
计算机组成与体系结构(6分)
软件的可靠性:是指一个系统在给定时间间隔内和给定条件下无失效运行的概率。软件的可用性:是指软件在特定使用环境下为特定用户用于特定用途时所具有的有效性。
软件的可维护性:是指与软件维护的难易程度相关的一组软件属性。
软件的可伸缩性:是指是否可以通过运行更多的实例或者采用分布式处理来支持更多的用户。
计算机的基本存储单位
从小到大依次是:位(bit)、字节(byte)、千字节(KB)、兆字节(MB)、吉字节(GB)等。下面我来简单介绍一下它们:
-
位(bit):这是计算机存储的最小单位,也叫二进制位或比特,它只能表示0或1这两种状态。
-
字节(byte):字节是常用的计算机存储单位,1字节等于8位。1字节可以表示256种不同的状态或数值,这对于表示字符、数字等基本信息已经足够了。
-
千字节(KB):1KB等于1024字节。这个单位常用于表示较小的文件或数据块。
-
兆字节(MB):1MB等于1024KB。这个单位常用于表示中等大小的文件,比如图片、音频文件等。
-
吉字节(GB):1GB等于1024MB。这个单位常用于表示较大的文件或存储设备容量,比如视频文件、硬盘、U盘等。
数据的表示--进制

权值相加法
二进制转十进制
从右往左 0b111 = 1 * 20+ 1 * 21 + 1 * 22 = 1+2+4
八进制转十进制
从右往左 0111 = 1 * 80 + 1 * 81+ 1 * 82= 1+8+64
十六进制转十进制
从右往左 0x111 = 1 * 160 + 1 * 161+ 1 * 162= 1+16+256
除基取余法
十进制转二进制
规则:将该数不断除以2,直到商为0为止,然后将每部得到的余数倒过来
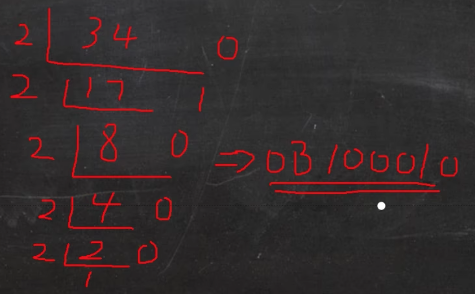
十进制转八进制
规则:将该数不断除以8,直到商为0为止,然后将每部得到的余数倒过来
十进制转十六进制
规则:将该数不断除以16,直到商为0为止,然后将每部得到的余数倒过来
其他
二进制转八进制
规则:从右往左,将二进制每3位一组,转成对应的八进制
0b11(3)010(2)101(5) => 0325
二进制十六进制
规则:从右往左,将二进制每4位一组,转成对应的十六进制
0b1101(D)0101(5) => 0xD5
八进制转二进制
规则:从右往左,将八进制每1位,转成对应的3位二进制
02(010)3(011)7(111) => 0b0010011111
十六进制二进制
规则:从右往左,将十六进制每1位,转成对应的4位二进制
02(0010)3(0011)B(1011) => 0b001000111011
数据的表示--整数
(1) 无符号整数(Unsigned Integer)
-
所有位表示数值,范围:0 到 2ⁿ−1(n 为位数)。
-
示例:8 位无符号整数范围:0 ~ 255(2⁸−1)。
(2) 有符号整数(Signed Integer)
-
原码:最高位表示符号(0 正,1 负),其余位表示数值。
-
问题:存在 +0 和 -0,计算复杂。
-
-
反码:正数:与原码相同。负数:符号位不变,数值部分取反。
-
示例:-5 在 8 位反码中表示为
11111010。
-
-
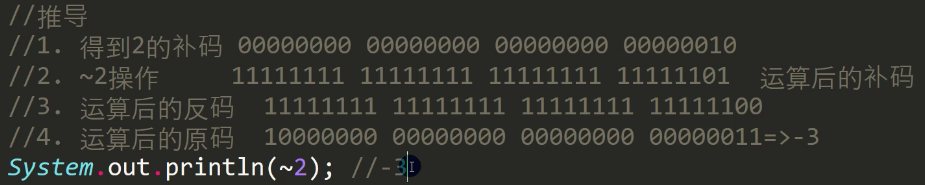
补码(最常用):为了解决正数负数计算
-
正数:与原码相同。 负数:反码 + 1。
-
优点:统一 +0 和 -0。加减法可直接运算,无需额外硬件。
-
示例:8 位补码范围:-128(
10000000) ~ 127(01111111)
-
在计算机中,n位补码(最高位符号位,n-1位数据位),表示范围是-2n-1 ~ +2n-1-1,其中最小值为人为定义,以n=8为例,其中-128的补码是人为定义的1000 0000

移码:在补码的基础上,符号位取反

数据的表示--浮点数
浮点数由三部分组成
-
符号位(Sign):1 位,
0表示正数,1表示负数。 -
指数位(Exponent):决定数值的范围,采用 偏移码(Excess-N) 表示。
-
尾数位(Mantissa/Significand):表示有效数字,隐含最高位
1(规范化形式)。
示例 :单精度浮点数 -12.375
-
转换为二进制:
-
整数部分:
12→1100 -
小数部分:
0.375→0.011(2-1 ×0 + 2-2 ×1+ 2-3 ×1) -
合并:
-12.375→-1100.011
-
-
规范化:
−1.100011×23-
符号位
S=1(负数) -
指数位
E=3 + 127 = 130→10000010(二进制) -
尾数位
M=100011(去掉隐含的1,补零到 23 位)→10001100000000000000000
-
-
最终表示(32 位):
1 10000010 10001100000000000000000
IEEE 754 两种常见格式
| 格式 | 总位数 | 符号位 | 指数位 | 尾数位 | 偏移量(Bias) |
|---|---|---|---|---|---|
| 单精度(float) | 32 位 | 1 位 | 8 位 | 23 位 | 127 |
| 双精度(double) | 64 位 | 1 位 | 11 位 | 52 位 | 1023 |
浮点数加(减)法操作流程
1 零操作数检查2 对阶操作 (阶码小改为大)
3 尾数加(减)运算
4 规格化及舍入处理。
计算机结构
程序计数器PC:存储下一条要执行指令的地址。指令寄存器IR:存储即将执行的指令,
主存地址寄存器MAR:用来保存当前CPU所访问的内存单元的地址。
状态条件寄存器PSW:存状态标志与控制标志,

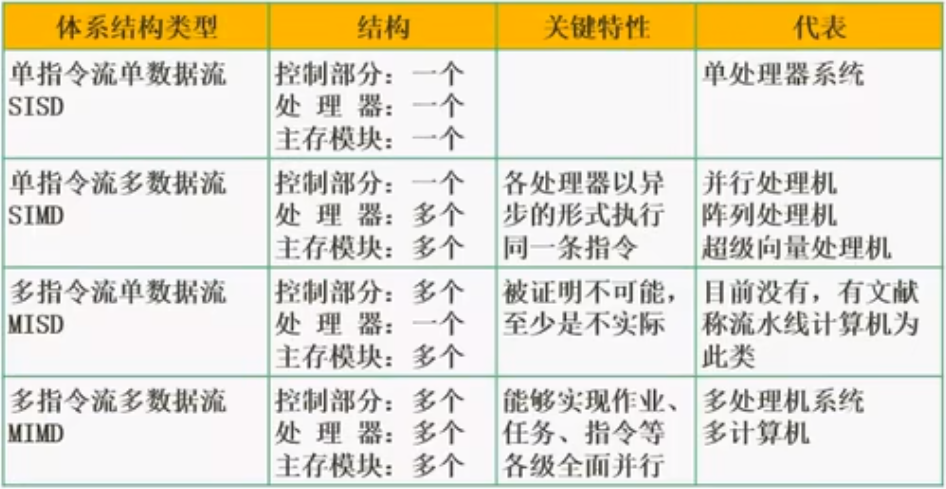
Flynn分类法
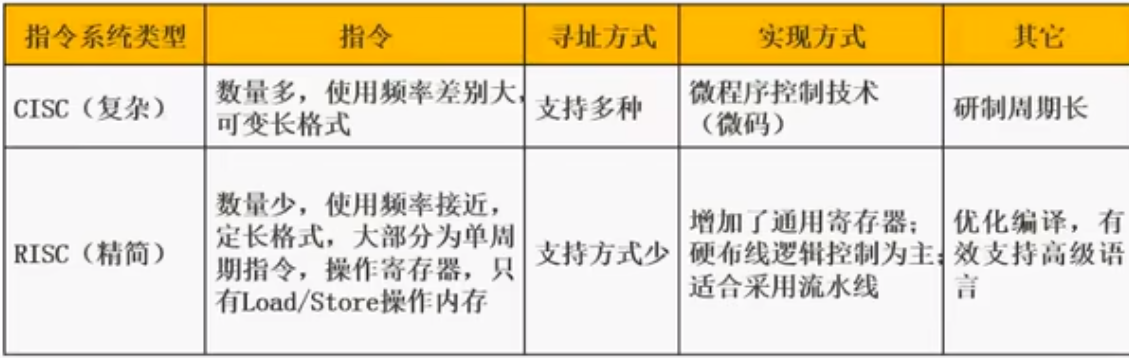
CISC与RISC
Complex Instruction Set Computing 以前电脑少,需要定制,所以指令都很复杂
Reduced Instruction Set Computer 现在电脑多了,需要通用,所以精简
寻址方式对比
1. 立即寻址(Immediate Addressing)最快
-
特点:操作数直接包含在指令中(常数)。
-
格式:
指令 操作数 -
优点:速度快(无需访存)。
-
缺点:仅适用于常量,灵活性低。
2. 寄存器寻址(Register Addressing)快
-
特点:操作数在寄存器中,无需访存。
-
格式:
指令 寄存器 -
优点:速度最快(CPU内部操作)。
-
缺点:寄存器数量有限。
3. 直接寻址(Direct Addressing)中
-
特点:指令中直接给出操作数的内存地址。
-
格式:
指令 [地址] -
优点:访问固定地址效率高。
-
缺点:地址空间受限(指令长度限制)。
4. 寄存器间接寻址(Register Indirect Addressing)中
-
特点:寄存器中存储的是操作数的内存地址。
-
格式:
指令 [寄存器] -
优点:适合处理数组或动态数据。
-
缺点:需额外访存操作。
5. 间接寻址 中
-
特点:指令中存放地址,这个地址存放操作数的地址。
-
格式:
指令 [地址] [地址]
流水线技术(考计算)
概念:流水线是指在程序执行时多条指令重叠进行操作的一种准并行处理实现技 术。
各种部件同时处理是针对不同指令而言的,它们可同时为多条指令的 不同部分进行工作,以提高各部件的利用率和指令的平均执行速度
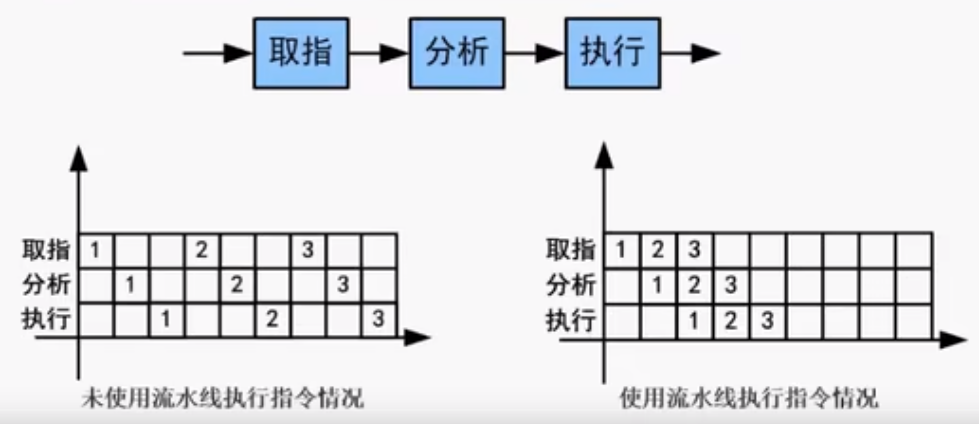
流水线计算 (先用理论公式,没有选项再用实际公式)

以上例子 k:分几段 n:指令数 流水线周期是2
流水线吞吐率
流水线的吞吐率(Though Put rate,TP)是指在单位时间内流水线所完成的 任务数量或输出的结果数量。
计算流水线吞吐率的最基本的公式如下:
 100/203
100/203
流水线最大吞吐率
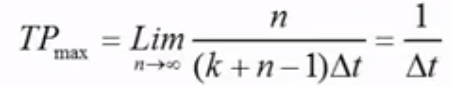 1/2 2是周期时间
1/2 2是周期时间
流水线的加速比
完成同样一批任务,不使用流水线所用的时间与使用流水线所用的时 间之比称为流水线的加速比。计算流水线加速比的基本公式如下:
 500/203 不使用流水线时间(2+2+1)*100=500
500/203 不使用流水线时间(2+2+1)*100=500
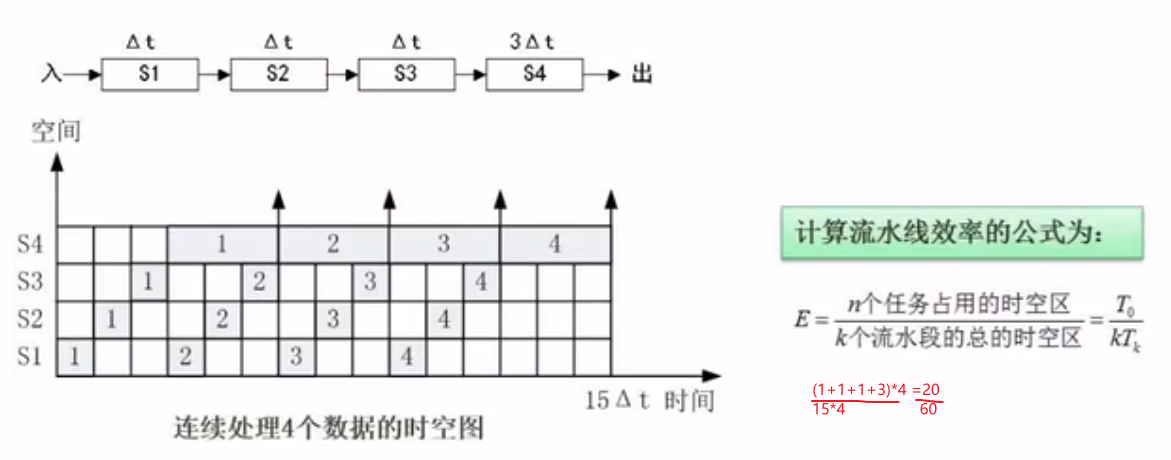
流水线的效率
流水线的效率是指流水线的设备利用率。在时空图上,流水线的效率定义为n个任务 占用的时空区与k个流水段总的时空区之比
存储系统
层次化存储结构
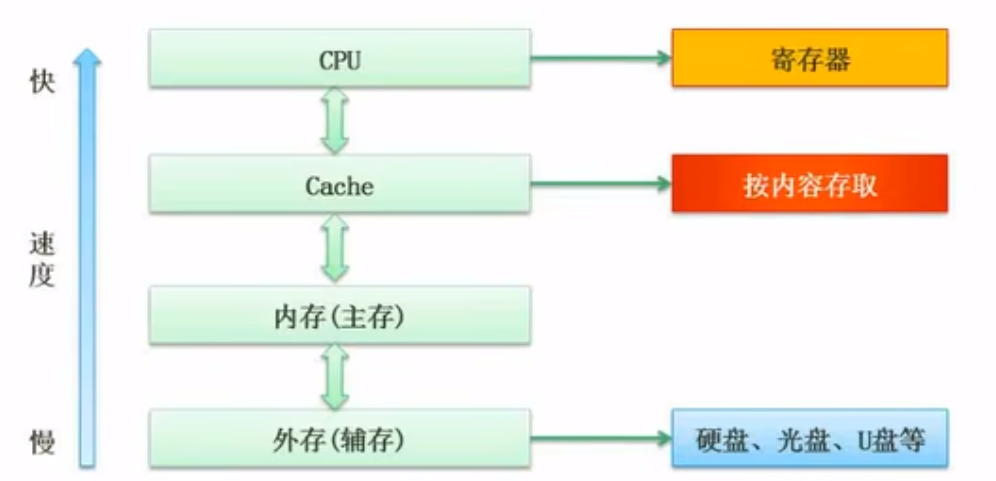
虚拟内存:主存+辅存
三级存储:cache+主存+辅存
DMA (直接内存访问)控制器
DMA 用于 外设(如硬盘、网卡)与主存之间的直接数据传输,无需 CPU 参与。
DMA 操作的是 主存的物理地址,因为:
- 外设(如硬盘)不识别虚拟地址或 Cache 地址。
- DMA 直接访问主存,绕过 CPU 和 Cache(避免缓存一致性问题)。
Cache(高速缓存)
- Cache的功能:提高CPU数据输入输出的速率,突破冯·诺依曼瓶颈,即CPU与存储 系统间数据传送带宽限制。
- 在计算机的存储系统体系中,Cache是访问速度最快的层次。
- 使用Cache改善系统性能的依据是程序的局部性原理。
- 在程序执行过程中,高速缓存(Cache)与主存间的地址映射由硬件自动完成

局部性原理
- 时间局部性
- 空间局部性
- 工作集理论:工作集是进程运行时被频繁访问的页面集合
Cache地址映射方式
Cache的地址映射方式决定了主存块(Block)如何放入Cache中,主要解决 主存地址 到 Cache地址 的转换问题。
| 映射方式 | 主存块放置规则 | 替换时机 | 硬件复杂度 | 优点 |
|---|---|---|---|---|
| 直接映射 | 固定Cache行(行号=块号%行数) | 同一行被占用时替换 | 低 | 硬件简单,访问速度快 |
| 全相联 | 任意Cache行 | Cache满时替换 | 高 | 冲突率最低 |
| 组相联 | 固定组,组内任意行(如2路组相联) | 组满时替换 | 中 | 是直接映射和全相联的折中方案 |
输入输出技术
I/O设备管理软件分为4层
用户程序:用户级I/O层:发出I/O调用。
设备无关I/O层:设备名解析、阻塞进程、分配缓冲区。
设备驱动程序:设置寄存器,检查设备状态。
中断处理程序:I/O完成后唤醒设备驱动程序。
硬件:完成具体的I/O操作。

I/O 数据传输方式
1. 程序控制 I/O(Polling)
-
原理:CPU 轮询设备状态寄存器,检查数据是否就绪。
-
特点:简单,但CPU利用率低(忙等待)。适用于低速设备(如早期键盘)。
2. 中断驱动 I/O
-
原理:设备就绪后向CPU发送中断信号,CPU暂停当前任务处理I/O。
-
特点:CPU无需轮询,效率高于Polling。中断处理开销可能影响实时性。
-
流程:
-
CPU启动I/O操作后继续执行其他任务。
-
设备就绪后触发中断。
-
CPU保存当前上下文(数据存在堆栈),执行中断服务程序(ISR)。
-
ISR完成数据传输后恢复原任务。
-
中断问量表: 中断向量表用来保存各个中断源的中断服务程序的入口地址。
当外设发出中断请求信号以后,由中断控制器确定其中断号,并根据中断号查找中断向量表来取得其中断服务程序的入口地址,同时NTC把中断请求信号提交给CPU。
3. 直接内存访问(DMA)
-
原理:由 DMA控制器 直接管理设备与内存间的数据传输,无需CPU介入。
-
特点:
-
大幅减少CPU负担,适合高速设备(如磁盘、显卡)。
-
需要硬件支持(DMA控制器)。
-
-
流程:
-
CPU初始化DMA(源地址、目标地址、数据长度)。
-
DMA控制器接管总线,直接读写内存。(传输一个数据需要一个总线周期)
-
传输完成后,DMA向CPU发送中断通知。
-
4. 通道控制 I/O(硬件)
-
原理:专用I/O处理器(通道)独立管理多个设备,进一步解放CPU。
-
特点:用于大型机(如IBM的通道子系统)。成本高,通用计算机较少使用。
为什么DMA比中断驱动更高效?
-
DMA:数据传输无需CPU参与,仅结束时通知CPU。
-
中断驱动:每次数据单元传输均需CPU介入。
主存-分类
DRAM:动态随机存储器,一般用于内存,需要不断地刷新电路,否则数据就消失了。
SRAM:随机存取存储器的一种。这种存储器只要保持通电,里面储存的数据就可以恒常保持
EPROM:一种断电后仍能保留数据的计算机储存芯片即非易失性的(非挥发性)。
EEPROM:指带电可擦可编程只读存储器。是一种掉电后数据不丢失的存储芯片
闪存(Flash Memory):
- 是一种长寿命的非易失性(在断电情况下仍能保持所存储的数据信息)的存储器。数据删除以固定的区块为单位,区块大小一般为256KB到20MB,
- 闪存是电子可擦除只读存储器(EEPROM)的变种EEPROM,与闪存不同的是,它能在字节水平上进行删除和重写而不是整个芯片擦写,这样闪存就比EEPROM的更新速度快。
- 闪存不像RAM(随机存取存储器)一样以字节为单位改写数据,因此不能取代RAM,也不能替换主存,但是在嵌入式中,可以用闪存代替ROM存储器

