吴恩达机器学习-第三课-第一周
吴恩达机器学习
学习视频参考b站:吴恩达机器学习
本文是参照视频学习的随手笔记,便于后续回顾。
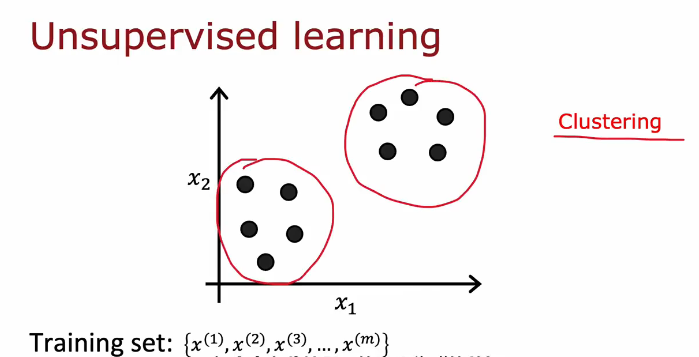
无监督学习
聚类算法(Clustering algorithm)
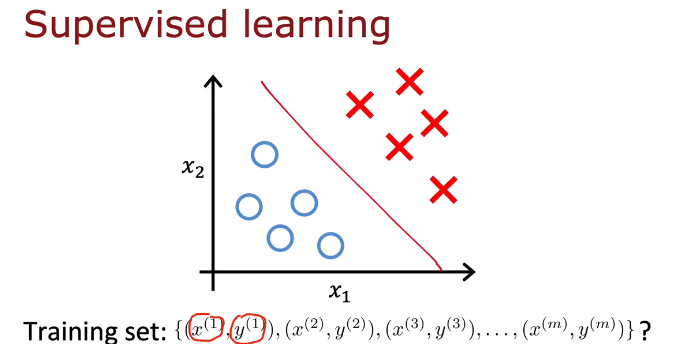
监督学习下
无监督学习下
聚类算法看看能不能给数据分组
聚类算法的一些例子:
相似新闻分组、市场分割、DNA数据分析、太空数据分析

