

ConcurrentHashMap
ConcurrentHashMap 线程安全的具体实现方式
JDK1.7
1 存储结构
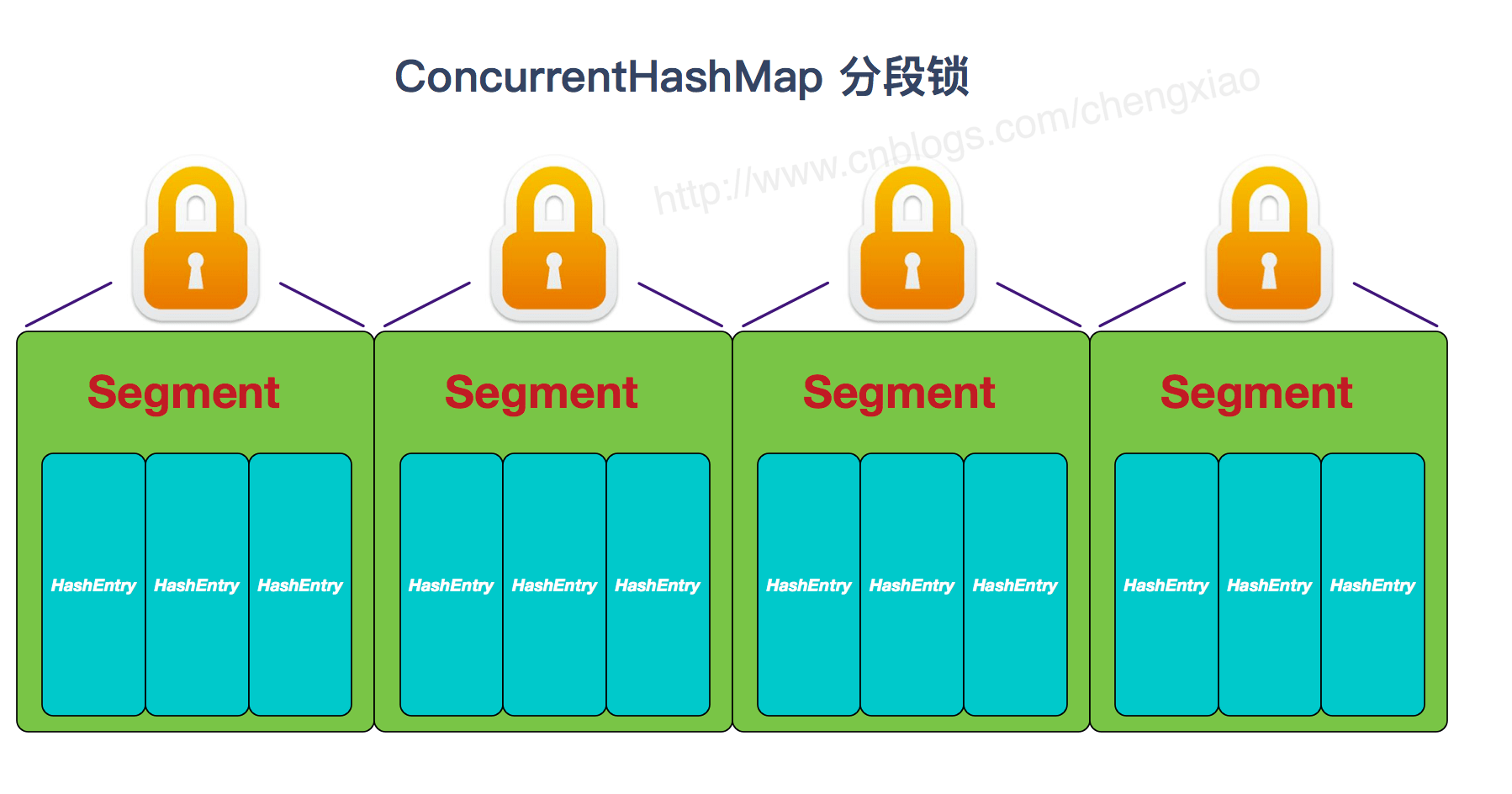
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据
一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和 HashMap 类似,是一种数组和链表结构,但是 Segment 的个数一旦初始化就不能改变。
一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。
初始化
- 必要参数校验。
- 校验并发级别 concurrencyLevel 大小,如果大于最大值,重置为最大值。无参构造默认值是 16.
- 寻找并发级别 concurrencyLevel 之上最近的 2 的幂次方值,作为初始化容量大小,默认是 16。
- 记录 segmentShift 偏移量,这个值为【容量 = 2 的N次方】中的 N,在后面 Put 时计算位置时会用到。默认是 32 - sshift = 28.
- 记录 segmentMask,默认是 ssize - 1 = 16 -1 = 15.
- 初始化 segments[0],默认大小为 2,负载因子 0.75,扩容阀值是 2*0.75=1.5,插入第二个值时才会进行扩容。
put
-
计算要 put 的 key 的位置,获取指定位置的 Segment。
-
如果指定位置的 Segment 为空,则初始化这个 Segment.初始化 Segment 流程:

3. Segment.put 插入 key,value 值。
由于 Segment 继承了 ReentrantLock,所以 Segment 内部可以很方便的获取锁,put 流程就用到了这个功能。
-
tryLock() 获取锁,获取不到使用
scanAndLockForPut方法继续获取。 -
计算 put 的数据要放入的 index 位置,然后获取这个位置上的 HashEntry 。
-
遍历 put 新元素,为什么要遍历?因为这里获取的 HashEntry 可能是一个空元素,也可能是链表已存在,所以要区别对待。
如果这个位置上的 HashEntry 不存在:
- 如果当前容量大于扩容阀值,小于最大容量,进行扩容。
- 直接头插法插入。
如果这个位置上的 HashEntry 存在:
- 判断链表当前元素 Key 和 hash 值是否和要 put 的 key 和 hash 值一致。一致则替换值
- 不一致,获取链表下一个节点,直到发现相同进行值替换,或者链表表里完毕没有相同的。
- 如果当前容量大于扩容阀值,小于最大容量,进行扩容。
- 直接链表头插法插入。
-
如果要插入的位置之前已经存在,替换后返回旧值,否则返回 null
- .
JDK1.8
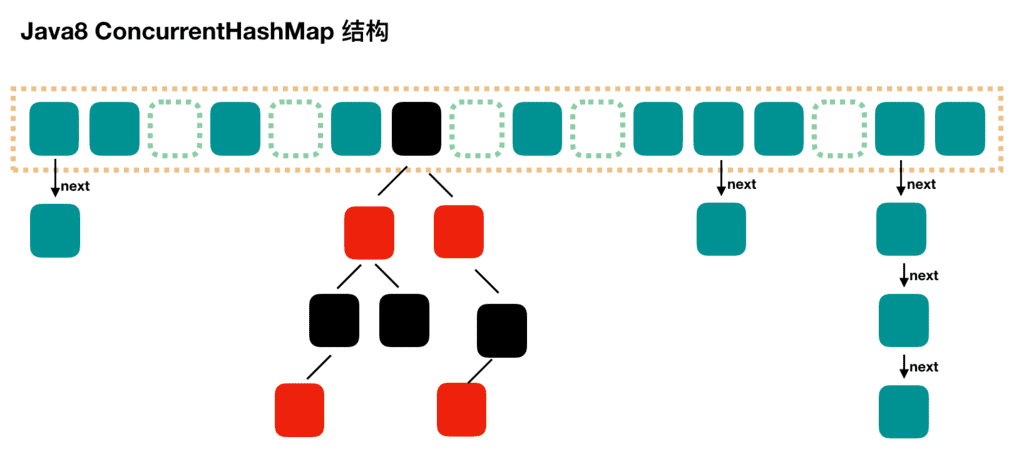
结构

put
-
根据 key 计算出 hash 。
-
判断tab数组是否需要进行初始化。
-
为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
-
如果当前位置的
hash == MOVED == -1,则需要进行扩容。 -
如果都不满足,则利用 synchronized 锁写入数据。
-
如果数量大于
TREEIFY_THRESHOLD(8)则要执行树化方法,在treeifyBin中会首先判断当前数组长度≥64时才会将链表转换为红黑树

 浙公网安备 33010602011771号
浙公网安备 33010602011771号