主存-编址
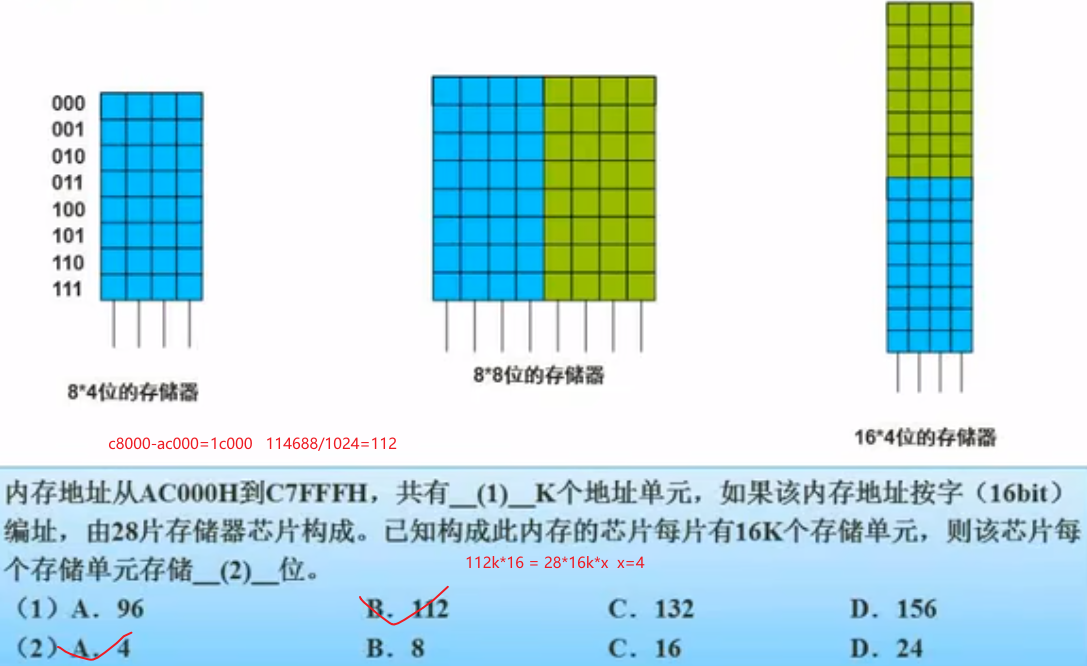
磁盘结构与参数
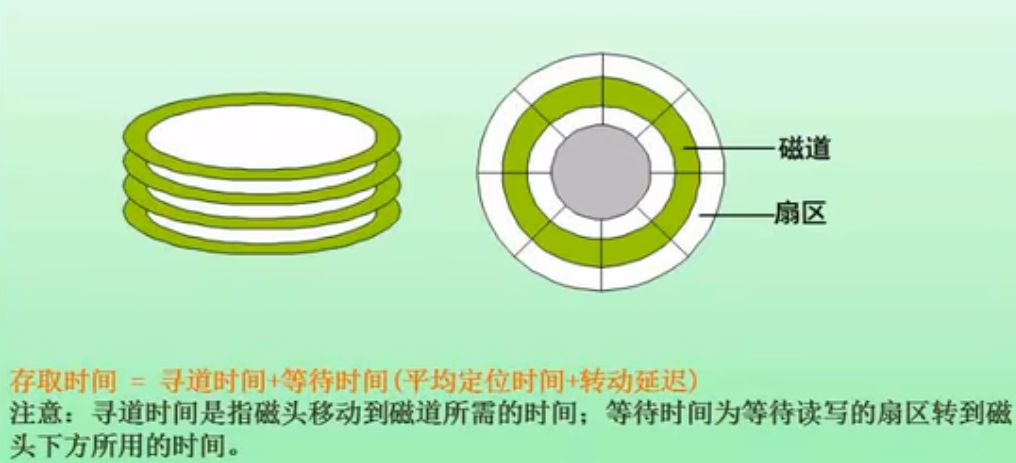
存取时间 = 寻道时间 + 旋转时间 + 处理时间
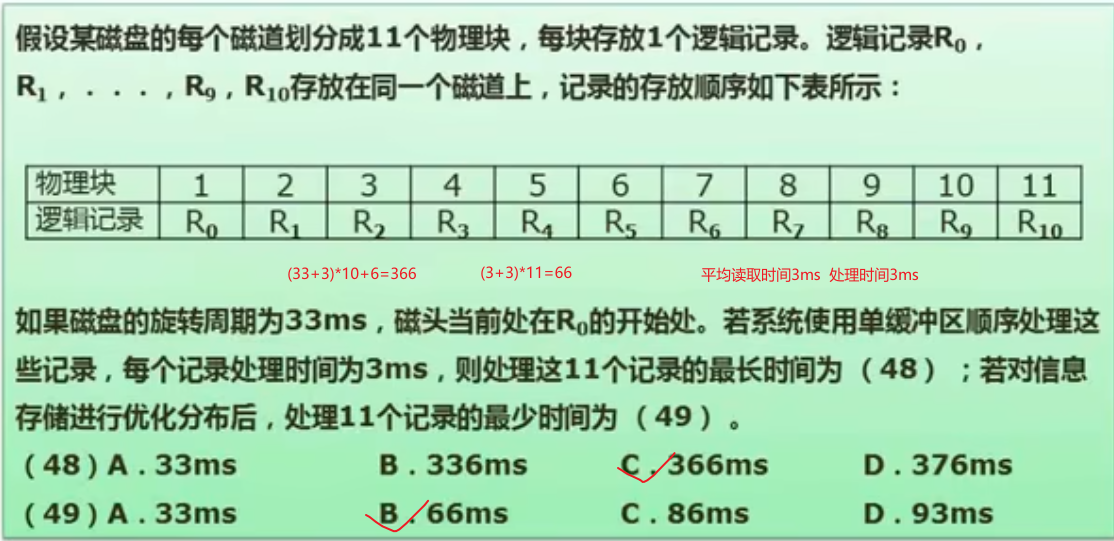
试题
总线系统
根据总线所处的位置不同,总线通常被分成三种类型,分别是:
内部总线:芯片与处理器之间
系统总线:CPU、主存、I/O设备各大部件之间的信息传输线
控制总线:传输数据 地址总线:内存超过4G用64位的系统 数据总线
外部总线:微机和外部设备之间
通讯总线:用于计算机系统之间或与其他系统之间的通信。
1. 并行总线(Parallel Bus)(先)
工作原理:数据通过多根信号线并行传输(如8/16/32位同时发送),传统IDE、SCSI采用此方式。
核心特点:多信号线,同步时钟,低频率。
优势:理论带宽高(早期优于串行总线)。协议简单,延迟低(无需编码/解码)。适合近距离传输
劣势:信号同步困难,高频下易串扰。布线复杂(需等长处理),成本高。
典型应用:旧式设备:IDE硬盘、打印机(LPT)、早期内存总线(SDRAM)。特定场景:FPGA片内总线(AXI)、工业控制(VME总线)。
2. 串行总线(Serial Bus)(后)
工作原理:数据按单比特流依次传输,通过一根或少量信号线传递信息(如USB、PCIe、SATA)。
核心特点:信号线少,高频时钟, 抗干扰强
优势:布线简单,成本低(减少PCB层数)。支持长距离传输(如USB 3.0可达5米)。扩展灵活(通道可叠加,如PCIe x16)。
劣势:需串并转换,协议开销略高。
典型应用:高速外设:显卡(PCIe)、SSD(NVMe)、显示器(DisplayPort)。通用接口:USB、Thunderbolt、以太网(RJ45)。
| 特性 | PCI总线 | SCSI总线 |
|---|---|---|
| 设计目标 | 通用外设扩展(显卡、网卡) | 高性能存储设备(硬盘、磁带机) |
| 传输方式 | 并行 | 并行 |
| 带宽 | 最高1.06 GB/s(PCI-X) | 最高320 MB/s(Ultra320 SCSI) |
| 设备连接数 | 通常4-5个(共享带宽) | 最多16个(含控制器) |
| 热插拔 | 不支持 | 部分支持 |
| 典型应用 | 显卡、扩展卡 | 硬盘阵列、扫描仪 |
| 后继技术 | PCIe(串行,更高带宽) | SAS(串行,兼容SCSI指令集) |
系统可靠性分析
系统可靠性指 系统在规定条件下和时间内,持续正确执行预期功能的能力,是衡量计算机系统、网络或软件稳定性的核心指标。其设计涵盖硬件冗余、容错机制、故障预测与恢复等多方面技术。
| 指标 | 定义 | 计算公式 |
|---|---|---|
| MTTF(平均无故障时间) | 系统两次故障间的平均时间 | 总运行时间 / 故障次数 |
| MTTR(平均修复时间) | 修复故障所需的平均时间 | 总修复时间 / 故障次数 |
| MTBF(平均失效间隔) | 系统周期性运行至故障至故障处理的全程时间段的平均值 | MTBF = MTTF+ MTTR |
| 可用性(Availability) | 系统可用的时间比例 |
|
系统可靠性是系统正常运行的概率,通常用R=MTTF / (MTTF + 1)
可用性 MTBF/ (MTBF+1)
串联系统:走通,只有一种情况也就是每个部件都有效
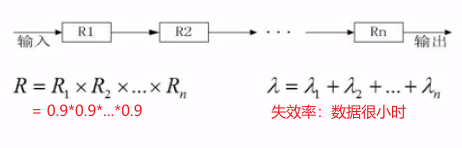
并联系统:走通情况有很多种,走不通的情况只有一种,即每个部件都无效
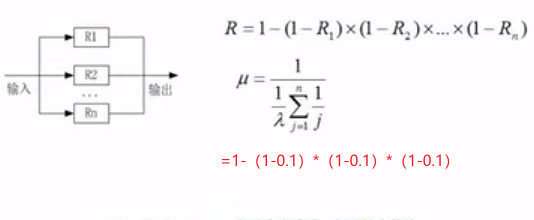
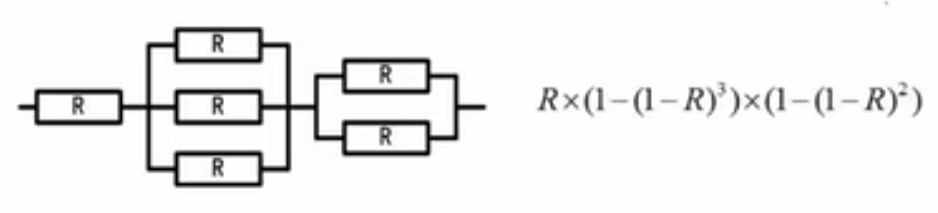
模冗余系统与混合系统
差错控制-CRC与海明校验码
码距
一个编码系统的码距是整个编码系统中任意(所有)两个码字的最小距离。例:
- 若用1位长度的二进制编码。若A=1,B=0。这样A,B之间的最小码距为1。
- 若用2位长度的二进制编码,若以A=11,B=00为例,A、B之间的最小码距为2。
- 若用3位长度的二进制编码,可选用111,000作为合法编码。A,B之间的最小码距为3。
校验码


海明校验码

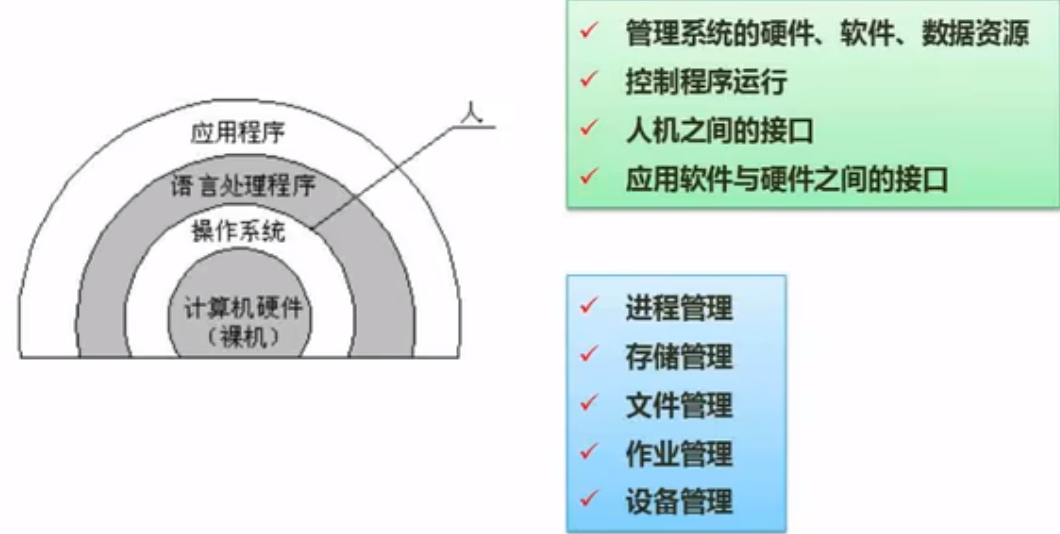
操作系统基本原理
概述
| 网络操作系统 | 方便有效共享网络资源,提供服务软件和有关协议的集合 主要的网络操作系统有:Unix、Linux和Windows Server系统 |
| 分布式操作系统 | 任意两台计算机可以通过通信交换信息 是网络操作系统的更高级形式,具有透明性、可靠性和高性能等特性 |
| 微机操作系统 | Windows: Microsoft开发的图形用户界面、多任务、多线程操作系统 Linux: 免费使用和自由传播的类Unix操作系统,多用户、多任务、多线程和多CPU的操作系统 |
| 嵌入式操作系统 |
运行在智能芯片环境中 特点:微型化、可定制(针对硬件变化配置)、实时性、可靠性、易移植性(HAL和BSP支持) |
核心-进程管理
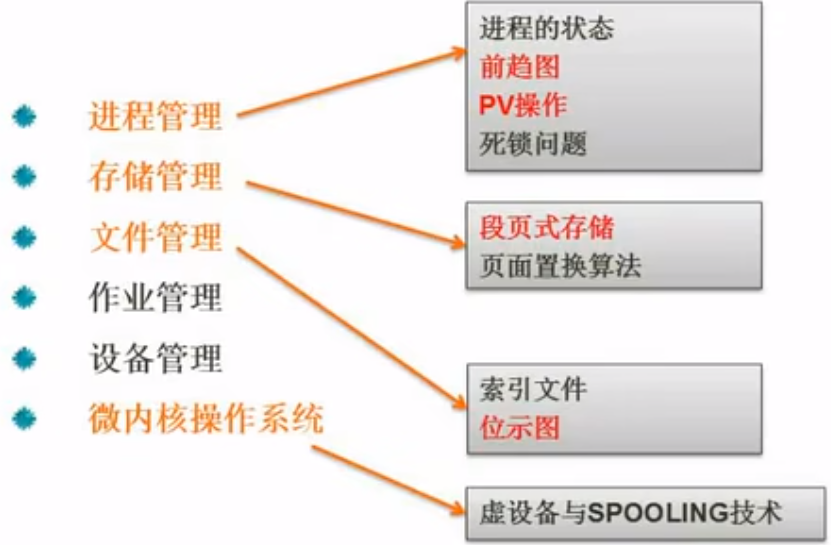
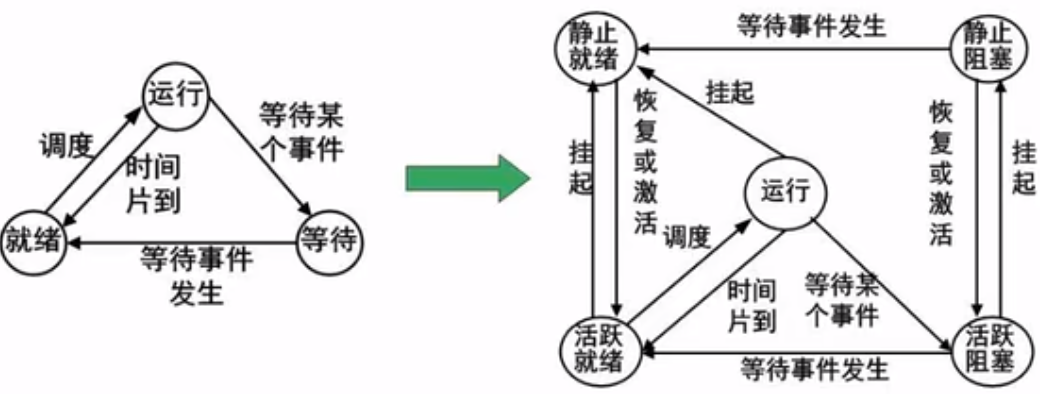
进程管理-进程的状态
等待 需要有io或者外设的输入 , 就绪则是等待cpu的调度
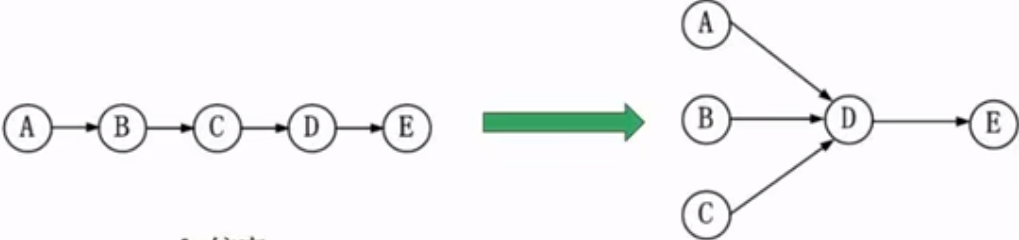
进程管理-前趋图
用来表示任务并行或串行执行关系,任务之间顺序关系
进程管理-同步和互斥
同步和互斥是操作系统中用于管理多个任务对共享资源的访问的概念。
互斥是指在同一时间内,只有一个任务可以访问临界资源。这意味着在一个任务访问临界资源时,其他任务必须等待,直到访问完成才能继续执行。互斥通常通过加锁(lock)和解锁(unlock)机制实现。
同步是指多个任务可以并发执行,但在某些情况下需要进行协调和等待。通过信号量(semaphore)、条件变量(condition variable)等机制来实现。
临界资源是指多个任务需要以互斥方式访问的共享资源。
临界区则是指程序中对临界资源进行操作的那段代码。
信号量:是一种特殊的变量
因此,同步和互斥是为了确保对临界资源的正确访问而采取的不同策略。同步主要解决任务之间的协调和通信问题,而互斥则解决多个任务对共享资源访问的争用问题。
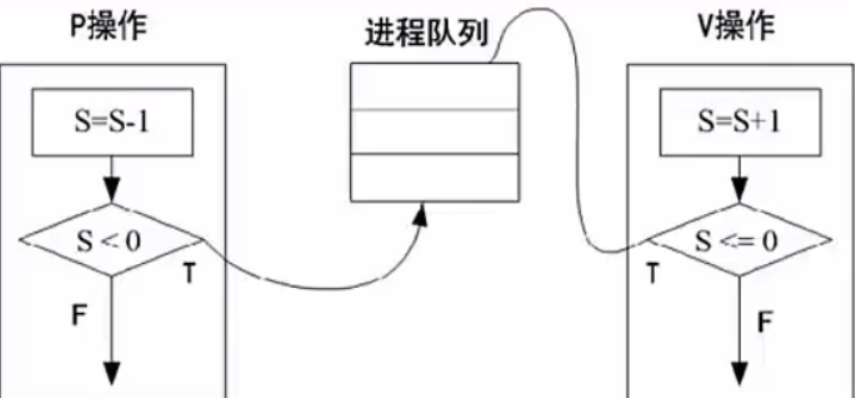
进程管理-pv操作(重要)
P操作(Passeren通过–荷兰语):申请资源,S=S-1,若s>=0,则执行P操作的进程继续执行;若S<0,则置该进程为阻塞状态(因为无可用资源),并将其插入阻塞队列。
V操作(Vrijgeven释放–荷兰语):释放资源,S=S+1,若s>0,则执行V操作的进程继续执行;若s<=0,则从阻塞状态唤醒一个进程,并将其插入就绪队列(此时因为缺少资源被P操作阻塞的进程可以继续执行),然后执行V操作的进程继续。
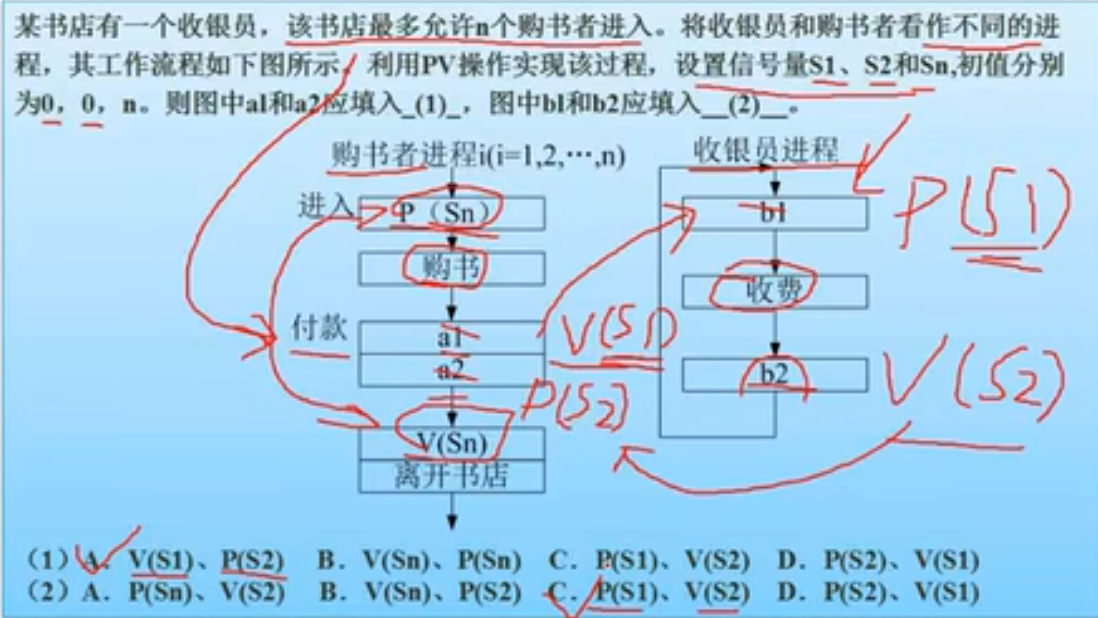
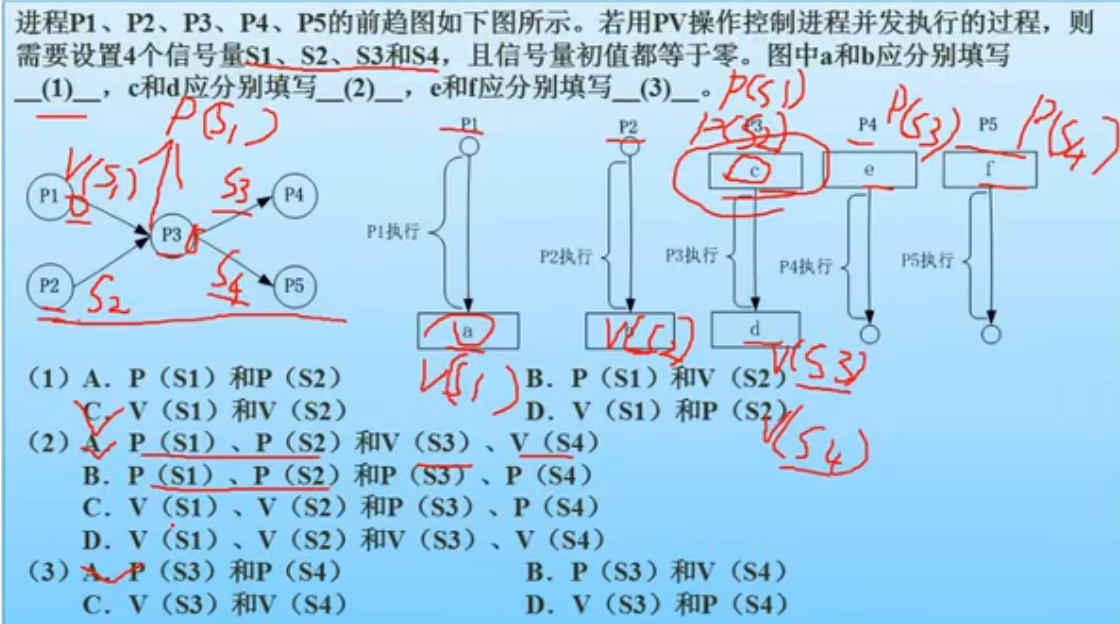
进程管理-死锁(考察不多)
当一个进程在等待永远不可能发生的事件时,就会产生死锁,若系统中有多个进程处于死锁状态,就会造成系统死锁。
死锁四个必要条件: 资源互斥,每个进程占有资源并等待其他资源,系统不能剥夺现场资源,进程资源图是一个环路
死锁避免: 打破4个条件:有序资源分配法,一般采用银行家算法来避免
银行家算法,就是提前计算出一条不会死锁的资源分配方法,才分配资源,否则不分配资源,相当于借贷,考虑对方还得起才借钱,提前考虑好以后,就可以避免死锁。

死锁计算问题: 系统内有n个进程,每个进程都需要R个资源,那么其发生死锁的最大资源数为n*(R-1)。其不发生死锁的最小资源数为n(R-1)+1。
进程和线程
进程是拥有资源的最小单位
线程是独立调度的最小单位
线程可以共享进程的公共数据、全局变量、代码、文件等资源;但不能共享线程独有的资源,如线程的栈指针等表示数据
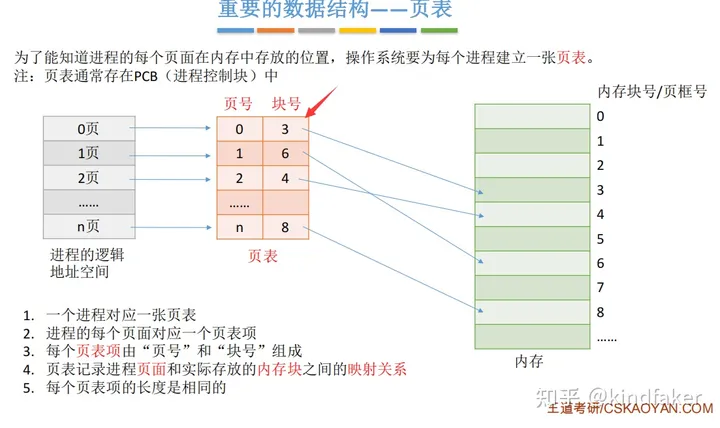
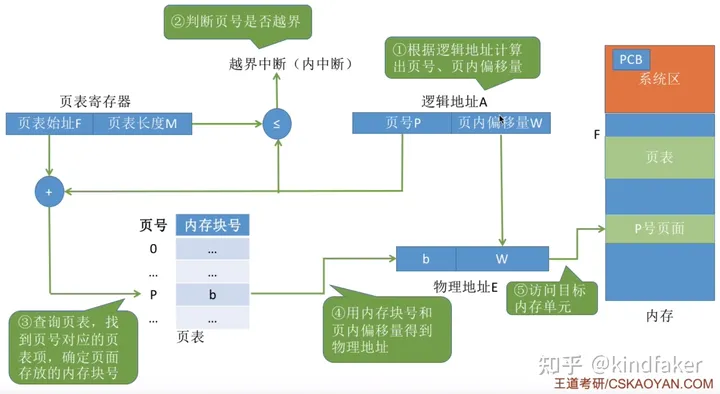
存储管理-分页式存储管理
逻辑地址转为物理地址--计算公式:物理地址= 块号*页面大小+页内偏移量


文件管理-空闲存储空间的管理
磁盘是用来存储程序数据的,存在没有放满的情况,即有空闲存储空间的情况,我们需要将这些空闲存储空间管理起来,以便某个程序需要运行时,给这个程序分配相应的空间。
- 空闲区表法(空闲文件目录):使用一张表来记录哪些地方是空闲的,以便把它们管理起来。
- 空闲链表法:把空闲的区块都链起来,链成一张链表,需要分配空间时,根据链表顺序进行遍历,从而分配相应的空间。
- 位示图法
- 成组链接法:对这些空闲的区块,既分组又分链,进行空闲区域管理的方法。
位示图:
是利用二进制的一位来表示磁盘中的一个盘块的使用情况。就是画一张位示图,然后图中每个格子表达的区域,用 1 表示该区域已被占用,用 0 表示该区域没被占用。
我们将所有的存储空间分成很多个物理块,就能够很直观的看出哪些物理块正在被使用,哪些物理块是空闲的,从而轻松解决空闲存储空间的管理难题。
例题:

设备管理-数据传输控制方式
内存和外设之间的传输控制问题
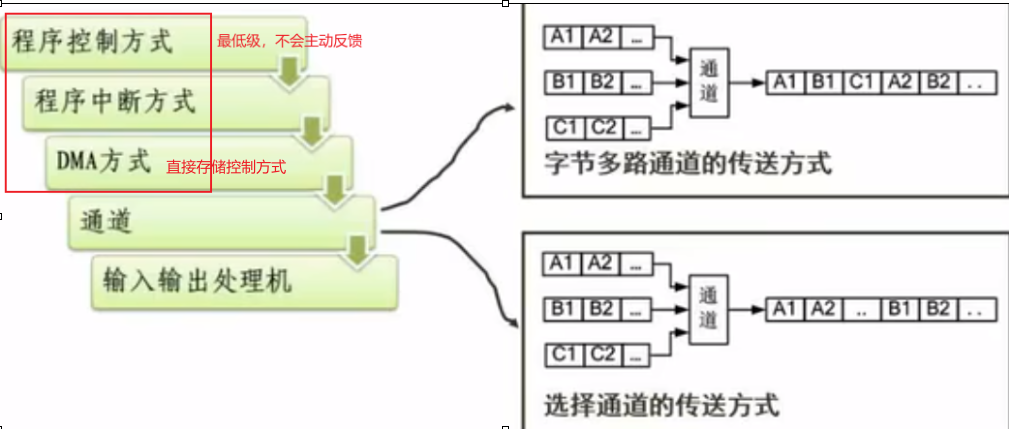
DMA: 专门的控制器来监管,效率较高,主存+外设
数据输入/输出技术的方式
- 程序查询方式:当主机进行I/0操作时,首先发出询问信号,读取设备的状态并根据设备状态决定下一步操作究竟是进行数据传输还是等待。这种控制下,CPU一旦启动I O,必须停止现行程序的运行,并在现行程序中插入一段程序。程序查询方式的主要特点是CPU有踏步等待现象,CPU与 IO串行工作。
- 程序中断:是指计算机执行现行程序的过程中,出现某些急需处理的异常情况和特殊请求,cpu暂时终止现行程序,而转去对随机发生的更紧迫的事件进行处理,在处理完毕后,cpu 将自动返回原来的程序继续执行。在中断方式中CPU与外设可并行工作。
- 直接内存存取DMA:是指在内存与I/O设备间传送数据块的过 程中,不需要CPU的任何干涉,只需要CPU在过程考试启动与过程结束时的处理,实际操作由DMA硬件直接执行完成,CPU在此传送过程中可做别的事情。在DMA方式中CPU与外设可并行工作。
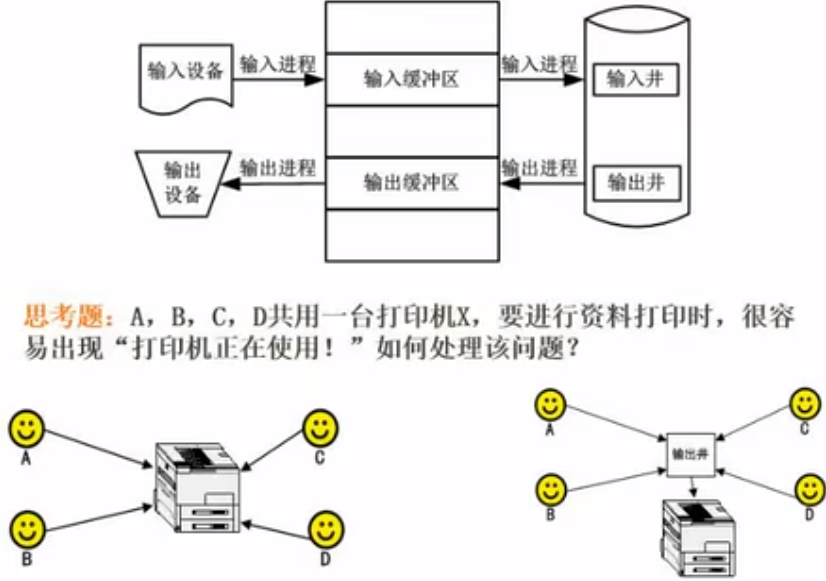
设备管理一虚设备与SPOOLING技术
微内核操作系统
磁盘的基本结构
1. 物理结构
-
盘片(Platter):磁性材料涂层的圆形盘面,双面存储数据。
-
磁头(Head):每个盘面一个磁头,负责读写数据。
-
磁道(Track):盘片上的同心圆环。
-
扇区(Sector):磁道的分段(通常 512B 或 4KB)。
-
柱面(Cylinder):所有盘面上相同半径的磁道组合。
2. 逻辑结构
-
块(Block):文件系统管理的最小单位(由多个扇区组成)。
-
分区(Partition):将物理磁盘划分为独立区域(如
C:、D:)。 -
卷(Volume):逻辑存储单元,可跨物理磁盘(如 RAID、LVM)。
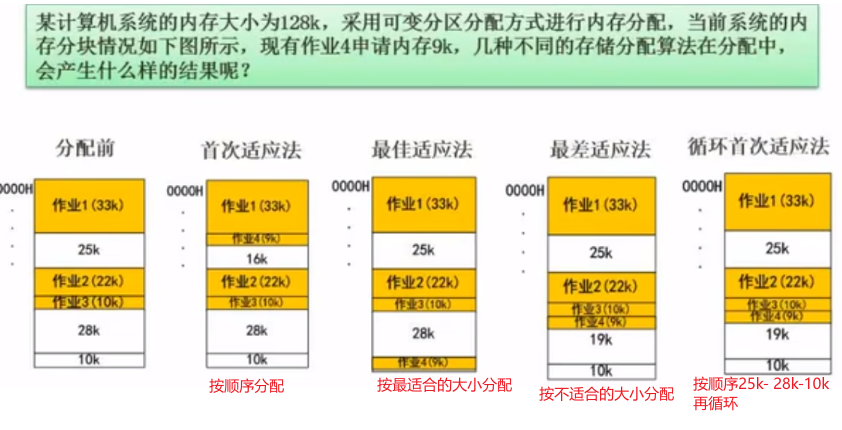
磁盘调度算法
当多个 I/O 请求到达时,操作系统需决定处理顺序以优化性能:
| 算法 | 策略 | 优点 | 缺点 |
|---|---|---|---|
| 先来先服务(FCFS) | 按请求顺序处理 | 公平简单 | 磁头移动距离长,效率低 |
| 最短寻道时间优先(SSTF) | 优先处理离当前磁道最近的请求 | 减少寻道时间 | 可能饥饿(远端请求被忽略) |
| 扫描算法(SCAN,电梯算法) | 磁头单向移动到底再反向 | 平衡寻道和响应时间 | 请求分布不均时效率下降 |
| 循环扫描(C-SCAN) | 单向移动,返回时不处理请求 | 更公平的响应时间 | 磁头空转浪费时间 |
| LOOK 与 C-LOOK | 仅移动到最远请求处即反向 | 减少不必要的移动 | 实现稍复杂 |
分布式数据库
分片透明: 是指用户不必关心数据是如何分片的,它们对数据的操作在全局关系上进行,即关心如何分片对用户是透明的,因此,当分片改变时应用程序可以不变。分片透明性是最高层次的透明性,如果用户能在全局关系一级操作,则数据如何分布,如何存储等细节自不必关心,其应用程序的编写与集中式数据库相同。
复制透明: 用户不用关心数据库在网络中各个节点的复制情况,被复制的数据的更新都由系统自动完成。
在分布式数据库系统中,可以把一个场地的数据复制到其他场地存放,应用程序可以使用复制到本地的数据在本地完成分布式操作,避免通过网络传输数据提高了系统的运行和查询效率。但是对于复制数据的更新操作,就要涉及对所有复制数据的更新。
位置透明: 是指用户不必知道所操作的数据放在何处(物理存储),即数据分配到哪个或哪些站点存储对用户是透明的。
局部映像透明性(逻辑透明):是最低层次的透明,该透明性提供数据到局部数据库的映像,即用户不必关心局部DBMS支持哪种数据模型、使用哪种数据操纵语言,数据模型和操纵语言的转换是由系统完成的。
因此,局部映像透明性对异构型和同构异质的分布式数据库系统是非常重要的。
数据库系统
一个可用的数据库系统必须能够高效地检索数据。这种高效性的需求促使数据库设计者使用复杂的数据结构来表示数据。
由于大多数数据库系统用户并未受过计算机的专业训练,因此系统开发人员需要通过视图层、逻辑层和物理层三个层次上的抽象来对用户屏蔽系统的复杂性,简化用户与系统的交互。
视图层(view level)是最高层次的抽象,描述整个数据库的某个部分。因为数据库系统的很多用户并不关心数据库中的所有信息,而只关心所需要的那部分数据。某些问题可以通过构建视图层实现,这样做除了使用户与系统交互简化,而且还可以保证数据的保密性和安全性。
逻辑层(logical level)是比物理层更高一层的抽象, 描述数据库中存储什么数据以及这些数据间存在什么关系。逻辑层通过相对简单的结构描述了整个数据库。尽管逻辑层的简单结构的实现涉及了复杂的物理层结构,但逻辑层的用户不必知道这些复杂性。因为,逻辑层抽象是数据库管理员的职责,由管理员确定数据库应保存哪些信息。
物理层(physical level) 是最低层次的抽象,描述数据在存储器是如何存储的。物理层详细地描述复杂的底层结构。
数据库模式
三级模式-两级映射
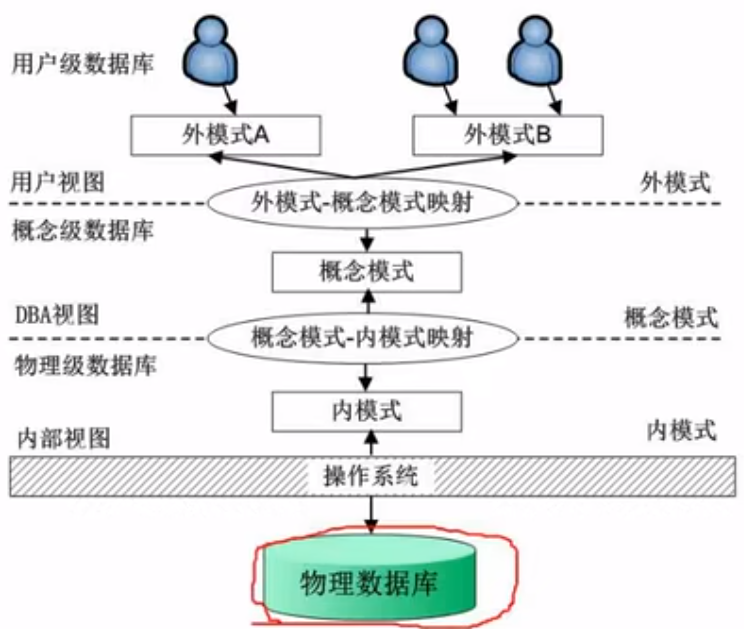
概念模式:对于表级,是数据库中全部数据的逻辑结构和特质的描述,由若干个概念记录类型组成,只涉及类型的描述,不涉及具体的值; 按数据不同内容,分类不同的表。
内模式:又叫存储模式,对应文件级。是数据物理结构和存储方式的描述,是数据在数据库内部表示的表示方法,定义所有内部的记录类型,索引和文件的组织方式,以及数据控制方面的细节。例 如:树结构存储,Hash方法存储,聚簇索引等。
数据库设计过程
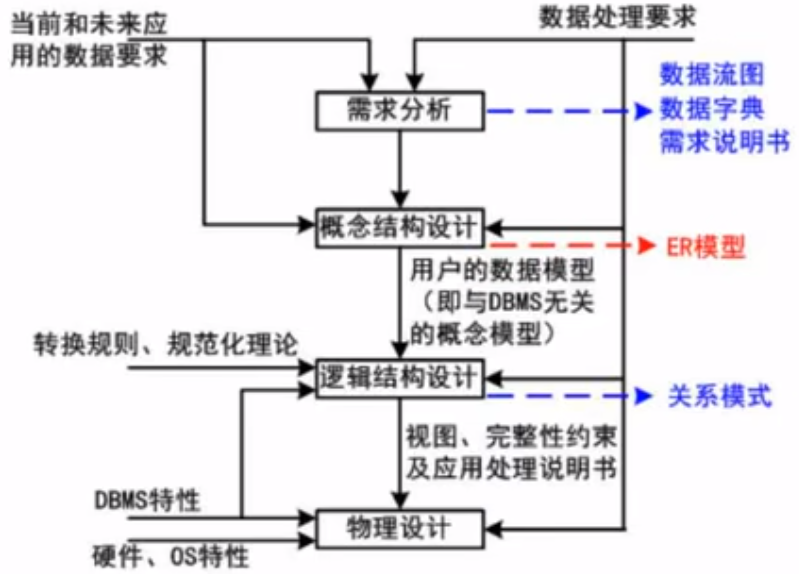
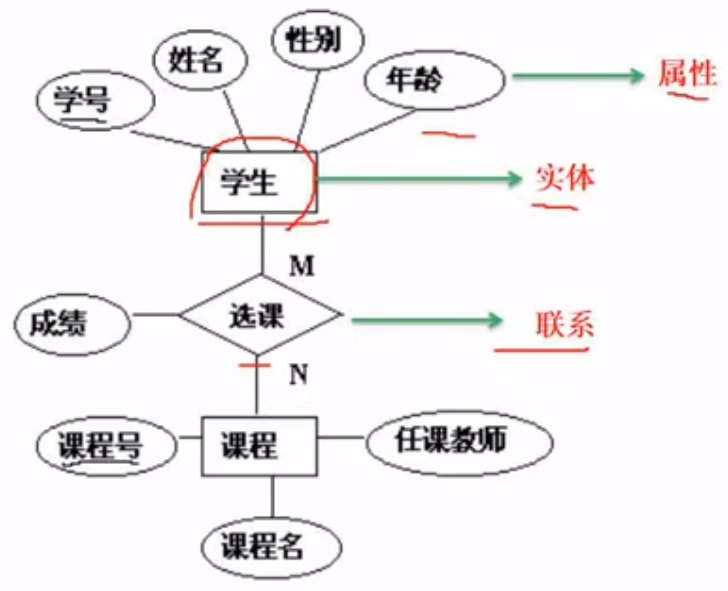
ER模型

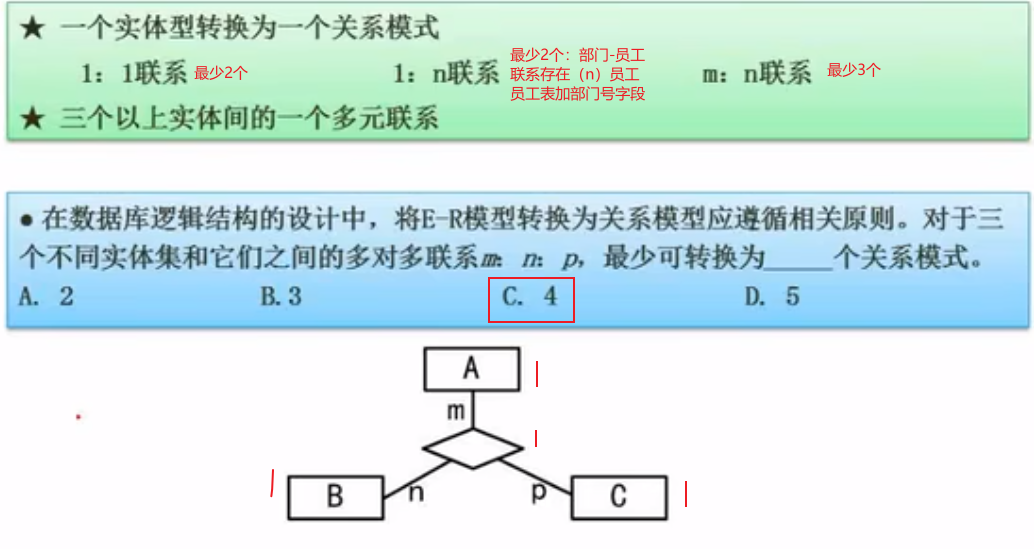
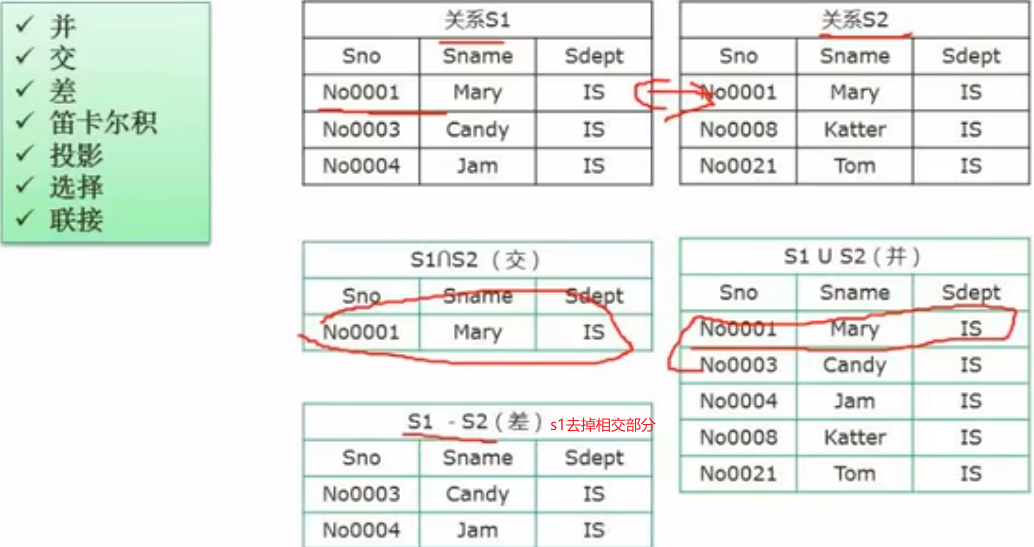
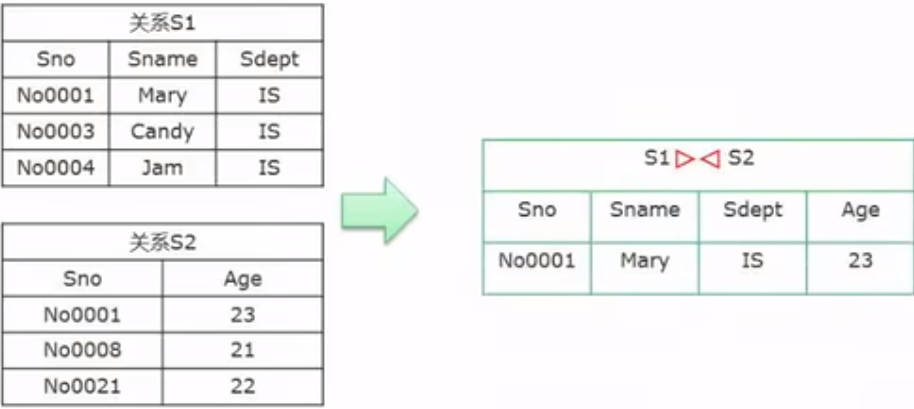
关系代数与元组演算
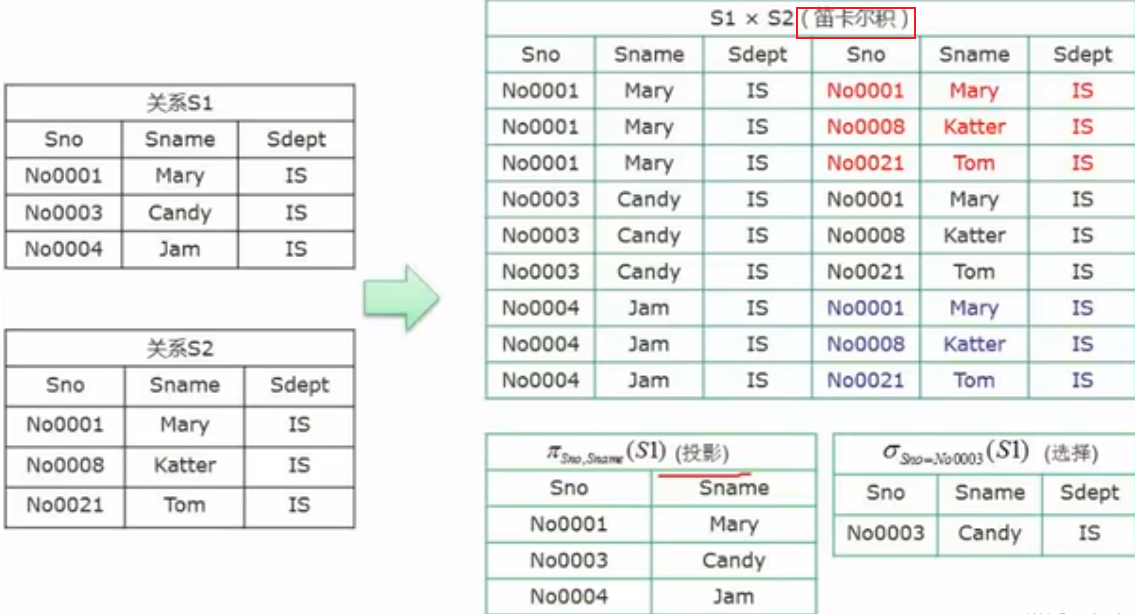
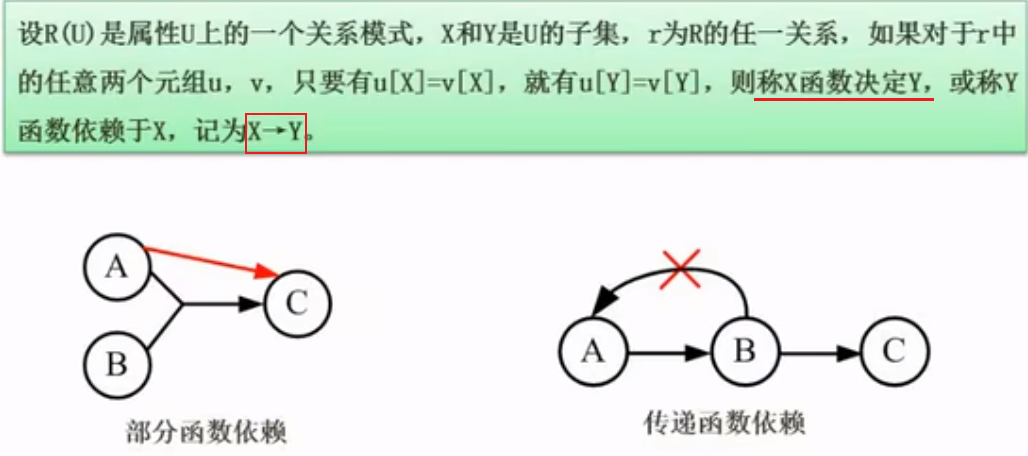
规范化理论-函数依赖