K-means algorithm(Clustering)
算法步骤
K-means算法只做两件事
1.将点分配给集群质心
2.移动集群质心
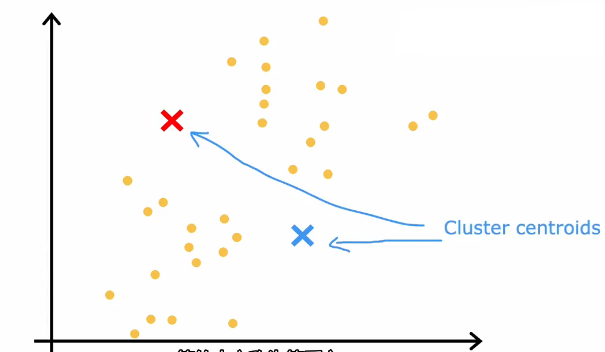
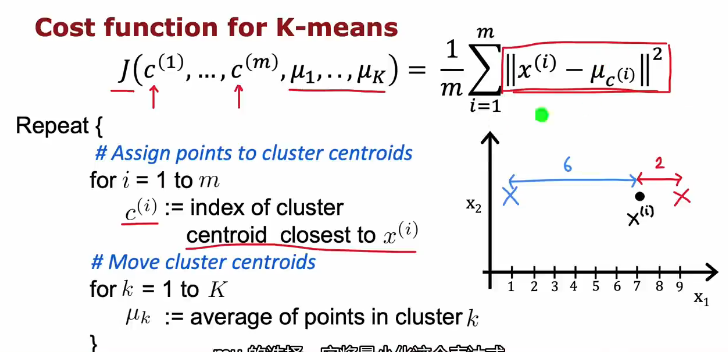
首先随机猜测两个集群分类的中心,像是下面红蓝叉号,中心叫做簇质心
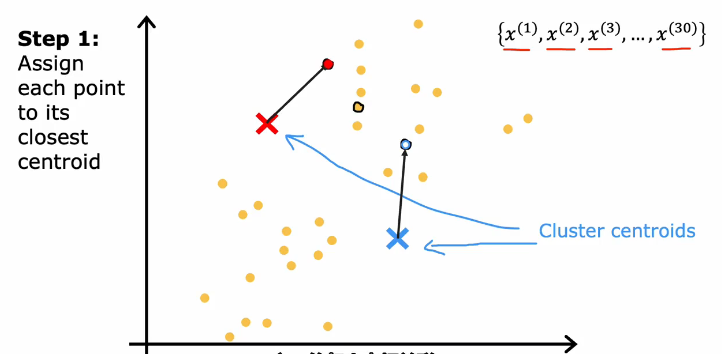
遍历所有点,发现是否靠近红簇质心或者蓝簇质心,将每一个点都分配给接近的簇质心
查看所有红点的平均值,将红簇质心移动到那里,蓝簇质心也相似
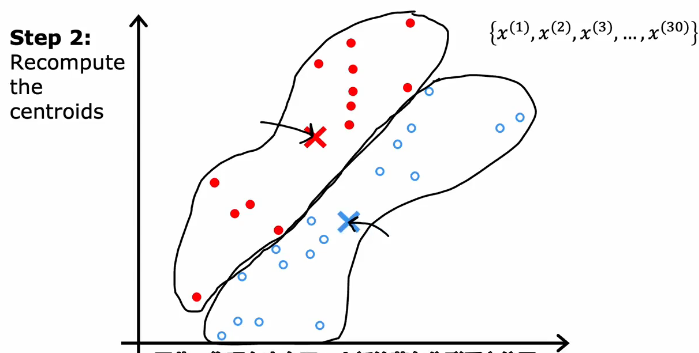
然后再进行第一步,分配点给簇质心,再移动簇质心
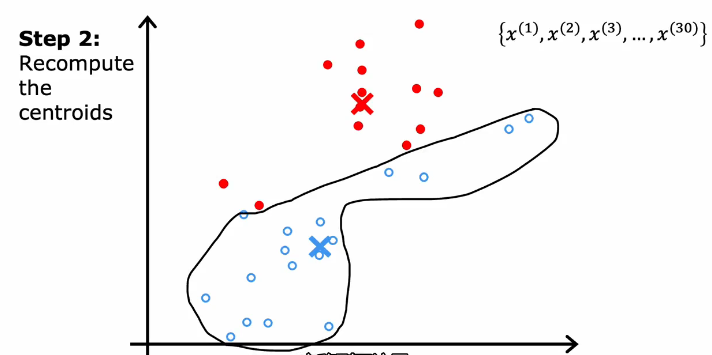
循环这两个步骤,最后簇质心位置不再变化,收敛
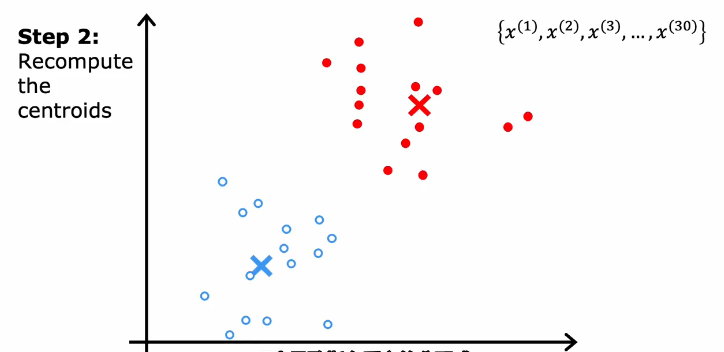
算法实现
1.首先随机n个质心(这些点和训练数据的维度一样)
2.分配点给簇质心(通过L2范数求点最小值分配给簇质心,接近哪个点就设置Cn为哪个点的值像是下图的1或2)
3.移动簇质心(求点的平均值)
4.重复2.3直到簇质心未知不再变化


如果分配给一个簇质心的点为0,那么最好消除这个簇质心,减少一个聚簇,像是下图

像是分配SML尺码
优化目标(optimization objective)
C(i)是指每个点分配给簇质心相对应的值
μk指的是簇质心(没被分配时)
μc(i)指的是被分配给相邻点的簇质心(分配点给簇质心后)
代价函数又称失真函数(Distortion)

