

R语言网络爬虫初学者指南(使用rvest包)
作者 SAURAV KAUSHIK
译者 钱亦欣
引言
网上的数据和信息无穷无尽,如今人人都用百度谷歌来作为获取知识,了解新鲜事物的首要信息源。所有的这些网上的信息都是直接可得的,而为了满足日益增长的数据需求,我坚信网络数据爬取已经是每个数据科学家的必备技能了。在本文的帮助下,你将会突破网络爬虫的技术壁垒,实现从不会到会。
大部分网上呈现的信息都是以非结构化的格式存储(html)且不提供直接的下载链接,因此,我们需要学习一些知识和经验来获取这些数据。
本文我将带你领略利用R做网络数据采集的全过程,通读文章后你将掌握如何来使用因特网上各位数据的技能。
目录
- 什么是网络数据爬取
- 为什么需要爬取数据
- 数据爬取方法
- 前提条件
- 使用R爬取网页
- 分析从网页爬取的数据
1. 什么是网络数据爬取
网络爬虫是讲呈现在网页上以非结构格式(html)存储的数据转化为结构化数据的技术,该技术非常简单易用。
几乎所有的主流编程语言都提供了网络数据爬取的实现方式,本文我们会用R来爬取IMDB上2016年最热门电影的一些特征。
我们将采集2016年度最热门电影的若干特征,同时我们也会遇到网页代码不一致的问题并将其解决。这是在做网络爬虫时最常遇到的问题之一。
如果你更喜欢用python变成,我建议你看这篇指南来学习如何用python做爬虫。
2. 为什么需要爬取数据
我确信你现在肯定在问“为什么需要爬取数据”,正如前文所述,爬取网页数据极有可能。(译者注:原文如此,我没看懂这个设问的逻辑)
为了提供一些使用的知识,我们将会爬取IMDB的数据,同时,利用爬虫你还可以:
- 爬取电影评分来构建推荐系统
- 爬取维基百科等信源的文本作为训练预料来构建深度学习模型以实现主体识别等功能
- 爬取有标签的图像(从Google,Flickr等网站)来训练图像分类模型
- 爬取社交媒体数据(Facebook 和 Twitter 等)做情感分析,观点挖掘等
- 爬取电商的用户评论和反馈(从Amazon,Flipkart等)
3. 数据爬取方法
网络数据抓取的方式有很多,常用的有:
- 人工复制粘贴:这是采集数据的缓慢但有效的方式,相关的工作人员会自行分析并把数据复制到本地。
- 文本模式匹配:另一种简单有效的方法是利用编程语言中的正则表达式来匹配固定模式的文本,在这里你可以学到关于正则表达式的更多内容。
- 使用API:诸如Facebook,Twitter和Linkedin一类的许多网站都提供了公共或者私人的API,它们提供了标准化的代码供用户请求规定格式的数据。
- DOM解析:程序可以使用浏览器来获取客户端脚本生成的动态内容。基于这些程序可以获得的页面来使用DOM树来解析网页也是可行的办法,
我们会使用DOM解析的方式来获取数据,并基于网页的CSS选择器来寻找含有所需信息的网页部分。但在开始之前,我们必须满足一些前提条件。
4. 前提条件
利用R实现网络爬虫的前提条件有两大块:
-
要写R语言爬虫,你对R必须有一定了解。如果你还是个新手,我强烈建议参照这个学习路径 来学习。本文将使用“Hadley Wickham(Hadley我爱你!!!)”开发的“rvest”包来实现爬虫。你可以从这里获得这个包的文档。如果你没有安装这个包,请执行以下代码。
install.packages('rvest')
-
除此之外,HTML,CSS的相关知识也很重要。学习他们的有一个很好的资源。我见识过不少对HTML和CSS缺乏了解的数据科学家,因此我们将使用名为Selector Gadget的开源软件来更高效地实现抓取。你可以在这里下载这个工具包。请确保你的浏览器已经安装了这个插件(推荐用chrome浏览器),并且能正常使用。(译者注:chrome中的css viewer 和 xpath helper 也是神器。)
![img]()

使用这个插件你可以通过点击任一网页中你需要的数据就能获得相应的标签。你也可以学习HTML和CSS的知识并且手动实现这一过程。而且,为了更深入地了解网络爬取这一艺术,我很推荐你学习下HTML和CSS来了解其背后的机理。
5. 使用R爬取网页
现在让我们开始爬取IMDB上2016年度最流行的100部故事片,你可以在这里查看相关信息。
# 加载包
library('rvest')
# 指定要爬取的url
url <- 'http://www.imdb.com/search/title?