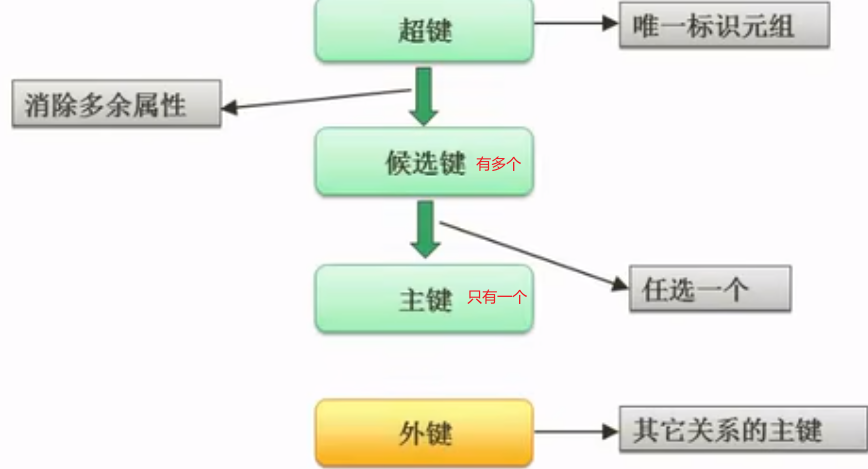
规范化理论-求候选键

规范化理论-范式
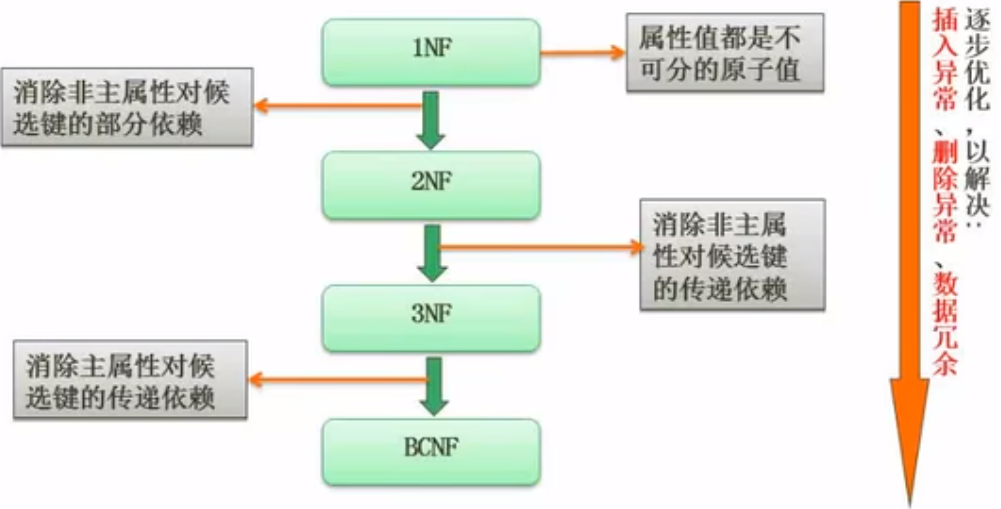

规范化理论-模式分解

并发控制
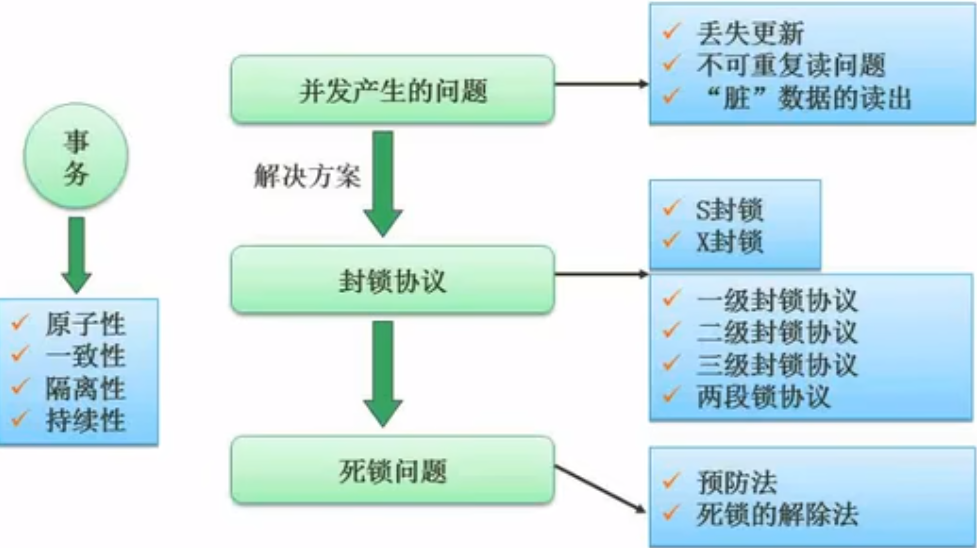

数据库完整性约束

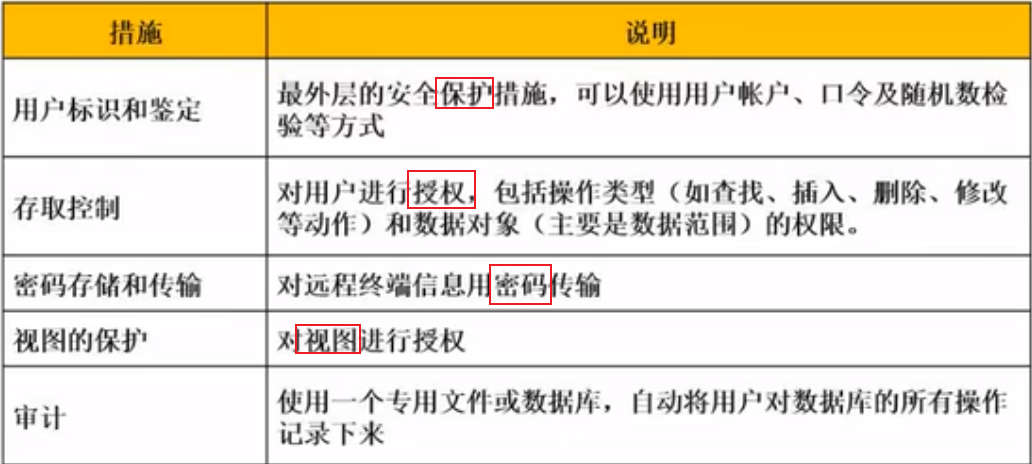
数据库安全
数据备份
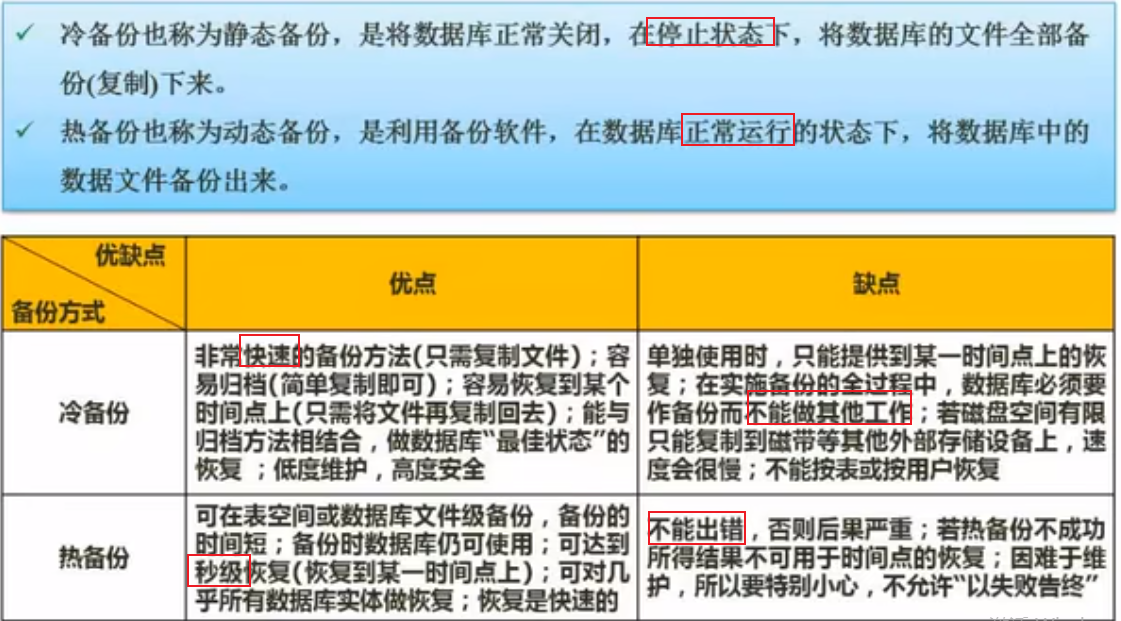

数据库故障与恢复
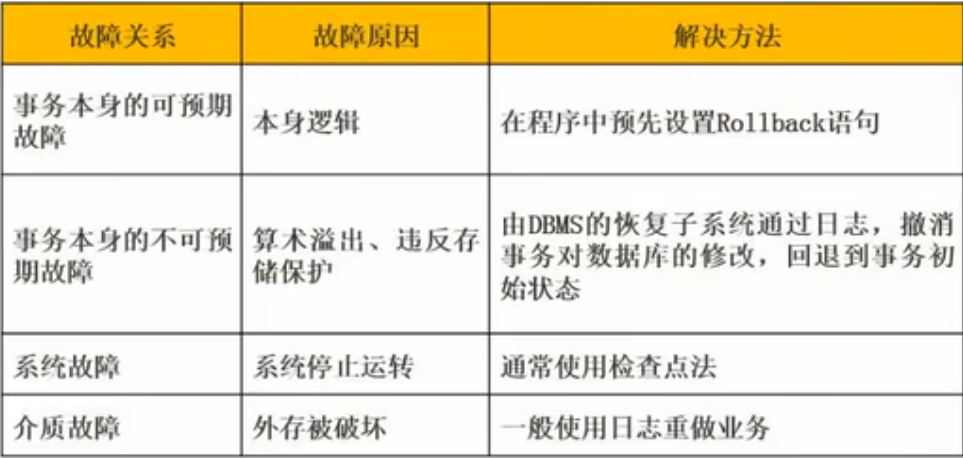
数据仓库与数据挖掘

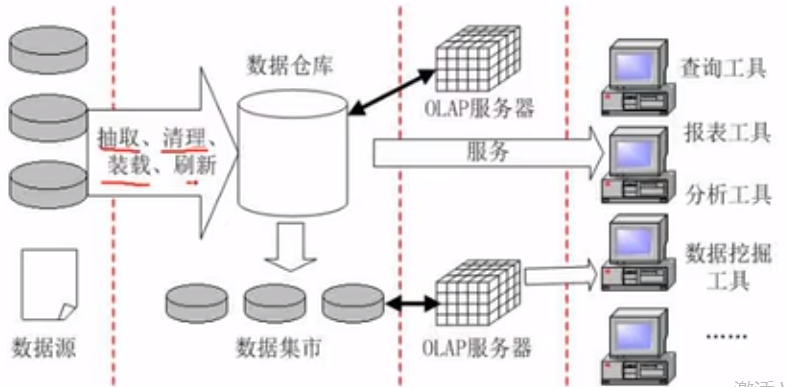
数据挖掘方法分类

反规范化

大数据


计算机网络
OSI/RM七层模型
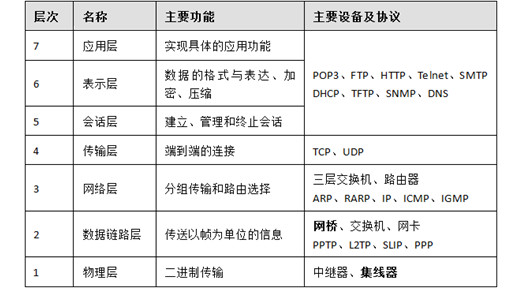
UDP常用一次性传输比较少量数据的网络应用,如DNS,SNMP等,因为对于这些应用,若是采用TCP,为连接的创建,维护和拆除 带来不小的开销。UDP也常用于多媒体应用(如IP电话,实时视频会议,流媒体,聊天软件等)数据的可靠传输对他们而言并不重要,TCP的拥塞控制会使他们有较大的延迟,也是不可容忍的
局域网只工作在下面2层:物理层和数据链路层,跨越网络层就不是同一个局域网
常见端口号
基于TCP:
FTP:(数据连接20,用于数据上传,下载)、(控制连接21,用于传输FTP命令和执行信息)
SSH:22
telnet:23(用于远程登录,可以远程烤制管理目标计算机)
SMTP:25(SMTP服务器开放的端口,用于发送邮件)
HTTP:80(超文本传输协议)
BGP:179
RIP:基于UDP,端口号为520
基于UDP:(UDP端口号为520)
DNS:53(域名解析)
DHCP:服务端端口UDP67,客户端端口68
TFTP:69(简单文件传输协议)
pop3: 110 (接受邮件)

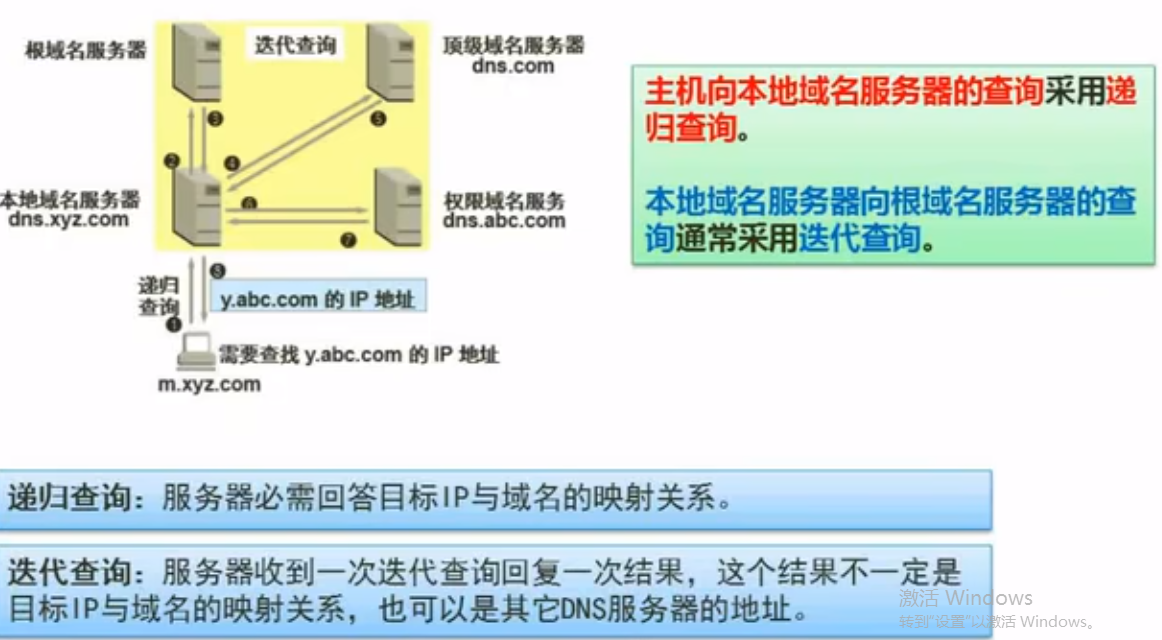
域名解析流程
域名查询:1 浏览器缓存 → 2. 系统缓存(Hosts/DNS) → 3. 本地 DNS 服务器→ 4. 根 DNS → 5. TLD DNS → 6. 权威 DNS → 7. 返回 IP
网络技术标准与协议
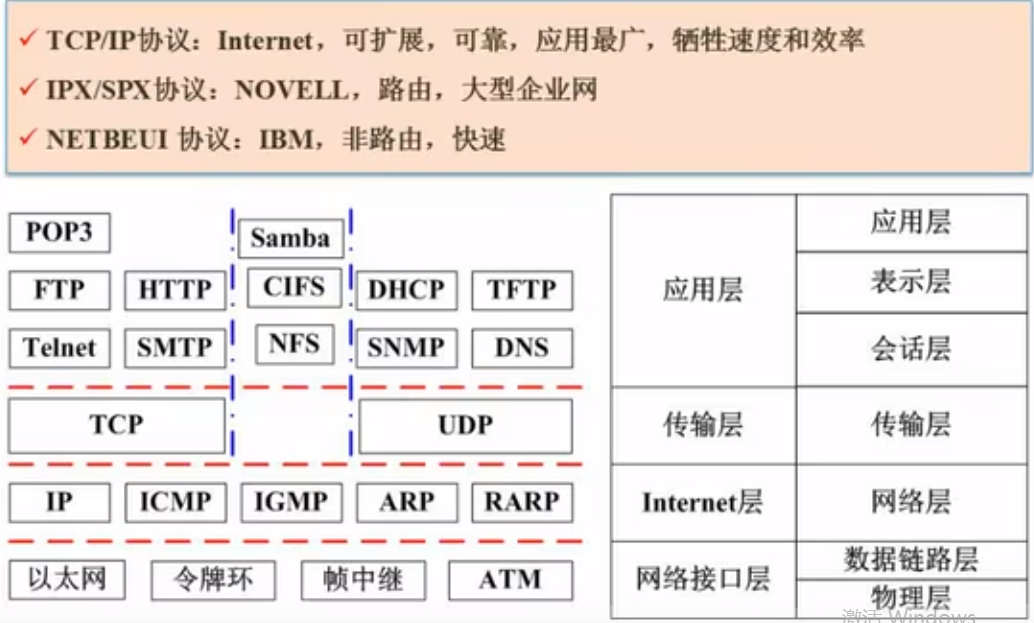
DNS协议
计算机网络的分类-拓扑结构

网络规划与设计
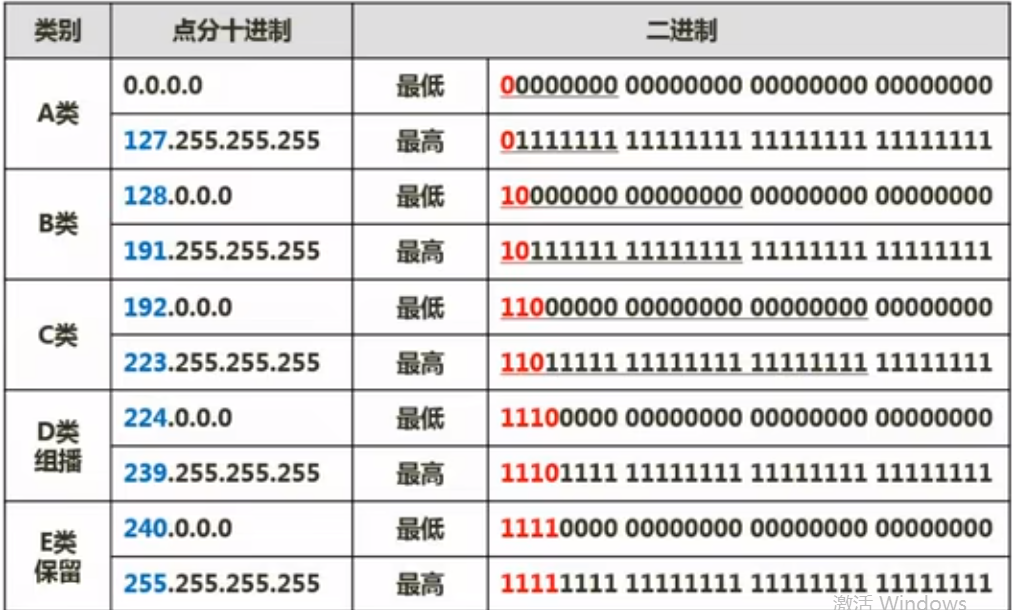
IP地址划分


(1) IP 地址
-
IP 地址是网络中设备的唯一标识。
-
IPv4 地址由 32 位二进制数组成,通常表示为 4 个十进制数(如
192.168.1.1)。 -
分为 网络部分 和 主机部分。
(2) 子网掩码
-
子网掩码用于区分 IP 地址中的网络部分和主机部分。
-
由连续的
1和0组成,1表示网络部分,0表示主机部分。 -
常见子网掩码:
255.255.255.0(/24)。
(3) 网络地址
-
网络地址是 IP 地址中网络部分的标识。
-
通过将 IP 地址与子网掩码进行 按位与运算 得到。
(4) 主机地址
-
主机地址是 IP 地址中主机部分的标识。
-
通过将 IP 地址与子网掩码的 反码 进行 按位与运算 得到。
无分类编址(无类域间路由)
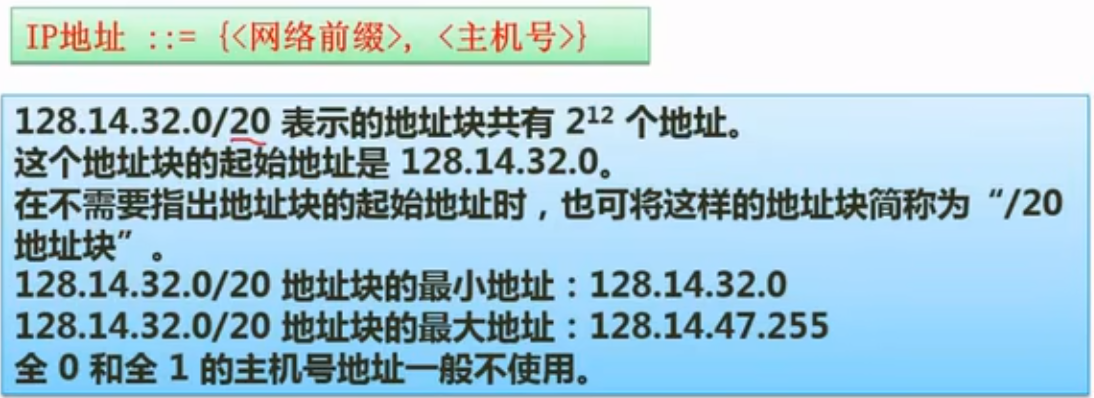
特殊含义的IP地址
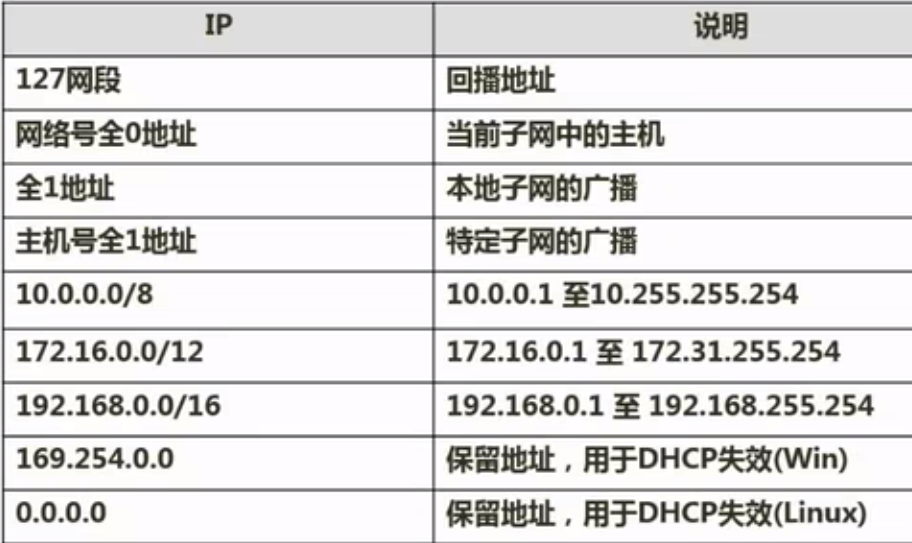
无线网
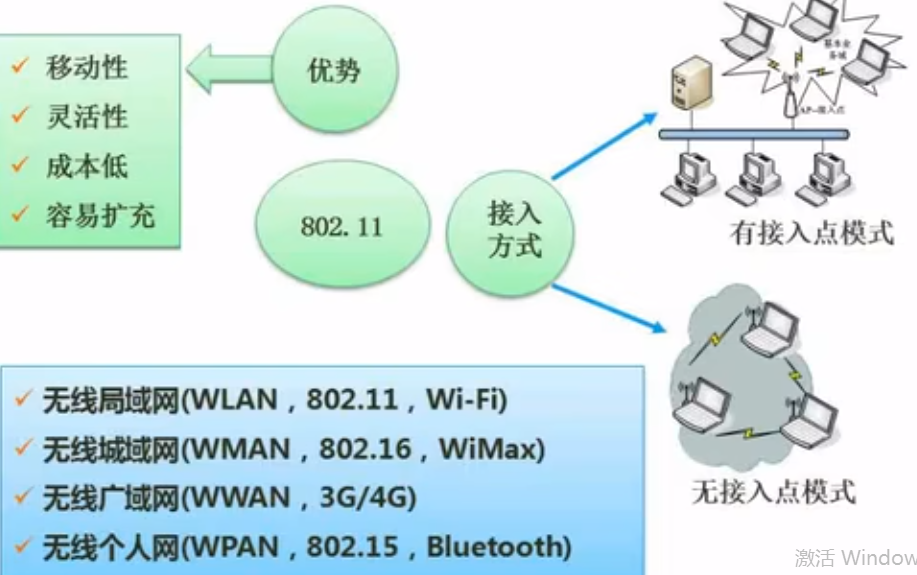
网络接入技术
公钥加密算法
- RSA:这是一种基于大质数分解困难的非对称加密算法,可以用于加密和数字签名。
- Rabin:这是RSA算法的一个特例,主要用于某些特定的安全协议中。
- ECC (Elliptic Curve Cryptography):这是一种椭圆曲线密码学,用于公钥加密和数字签名。非对称加密算法
- ElGamal:它是一种非对称加密算法,用于加密和数字签名。
- 背包算法:这是一个特殊的公钥加密算法。
- DSA:这是一种数字签名算法,它只能用于签名操作,而不是加密。
- 数字签名标准 (DSS):类似于DSA,也是一种数字签名算法,但它支持加解密功能
- SHA,MD5:摘要算法
对称加密算法:DES,3DES,AES
非对称加密算法: RSA ,ECC, EIGamal
信息摘要
简要的描述了一份较长的信息或文件,它可以被看作一份长文件的“数字指纹”。用于创建数字签名,对于特定的文件而言,信息摘要是唯一的。不同的文件产生的信息摘要也是不一样的。
常见的算法有MD5和SHA,可以用来保证数据的完整性, 防止发送的报文被篡改。
一个唯一对应一个消息或文本的固定长度的值,它由一个单向Hash加密函数对消息进行作用 而产生。常见的消息摘要算法有MD、SHA、MAC 等
数字证书
数字证书:是一个经证书授权中心(上海CA中心)数字签名的包含公开密钥拥有者信息以及公开密钥的文件。
最简单的证书:包含一个公开密钥、名称以及证书授权中心的数字签名。
CA机构:又称为证书授证(Certificate Authority)中心,作为电子商务交易中受信任的第三方,承担公钥体系中公钥的合法性检验的责任。
CA中心为每个使用公开密钥的用户发放一个数字证书,数字证书的作用是证明证书中列出的用户合法拥有证书中列出的公开密钥。
原因:保证网络安全的四大要素,即信息传输的保密性、数据交换的完整性、 发送信息的不可否认性、交易者身份的确定性。
原理:数字证书采用公钥体制,即利用一对互相匹配的密钥进行加密、解密。
每个用户自己设定一把特定的仅为本人所知的私有密钥(私钥),用它进行解密和签名;
同时设定一把公共密钥(公钥)并由本人公开,为一组用户所共享,用于加密和验证签名。
例子:
当发送一份保密文件时,发送方使用接收方的公钥对数据加密,而接收方则使用自己的私钥解密,这样信息就可以安全无误地到达目的地了。
通过数字的手段保证加密过程是一个不可逆过程,即只有用私有密钥才能解密。
数字签名:用户也可以采用自己的私钥对信息加以处理,由于密钥仅为本人所有,这样就产生了别人无法生成的文件,也就形成了数字签名
A、公钥加密,也叫非对称(密钥)加密(public key encryption),属于通信科技下的网络安全二级学科, 指的是由对应的一对唯一性密钥(即 公开密钥 和私有密钥)组成的加密方法,常见的公钥加密算法 有RSA、ElGama、背包算法等。
B、流加密,是对称加密算法的一种,加密和解密双方 使用相同伪随机加密数据流作为密钥,明文数据每次 与密钥数据流顺次对应加密,得到密文数据流。常见 的流密码加密算法有:RC4、ORYX、SEAL等。
C、分组加密将明文分成多个等长的模块(block) 。 使用确定的算法和对称密钥对每组分别加密解密, 常 见的分组加密算法有DES, AES等。
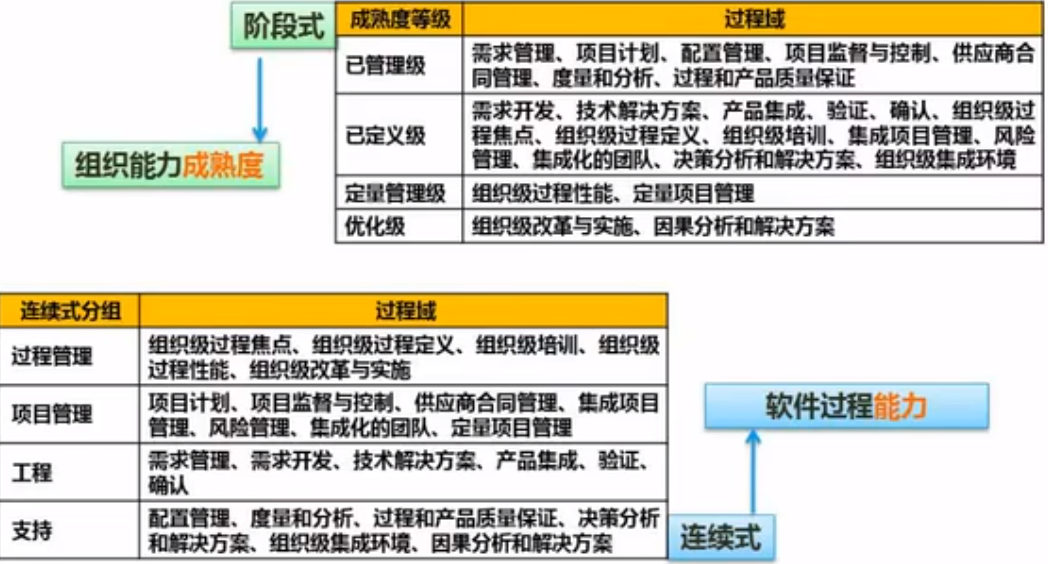
CMM
是美国卡内基一梅隆大学软件工程研究所与企业、政府合作的基础上开发的模型,主要用于评价软件企业的质量保证能力。
CMM为软件企业的过程能力提供了一个阶梯式的进化框架,将软件过程改进的进化步更分为5个成熟度等圾,每个等级定义了一组过能力目标,并描述了要达到这些目标应采取的实践活动,为不断改进过程奠定了循序渐近的基础。