如果想让这个L2范数最小化,就要将点分配给最近的簇质心
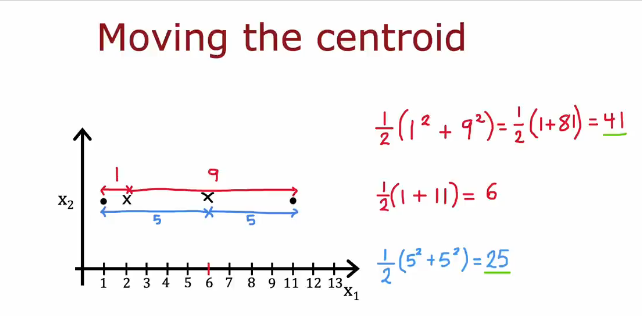
移动簇质心
K-means算法在优化失真函数J,让它保持收敛,在每次循环让它保持不变或下降
初始化K-means(随机猜测簇质心)

m为训练数据点,K为K个簇质心
一种初始化方法是:随机取K个点,将它们作为簇质心点的位置

这样的话选的随机点不同,导致的分类也不同(陷入局部最小值),可以通过多次聚簇,选择其中失真函数值J最小的作为最终结果
算法实现
一般运行次数不要超过1000次,收益会递减,至少尝试50次

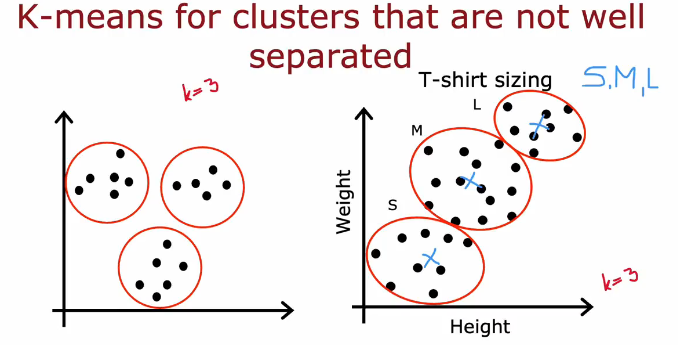
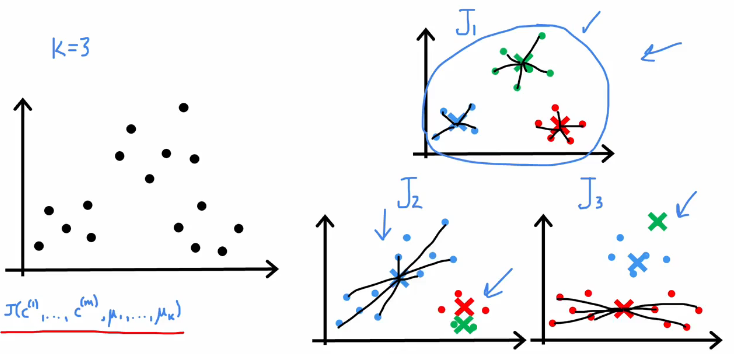
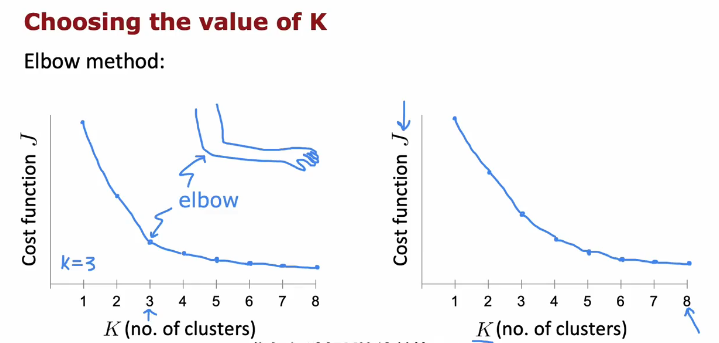
如何选择聚簇数量K
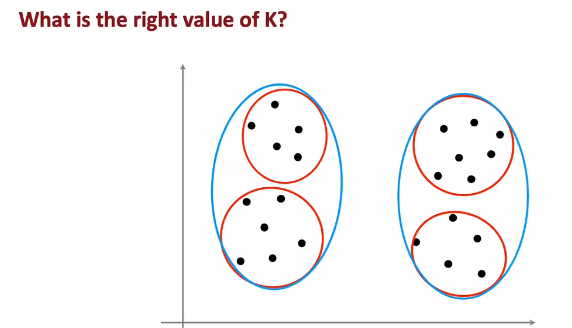
