MySQL
- 数据库:DataBase(DB),存储和管理数据的仓库,通过数据库管理系统(DBMS)操纵和管理数据库,借助SQL(操作关系型数据库的编程语言,定义了一套操作关系型数据库的统一标准)实现
MySQL数据库:
-
数据库的设计
MYSQL连接:mysql -u用户名 -p密码 [-h数据库服务器IP地址 -P端口号]
关系型数据库:建立在关系模型基础上,由多张相互连接的二维表组成的数据库-
MYSQL数据模型:内置一个DBMS,客户端通过SQL语句控制
-
SQL通用语法:
-
可以单行或者多行书写,以分号结尾
-
可以使用空格或缩进来增强语句可读性
-
sql语句不区分大小写
-
单行注释:-- (此处有一个空格)注释内容或者 # 注释内容(mysql特有),多行注释:/**/

-
-
DDL
- 查询:查询所有数据库:show databases,查询当前数据库:select database();
- 创建数据库:create database (if not exists)数据库名称;
- 切换数据库,使用数据库:use 数据库名称;
- 删除数据库:drop database 数据库名称;
- 表(增删查改)

- 约束:作用于表中字段上的规则,用于限制存储在表中的数据

aoto_incrment:主键值自动增长



!!!:删除表的时候,表中所有数据都会删除
- 约束:作用于表中字段上的规则,用于限制存储在表中的数据
-
数据类型
-
数值类型

-
字符串类型

-
日期时间类型

-
-
-
数据库的操作(database可以替换成schema)
-
添加数据(insert)

-
更新数据(update)


-
删除操作(delete)


-
DQL:查询数据库表中的记录



- count:1.count(字段) 2.count(常量) 3.count(*)
- 聚合函数不对null值进行计算

- where和having的区别:
- 执行时机不同,where是在分组之前进行过滤,不满足where条件,不参与分组,而having是分组之后对结果进行过滤。
- 判断条件不同,where不能对聚合函数进行判断,而having可以。
- 注意事项:分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无意义。执行顺序:where>聚合函数>having。

- 分页查询:select 字段列表 from 表名 limit 起始索引(从哪条数据开始查询),查询记录数(每页展示的查询记录数);

- 多表设计:
- 一对多:部门对员工,利用外键约束建立起两张表之间的联系



- 一对一:用户与身份证信息的关系 关系:一对一关系,用于多表拆分,将一张表的基础字段放在一张表中,其他字段放在另一张表中,提升操作效率。
实现:在任意一方加入外键,关联另一方的主键,并且设置外键为唯一的

- 多对多:学生与老师,学生与课程。实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
-
多表查询:
- 内连接:查询的是两张表的交集部分
隐式内连接(经过测试,也是自然连接):select 字段列表 from 表1, 表2 where 条件 ...;
显示内连接(就是自然连接):select 字段列表 from 表1[inner] join 表 2 on 连接条件;
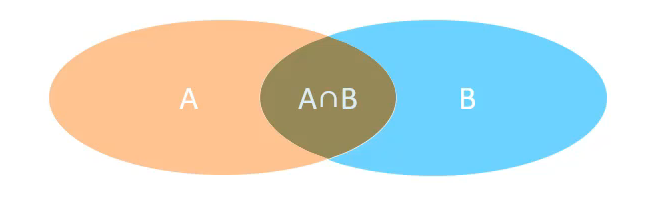
- 外连接:除了交集部分还包括左右部分(取决于什么连接方式)
左外连接:select 字段列表 from 表1 left [outer] join 表2 on 连接条件 ...;
右外连接:select 字段列表 from 表1 right [outer] join 表2 on 连接条件 ...; - 子查询:
SQL语句中嵌套select语句,称为嵌套查询,又称子查询
形式:select * from t1 where column1 = (select colum1 from t2 ...);
子查询外部的语句可以是insert/update/delete/select 的任何一个,最常见的是select。