初始级:是起点,该等级的企业一般缺少有效的管理,项目进行过程中常放弃最初的规划,开发项目成效不稳定。
而从可重复级开始,每个级别都设定了一组目标,且低级别目标的实现是实现高级别目标的基础。
可重复级:要求企业建了基本的管理制度和规程,管理工作有章可循,初步实现开发过程标准化。
定义级:要求整个软件生命周期的管理和技术工作均己实现标准化、文档化,并建立完善的培训制度和专家评审制度,项目质是、进度和费用均可控制。
管理级:企业的软件过程和产品己建立定量的质量目标,并通过一致的度最标准来指导软件过程,保证项目对生产率和质量进行度量,可预测过程和产品质量趋势。
优化级:企业可集中精力改进软件过程,并拥有防止出现缺陷、识别薄环节及进行改进的手段
该模型经过二十多年的验证,目前已经成为国际上最流行、最实用的软件生产过程标准和软件企业成熟度的等级认证标准
法律法规(2-3分)
从所涉及的法律法规角度:《中华人民共和国著作权法》 《计算机软件保护条例》 《商标法》 《专利法》
从试题考点分布的角度: 保护期限 知识产权人确定 侵权判断
知识产权: 著作权及邻接权; 专利权; 工业品外观设计权; 商标权; 地理标志权 集成电路布图设计权
软件著作权人享有下列各项权利:
(一)发表权,即决定软件是否公之于众的权利;(二)署名权,即表明开发者身份,在软件上署名的权利;
(三)修改权,即对软件进行增补、删节,或者改变指令、语句顺序的权利:
(四)复制权,即将软件制作一份或者多份的权利;
(五)发行权,即以出售或者赠与方式向公众提供软件的原件或者复制件的权利;
(六)出租权,即有偿许可他人临时使用软件的权利,但是软件不是出租的主要标的的除外;
(七)信息网络传播权,即以有线或者无线方式向公众提供软件,使公众可以在其个人选定的时间和地点获得软件的权利;
(八)翻译权,即将原软件从一种自然语言文字转换成另一种自然语言文字的权利;
(九)应当由软件著作权人享有的其他权利。
法律法规-保护期限
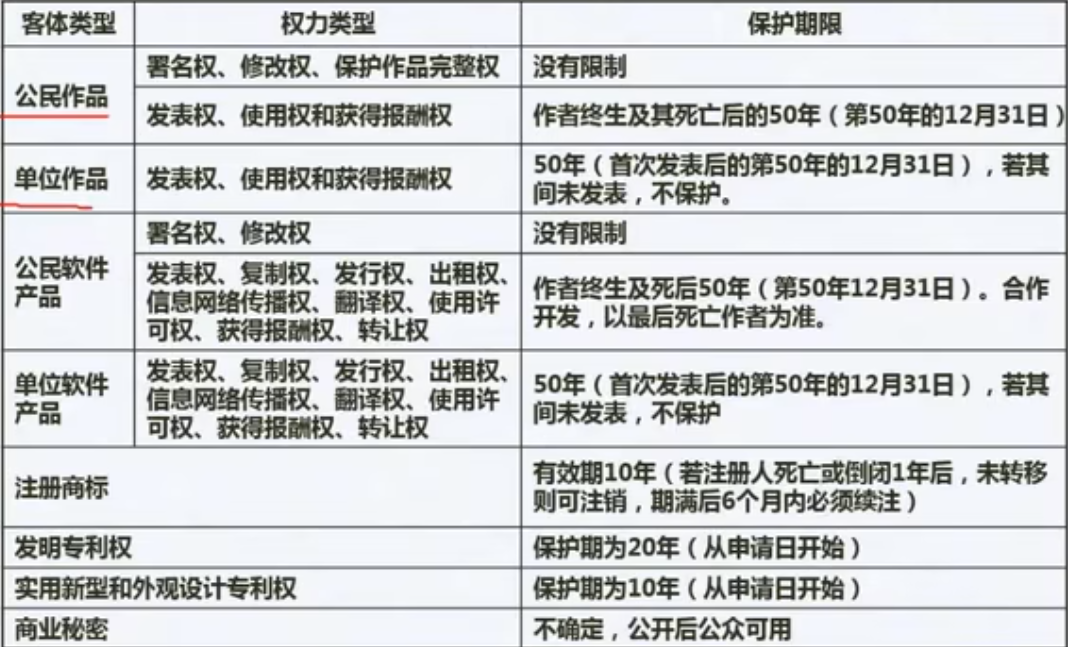
法律法规一知识产权人确定

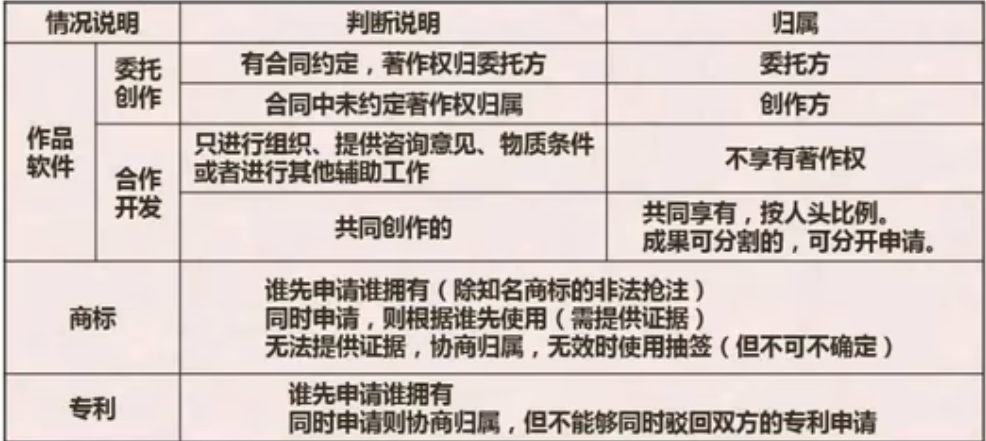
法律法规-侵权判定

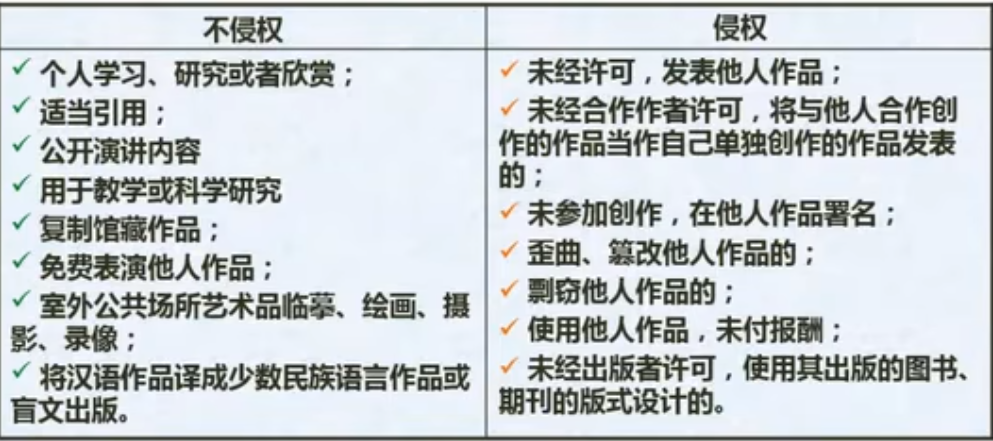
标准化基础知识-标准的分类

标准化基础知识-标准的编号

多媒体基础(1-3分)
计算机中能存放和处理的是数字信息,对于模拟视频信号要在计算机中进行处理,首先就要将这种模拟信号转换为数字信号,即A/D变换。
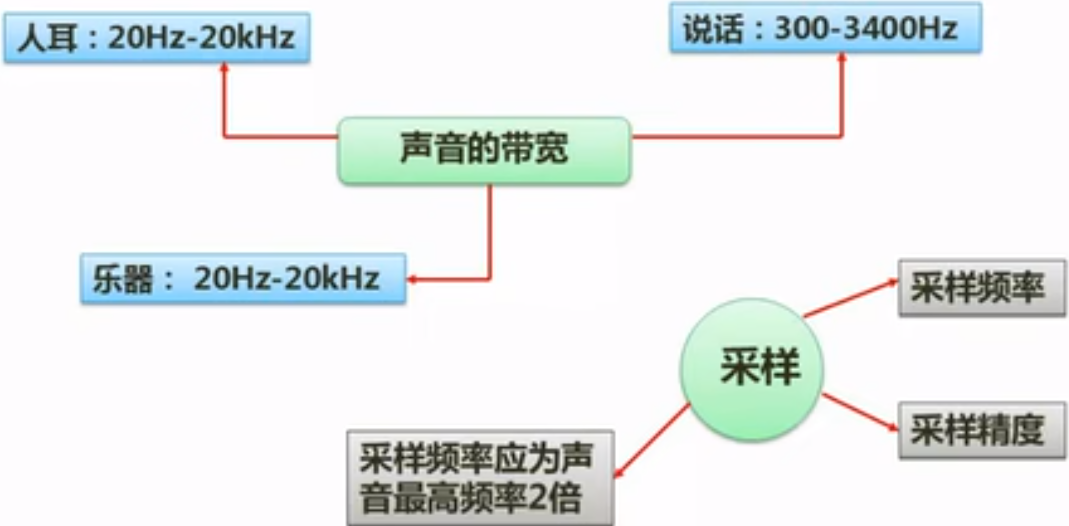
多媒体技术基本概念-音频相关概念
多媒体技术基本概念-媒体种类
感觉媒体:指人们接触信息的感觉形式。如:视觉、听觉、触觉、嗅觉和味觉等。
表示媒体:指信息的表示形式。如:文字、图形、图像、动画、音频和视频等。
显示媒体(表现媒体):表现和获取信息的物理设备。如:输入显示媒体键盘、 鼠标和麦克风等;输出显示媒体显示器、打印机和音箱等。
存储媒体:存储数据的物理设备,如磁盘、光盘和内存等。
传输媒体:传输数据的物理载体,如电缆、光缆和交换设备等。
多媒体技术基本概念-多媒体相关计算问题


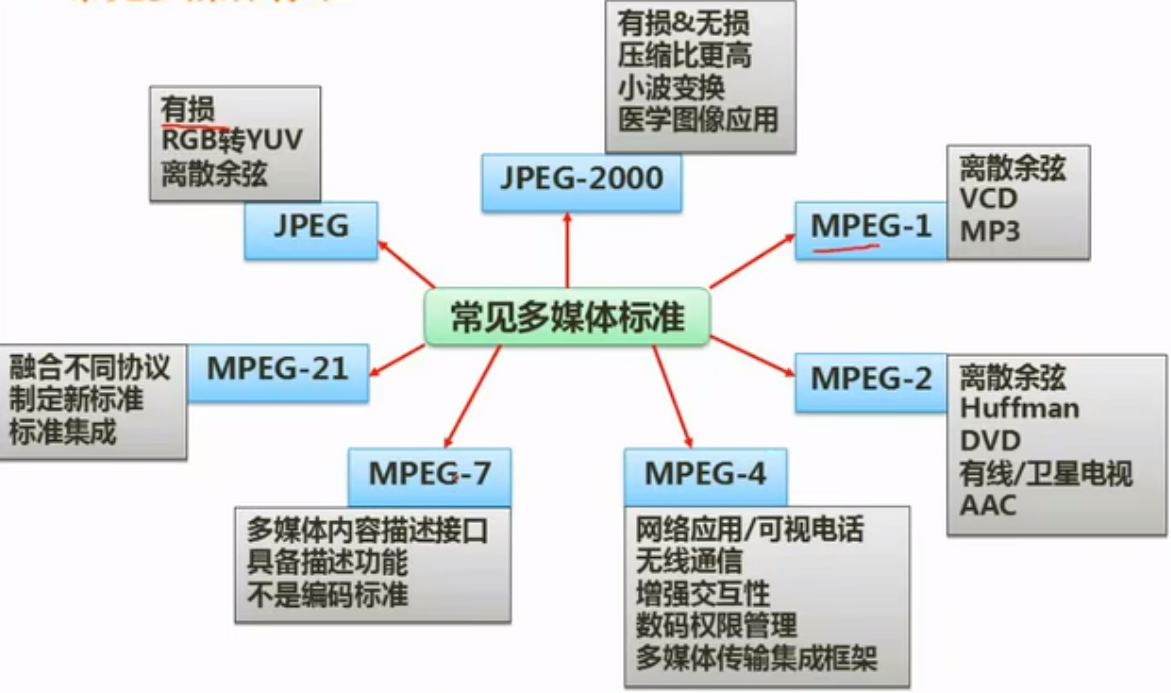
常见多媒体标准
MP3在mpeg-1里面的第三层定义的
数据压缩技术(考一点点)
有冗余才能压缩

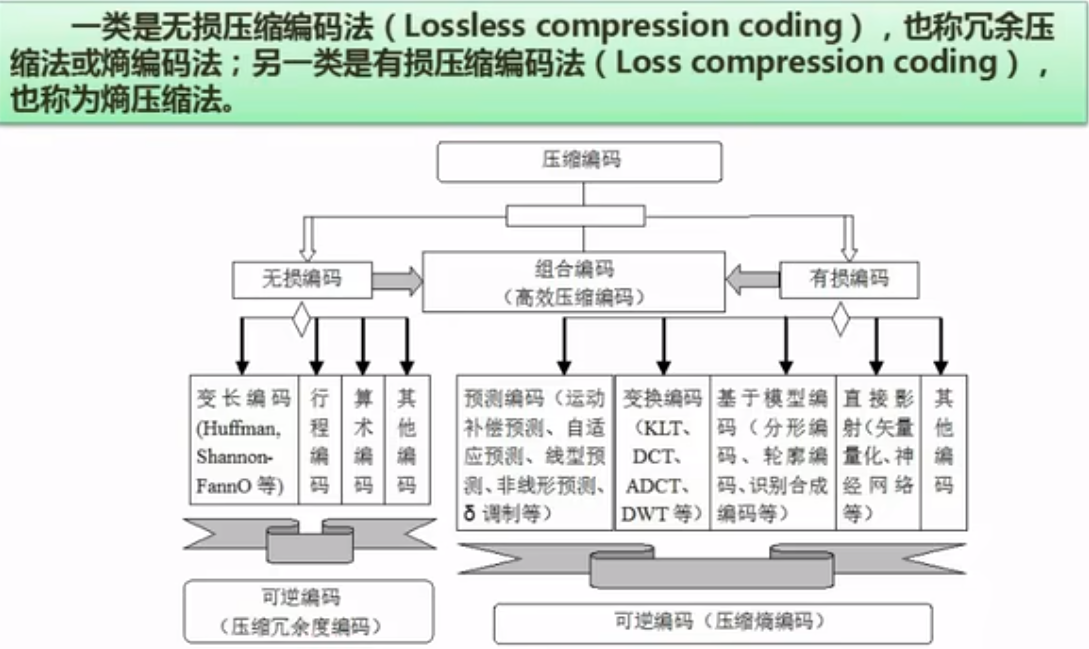
软件工程基础知识
软件开发模型
是软考上午题中必考的一个知识点。给出一定的条件,让我们判断属于哪一种开发模型。
| 模型 | 灵活性 | 文档要求 | 适用规模 | 典型场景 |
|---|---|---|---|---|
| 瀑布模型 | 低 | 高 | 中小型 | 需求稳定的传统软件 |
| 敏捷开发 | 高 | 低 | 中小型 | 互联网产品、快速迭代 |
| RUP | 中 | 中 | 中大型 | 复杂企业系统 |
| DevOps | 高 | 中 | 中大型 | 云服务、持续交付 |
| 螺旋模型 | 中 | 高 | 大型/高风险 | 军工、航天 |
【瀑布模型】
1.定义:将软件生存周期中的各个活动规定为依线性顺序连接的若干阶段的模型,包括需求分析、设计、编码、测试、运行与维护。它规定了由前至后、相互衔接的固定次序,如同瀑布流水逐级下落。
2.适用于:以文档作为驱动、适合于软件需求很明确的软件项目。
3.优点:容易理解,管理成本低;强调开发的阶段性早期计划及需求调查和产品测试。
4.不足:以前很流行,现在被淘汰(有大缺陷):客户必须能够完整、正确、清晰地表达出他们的需要;需求或设计的错误往往是在项目后期才被发现,对于项目风险控制能力较弱,经常延期。
【增量模型】
1.定义:将需求分段为一系列增量产品,每一增量可以分别开发。根据第一个增量,可以快速开发出核心产品。
2.适用于:软件体系结构开放,加入新构件过程简单。
3.优点:第一个可交付版本所需要的时间和成本很少;所承担的风险不大;减少用户需求的变更。
4.不足:如果没有对变更要求进行规划,那么会导致后来增量的不稳定;如果需 求不稳定完整,那么会导致重新开发;管理发生的成本、进度和配置的复杂性会超出组织的能力。
【原型模型】
1.定义:快速建立起来的可以在计算机上运行的程序,或仅仅是一个演示界面。
2.适用于:需求不够明确的项目。
3.优点:能快速、低成本地构建原型。
4.不足:必须要求具有技能高水平的原型化人员。
【螺旋模型】
1.定义:瀑布与演化模型的结合,加入风险分析。四象限工作步骤:制定计划、 风险分析、实施工程、用户评估。
2.适用于:庞大、复杂并且具有高风险的系统。支持需求的动态变化。
3.优点:提高软件的适应能力;降低了软件开发的风险。
4.不足:过多的迭代次数增加了开发成本,延迟了提交时间。
【喷泉模型】
1.定义:以用户需求为动力,以对象作为驱动的模型。具有迭代性和无间隙性。
2.适用于:面向对象的开发方法。
3.优点:各阶段没有明显的界线,可以同步开发,提高了软件开发效率,节省了 时间。
4.不足:各开发阶段是重叠的,不利于项目的管理;严格要求文档,使得审核的难度加大。
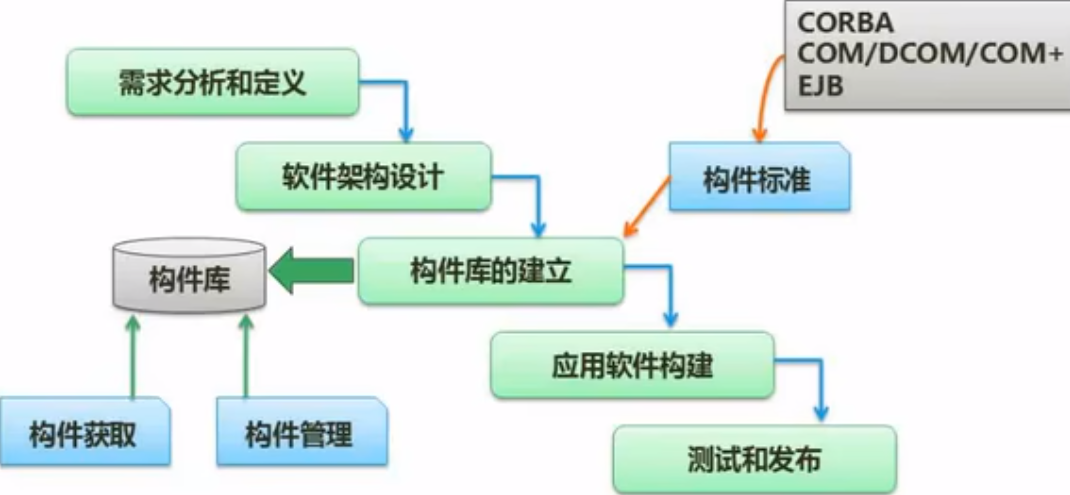
【构件组装模型】
1.定义:利用预先包装的构件来构造应用系统。具有许多螺旋模型的特点,本质上是演化模型,需要以迭代方式构建软件。
2.适用于:需要一定的构件模型支持的软件项目。
3.优点:构件组装模型导致软件的复用,提高了开发效率;允许多个项目同时开发,降低了费用,提高了可维护性。
4.不足:构件的引入具有较大的风险;过分依赖于构件,构件的质量影响产品的 质量;需要精干的、有经验的分析人员和开发人员,客户的满意度低。
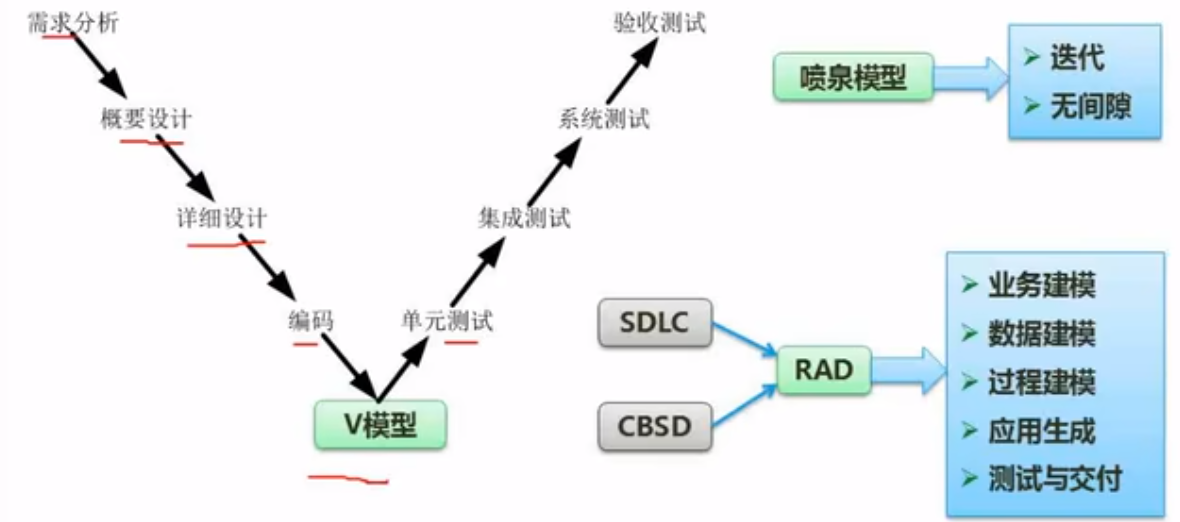
【V模型】
测试贯穿整个过程
【形式化方法模型】
1.定义:建立在严格数学基础上的一种开发方法。
2.适用于:需要生成计算机软件形式化的数学规格说明。
3.优点:易于发现需求的歧义性、不完整性和不一致性;易于对分析模型、设计 模型和程序进行验证。
4.不足:需要通过严密的数学演算。
统一过程(RUP,Rational Unified Process)
| 特点 | 说明 |
|---|---|
| 迭代式开发 | 将项目分为多个迭代(Iteration),每个迭代交付可运行的增量版本。 |
| 用例驱动 | 以用户需求(Use Case)为核心,指导设计和开发。 |
| 以架构为中心 | 早期确定系统架构,避免后期大规模返工。 |
| 风险驱动 | 优先解决高风险问题,降低项目失败概率。 |
| 支持 UML 建模 | 使用统一建模语言(UML)描述系统设计。 |
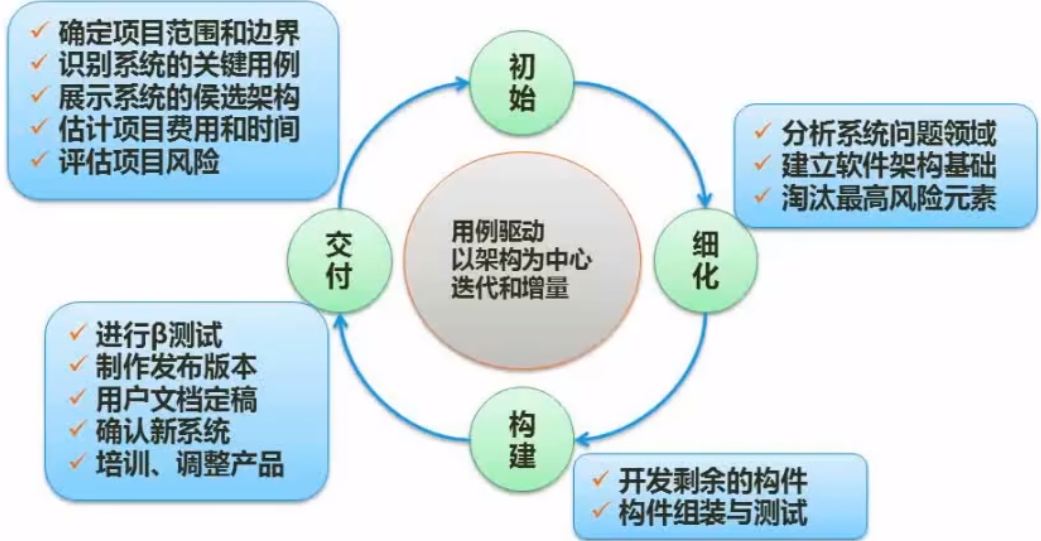
RUP vs 敏捷开发
| 特性 | RUP | 敏捷(如 Scrum) |
|---|---|---|
| 流程规范性 | 高(文档和模型驱动) | 低(强调可工作软件) |
| 适用规模 | 中大型复杂项目 | 中小型快速迭代项目 |
| 变更响应 | 需严格流程 | 灵活适应变化 |
| 典型代表工具 | IBM Rational Rose、UML | Jira、Kanban 板 |
敏捷开发
敏捷开发以用户的需求进化为核心,采用迭代、循序渐进的方法进行软件开发
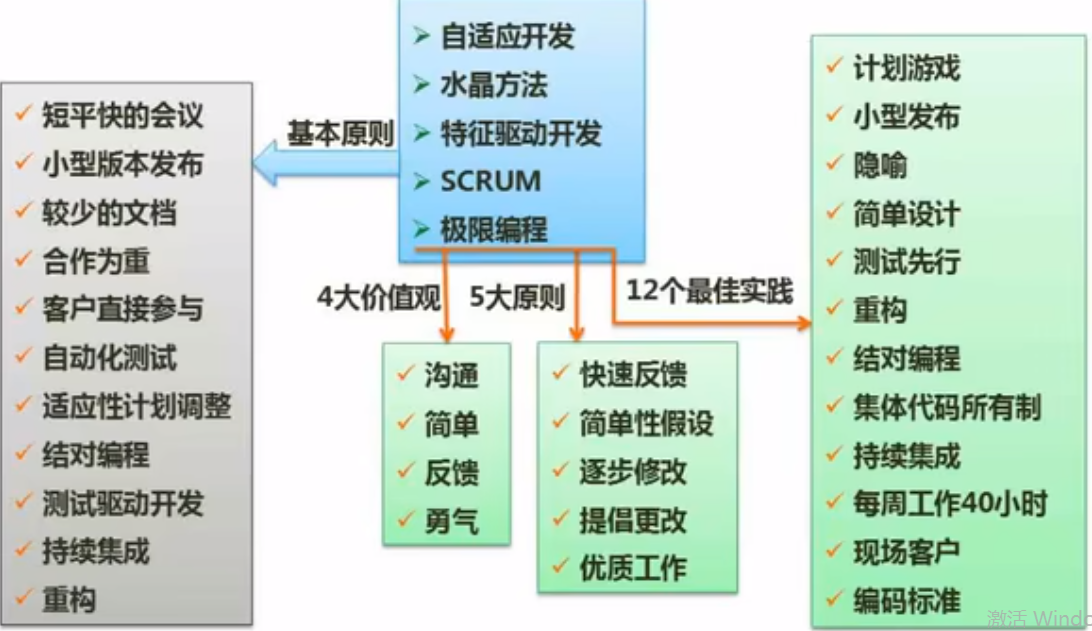
【极限编程XP】
1.四大价值观:沟通、简单、反馈、勇气
2.十二个最佳实践:
【特征驱动开发FDD】
1.FDD角色定义
软件开发中最重要的是人。FDD定义了6种关键的项目角色:项目经理,首席架构设计师,开发经理,主程序员,程序员,领域专家
领域专家作为关键的项目角色正是敏捷宣言中“业务人员同开发人员紧密合作”的体现。
2.核心过程
3.最佳实践:领域对象建模、根据特征进行开发、类的个体所有、组成特征小组、审查、定期构造、配置管理、结果的可见性。
【并列争球法Scrum】
使用了迭代的方法,其中,把每段时间(30天)一次的迭代称为一个“冲刺”,并按需求的优先级别来实现产品,多个自组织和 自治的小组并行地递增实现产品。
Scrum是一个用于开发和维持复杂产品的框架,是一个增量的、迭代的开发过程。
1.Scrum的五个活动:产品待办事项列表梳理、Sprint 计划会议、每日Scrum会议、Sprint评审会议、Sprint 回顾会议
2.Scrum的5大价值观
【水晶方法Crystal】
适合于一个小团队来进行敏捷开发,人数在6人以下为宜。
七大体系特征: (1)经常交付(2)反思改进(3)渗透式交流 (4)个人安全 (5)焦点 (6)与专家用户建立方便的联系 (7)配有自动测试、配置管理和经常集成功能的技术环境
【开放式源码】
【自适应软件开发Adaptive Software Development ASD方法】核心是三个非线性的、重叠的开发阶段:猜测、合作与学习。
系统开发

