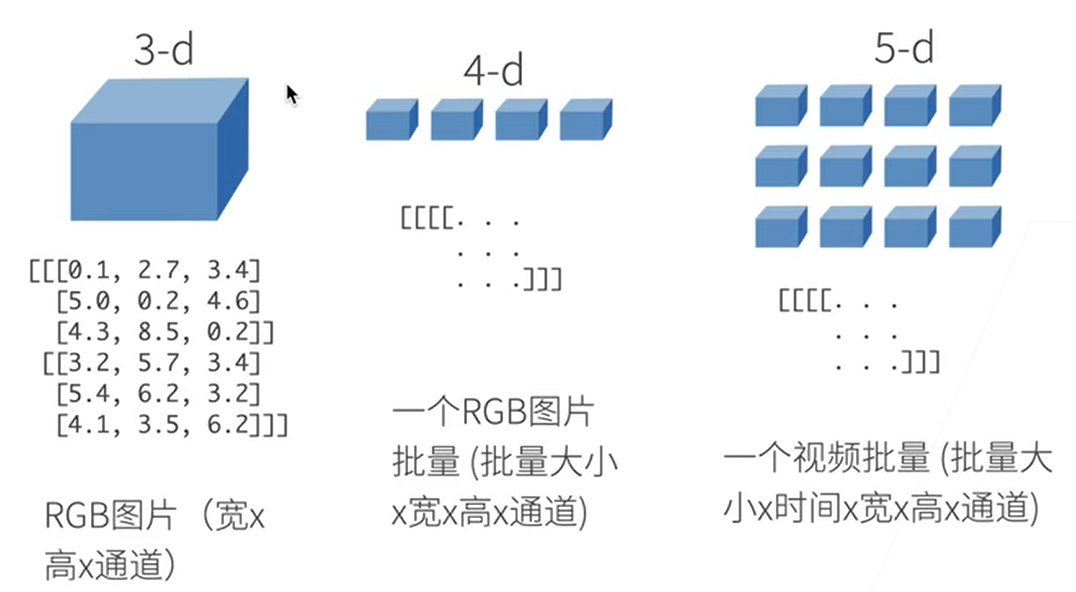
3维一个RGB图片宽,高,通道
4维一个RGB图片批量:批量大小、宽、高、通道
5维视频批量,批量大小、时间、宽、高、通道
通常定义的三维矩阵,一层就是一片吐司,一个吐司就是一个二维矩阵,有n行m列,这里假设有c片吐司,那这个三维矩阵的shape就是(c,n,m)
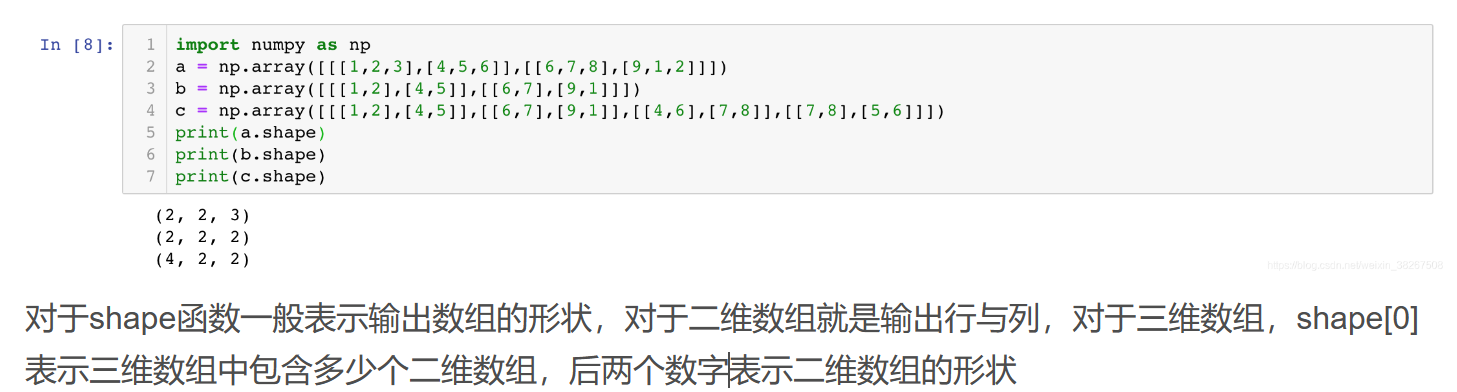
N维数组是机器学习和神经网络的主要数据结构
Numpy的ndarray
PyTorch和TensorFlow中的Tensor(张量)
创建数组:
形状:例如3*4矩阵
每个元素的数据类型:例如32位浮点数
每个元素的值,例如全0,随机数...
访问元素:
访问一个元素[1,2]
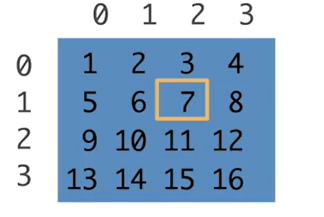
一行[1,:]
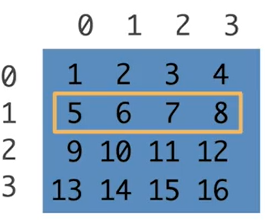
一列[:,1]
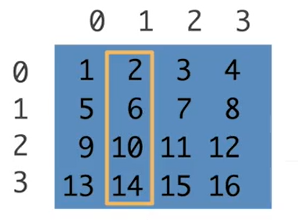
子区域[1:3,1:] [1,3)行,[1,)列
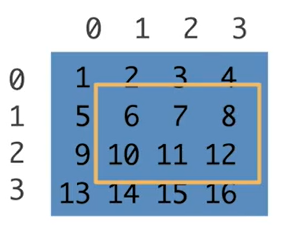
子区域[::3,::2] 行每三个一跳,列每两个一跳
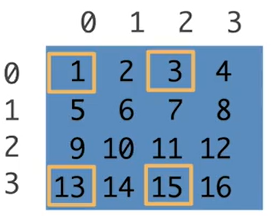
总结:
,的参数是行和列,:的参数是左开右闭的区间,::这个形式有三个参数,前两个是左开右闭的区间,最后一个是跳数
数据操作实现:
张量:表示一个数值组成的数组,这个数组可能有多个维度