count=100&release_date=2016,2016&title_type=feature'
# 从网页读取html代码
webpage <- read_html(url)
现在,让我们爬取网页上的这些数据:
- Rank:从1到100,代表排名
- Title:故事片的标题
- Description:电影内容简介
- Runtime: 电影时长
- Genre: 电影类型
- Rating: IMDB提供的评级
- Metascore: IMDB上该电影的评分
- Votes: 电影的好评度
- Gross_Earning_in_Mil: 电影总票房(百万)
- Director: 影片的总导演,如果有多位,取第一个
- Actor: 影片的主演,如果有多位,取第一个
这是页面的截图
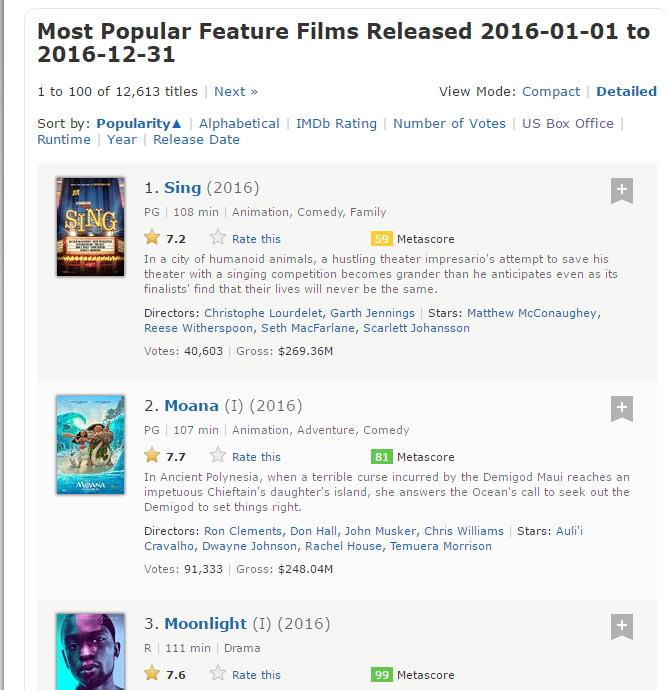
Step 1: 爬取的第一步是使用 selector gadget获得排名的CSS选择器。你可以点击浏览器中的插件图标并用光标点击排名的区域。

要确保所有的排名都被选择了,你也可以再次点击选中区域来取消选择,最终只有高亮的那些部分会被爬取。
Step 2: 一旦你已经选择了正确的区域,你需要把在底部中心显示的相应的CSS选择器复制下来。

Step 3: 只要CSS选择器包含排名,你就能用几行简单的代码来获取所有的排名了:
# 用CSS选择器获取排名部分
rank_data_html <- html_nodes(webpage,'.text-primary')
# 把排名转换为文本
rank_data <- html_text(rank_data_html)
# 检查一下数据
head(rank_data)
[1] "1." "2." "3." "4." "5." "6."
Step 4: 获取数据之后,请确保他们被你所需的格式存储,我会把排名处理成数值型。
# 数据预处理:把排名转换为数值型
rank_data<-as.numeric(rank_data)
# 再检查一遍
head(rank_data)
[1] 1 2 3 4 5 6
Step 5: 现在你可以清空选择部分并开始选择电影标题了,你可以看见所有的标题都被选择了,你依据个人需要做一些增删。

Step 6: 正如从前,再次复制CSS选择器并用下列代码爬取标题。
# 爬取标题
title_data_html <- html_nodes(webpage,'.lister-item-header a')
# 转换为文本
title_data <- html_text(title_data_html)
# 检查一下
head(title_data)
[1] "Sing" "Moana" "Moonlight" "Hacksaw Ridge"
[5] "Passengers" "Trolls"
Step 7: 下列代码会爬取剩余的数据– Description, Runtime, Genre, Rating, Metascore, Votes, Gross_Earning_in_Mil , Director and Actor data.
# 爬取描述
description_data_html <- html_nodes(webpage,'.ratings-bar+ .text-muted')
# 转为文本
description_data <- html_text(description_data_html)
# 检查一下
head(description_data)
[1] "\nIn a city of humanoid animals, a hustling theater impresario's attempt to save his theater with a singing competition becomes grander than he anticipates even as its finalists' find that their lives will never be the same."
[2] "\nIn Ancient Polynesia, when a terrible curse incurred by the Demigod Maui reaches an impetuous Chieftain's daughter's island, she answers the Ocean's call to seek out the Demigod to set things right."
[3] "\nA chronicle of the childhood, adolescence and burgeoning adulthood of a young, African-American, gay man growing up in a rough neighborhood of Miami."
[4] "\nWWII American Army Medic Desmond T. Doss, who served during the Battle of Okinawa, refuses to kill people, and becomes the first man in American history to receive the Medal of Honor without firing a shot."
[5] "\nA spacecraft traveling to a distant colony planet and transporting thousands of people has a malfunction in its sleep chambers. As a result, two passengers are awakened 90 years early."