软件工程的内聚性
| 内聚类型 | 描述 |
| 功能内聚 | 完成一个单一功能,各个部分协同工作,缺一不可 |
| 顺序内聚 | 处理元素相关,而且必须顺序执行 |
| 通信内聚 | 所有处理元素集中在一个数据结构的区域上 |
过程内聚 |
处理元素相关,而且必须按特定的次序执行 |
| 瞬时内聚(时间内聚) | 所包含的任务必须在同一时间间隔内执行 |
| 逻辑内聚 | 完成逻辑上相关的一组任务 |
| 偶然内聚(巧合内聚) | 完成一组没有关系或松散关系的任务 |
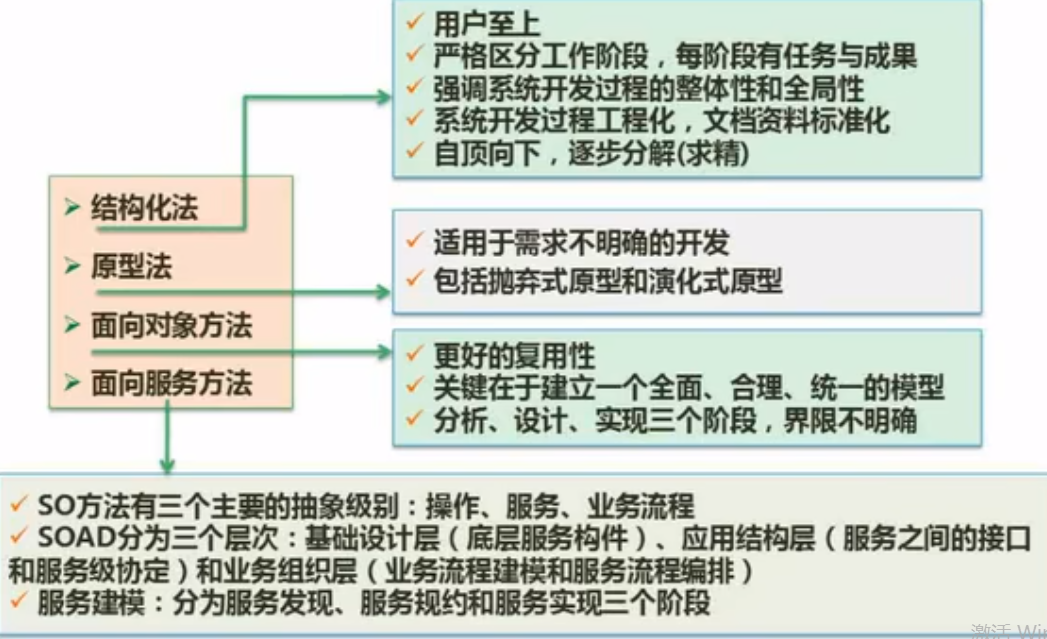
信息系统开发方法
| 方法 | 适用场景 | 关键优势 | 主要挑战 |
|---|---|---|---|
| 结构化 | 需求稳定的传统系统 | 流程清晰,文档完备 | 难以应对变更 |
| 面向对象 | 复杂业务逻辑系统 | 高复用性,易维护 | 设计复杂度高 |
| 原型法 | 需求模糊或UI密集型项目 | 快速验证,用户参与 | 可能牺牲代码质量 |
| 敏捷 | 创新性、快速迭代项目 | 灵活响应变化 | 依赖高效团队协作 |
结构化法:比较固化-逐渐被淘汰
主流:面向对象
需求开发一需求分类与需求获取
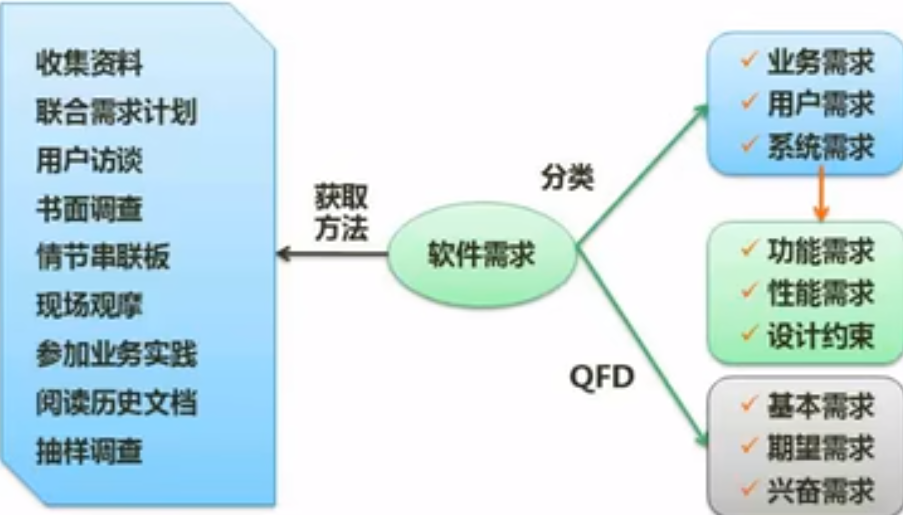
软件需求中:对软件产品的响应时间,吞吐量,价格等属性的要求都属于非功能性需求
类封装了信息和行为,是面向对象的重要组成部分。类可以分为三种类型:实体类、 边界类和控制类。
①实体类映射需求中的每个实体,实体类保存需要存储在永久存储体中的信息。实体类是对用户来说最有意义的类,通常采用业务领域术语命名,一般来说是一个名词,在用例模型向领域模型转化中,一个参与者一般对应于实体类。
②控制类是用于控制用例工作的类,一般是由动宾结构的短语(“"动词+名词”或”名词+动词”)转化来的名词。 控制类用于对一个或几个用例所特有的控制行为进行建模,控制对象通常控制其他对象,因此它们的行为 具有协调性。
③边界类用于封装在用例内、外流动的信息或数据流。边界类是一种用于对系统外部环境与其内部运作 之间的交互进行建模的类。边界对象将系统与其外部环境的变更隔离开,便这些变更不会对系统其他部分造成影响。
模块结构图
模块结构图:由5种基本符号组成模块:这里所说的模块通常是指用一个名字就可以调用的一段程序语句。在模块结构图中用矩形表示。
调用:模块结构图中箭头总是由调用模块指向被调用模块。
数据:当一个模块调用另一个模块时,调用模块可以 把数据传送到被调用模块供处理,而被调用模块又可 以将处理的结果送回到调用模块。在模块之间传送的 数据,使用与调用箭头平行的带空心圆的箭头表示, 并在旁边标上数据名。
控制信息:在模块间有时必须传送某些控制信息。控制信息与数据的主要区别是前者只反映数据的某种状 态,不必进行处理, 控制信息与控制成分并不等价。
软设在程序设计语言中提到的语言控制成分。控制成分指明语言允许表述 的控制结构,程序员使用控制成分来构造程序中的控 制逻辑。理论上已经证明,可计算问题的程序都可以 用顺序、选择和循环这3种控制结构来描述,
转接符号:当模块结构图在一张纸上画不下,需要转 接到另一张纸上,或者为了避免图上线条交叉时,都可以使用转接符号,圆国内加上标号。
结构化设计-基本原则
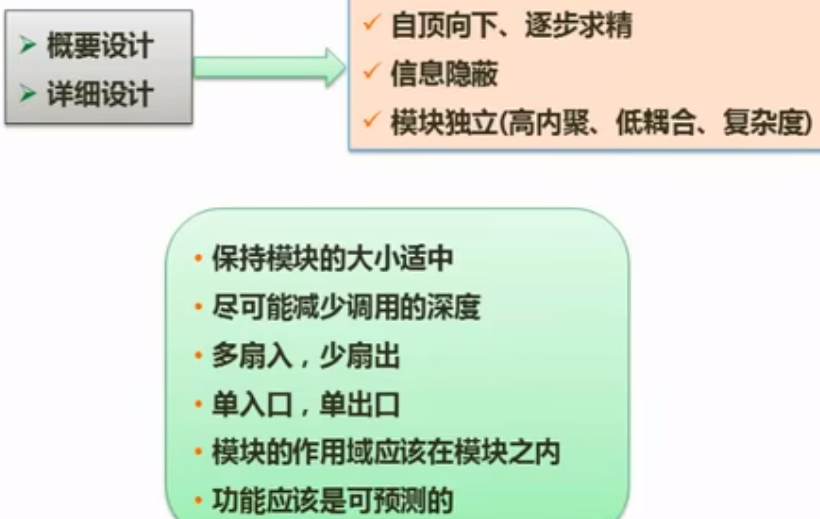
结构化设计-系统结构/模块结构 (了解)
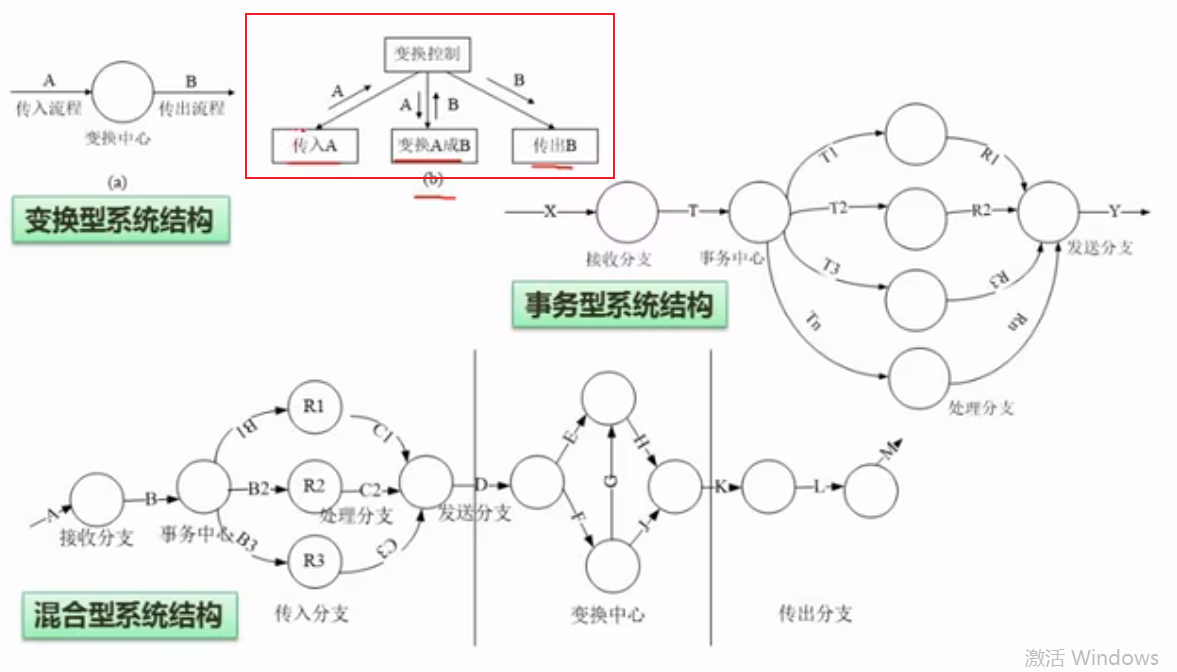
软件测试-测试原则与类型
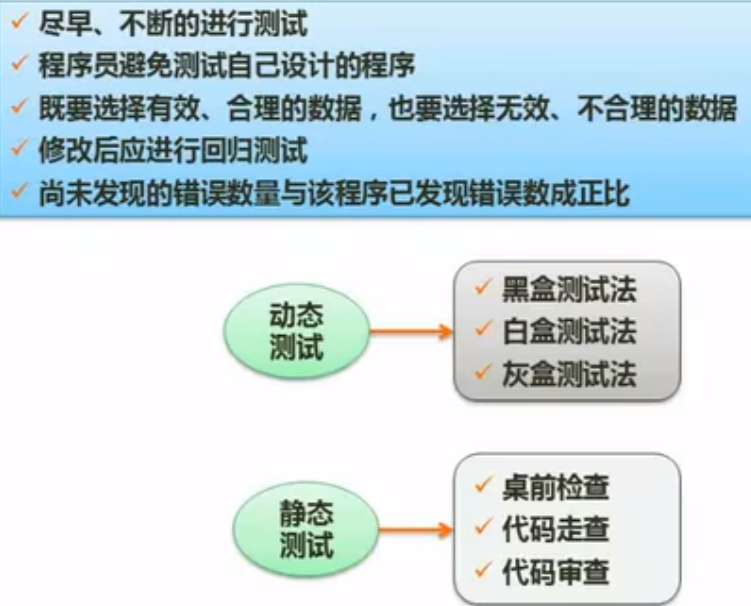
软件测试-测试用例设计
面向对象软件的测试
可分为下列的4个层次进行。
(1)算法层:测试类中定义的每个方法。
(2)类层:测试封装在同一个类中的所有方法与属性之间的相互作用。
(3)模板层:测试一组协同工作的类之间的相互作用。
(4)系统层:把各个子系统组装成完整的面向对象软件系统,在组装过程中同时进行测试。
ISO/IEC 9126软件质量模型
该模型的质量特性和质量子特性如下:
- 功能性(适合性、准确性、互用性、依从性、安全性);
- 可靠性(成熟性、容错性、易恢复性);
- 易使用性(易理解性、易学性、易操作性);
- 效率(时间特性、资源特性);
- 可维护性(易分析性、易改变性、稳定性、易测试性);
- 可移植性(适应性、易安装性、一致性、易替换性)
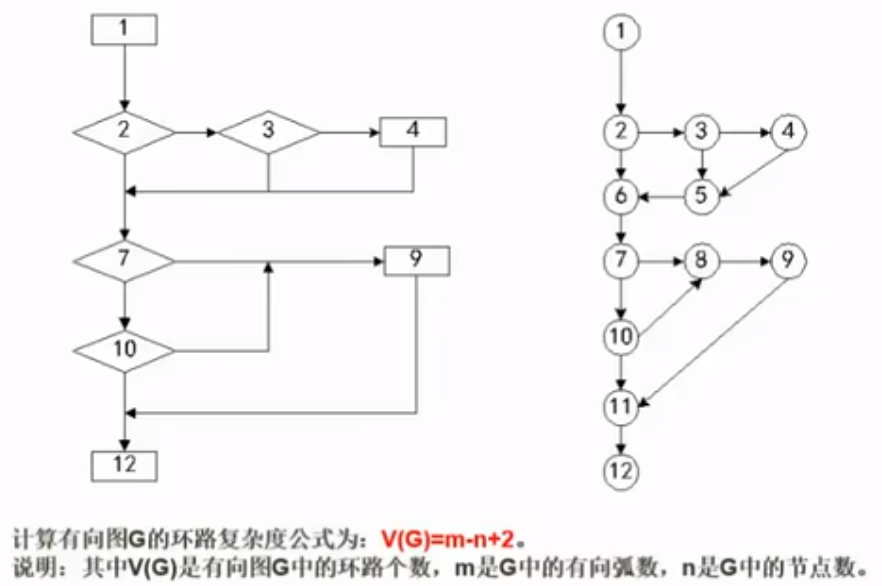
McCabe度量法
是一种基于程序控制流的复杂性度量方法。McCabe复杂性度量又称环路度量,其计算公式为: V(g)=m-n+2, 其中 m:margin n:node
系统运行与维护-软件维护

改正性维护:是指改正在系统开发阶段已发生而系统测试阶段尚未发现的惜误
适应性维护:是指便用软件适应信息技术变化和管理需求变化而进行的修改。
完善性维护:是为扩充功能和改善性能而进行的修改,主要是指对已有的软件系统增加一些在系统分析和设计阶段中没有规定的功能与性能特征。
预防性维护:为了改进应用软件的可靠性和可维护性,为了适应未来的软硬件环境的变化,应主动增加预防性的新的功能,以使应用系统适应各类变化而不被淘汰。
软件过程改进-CMMI
CMM:能力成熟度模型,是指软件开发的成熟度。 CMMI是由CMM发展而来
项目管理


项目管理工具
用来辅助软件的项目管理活动。通常项目管理活动包括项目的计划、调度、通信、成本估 算、资源分配及质量控制等。
一个项目管理工具通常 把重点放在某一个或某几个特定的管理环节上,而不提供对管理活动包罗万象的支持。
项目管理工具具有以下特征:
(1)覆盖整个软件生存周期;
(2)为项目调度提供多种有效手段;
(3)利用估算模型对软件费用和工作量进行估算;
(4)支持多个项目和子项目的管理;
(5)确定关键路径,松弛时间,超前时间和滞后时 间;
(6)对项目组成员和项目任务之间的通信给予辅助;
(7)自动进行资源平衡;
(8)跟踪资源的使用;
(9)生成固定格式的报表和剪裁项目报告。 成本估算工具就是一种典型的项目管理工具。
鱼骨图:是常用来【发现问题根源】并【提出解决问题的有效办法】的工具。
管理开发进度的工具
1 甘特图

甘特图能够消晰描述每个任务的开始/结束时间及各任务之间的并行性,也可以动态地反映项目的开发进展情况,但难以反映多个任务之间存在的逻辑关系;
2 PERT (计划评审技术)图

用时最长的为关键路径:ADEFH 19
PERT利用项目的网络图和各活动所需时间的估计值(通过加权平均得到的)去计算项目总时间,强调任务之间的先后关系,但不能反映任务之间的并行性,以及项目的当前进展情况;
PERT利用期望值而不是最可能的活动所需时间估计(在CPM法中用的)。
3 CPM (关键路径法)图
节点表示
• Event number: 事件编号
• Earliest Date:最早(开始/完成)时间
• Latest Date:最晚(开始/完成)时间
• Slack:松弛时间

CPM用于确定项目中最关键的活动路径,借助网络图和各活动所需时间,计算每一活动的最早或最迟开始和结束时间。
CPM的关键是计算总时差,这样可决定哪一活动有最小时间弹性。