运行多个K值的聚簇来绘制成本函数曲线,肘(elbow)法选择K数量
但是某些应用不适用肘法
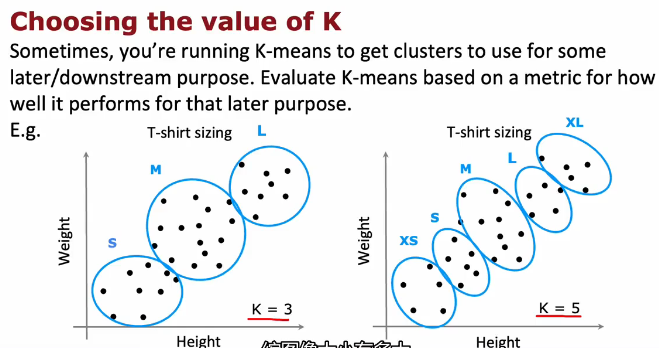
如果有多个聚簇数量,每一个都看起来可以,可以通过看拟合情况,看额外成本,看是否对业务更好,更简单更便宜
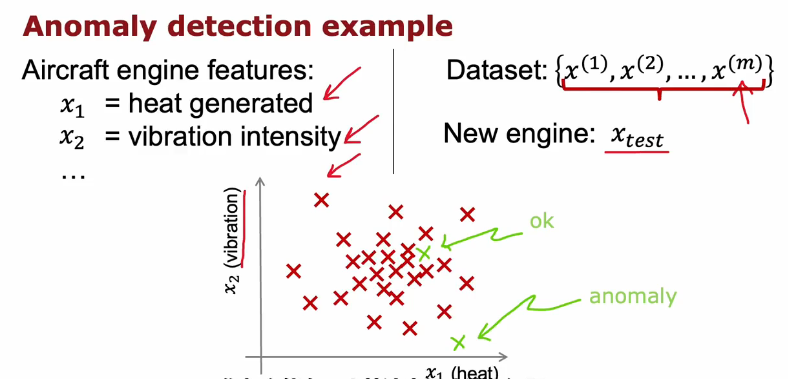
异常检测(Anomaly Detection)
密度估计技术(Density estimation)
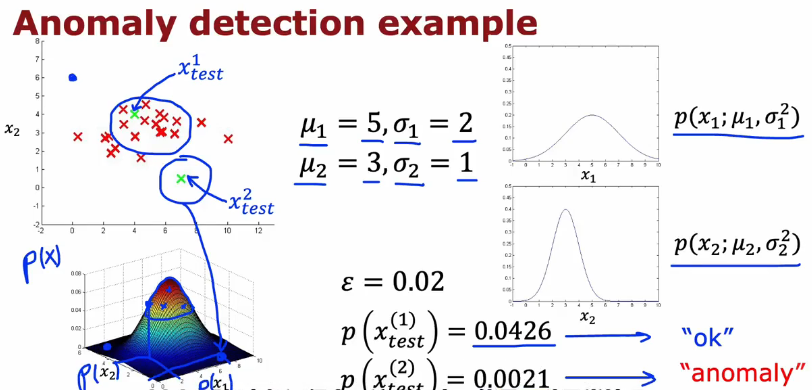
异常检测示例:
给出正常的发动机数据集,判断Xtest中的数据是否与数据集相似,不相似说明有问题(异常)
使用密度估计技术来实现上面的示例:
1.要为x的概率建立模型,判断什么时候概率高,什么时候概率低(像是下图,圆越大概率越低)
2.判断Xtest的概率,如果小于ε,说明概率很小,异常(Flag anomaly),反之正常