x.shape访问张量的形状和张量中元素的总数,一维数组,12个元素

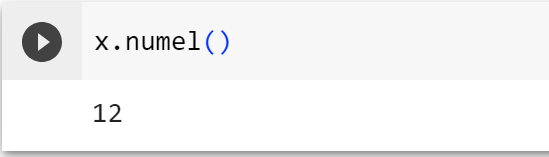
x.numel()元素的总数
改变一个张量的形状,而不改变元素数量和元素值,我们可以调用reshape函数

使用全0、全1、其他常量或从特定分布中随机采样的数字


通过提供包含数值的python列表,来为所需张量中的每个元素赋予确定值

一些运算:

把多个张量连结在一起

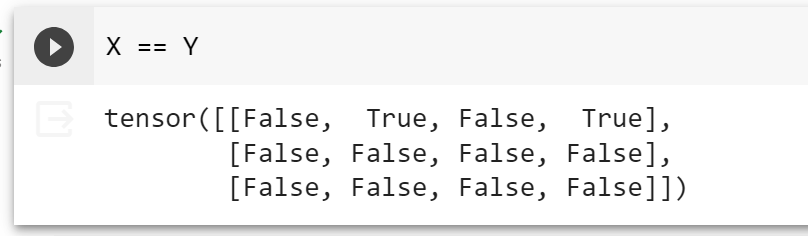
通过逻辑运算符构建二元张量
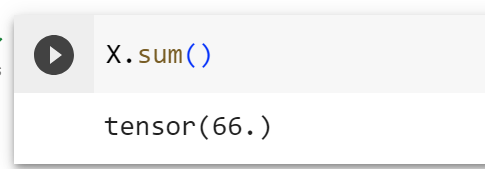
对张量中的所有元素进行求和,会产生只有一个元素的张量
即使形状不同,我们仍然可以通过广播机制,来按元素操作