关键路径的意义
– 必须保证关键路径上的资源和关键路径活动顺利执行
– 要缩短整个项目周期,必须缩短关键路径
求沟通路径
在知道小组成员后,求沟通路径可按公式n(n-1)/2 求解,
题目:开发小组有8个成员,即存在的沟通路径为8x (8-1) / 2=28条。
在团队中,"沟通路径"通常指 成员之间两两直接沟通的独立渠道。例如:
-
2 个人:1 条路径(A ↔ B)。
-
3 个人:3 条路径(A ↔ B, A ↔ C, B ↔ C)。
数学建模
这是一个典型的 组合问题,计算从 8 个成员中任意选取 2 个的组合数:
沟通路径数=C(8,2) = 8! / 2!(8−2)! = 8×7 / 2×1=28
每个成员需要与其他 7 人沟通,但这样会重复计算(A ↔ B 和 B ↔ A 是同一条路径)
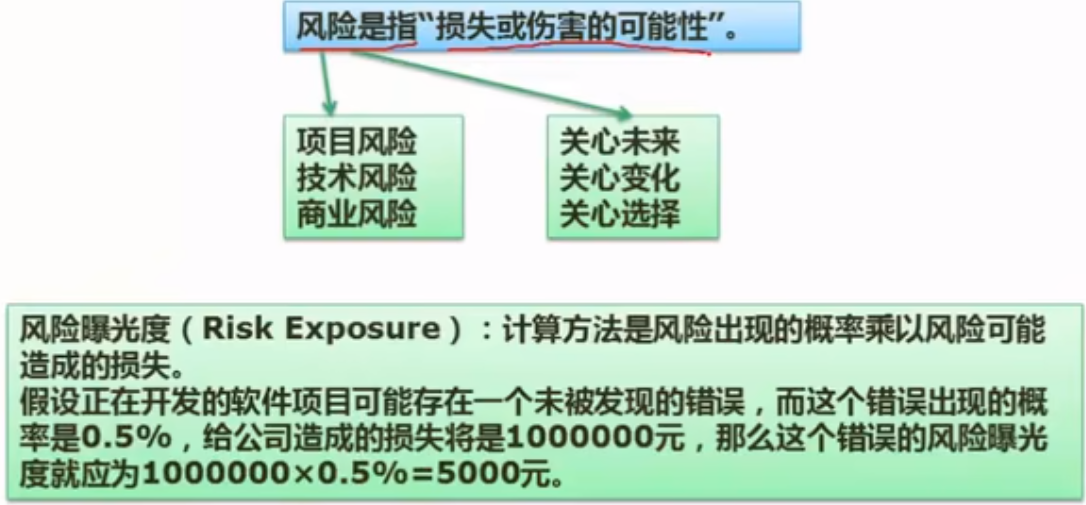
软件风险
- 不确定性:是指风险可能发生,也可能不发生
- 损失:是当风险确实发生时,会引起的不希望的后果和损失
已知风险和未知风险:是对软件风险进行分类的一种方式。
员工和预算:是在识别项目风险时需要识别的因素。
面向对象
多态
- 参数多态:这是最纯的多态形式,允许函数或方法接受不同类型的参数,并在运行时进行类型检查和处理。
- 包含多态:这种多态允许同一个操作在父类和子类中都有定义,并且子类可以重写父类的方法。这种多态通常需要进行运行时的类型检查,最常见的例子是子类型化,即一个类型是另一个类型的子类型。
- 过载多态:同一个名字(如函数名或操作符)在不同的上下文中可以有不同的含义或操作。这种多态依赖于上下文来确定具体的行为。
- 强制多态:在编译时,编译器通过语义操作将操作对象的类型强制转换为符合函数或操作符要求的类型。
一、编译时多态(静态多态)
-
方法重载(Overloading)
在同一个类中定义多个同名方法,通过参数列表(类型、数量或顺序)的差异区分具体调用哪个方法。编译器在编译阶段即可确定匹配的方法,例如:- 示例:
Calculator类中的add方法,接收不同参数类型(int或double)或数量(可变参数)。 - 特点:简化接口设计,无需为不同类型编写不同方法名。
- 示例:
-
模板/泛型编程
通过参数化类型实现代码复用,例如C++的模板或Java的泛型。编译器根据具体类型生成对应的代码。
二、运行时多态(动态多态)
-
方法重写(Overriding)
子类继承父类并重写其方法,通过父类引用指向子类对象,运行时根据实际对象类型调用对应方法。例如:- 示例:
Animal父类的sound()方法被Cat和Dog子类重写,调用时分别输出“喵”和“汪”。 - 必要条件:继承关系、方法重写、向上转型(父类引用指向子类对象)。
- 示例:
-
接口多态
通过接口定义统一方法,不同实现类提供具体逻辑。例如Java中List接口的ArrayList和LinkedList实现。
软件开发过程
包括分析、系统设计、开发类、组装测试和应用维护
分析过程:问题域分析、应用分析。此阶段主要识别对象及对象之间的关系,最终形成软件的分析模型,并进行评估。
设计阶段:主要构造软件总的模型,实现相应源代码,在此阶段,需要发现对象的过程,确定接口规格。
面向对象分析阶段:认定对象、组织对象、对象间的相互作用、基于对象的操作。
面向对象设计阶段:识别类及对象、定义属性、定义服务、识别关系、识别包。
面向对象程序设计:程序设计范型、选择一种OOPL
面向对象测试:算法层、类层、模板层、系统层。
基本概念
对象 类(实体类、边界类、控制类) 抽象 封装 继承与泛化 多态 接口 消息 组件 模式和复用面向对象分析的目的是为了获得对应问题的理解,确定系统的功能、性能要求。
面向对象分析包含5个活动,即认定对象、组织对象、描述对象间的相互作用、定义对象的操作和定义对象的内部信息。
面向对象的测试层次
1、算法层:测试类中定义的每个方法,相当于传统软件测试中的单元测试。2、类层:测试封装在同一个类中的所有方法与属性之间的相互作用。可以认为是面向对象测试中所特 有的模块(单元)测试。
3、模板层:也称为主题层,测 试协同工作的类或对象之间的相互作用。相当于传统软件测试中的子系统测试。
4、系统层:把各个子系统 组装成完整的面向对象软件系统,在组装过程同时进行测试。
面向对象的开发方法
方法重载:是通过静态绑定机制实现多态。在编译时,根据方法调用时传递的参数类型和数量来确定具体是调用哪个重载方法。方法重载是一种静态多态,也称为编译时多态。方法覆盖:覆盖通过动态绑定机制实现多态。属于运行时多态,子类重新定义父类中已定义的方法
设计原则(选择题)
接口分离原则: 使用多个专门的接口要比使用单一的总接口要好。开放-封闭原则: 对扩展开放,对修改关闭。
共同封闭原则: 包中的所有类对于同一性质的变化应该是共同封闭的。一个变化若对一个包产生影响,则将对该包里的所有类产生影响,而对于其他的包不造成任何影响。
共同重用原则: 一个包里的所有类应该是共同重用的。如果重用了包里的一个类,那么就要重用包中的所有类。
单一职责原则:设计目的单一的类
依赖倒置原则:要依赖于抽象,而不是具体实现;针对接口编程,不要针对实现编程
组合重用原则:要尽量使用组合,而不是继承关系达到重用目的
迪米特(Demeter)原则(最少知识法则):一个对象应当对其他对象有尽可能少的了解
李氏(Liskov)替换原则:子类可以替换父类。在软件中将一个基类对象替换成它的子类对象时程序将不会产生任何错误和异常。
反过来则不成立。即:如果一个软件实体使用的是一个子类对象,那么它不一定能够使用基类对象。
例如:我喜欢动物,那我一定喜欢狗,因为狗是动物的子类;但是,我喜欢狗不能据此断定我喜欢所有的动物。
里氏替换原则是实现开闭原则的重要方式之一,由于在使用基类对象的地方都可以使用子类对象,因此在程序中尽量使用基类类型来 对对象进行定义,而在运行时再确定其子类类型用子类对象来替换父类对象。
运用:
里氏替换原则时应该将父类设计为抽象类或者接口,让子类继承父类或实现父接口并实现在父类中声明的方法;
在运行时子类实例替换父类实例可以很方便地扩展系统的功能而无需修改原有子类的代码。
与此同时,假若需要增加新的功能则可以通过增加一个新的子类来实现。
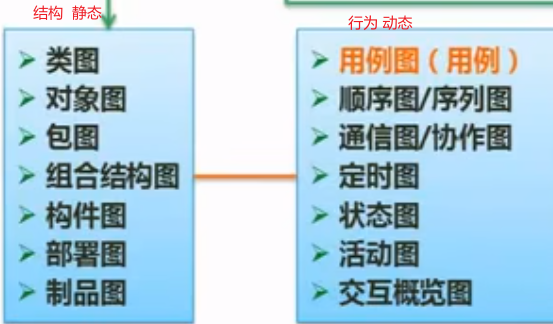
UML
UML-Unified Modeling Language 统一建模语言,又称标准建模语言。是用来对软件密集系统进行可视化建模的一种语言
关系:依赖 关联 泛化 实现
静态比较,固定;
设计模式-概念
从上到下3个层级

设计模式-分类
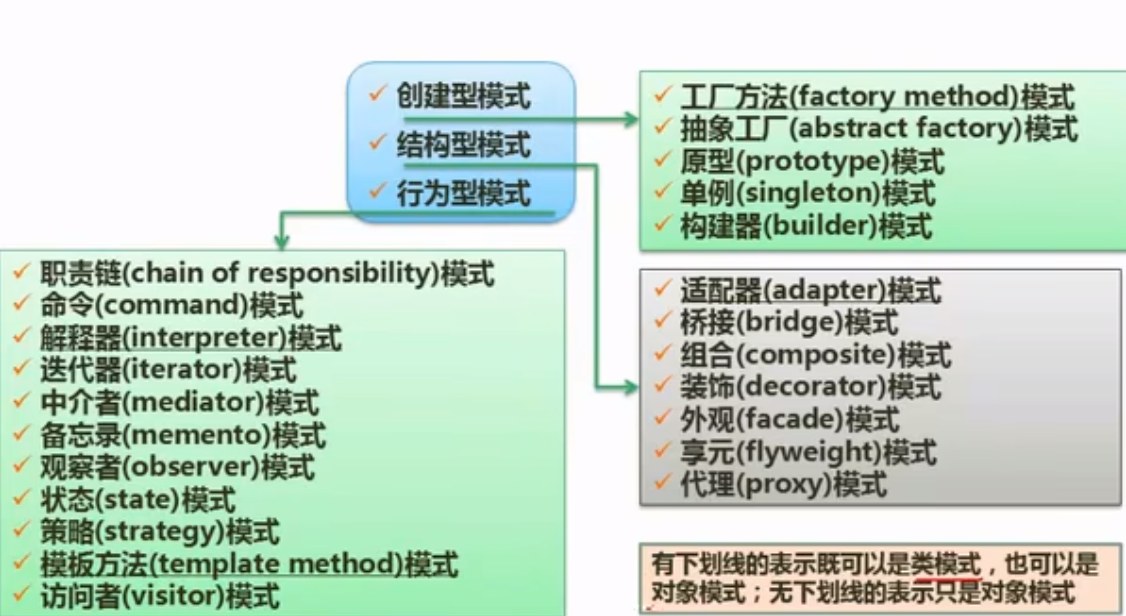
创建型

结构型

行为型


数据流图
数据流图基本概念(Data Flow Diagram,DFD)
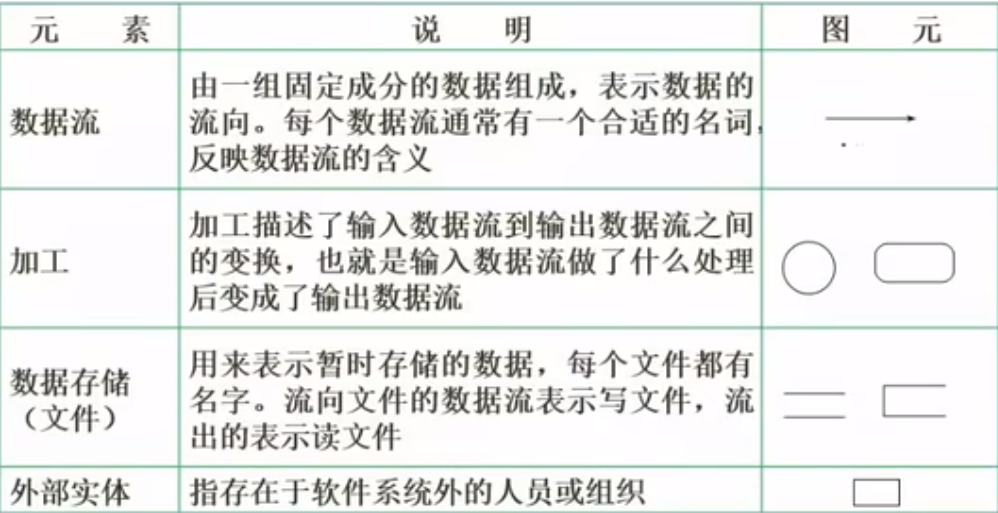
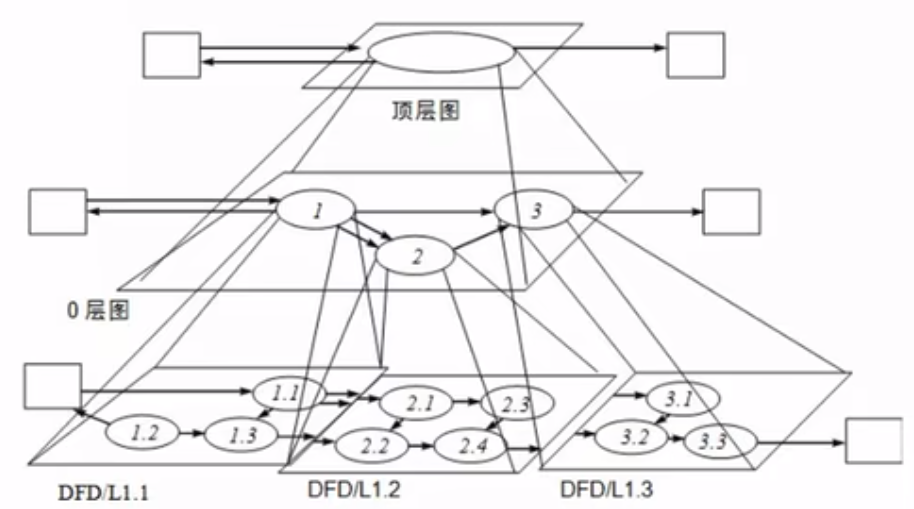
数据流图(分层数据流图)
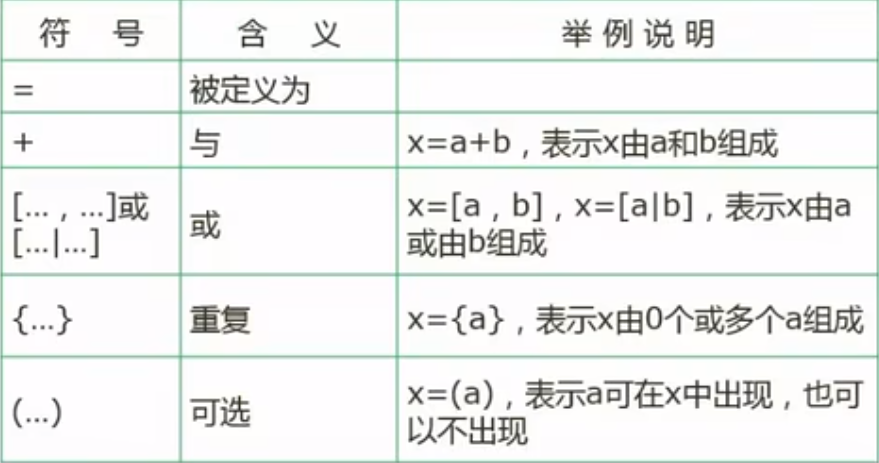
数据字典
案例分析-大题
解题技巧:数据流平衡原则
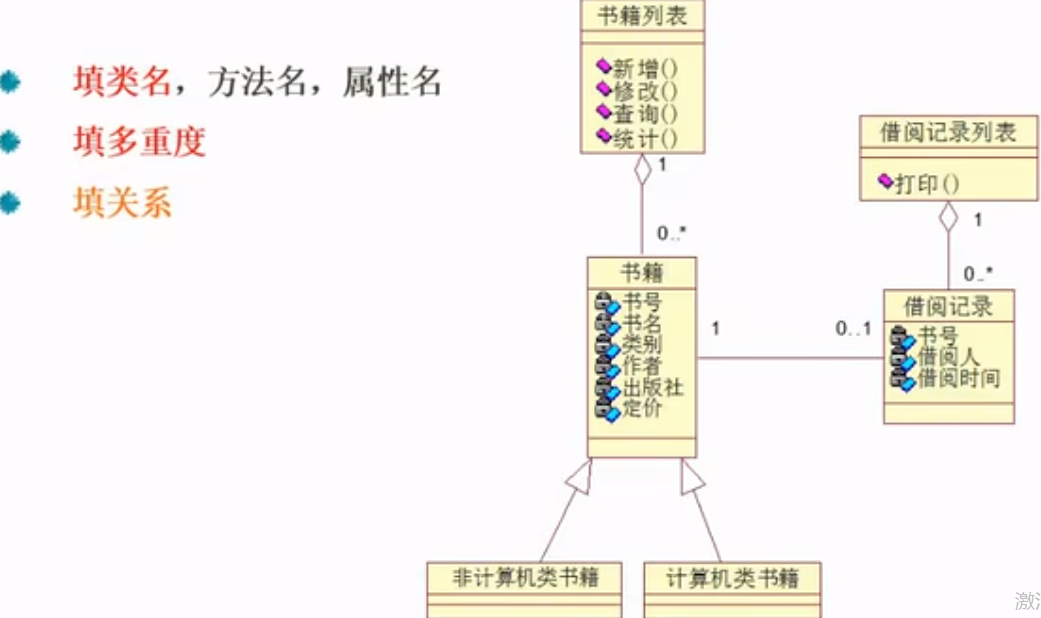
数据库设计(15分)
数据库基础
事务(transaction)指一组SQL语句;
回退(rollback)指撤销指定SQL语句的过程;
提交(commit)指将未存储的SQL语句结果写入数据库表;(执行成功写入数据库)
保留点(savepoint)指事务处理中设置的临时占位符(placeholder),可以对它发布回退(与回退整个 事务处理不同)。
数据库设计过程
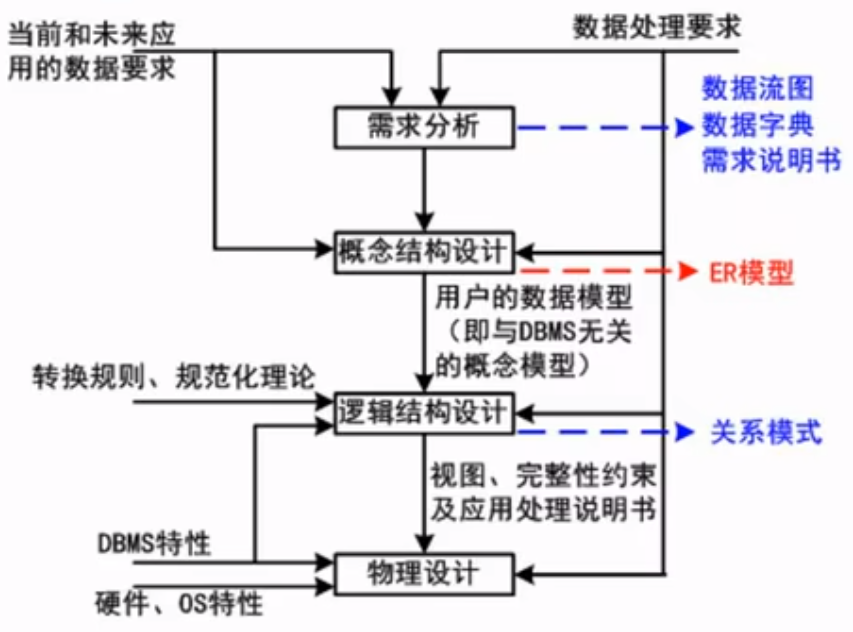
数据库概念结构设计阶段
工作步骤:1抽象数据 2设计局部视图 3合并取消冲突 4修改重构消除冗余
ER模型

案例分析-大题
类与类之间的关系
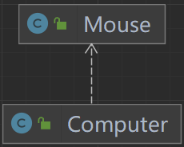
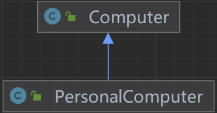
- 单向关联:类A中包含有类B。
- 双向关联:类A中包含有类B,类B中包含有类A。



UML建模
类图
类图(ClassDiadram)展现了一组对象、接口、协作和它们之间的关系。在面向对象系统的建模中,最常见的就是类图,给出系统的静态设计视图。

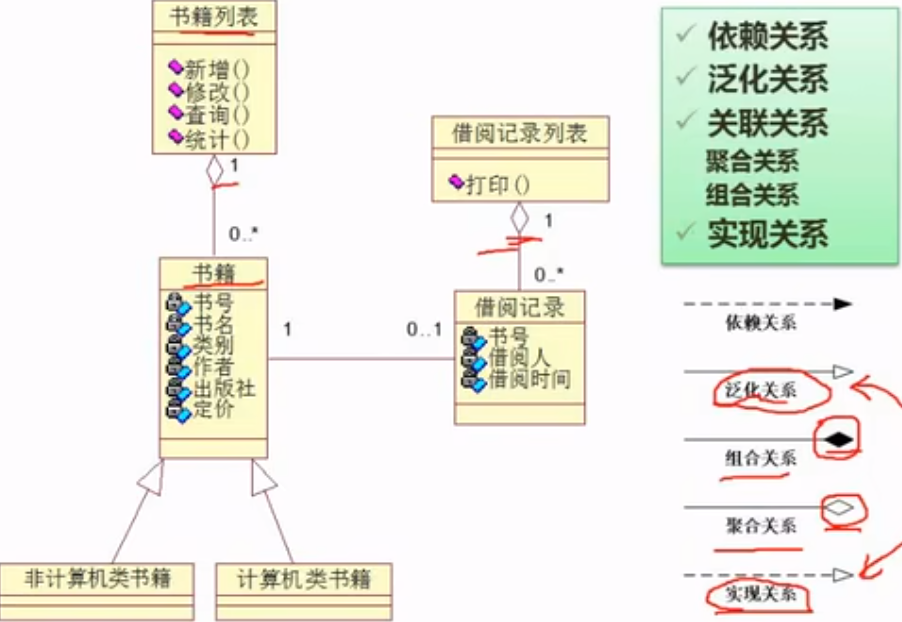
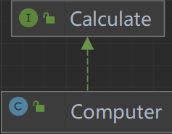
泛化==继承
对象图(ObjectDiagram)
展现了某一时刻一组对象以及他们之间的关系。描述了在类图中所建立的事物的实例的静态快照,给出系统的静态设计视图或静态进程视图。

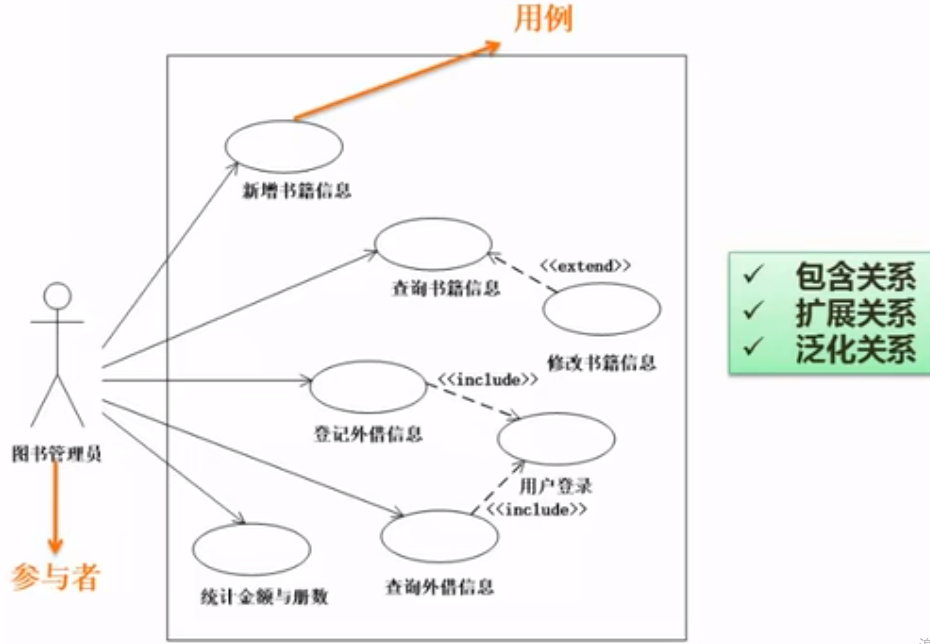
用例图
用例图(UseCaseDiagram)展现了一组用例、参与者(Actor)以及它们之间的关系。这个视图主要支持系统的行为,即该系统在它的周边环境的语境中所提供的外部可见服务。用例图用于对一个系统的需求进行建模,包括说明这个系统应该做什么(从系统外部的一个视点出发),而不考虑系统应该怎样做。
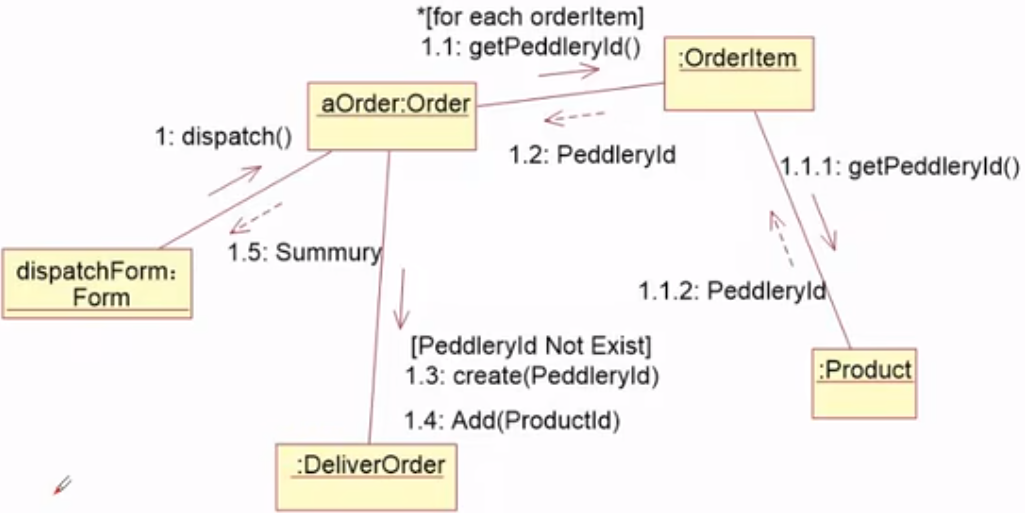
交互图
- 序列图是强调消息时间顺序的交互图;
![]()
- 通信图是强调接收和发送消息的对象的结构组织的交互图
-
![]()
![]()