[6] "\nAfter the Bergens invade Troll Village, Poppy, the happiest Troll ever born, and the curmudgeonly Branch set off on a journey to rescue her friends.
# 移除 '\n'
description_data<-gsub("\n","",description_data)
# 再检查一下
head(description_data)
[1] "In a city of humanoid animals, a hustling theater impresario's attempt to save his theater with a singing competition becomes grander than he anticipates even as its finalists' find that their lives will never be the same."
[2] "In Ancient Polynesia, when a terrible curse incurred by the Demigod Maui reaches an impetuous Chieftain's daughter's island, she answers the Ocean's call to seek out the Demigod to set things right."
[3] "A chronicle of the childhood, adolescence and burgeoning adulthood of a young, African-American, gay man growing up in a rough neighborhood of Miami."
[4] "WWII American Army Medic Desmond T. Doss, who served during the Battle of Okinawa, refuses to kill people, and becomes the first man in American history to receive the Medal of Honor without firing a shot."
[5] "A spacecraft traveling to a distant colony planet and transporting thousands of people has a malfunction in its sleep chambers. As a result, two passengers are awakened 90 years early."
[6] "After the Bergens invade Troll Village, Poppy, the happiest Troll ever born, and the curmudgeonly Branch set off on a journey to rescue her friends."
# 爬取runtime section
runtime_data_html <- html_nodes(webpage,'.text-muted .runtime')
# 转为文本
runtime_data <- html_text(runtime_data_html)
# 检查一下
head(runtime_data)
[1] "108 min" "107 min" "111 min" "139 min" "116 min" "92 min"
# 数据预处理: 去除“min”并把数字转换为数值型
runtime_data <- gsub(" min","",runtime_data)
runtime_data <- as.numeric(runtime_data)
# 再检查一下
head(rank_data)
[1] 1 2 3 4 5 6
# 爬取genre
genre_data_html <- html_nodes(webpage,'.genre')
# 转为文本
genre_data <- html_text(genre_data_html)
# 检查一下
head(genre_data)
[1] "\nAnimation, Comedy, Family "
[2] "\nAnimation, Adventure, Comedy "
[3] "\nDrama "
[4] "\nBiography, Drama, History "
[5] "\nAdventure, Drama, Romance "
[6] "\nAnimation, Adventure, Comedy "
# 去除“\n”
genre_data<-gsub("\n","",genre_data)
# 去除多余空格
genre_data<-gsub(" ","",genre_data)
# 每部电影只保留第一种类型
genre_data<-gsub(",.*","",genre_data)
# 转化为因子
genre_data<-as.factor(genre_data)
# 再检查一下
head(genre_data)
[1] Animation Animation Drama Biography Adventure Animation
10 Levels: Action Adventure Animation Biography Comedy Crime Drama ... Thriller
# 爬取IMDB rating
rating_data_html <- html_nodes(webpage,'.ratings-imdb-rating strong')
# 转为文本
rating_data <- html_text(rating_data_html)
# 检查一下
head(rating_data)
[1] "7.2" "7.7" "7.6" "8.2" "7.0" "6.5"
# 转为数值型
rating_data<-as.numeric(rating_data)
# 再检查一下
head(rating_data)
[1] 7.2 7.7 7.6 8.2 7.0 6.5
# 爬取votes section
votes_data_html <- html_nodes(webpage,'.sort-num_votes-visible span:nth-child(2)')
# 转为文本
votes_data <- html_text(votes_data_html)
# 检查一下
head(votes_data)
[1] "40,603" "91,333" "112,609" "177,229" "148,467" "32,497"
# 移除“,”
votes_data<-gsub(",", "", votes_data)
# 转为数值型
votes_data<-as.numeric(votes_data)
