DDIA----笔记(不定时更新)
可靠性,可扩展性,可维护性
常见标准组件:
- 数据库(database)存储数据,以便自己或其他应用程序之后能再次找到
- 缓存(cache)记住开销昂贵操作的结果,加快读取速度搜索索引(search indexes)允许用户按关键字搜索数据,或以各种方式对数据进行过滤
- 流处理(stream processing) 向其他进程发送消息,进行异步处理
- 批处理(batch processing)定期处理累积的大批量数据
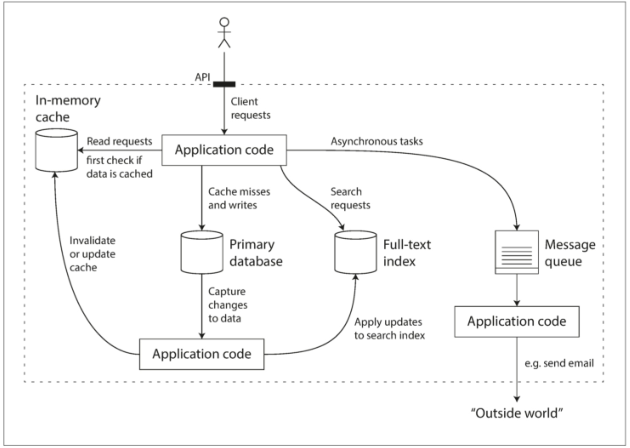
类别之间的界限变得越来越模糊,例如:数据存储可以被当成消息队列用(Redis),消息队列则带有类似数据库的持久保证(Apache Kafka)。如果将缓存(应用管理的缓存层,Memcached或同类产品)和全文搜索(全文搜索服务器,例如Elasticsearch或Solr)功能从主数据库剥离出来,那么使缓存/索引与主数据库保持同步通常是应用代码的责任。
- 可靠性(Reliability)
系统在困境(adversity)(硬件故障、软件故障、人为错误)中仍可正常工作(正确完成功能,并能达到期望的性能水准)。
造成错误的原因叫做故障,能预料并应对故障的系统特性可称为容错:系统可以容忍所有可能的错误,但在实际中这是不可能的。
注意故障不同于失效。故障通常定义为系统的一部分状态偏离其标准,而失效则是系统作为一个整体停止向用户提供服务。故障的概率不可能降到零,因此最好设计容错机制以防因故障而导致失效。
为了减少硬件故障,第一反应通常都是增加单个硬件的冗余度、大量使用机器。优先考虑灵活性和弹性,引入软件容错机制。
软件错误:仔细考虑系统中的假设和交互;彻底的测试;进程隔离;允许进程崩溃并重启;测量、监控并分析生产环境中的系统行为。运行时不断自检,并在出现差异时报警
人为错误:以最小化犯错机会的方式设计系统、将人们最容易犯错的地方与可能导致失效的地方解耦、各个层次进行彻底的测试、允许从人为错误中简单快速地恢复、配置详细和明确的监控、良好的管理实践与充分的培训
- 可扩展性(Scalability)
有合理的办法应对系统的增长(数据量、流量、复杂性)
服务降级的常见原因是负载增加,例如:系统负载已经从一万个并发用户增长到十万个并发用户,或者从一百万增长到一千万。也许现在处理的数据量级要比过去大得多。
可扩展性是用来描述系统应对负载增长能力的术语
性能方面描述:增加负载参数并保持系统资源(CPU、内存、网络带宽等)不变时,系统性能将受到什么影响?增加负载参数并希望保持性能不变时,需要增加多少系统资源?
参数:吞吐量、延迟和响应时间、
延迟考虑的时间花费方面:上下文切换到后台进程,网络数据包丢失与TCP重传,垃圾收集暂停,强制从磁盘读取的页面错误,服务器机架中的震动
- 可维护性(Maintainability)
许多不同的人(工程师、运维)在不同的生命周期,都能在高效地在系统上工作(使系统保持现有行为,并适应新的应用场景)
可操作性:便于运维团队保持系统平稳运行
简单性:从系统中消除尽可能多的复杂度(complexity),使新工程师也能轻松理解系统。
可演化性:使工程师在未来能轻松地对系统进行更改,当需求变化时为新应用场景做适配。
复制
复制意味着在通过网络连接的多台机器上保留相同数据的副本。
复制作用:
- 高可用性:即使在一台机器(或多台机器,或整个数据中心)停机的情况下也能保持系统正常运行
- 断开连接的操作:允许应用程序在网络中断时继续工作
- 延迟:将数据放置在距离用户较近的地方,以便用户能够更快地与其交互
- 可扩展性:能够处理比单个机器更高的读取量可以通过对副本进行读取来处理
复制的主要方法:
单主复制
客户端将所有写入操作发送到单个节点(领导者),该节点将数据更改事件流发送到其他副本(追随者)。读取可以在任何副本上执行,但从追随者读取可能是陈旧的。
多主复制
客户端发送每个写入到几个领导节点之一,其中任何一个都可以接受写入。领导者将数据更改事件流发送给彼此以及任何跟随者节点。
无主复制
客户端发送每个写入到几个节点,并从多个节点并行读取,以检测和纠正具有陈旧数据的节点。每种方法都有优点和缺点。单主复制是非常流行的,因为它很容易理解,不需要担心冲突解决。在出现故障节点,网络中断和延迟峰值的情况下,多领导者和无领导者复制可以更加稳健,但代价很难推理,只能提供非常弱的一致性保证。
复制可以是同步的,也可以是异步的。尽管在系统运行平稳时异步复制速度很快,但是在复制滞后增加和服务器故障时要弄清楚会发生什么,这一点很重要。如果一个领导者失败了,并且你推动一个异步更新的追随者成为新的领导者,那么最近承诺的数据可能会丢失。
复制滞后时的行为的一致性模型:
写后读
用户应该总是看到自己提交的数据。
单调读
当用户在某个时间点看到数据后,他们不应该在较早的时间点看到数据。
一致前缀读
用户应该将数据视为具有因果意义的状态:例如,按照正确的顺序查看问题及其答复。
多领导者和无领导者复制方法所固有的并发问题:因为他们允许多个写入并发发生冲突。
数据库可能使用的算法来确定一个操作是否发生在另一个操作之前,或者它们是否同时发生。
通过合并并发更新来解决冲突的方法:版本向量和向量时钟
待更新尾巴-------------------------------------------------------------------------------------------------------------------
作者:Honey_Badger —— 觉得这文章好,点一下左下角
出处:http://tk55.cnblogs.com/
posted on 2020-10-06 22:41 Honey_Badger 阅读(754) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号