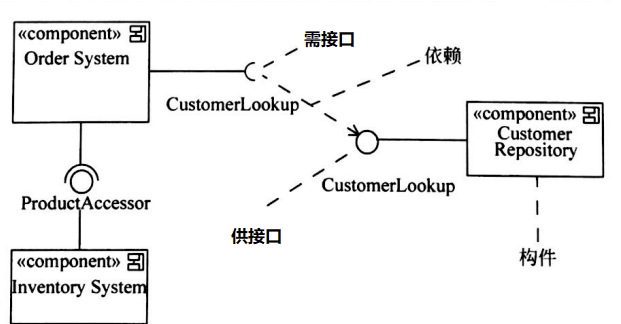
部署图
(DeployDiagram)是用来对面向对象系统的物理方面建模的方法,展现了运行时处理结点以及其中构件(制品)的配置。
组件(构件)图
(ComponentDiagram)展现了一组组件之间的组织和依赖。
活动图
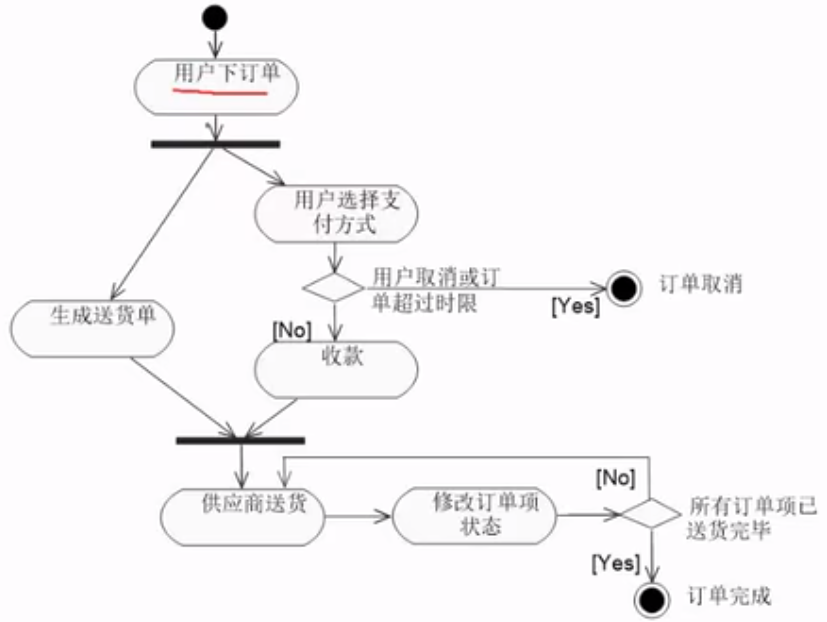
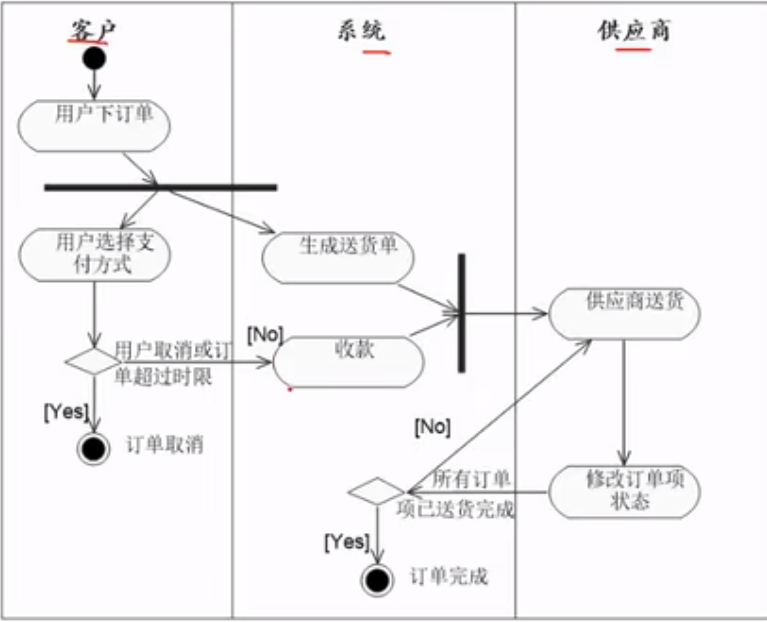
状态图
状态图:也是动态图:描述的是状态的变迁,以状态为节点;箭线:代表的是事件

软件设计需要遵循的原则
软件设计是把许多事物和问题进行抽象,并且需要不同层次和角度的抽象,所以软件设计的基本原则之一是抽象;
软件设计应当模块化,也就是说,软件应在逻辑上分割 为实现特定的功能和子功能的部分;
软件设计还应该遵循信息隐蔽(Information Hiding),即包含在模块内部且其他模块不可访问的内容对其他模块来说是透明的。
信息隐蔽意味着有效的模块性能能够通过定义一套独立的模块来实现,这些模块相互之 间的通信仅仅包括实现软件功能所必需的信息。
封装是手段,它的目的是要达到信息隐蔽。
数据结构与算法
根据考试大纲,本章要求考生掌握以下几个方面的知识点。
(1)数据结构设计:线性表、查找表、树、图的顺序存储结构和链表存储结构的设计和实现。
(2)算法设计:迭代、穷举搜索、递推、递归、回溯、贪心、动态规划、分治等算法设计。
从历年的考试情况来看,本章的考点主要集中以下方面。
在数据结构设计中,主要考查基本数据结构如栈,二叉树的常见操作代码实现。
在算法设计中,主要考查动态规划法、分治法、回溯法、递归法、贪心法。
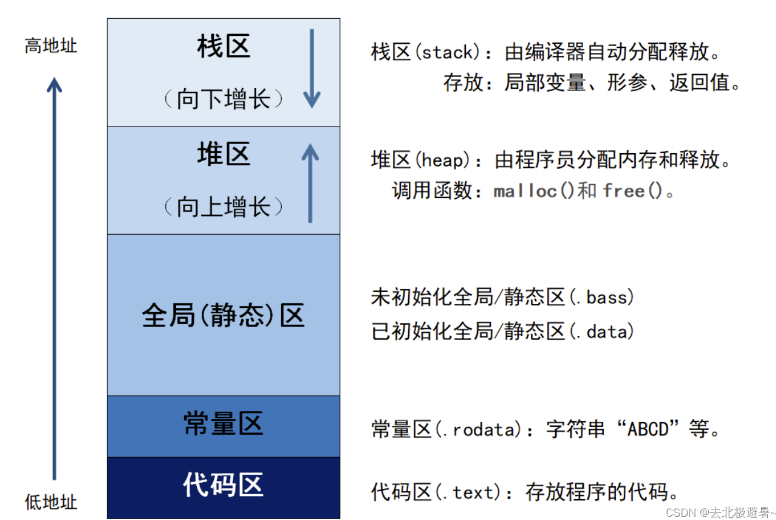
C语言内存五大区
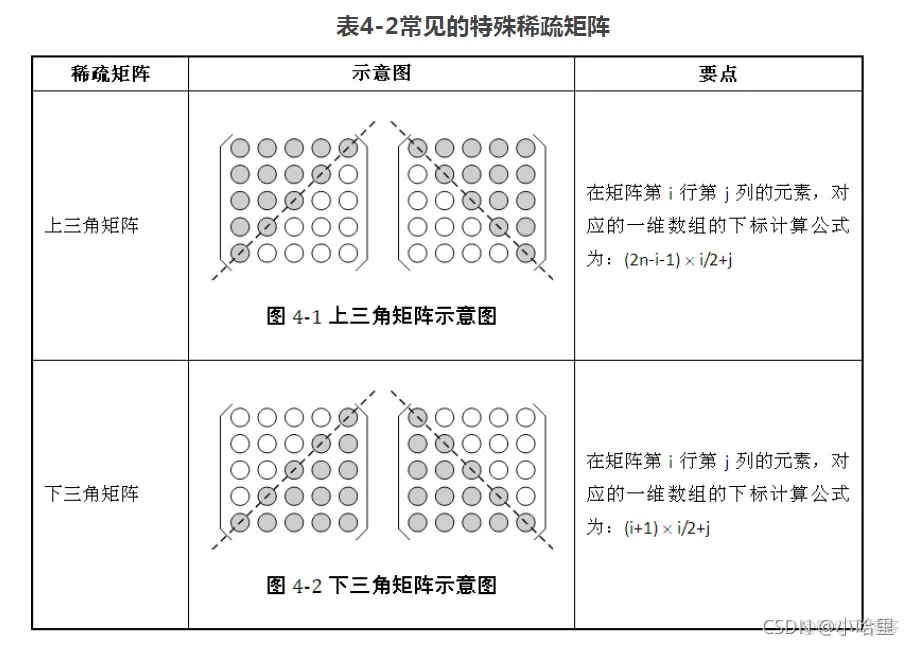
数据结构
数组:计算存储地址
二维数组,第一个称为行下标,第二个称为列下标

稀疏矩阵:选择题:可把选项代入,验证答案是否正确
在计算机中存储一个矩阵时,可使用二维数组。如果一个矩阵的元素绝大部分为零,则称为稀疏矩阵。
若直接用一个二维数组表示稀疏矩阵,则会因存储太多的零元素而浪费大量的内存空间。
在稀疏矩阵中,有一种情况非常常见,即稀疏矩阵内部存在对称性。这样,我们可以采用一维数组来表示它们,这也常称为压缩存储
树的遍历是针对根节点的
前序遍历顺序:根节点--左子树一右子树,根左右
中序遍历顺序:左子树-根节点-右子树,左根右
后序遍历顺序:左子树--右子树-根节点,左右根
算法
分治法
顾名思义就是分而治之的意思。就是把一个复杂的问题拆分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
例子:二分查找法,快速排序
回溯法
可以系统的搜索一个问题的所有解或任一解。 回溯法通常涉及到对问题状态的深度优先搜索,在搜索过程中,算法尝试一步步地构建解决方案,每次决策都会将问题状态转移到下一步,并检查当前状态是否满足问题的要求。如果当前状 态满足问题要求,则继续向下搜索;如果不满足要求,则回溯到上一个状态,并尝试其他的决策。
贪心法
总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,它所做出的仅仅是在某种意义上的局部最优解。
贪心法是一种求解问题的策略,其核心思想是在每一步选择中都采取当前状态下最优的选择,从而希望最终达到全局最优解。
贪心法通常适用于满足「最优子结构]和「贪心选择性质]的问 题。
贪心法体现:Djikstra(迪杰斯特拉)算法,构造最小生成树的Prim(普里姆)算法和Kruskal (克鲁斯卡尔)算法
1.Prim算法(最小生成树)
此算法可以称为“加点法”,每次迭代选择代价最小的边对应的点,加入到最小生成树中。算法从某一个顶点s开始,逐渐长大覆盖整个连通网的所有顶点。
2.Kruskal算法(最小生成树)
此算法可以称为“加边法”,初始最小生成树边数为0,每迭代一次就选择一条满足条件的最小代价边,加入到最小生成树的边集合里。
算法目的:将一个大的任务拆分成若干个小的任务逐个解决来完成拆分之前总任务的效果。
算法过程 1.把求解的问题分成若干个子问题 2.对每个子问题求解,得到子问题的局部最优解 3.把子问题的解局部最优解合成原来问题的一个解
该算法存在的问题 1.不能保证求得的最后解是最佳的 2.只能求满足某些约束条件的可行解的范围
动态规划
将待求问题划分为若干个子问题,按划分的顺序求解子阶段问题,前一个子问题的解,为后一个子问题的求解提供了有用的信息(最优子结构)。在求解任一子问题时,列出各种可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其它局部解。依次解决各个子问题,最后求出原问题的最优解
通常适用于具有「最优子结构]和「重叠子问题]性质的问题。
例子:0/1背包问题
旅行商(Traveling Salesman Problem, TSP):旅行商问题是寻找最短可能路线访问每个城市一次并返回起点的问题。
生成树
对图的所有顶点进行遍历,构成的树结构称为图的生成树。生成树是一个连通且无回路的子图,它包含了原图中所有的节点,但尽可能地减少了边的数量。
生成树是一个图(通常是连通图或无向图)的子图,它满足以下条件:
连通性:生成树中的任意两个顶点之间都存在一条路径。
无环性:生成树中不包含任何环(即闭合的路径)。
包含所有顶点:原图中的所有顶点都出现在生成树中。
边数最少:在所有包含所有顶点的子图中,生成树的边数是最少的。对于含有n个顶点的连通图,其生成树恰好含有n-1条边。
有几种著名的算法可以用来找出图中的生成树,其中最著名的是普里姆(Prim)算法和克鲁斯卡尔(Kruskal)算法。
普里姆算法:从图中的任意一个顶点开始,每次选择与当前生成树距离最短的边,直到所有顶点都包含在生成树中。
克鲁斯卡尔算法:首先对所有边按权重进行排序,然后从小到大依次选择边,如果选择的边不构成环,则将其加入生成树中。
常见题目
分数背包
分数背包问题(Fractional Knapsack Problem)是指在有一个容量限制的背包中,选择放入一些物品以最大化总价值,且物品可以分割。对于分数背包问题,贪心策略是有效的,即按照单位重量的价值比(价值/重量)从高到低对物品排序,然后尽可能多地选取这
些物品。这种方式可以确保获得最大总价值,因为它总是优先考虑性价比最高的物品。
0-1背包
0-1 背包问题与分数背包不同,因为在这个问题中,物品不能分割,只能选择放或不放(0 或 1)。贪心策略在这里不适用,因为最优解可能需要跳过某些高价值但高重量的物品,而选择低价值但轻的物品来达到背包容量限制下的最大价值。
解决 0-1 背包通常需要使用动态规划或回溯等方法。
旅行商问题
旅行商问题是寻找最短可能路线访问每个城市一次并返回起点的问题。贪心策略,比如总是选择最近未访问的城市作为下一个目的地,通常不能保证得到最优解。
TSP 是一个 NP 完全问题,通常需要更复杂的算法如动态规划、近似算法或遗传算法等来求解。
最长公共子序列
Longest Common Subsequence, LCS):LCS 问题是要找到两个序列的最长子序列,该子序列不需要在原序列中连续出现,但必须保持原序列中的相对顺序。贪心策略不能直接有效地解决 LCS 问题,这个问题通常通过动态规划来解决。
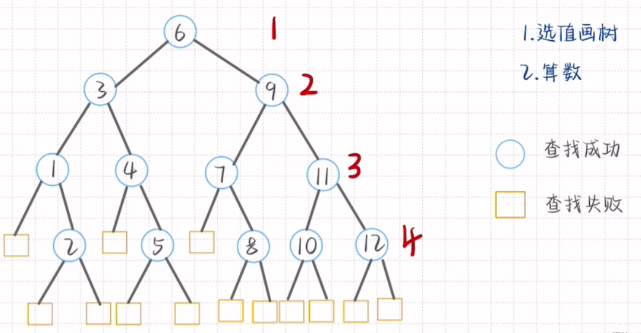
二分查找法的平均查找长度:每个元素的查找次数相加 / 除以元素总数。
查找的次数=每一层的层数×每一层的结点个数,上图即是1x1+2x2+3x4+4x5=37,则查找成功的平均查找长度为37/12
注意:当计算查找失败的平均长度时,层数需要依次减1,即原先第四层变为第三层,然后进行查找失败的次数的计算,即是3x3+4x10=49(以上算式中“x”前面的为层数,后面为该层的结点数), 则对应的查找失败的平均查找长度为49/13
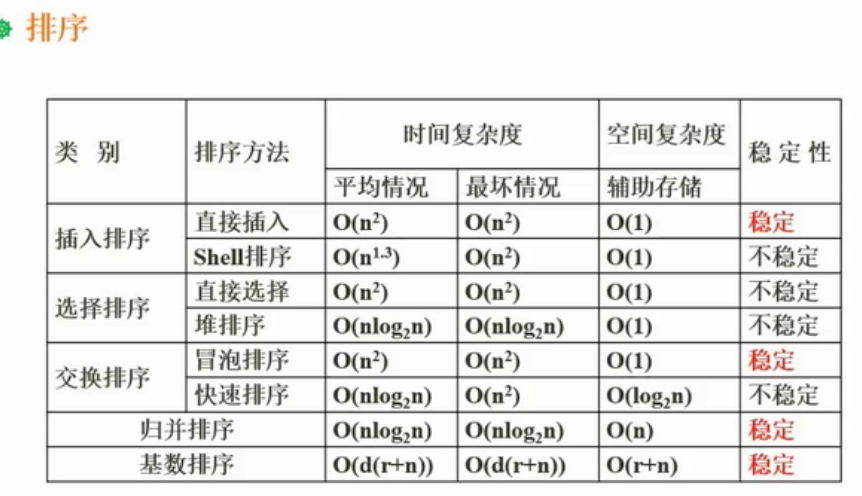
排序
冒泡排序(稳定):基本有序,且数据量较小时。
插入排序(稳定):基本有序,且数据量较小时。
希尔排序(不稳定):当数据量中等时适用,数据越有序,越高效,希尔是对插入排序的一种优化。
选择排序(不稳定):跟数据是否有序无关,数据量较小时适用。
堆排序(不稳定):当数据量较大时适用,最少,最坏与平均时间一致,无需辅助空间。
归并排序(稳定):当数据量较大时适用,最少,最坏与平均时间一致,但需要较多辅助空间。
快速排序(不稳定):分治法---当数据量较大,数据是随机分布时适用,需要一点辅助空间。快速排序的平均时间最短,但可能出现最坏时间。
关键字序列构造二叉排序树的基本过程是, 若需插入的关键字大于树根,则插入到右子树上,若 小于树根,则插入到左子树上,若为空树,则作为树根结点。
动态规划算法总体思想:如果能够保存已解决的子问 题的答案,而在需要时再找出已求得的答案,就可以 避免大量重复计算,从而得到多项式时间算法 从根开始计算,到找到位于某个节点的解,
回溯法 (深度优先搜索)作为最基本的搜索算法,其采用了 一种“一只向下走,走不通就掉头“的思想(体会”回溯” 二字),相当于采用了先根遍历的方法来构造搜索树。
零碎知识
系统开发
人机交互“黄金三原则”包括: 用户操纵控制、减轻用户的记忆负担、保持界面的一致性。
事务型数据库容易形成信息孤岛,而主题数据库不容易形成”信息孤岛”
一般争议处理的流程:先找主管行政管理部门进行仲裁,仲裁不成功再进行诉讼
- 相联地址映射:主存的任意一块可以映象到cache中的任 意一块。
- 直接相联映射:主存中一块只能映象到Cache的一个特 定的块中。
- 组相联的映射:各区中的某一块只能存入缓存的同组号的 空间内,但组内各块地址之间则可以任意存放。即从主存的组 到Cache的组之间采用直接映象方式,在两个对应的组内部 采用全相联映象方式。
- 主存主要采用动态随机存储器DRAM
- Cache采用静态随机存储器SRAM
- EEPROM是电擦除可编程的只读存储器
系统初始化过程可以分为3个主要环节,按照自底向上、 从硬件到软件的次序依次为:片级初始化、板级初始化和系统 级初始化。
系统初始化:该初始化过程以软件初始化为主,主要进行 操作系统的初始化
逆波兰表达式--适合栈
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) * ( 3 + 4 ) 。该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) * ) 。
逆波兰表达式主要有以下两个优点:去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。
适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中。
语法分析
编译程序中语法分析器接受以单词为单位的输入,并产生有关信息供以后各阶段使用。
语法分析技术:算符优先法、LR分析法和递归下降法
LR分析法主要有SLR(1)、LR(0)、LR(1)和LALR(1)等4种,
其中LR(1)的分析能力最强,LR(0)的分析能力最弱。
沟通路径
软件开发小组的沟通路径受到小组组织形式和规模的影响。若任意小组成员之间均可能有沟通路径,则可用完全连通图来对开发小组的沟通路径建模,最多的沟通路径为完全连通图的边数,即n个成员的开发小组的沟通路径是n(n-1)/2,因此8个成员的开发小组的沟通路径有28条
Web应用防护墙(Web Application Firewall,简称 WAF)
是通过执行一系列针对HTTP/HTTPS的安全策 略来专门为Web应用提供保护的一款产品,主要用于 防御针对网络应用层的攻击,像SQL注入、跨站脚本 攻击、参数篡改、应用平台漏洞攻击、拒绝服务攻击 等。流氓软件已经处于系统内部了,无法有效防止。
二叉排序树(BST,Binary Sort Tree)
二叉排序树(也称为二叉查找树)或者是一棵空树,或者是具有以下特性的二叉树:
1)若左子树非空,则左子树上所有结点的值均小于根节点的值。
2)若右子树非空,则右子树上所有结点的值均大于根节点的值。
3)左、右子树也分别是一棵二叉排序树。
根据二叉排序树的定义,左子树结点值<根节点值<右子树结点值,所以对二叉排序树进行中序遍历,可以得到一个递增的有序序列。
例如,图所示的二叉排序树的中序遍历序列为123468。

哈夫曼树
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。
哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。哈夫曼树又称最优树
特点:哈夫曼树只有度为0和2的结点,包含n棵树的森林要经过n-1次合并才能形成哈夫曼树,共产生n-1个结点,所以包含n个叶子结点的哈夫曼树中共有n+n-1=2n-1个结点

结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积
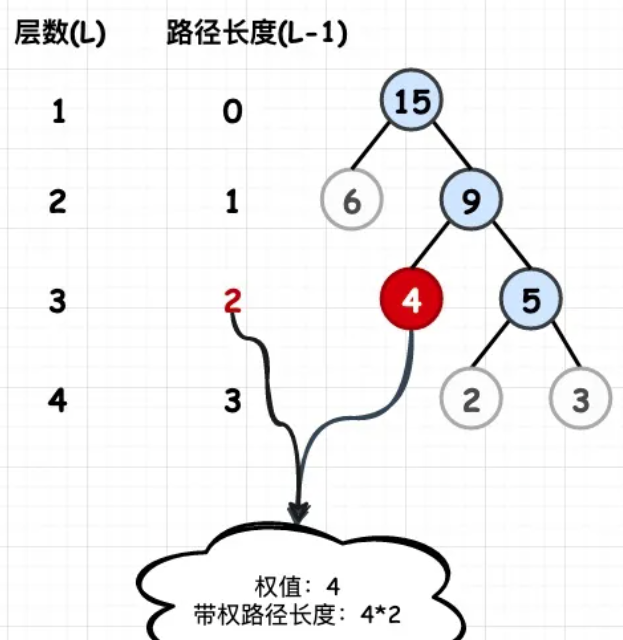
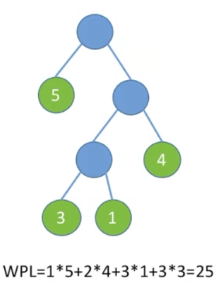
树的带权路径长度规定为:所有叶子结点的带权路径长度之和

CPU强调通用性,需要处理各种数据类型,又要进行 逻辑判断进行大量的分支跳转和中断的处理。因此CPU内部结构异常复杂。
CPU利用较高的主频和高速缓存来提升执行指令的速度
GPU面对的是类型高度统一、相互无依赖的大规模数据和不需要被打断的纯净计算环境。
GPU是一种单指令多数据流(Single Instruction Multiple Data,SIMD) 架构,特点是比CPU包含更多的计算单元和更简单的控制单元。
无向完全图:结点为n的边数为:n(n-1)/2
有向完全图:结点为n的边数为:n(n-1)
有向完全图与无向完全图的区别是,有向完全图的两个结点可以连接两条边。

Armstrong公理(Armstrong's Axioms)
由计算机科学家W.W. Armstrong于1974年提出,是关系数据库设计中函数依赖理论的逻辑基础,用于验证关系模式的规范化(如2NF、3NF、BCNF)。其核心作用是通过逻辑推理从已知的函数依赖集推导出所有隐含的函数依赖,确保数据依赖的完整性。
三条基本公理
- 自反律(Reflexivity Rule):若属性集Y⊆X⊆UY⊆X⊆U,则X→YX→Y成立。例如,{学号,姓名}→{学号}{学号,姓名}→{学号}是平凡依赖。
- 增广律(Augmentation Rule):若X→YX→Y成立且Z⊆UZ⊆U,则XZ→YZXZ→YZ成立。例如,已知{学号}→{姓名}{学号}→{姓名},可推出{学号,课程}→{姓名,课程}{学号,课程}→{姓名,课程}。
- 传递律(Transitivity Rule):若X→YX→Y且Y→ZY→Z,则X→ZX→Z成立。例如,{学号}→{班级}{学号}→{班级}和{班级}→{班主任}{班级}→{班主任}可推导出{学号}→{班主任}{学号}→{班主任}。
衍生规则
通过基本公理可推导出以下常用规则:
- 合并规则:若X→YX→Y且X→ZX→Z,则X→YZX→YZ(由增广律和传递律导出)。
- 分解规则:若X→YZX→YZ,则X→YX→Y且X→ZX→Z(与合并规则互为逆过程)。
- 伪传递规则:若X→YX→Y且WY→ZWY→Z,则XW→ZXW→Z(结合增广律与传递律)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号