# 再检查一下
head(votes_data)
[1] 40603 91333 112609 177229 148467 32497
# 爬取directors section
directors_data_html <- html_nodes(webpage,'.text-muted+ p a:nth-child(1)')
# 转为文本
directors_data <- html_text(directors_data_html)
# 检查一下
head(directors_data)
[1] "Christophe Lourdelet" "Ron Clements" "Barry Jenkins"
[4] "Mel Gibson" "Morten Tyldum" "Walt Dohrn"
# 转为因子
directors_data<-as.factor(directors_data)
# 爬取actors section
actors_data_html <- html_nodes(webpage,'.lister-item-content .ghost+ a')
# 转为文本
actors_data <- html_text(actors_data_html)
# 检查一下
head(actors_data)
[1] "Matthew McConaughey" "Auli'i Cravalho" "Mahershala Ali"
[4] "Andrew Garfield" "Jennifer Lawrence" "Anna Kendrick"
# 转为因子
actors_data<-as.factor(actors_data)
我时爬Metascore时遇到问题,我希望你能仔细看看。
# 爬取metascore section
metascore_data_html <- html_nodes(webpage,'.metascore')
# 转为文本
metascore_data <- html_text(metascore_data_html)
# 检查一下
head(metascore_data)
[1] "59 " "81 " "99 " "71 " "41 "
[6] "56 "
# 去除多余空格
metascore_data<-gsub(" ","",metascore_data)
# 检查metascore data的长度
length(metascore_data)
[1] 96
Step 8: meta score只有96个数据,可我们却爬取了100部电影。这个问题产生的原型是由4部电影没有Metascore数据。
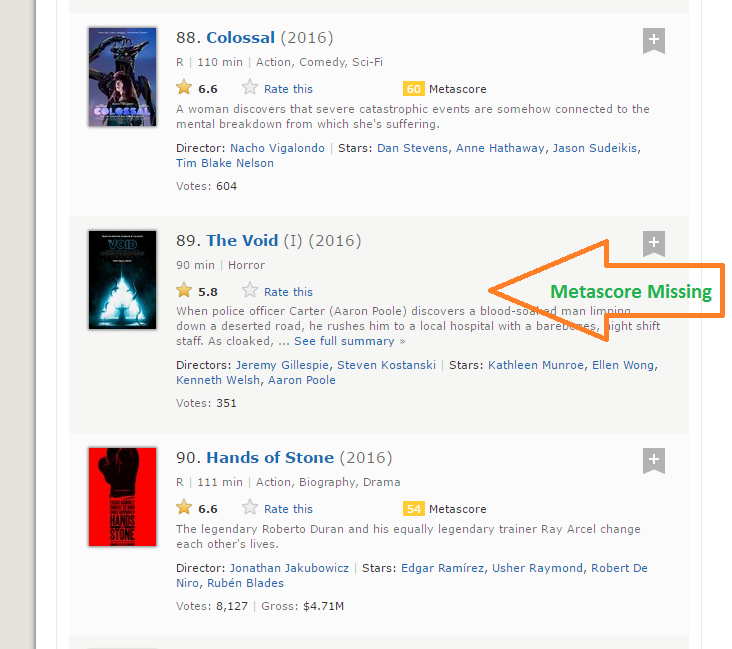
Step 9: 这是爬取所有网页都会遇到的常见问题,如果我们只是简单地用NA来填充这四个缺失值,它会自动填充第97到100部电影。通过一些可视化检查,我们发缺失matascore的是第39,73,80和89部电影。我用下面的函数来解决这个问题。
for (i in c(39,73,80,89)){
a <- metascore_data[1:(i-1)]
b<-metascore_data[i:length(metascore_data)]
metascore_data <- append(a, list("NA"))
metascore_data <- append(metascore_data, b)
}
# 转换为数值型
metascore_data <- as.numeric(metascore_data)
# 再次检查下长度
length(metascore_data)
[1] 100
# 看看描述性统计量
summary(metascore_data)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
23.00 47.00 60.00 60.22 74.00 99.00 4
Step 10: 同样的问题也会发生在Gross变量上,我用同样的方式来解决。
# 爬取revenue section
gross_data_html <- html_nodes(webpage,'.ghost~ .text-muted+ span')
# 转为文本
gross_data <- html_text(gross_data_html)
# 检查一下
head(gross_data)
[1] "$269.36M" "$248.04M" "$27.50M" "$67.12M" "$99.47M" "$153.67M"
# 去除'$' 和 'M' 标记
gross_data <- gsub("M", "", gross_data)
gross_data <- substring(gross_data, 2, 6)
# 检查长度
length(gross_data)
[1] 86
# 填充缺失值
for (i in c(17,39,49,52,57,64,66,73,76,77,80,87,88,89)){
a <- gross_data[1:(i-1)]
b <- gross_data[i:length(gross_data)]
gross_data <- append(a, list("NA"))
gross_data <- append(gross_data, b)
}
# 转为数值
gross_data<-as.numeric(gross_data)
# 再次检车长度
length(gross_data)
[1] 100
summary(gross_data)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.08 15.52 54.69 96.91 119.50 530.70 14
Step 11: .我们已经成功爬取了100部电影的11个特征,让我们创建一个数据框并看看结构。
# 合并所有list来创建一个数据框
movies_df <- data.frame(
Rank = rank_data,
Title = title_data,
Description = description_data,
Runtime = runtime_data,
Genre = genre_data,
Rating = rating_data,
Metascore = metascore_data,
Votes = votes_data,
Gross_Earning_in_Mil = gross_data,
Director = directors_data,
Actor = actors_data
)
# 查看数据框结构
str(movies_df)
'data.frame' : 100 obs. of 11 variables:
$ Rank : num 1 2 3 4 5 6 7 8 9 10 ...
$ Title : Factor w/ 99 levels "10 Cloverfield Lane",..: 66 53 54 32 58 93 8 43 97 7 ...