异常检测经常用在欺诈检测,通过观察用户使用时的各种数据的记录来对用户的典型行为进行建模。如果数据异常时不是直接关闭连接,而是通过验证,像是手机验证码来验证身份。
也用来金融,像是不寻常的购买
或者用来装置异常检测,像是上面的飞机发动机案例
再就是用来检测数据中心中电脑的异常行为等等

高斯正态分布(Gaussian (Normal) Distribution)
正态分布(高中或概率论学过)
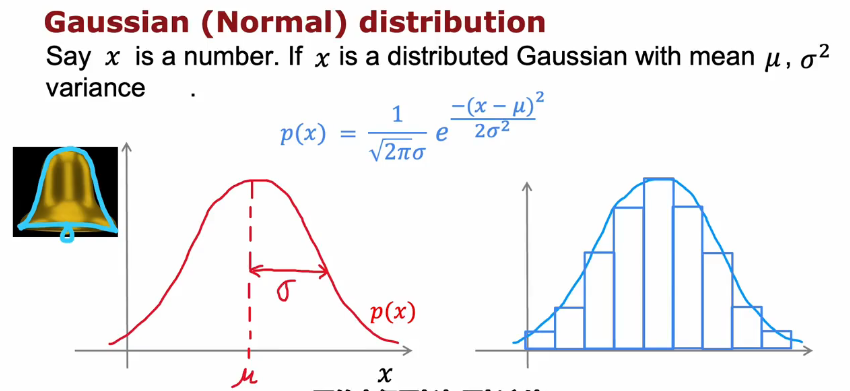
平均值μ、标准差σ变化与图形变化
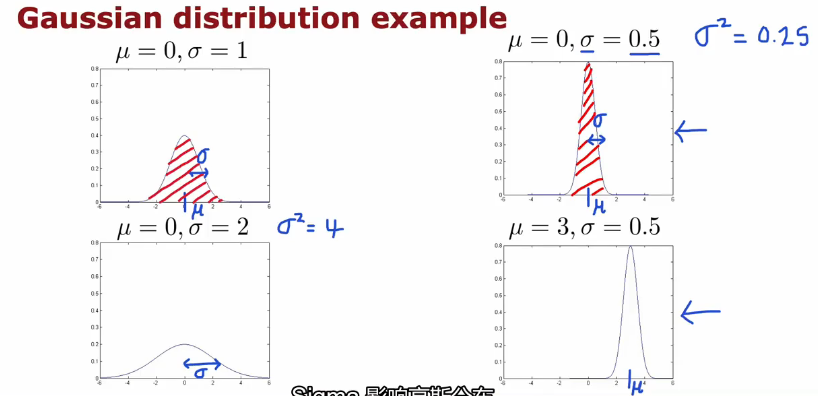
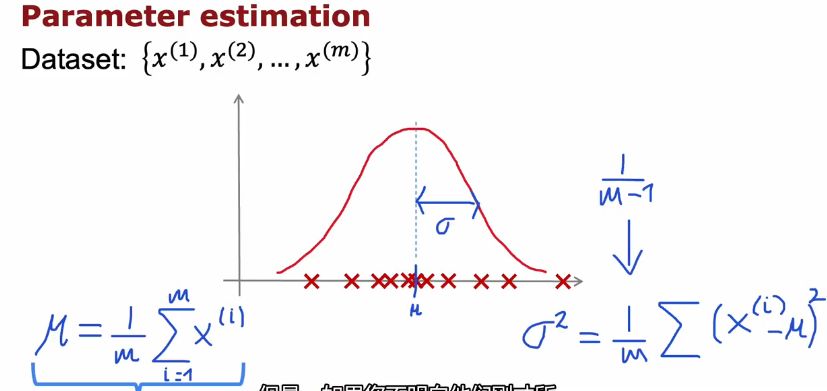
数据集中正态分布及μ、σ赋值
1/m和1/(m-1)没什么区别,一般是1/m
异常检测算法(algorithm)
训练集中每一个X(m)都包含n个特征的值
p(x)就是求每一个特征的概率相乘

异常检测算法步骤:
1.选择n个特征值可能是异常的预示
2.计算每个特征值的平均值和方差(正态分布)
3.计算新示例x的p(x),看看是大是小,如果小于ε说明异常