a,b拓展为3*2
0 0 0 1
1 1 + 0 1
2 2 0 1
可以用-1选择最后一个元素

指定行列赋值

按区域赋值

转换为NumPy张量

将大小为1的张量转换为python标量

数据预处理
CSV-Comma-Separated Values
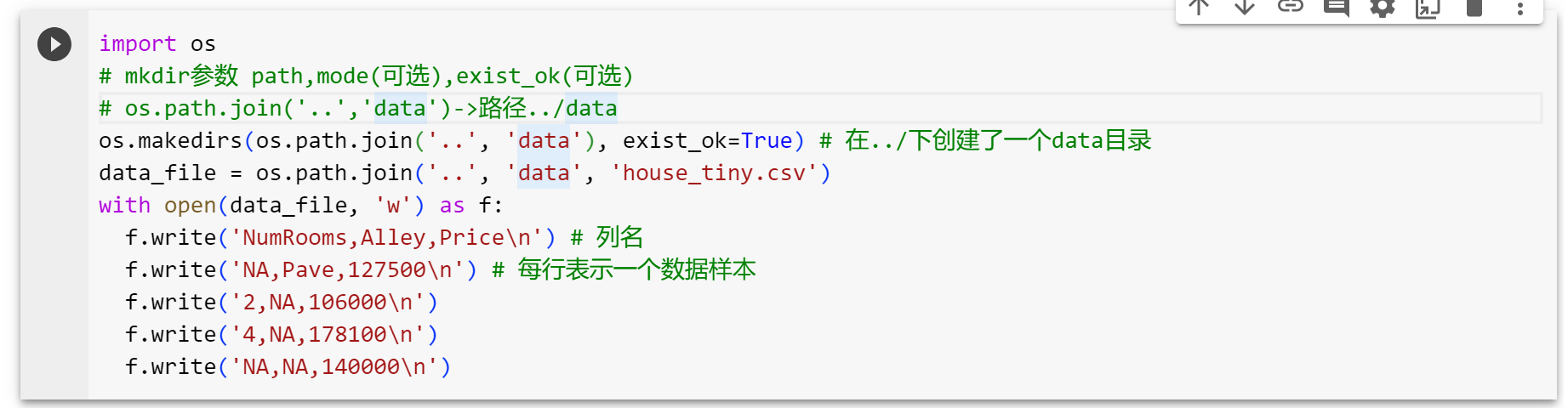
创建一个人工数据集,并存储在csv文件
读取pandas
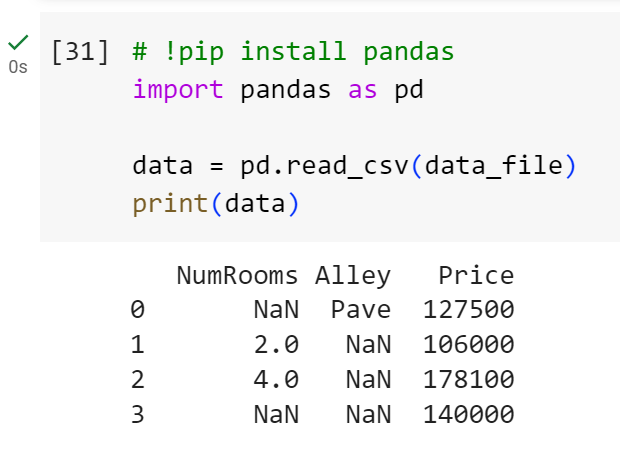
为了处理缺失数据,典型方法包括插值和删除,这里我们将考虑插值
这里inputs将第[0,2)列取出,这里数值缺失值用未缺失的值的均值(2.0+4.0)/2填充,非数值的不变