$ Description : Factor w/ 100 levels "19-year-old Billy Lynn is brought home for a victory tour after a harrowing Iraq battle. Through flashbacks the film shows what"| __truncated__,..: 57 59 3 100 21 33 90 14 13 97 ...
$ Runtime : num 108 107 111 139 116 92 115 128 111 116 ...
$ Genre : Factor w/ 10 levels "Action","Adventure",..: 3 3 7 4 2 3 1 5 5 7 ...
$ Rating : num 7.2 7.7 7.6 8.2 7 6.5 6.1 8.4 6.3 8 ...
$ Metascore : num 59 81 99 71 41 56 36 93 39 81 ...
$ Votes : num 40603 91333 112609 177229 148467 ...
$ Gross_Earning_in_Mil: num 269.3 248 27.5 67.1 99.5 ...
$ Director : Factor w/ 98 levels "Andrew Stanton",..: 17 80 9 64 67 95 56 19 49 28 ...
$ Actor : Factor w/ 86 levels "Aaron Eckhart",..: 59 7 56 5 42 6 64 71 86 3 ...
现在2016年上映的最流行的100部故事片在IMDB上的数据已经爬取成功了!
6. 分析从网页爬取的数据
爬取好数据后,你们队数据进行一些分析与推断,训练一些机器学习模型。我在上面这个数据集的基础上做了一些有趣的可视化来回答下面的问题。
library('ggplot2')
qplot(data = movies_df,Runtime,fill = Genre,bins = 30)
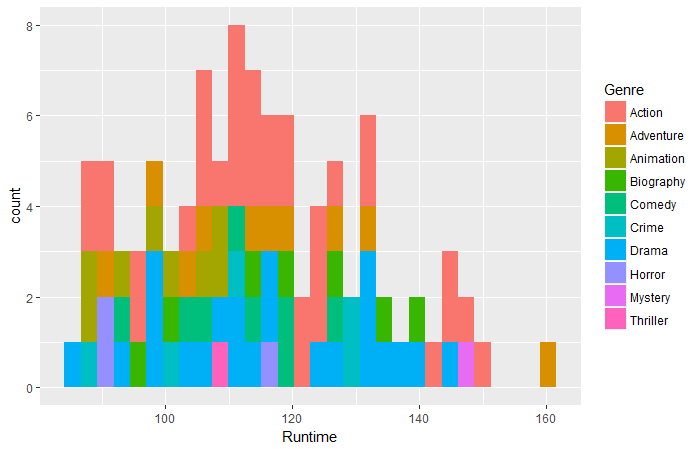
**Question 1: ** 那个类型的电影市场最长?
ggplot(movies_df,aes(x=Runtime,y=Rating))+
geom_point(aes(size=Votes,col=Genre))

**Question 2: ** 市场130-160分钟的电影里,哪一类型东西好评率最高?
ggplot(movies_df,aes(x=Runtime,y=Gross_Earning_in_Mil))+
geom_point(aes(size=Rating,col=Genre))
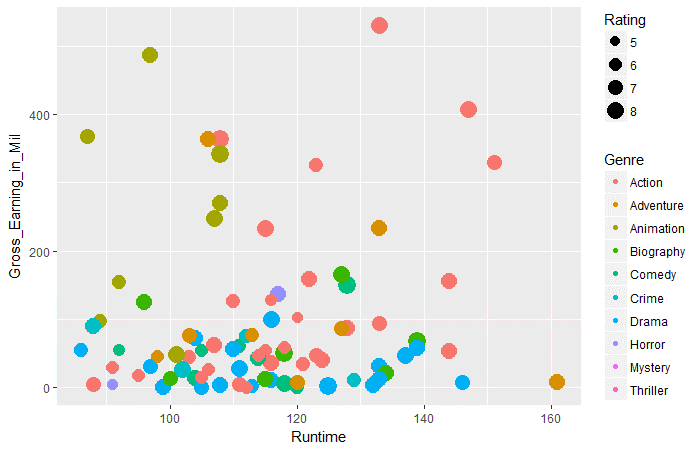
**Question 3: ** 100-120分钟的电影中,哪类作品的票房成绩最好
结语
我相信本文会让你对利用R爬取网页有一定了解,你对采集数据过程中可能遇到的问题也有所涉猎了。由于网页上的大部分数据是非结构化的,爬虫真的是非常重要的一项技能。
原文链接:https://www.analyticsvidhya.com/blog/2017/03/beginners-guide-on-web-scraping-in-r-using-rvest-with-hands-on-knowledge/
爬虫利器Rvest包
说在前面
如果读过了上一篇文章,应该对Rcurl和XML包进行爬虫有了一定得了解。实际上,这个组合虽然功能强大,但是经常会出一点意想不到的小问题。这篇文章我将介绍更便捷的Rvest包真正的快速爬取想要的数据。主要内容
还是以上篇文章的豆瓣图书 Top250为例,我们只需要以下几行代码就可以实现与上文一样的效果:
library(rvest)
web<-read_html("https://book.douban.com/top250?icn=index-book250-all",encoding="UTF-8")
position<-web %>% html_nodes("p.pl") %>% html_text()
逐行解读一下。
第一行是加载Rvest包。
第二行是用read_html函数读取网页信息(类似Rcurl里的getURL),在这个函数里只需写清楚网址和编码(一般就是UTF-8)即可。
第三行是获取节点信息。用%>%符号进行层级划分。web就是之前存储网页信息的变量,所以我们从这里开始,然后html_nodes()函数获取网页里的相应节点。在下面代码里我简单的重现了原网页里的一个层级结构。可以看到,实际上我们要爬取的信息在25个class属性为pl的<p>标签里的文本。
<p class="pl">
[清] 曹雪芹 著 / 人民文学出版社 / 1996-12 / 59.70元
</p>
而对于这样的结构,在htmlnodes()函数里的写法就是简单的 "p.pl",其中“.”表示class属性的值,如果是id属性则用“#”,如果大家学过CSS选择器就很好理解了,是完全一致的。
最后我们用html_text()函数表示获取文本信息,否则返回的是整个<p>标签。总体上用以下一行代码就可以实现:
position<-web %>% html_nodes("p.pl") %>% html_text()
比较与XML获取节点的方法(如下行代码),其实二者是异曲同工的,只不过将“/”分隔换为了“%>%”,同时个别写法有些许调整。
node<-getNodeSet(pagetree, "//p[@class='pl']/text()")
最终如果我们打印出这个变量的内容,就会发现和上篇文章中的爬取内容是一致的:
> position
[1] "[美] 卡勒德·胡赛尼 / 李继宏 / 上海人民出版社 / 2006-5 / 29.00元"
[2] "[法] 圣埃克苏佩里 / 马振聘 / 人民文学出版社 / 2003-8 / 22.00元"
[3] "钱锺书 / 人民文学出版社 / 1991-2 / 19.00"
[4] "余华 / 南海出版公司 / 1998-5 / 12.00元"
[5] "[日] 东野圭吾 / 刘姿君 / 南海出版公司 / 2008-9 / 29.80元"
[6] "[日] 村上春树 / 林少华 / 上海译文出版社 / 2001-2 / 18.80元"
[7] "(日)东野圭吾 / 李盈春 / 南海出版公司 / 2014-5 / 39.50元"
[8] "[捷克] 米兰·昆德拉 / 许钧 / 上海译文出版社 / 2003-7 / 23.00元"
[9] "[清] 曹雪芹 著 / 人民文学出版社 / 1996-12 / 59.70元"
[10] "刘慈欣 / 重庆出版社 / 2008-1 / 23.00"
[11] "郭敬明 / 春风文艺出版社 / 2003-11 / 20.00元"
[12] "[美] 丹·布朗 / 朱振武 / 上海人民出版社 / 2004-2 / 28.00元"
[13] "[日] 东野圭吾 / 刘子倩 / 南海出版公司 / 2008-9 / 28.00"
[14] "韩寒 / 国际文化出版公司 / 2010-9 / 25.00元"
[15] "柴静 / 广西师范大学出版社 / 2013-1-1 / 39.80元"
[16] "顾漫 / 朝华出版社 / 2007-4 / 15.00元"
[17] "[英] 夏洛蒂·勃朗特 / 世界图书出版公司 / 2003-11 / 18.00元"
[18] "路遥 / 人民文学出版社 / 2005-1 / 64.00元"
[19] "[英] J. K. 罗琳 / 苏农 / 人民文学出版社 / 2000-9 / 19.50元"
[20] "[哥伦比亚] 加西亚·马尔克斯 / 范晔 / 南海出版公司 / 2011-6 / 39.50元"
[21] "[美国] 玛格丽特·米切尔 / 李美华 / 译林出版社 / 2000-9 / 40.00元"
[22] "李可 / 陕西师范大学出版社 / 2007-9 / 26.00元"
[23] "韩寒 / 作家出版社 / 2000-5 / 16.00"
[24] "刘瑜 / 上海三联书店 / 2010-1 / 25.00元"
[25] "张爱玲 / 花城出版社 / 1997-3-1 / 11.00"
想要学习更多,我们可以在Rstudio里的命令行输入如下代码查询html_nodes()函数的相关用法:
?html_nodes
Rvest这个包的说明文档里给出了一些其他例子:
ateam <- read_html("http://www.boxofficemojo.com/movies/?id=ateam.htm")
ateam %>% html_nodes("center") %>% html_nodes("td")
ateam %>% html_nodes("center") %>% html_nodes("font")
library(magrittr)
ateam %>% html_nodes("table") %>% extract2(1) %>% html_nodes("img")
ateam %>% html_nodes("table") %>% `[[`(1) %>% html_nodes("img")
ateam %>% html_nodes("table") %>% `[`(1:2) %>% html_nodes("img")
ateam %>% html_nodes("table") %>% extract(1:2) %>% html_nodes("img")
下面也一并讲解一下:
ateam <- read_html("http://www.boxofficemojo.com/movies/?id=ateam.htm")
首先,所有的例子都是基于同一个网站,我们把这个网站存储在ateam变量里。
然后下面两行代码分别获取了ateam这个网页里<center>标签里<td>的全部内容和<center>标签里<font>的全部内容
ateam %>% html_nodes("center") %>% html_nodes("td")
ateam %>% html_nodes("center") %>% html_nodes("font")
运行结果如下,可见<center>标签下有7个<td>标签,一个<font>标签:
{xml_nodeset (7)}
[1] <td align="center" colspan="2">\n <font size="4">Domestic Total Gross: <b>$77,222, ...