开发和评估异常检测系统(Developing and evaluating)
y=0为正常,y=1为异常
在验证集和测试集增添一些异常数据

飞机发动机示例:
通过在数据集中添加一些异常数据来调整选择合适的ε,以更好的拟合模型
如果没有测试集,并且异常数据只有2个,就全部放到验证集,不过这样只是数据集小时相对较好

算法评估步骤:
通过数据集拟合模型,p(x)≥ε时y=0正常,p(x)<ε时y=1异常
正常数据少,异常数据多时可以通过之前学过的评估标准提高分类准确性

异常检测与监督学习的对比
为什么异常检测都给异常分类了y=0/1而不用监督学习呢?
什么时候用异常检测:
1.正常数据非常少,异常数据非常多时
2.有很多不同的异常类型,算法很难从正常数据学到异常是什么样
什么时候用监督学习:
1.非常多的正常和异常的数据
2.有足够多的正常示例让算法学习什么是正常,预测正常的示例可能和训练集中的某一些数据相似

选择使用什么特征(choosing what features to use)
通过plt.hist绘制图像
1.看看特征是否像高斯曲线,如果像那就很好,如果不像就通过某些方法将其转换成像是高斯曲线
例如下图的转换方法
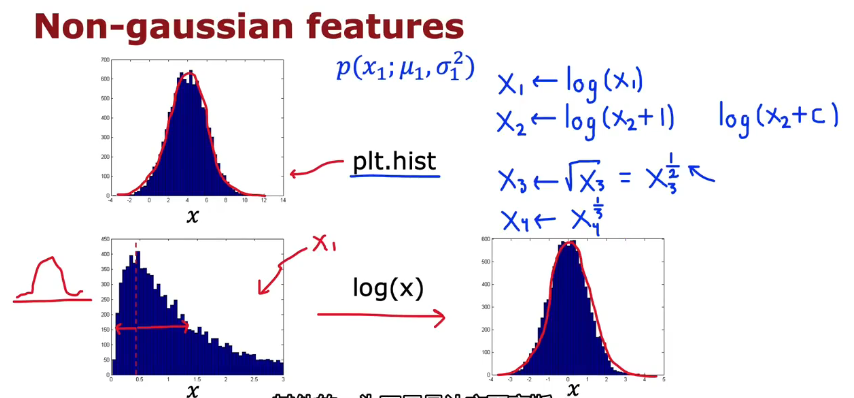
2.如果某个异常和正常数据集的概率相差不大,可以去寻找为什么这个数据被标签为异常,如果能识别出一些新特征,这就有助于将这个异常与正常数据区分开
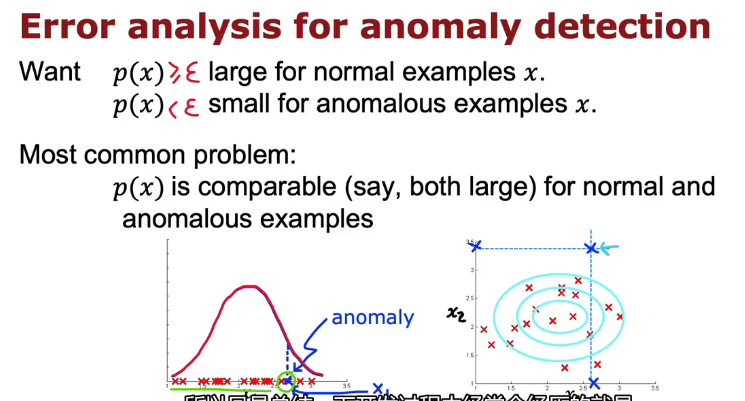
检测数据中心计算机的示例:

Summary
本周主要学了以下内容
1.介绍了无监督学习的两类算法:聚类算法和异常检测
2.聚类算法:K-means算法的步骤、实现和优化,初始化簇质心,如何选择聚簇的数量
3.异常检测:密度估计技术,高斯正态分布,异常检测的算法,算法评估,与监督学习的对比,选择使用什么特征

 浙公网安备 33010602011771号
浙公网安备 33010602011771号