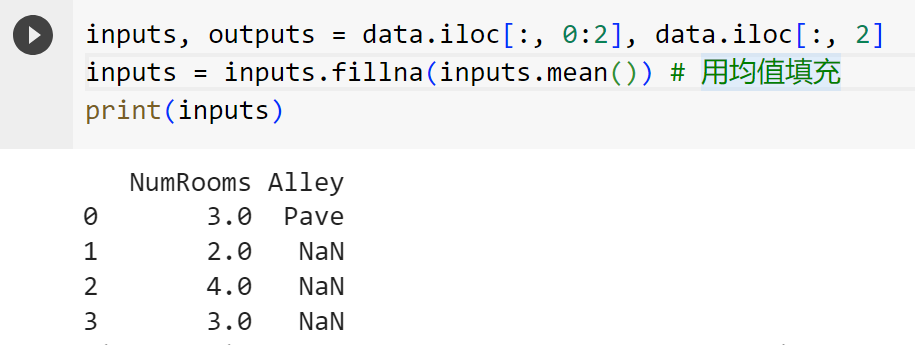
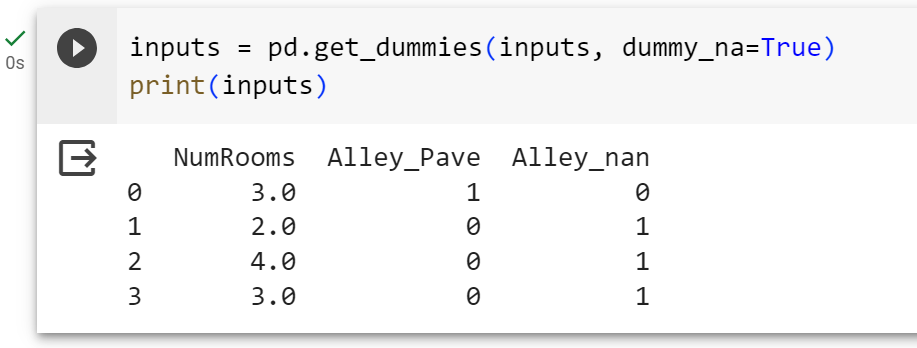
对于inputs中的类别值或离散值,我们将NaN视作一个类别
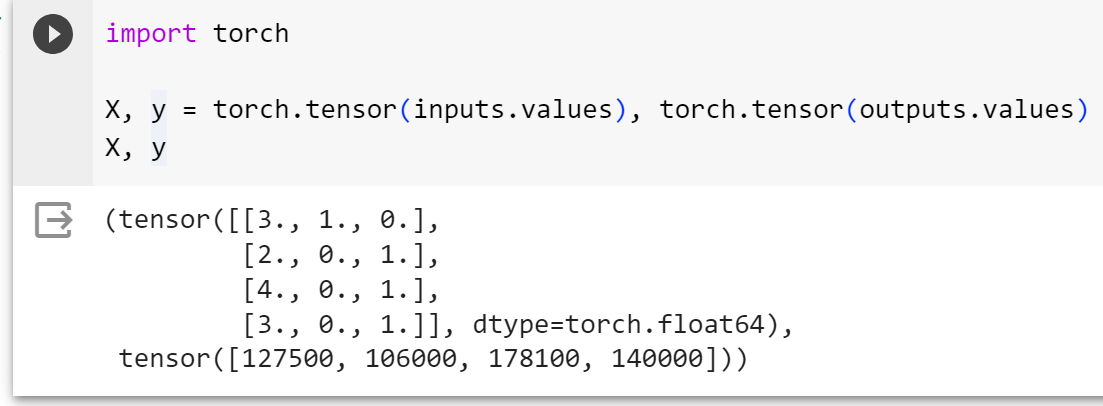
现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式
b是a的reshape,发现改了b,a也改了,类似于数据库中b是a的一个view(视图)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号