[2] <td valign="top">Distributor: <b><a href="/studio/chart/?studio=fox.htm">Fox</a></b ...
[3] <td valign="top">Release Date: <b><nobr><a href="/schedule/?view=bydate&release ...
[4] <td valign="top">Genre: <b>Action</b></td>
[5] <td valign="top">Runtime: <b>1 hrs. 57 min.</b></td>
[6] <td valign="top">MPAA Rating: <b>PG-13</b></td>
[7] <td valign="top">Production Budget: <b>$110 million</b></td>
{xml_nodeset (1)}
[1] <font size="4">Domestic Total Gross: <b>$77,222,099</b></font>
接着官方例子中还给出了获取特定序位的html标签的方法,用到了magrittr包里的extract2函数:
library(magrittr)
ateam %>% html_nodes("table") %>% extract2(1) %>% html_nodes("img")
ateam %>% html_nodes("table") %>% `[[`(1) %>% html_nodes("img")
上面两行代码都可以获得该网页中第一个<table>标签(由extract2(1)或`[[`(1)获取)中的所有<img>标签里的内容,运行结果如下:
{xml_nodeset (6)}
[1] <img src="https://images-na.ssl-images-amazon.com/images/M/MV5BMTc4ODc4NTQ1N15BMl5B ...
[2] <img src="http://www.assoc-amazon.com/e/ir?t=boxofficemojo-20&l=as2&o=1& ...
[3] <img src="http://www.assoc-amazon.com/e/ir?t=boxofficemojo-20&l=as2&o=1& ...
[4] <img src="/img/misc/bom_logo1.png" width="245" height="56" alt="Box Office Mojo"/>
[5] <img src="/img/misc/IMDbSm.png" width="34" height="16" alt="IMDb" valign="middle"/>
[6] <img src="http://b.scorecardresearch.com/p?c1=2&c2=6034961&cv=2.0&cj=1"/>
同理我们也可以获得网页里前两个<table>标签储存的所有<img>标签里的内容:
ateam %>% html_nodes("table") %>% `[`(1:2) %>% html_nodes("img")
ateam %>% html_nodes("table") %>% extract(1:2) %>% html_nodes("img")
本篇文章就到此为止了,之后我将继续讲解关于正则以及R中stringr包的相关内容,对获取的字符串进行进一步的处理操作。
结语
更多内容请关注我的专栏:R语言与数据挖掘 - 知乎专栏
或关注我本人知乎主页:温如
R语言学习:使用rvest包抓取网页数据

rvest是R语言一个用来做网页数据抓取的包,包的介绍就是“更容易地收割(抓取)网页”。其中html_nodes()函数查找标签的功能非常好用。以抓取天猫搜索结果页的宝贝数据为例说明rvest的使用。
分析网页
- 打开天猫,按F12键打开浏览器的开发工具。个人用的火狐,谁让Chrom不支持linux了,唉。不过还是chrome好用啊。其他浏览器都有类似的功能。
- 随便搜索个啥,比如核弹,我草还真出结果了!