标量子查询:返回的结果是单个值(数字,字符串,日期等),最简单的形式 ,常见操作符:=,<>,>,>=,<,<=
列子查询:子查询返回结果为一列(可以是多行),常用操作符:in,not in等
行子查询:返回结果是一行(可以是多列),常用的操作符:=、<>,in,not in
表子查询:子查询返回的结果是多行多列,常作为临时表,常用的操作符:in - 内连接:查询的是两张表的交集部分
-
事务:是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
- 注意事项:默认MYSQL的事务是自动提交的,也就是说,当执行一条DML语句,MYSQL会立即隐式地提交业务。
- 四大特性(ACID)
- 原子性:事务是不可分割的最小单元,要么全部成功,要么全部失败。
- 一致性:事务完成时,必须使所有数据都保持一致状态
- 隔离性:数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行
- 持久性:事务一旦回滚,他对数据库中的数据的改变就是永久的。
- 注意事项:默认MYSQL的事务是自动提交的,也就是说,当执行一条DML语句,MYSQL会立即隐式地提交业务。
-
-
数据库优化
- 索引:帮助数据库高效获取数据的数据结构
-
优点:提高数据查询的效率,降低数据库的I/O成本。
通过索引列对数据进行排序,降低数据排序的成本,降低cpu消耗。 -
缺点:索引会占用存储空间
索引大大提高了查询效率,同时却也降低了insert,update,delete的效率。 -
结构:Hash索引,B+Tree索引,Full-Text索引等,默认用B+Tree结构组织的索引。之所以不采用二叉搜索树或红黑树,是因为大数据情况下,层级深,检索速度慢。它们只有两个子节点。
- B+Tree(多路平衡搜索树)
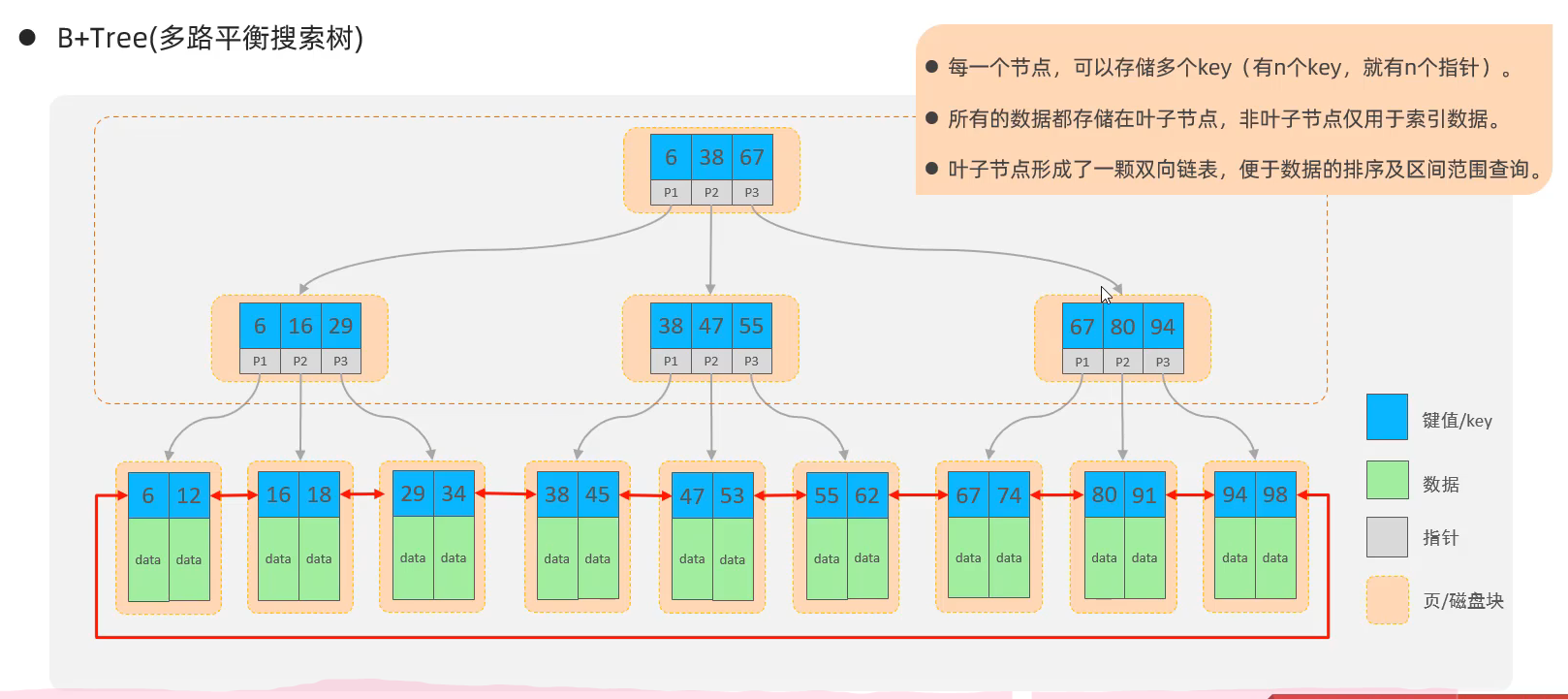
- B+Tree(多路平衡搜索树)
-
语法:

若是指定了主键,就自动创建了索引,而且主键索引的性能是最高的。
若是建立了唯一约束,也是建立了唯一索引。
-
- 索引:帮助数据库高效获取数据的数据结构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号