关于在scrapy中使用xpath
1. 还是以虎嗅为例,他给我返回的是一个json格式的json串

2.那么我需要操作的就是把json串转换成我们的字典格式再进行操作
str=json.loads(response.body)['data'] #这边是拿到响应体数据,然后进行序列化成字典,拿到字典中key为data的的值.是一个字符串
3.自己导入选择器
from scrapy.selector import Selector
4.使用Selector的xpath方法获取内容
result = Selector(text=你从json提取出来的str).xpath('你的xpath表达式').extract()
5.使用效果
我把上一篇虎嗅的在parse中修改了来示范一下
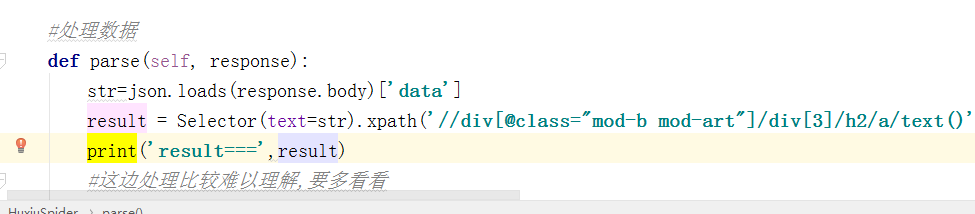
#处理数据 def parse(self, response): str=json.loads(response.body)['data'] result = Selector(text=str).xpath('//div[@class="mod-b mod-art"]/div[3]/h2/a/text()').extract() print('result===',result) #这边处理比较难以理解,要多看看

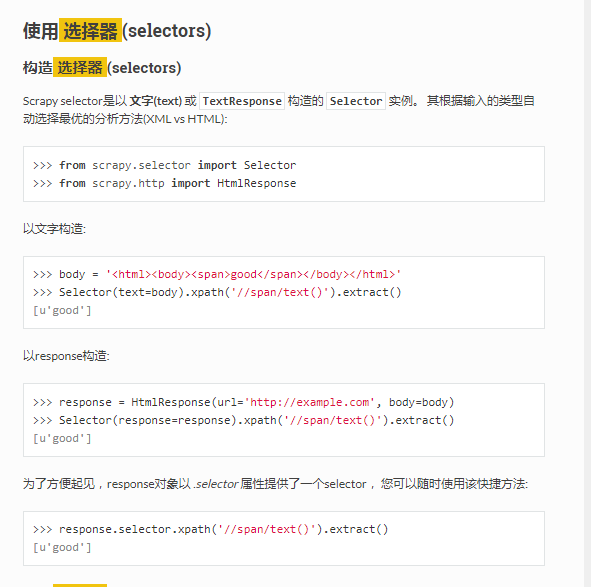
5.文档
当输入 response.selector 时, 您将获取到一个可以用于查询返回数据的selector(选择器),
以及映射到 response.selector.xpath() 、 response.selector.css() 的
快捷方法(shortcut): response.xpath() 和 response.css() 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号