- 接下来,在浏览器的开发工具"查看器"中查看网页的源码。或者按一下CTRL+SHIFT+C,选择任意宝贝。可以看到宝贝的图片、月销量等数据都是包含在<div class="product-iWrap">...</div>块中的。
- 打开该div块,哈哈,咱们需要的商品图片、链接、月销量、价格,以及商户名称等,都可以在里面找到了。话说,猫爹其实挺开放的,没有做太多限制,不然想抓这些数据就麻烦了。
接下来启动R,以下是用rvest包抓取宝贝数据的过程
- 安装rvest包
install.packages("rvest") - 加载rvest包
library(rvest) - 保存搜索链接到对象gurl,链接的拼接方式挺有规律的
gurl <- "https://list.tmall.com/search_product.htm?q=%C9%AD%B1%C8%B0%C2&type=p&vmarket=&spm=875.7931836%2FB.a2227oh.d100&from=mallfp..pc_1_searchbutton" - 抓取数据保存到对象md中
- %>%是管道操作符,意思是把左边的操作结果作为参数传递给右边的命令
- div.product-iWrap 是CSS选择器的语法,即是 div class="div.product-iWarp"
md <- gurl %>% read_html(encoding="GBK") %>% # 读取gurl的链接,指定编码为gbk html_nodes("div.product-iWrap") # 筛选出所有包含在<div class="product-iWrap">...</div>块的内容 - 从对象md继续筛选,获卖家名称等数据。
- html_attr("data-nick") 是从html_nodes()筛选出的标签中,查找data-nick属性的值。
- gsub()是字符串查找替换的函数,pattern是指定用来查找的正则表达式。
- html_nodes("p.productTitle>a[title]"),”>"指定的筛选条件的父级标签。
- html_text() 只抓取<标签>内容</标签>中的内容部分。
# 抓取卖家昵称和ID
sellerNick <- md %>% html_nodes("p.productStatus>span[class]") %>%
html_attr("data-nick")
sellerId <- md %>% html_nodes("p.productStatus>span[data-atp]") %>%
html_attr("data-atp") %>%
gsub(pattern="^.*,",replacement="")
# 抓取宝贝名称等数据
itemTitle <- md %>% html_nodes("p.productTitle>a[title]") %>%
html_attr("title")
itemId <- md %>% html_nodes("p.productStatus>span[class]") %>%
html_attr("data-item")
price <- md %>% html_nodes("em[title]") %>%
html_attr("title") %>%
as.numeric
volume <- md %>% html_nodes("span>em") %>%
html_text
# 最后保存成数据框对象并存盘备用,以及写入csv文件
options(stringsAsFactors = FALSE) # 设置字符串不自动识别为因子
itemData <- data.frame(sellerNick=sellerNick,
sellerId=sellerId,itemTitle=itemTitle,
itemId=itemId,
price=price,
volume=volume)
save(itemData,file="F:/mydata/itemData.rData")
write.csv(itemData,file="F:/mydata/itemData.csv")补充一个用rvest从赶集网抓取二手房单页面数据的代码
getData <- function(gurl){
# 抓取赶集网二手房源单页的数据
library(rvest)
# 赶集网首页筛选长沙-雨花区-砂子塘的二手房源,获得链接,o1为页数
# gurl <- "http://cs.ganji.com/fang5/yuhuashazitang/o1/"
tmp <- gurl %>% html_session %>%
read_html(encoding="utf-8") %>%
html_nodes("div.f-main-list>div>div")
# 单个房源的puid
puid <- tmp %>% html_attr("id")
# 单个房源的链接
itemURL <-tmp %>% html_attr("href") %>%
gsub(pattern="/fang5",replacement="http://cs.ganji.com/fang5")
# 缩略图链接
smallImg <- tmp %>% html_nodes("dl>dt>div>a>img") %>% html_attr("src")
# 标题
iTitle <- tmp %>% html_nodes("dl>dd>a") %>% html_attr("title")
# 户型
iLayout <- tmp %>% html_nodes("dl>dd[data-huxing]") %>% html_attr("data-huxing")
# 面积
iArea <- tmp %>% html_nodes("dl>dd[data-huxing]") %>%
html_attr("data-area") %>%
gsub(pattern="[^0-9]",replacement="")
# 筛选朝向等数据
iTmp <- tmp %>% html_nodes("dl>dd[data-huxing]>span") %>% html_text
iOrientation <- iTmp[seq(from=5,to=length(iTmp),by=9)] # 提取朝向
iFloor <- iTmp[seq(from=7,to=length(iTmp),by=9)] %>% # 提取楼层
gsub(pattern="\n",replacement="")
iDecoration <- iTmp[seq(from=9,to=length(iTmp),by=9)] # 提取装修
# 提取地址
iAddr <- tmp %>% html_nodes("dl>dd>span.area") %>% html_text %>%
gsub(pattern="\n",replacement=" ") %>%
gsub(pattern=" ",replacement="")
# 提取价格
iPrice <- tmp %>% html_nodes("dl>dd>div.price>span:first-child") %>% html_text
# 提取单价
iTime <- tmp %>% html_nodes("dl>dd>div.time") %>% html_text %>%
gsub(pattern="[^0-9]",replacement="") %>% as.numeric
# 合并数据框
iData <- data.frame(puid=puid,
iLayout=iLayout,
iArea=iArea,
iPrice=iPrice,
iTime=iTime,
iDecoration=iDecoration,
iFloor=iFloor,
iOrientation=iOrientation,
itemURL=itemURL,
smallImg=smallImg,
iTitle=iTitle,
iAddr=iAddr,
stringsAsFactors=FALSE)
# 返回数据框
return(iData)
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号