
Langchain4j-6-RAG
基本概念
RAG(检索增强生成,Retrieval-Augmented Generation)是通过外挂知识库,让大模型具备垂类知识的一种技术,扩展知识边界,并避免“幻觉”问题。
主要步骤有:
- 预处理(蓝线部分):将数据通过分词器切分为片段,然后通过嵌入模型转换为向量,存储到向量数据库中
- 检索(红线部分):通过外部文档库搜索相关文本片段,或通过向量数据库进行相似度查询,先检索出与用户问题相关的内容。
- 生成(红线部分):将检索到的相关内容与用户原始问题一同输入到大语言模型中,由模型进行理解和综合,生成更准确、包含事实依据的回答。
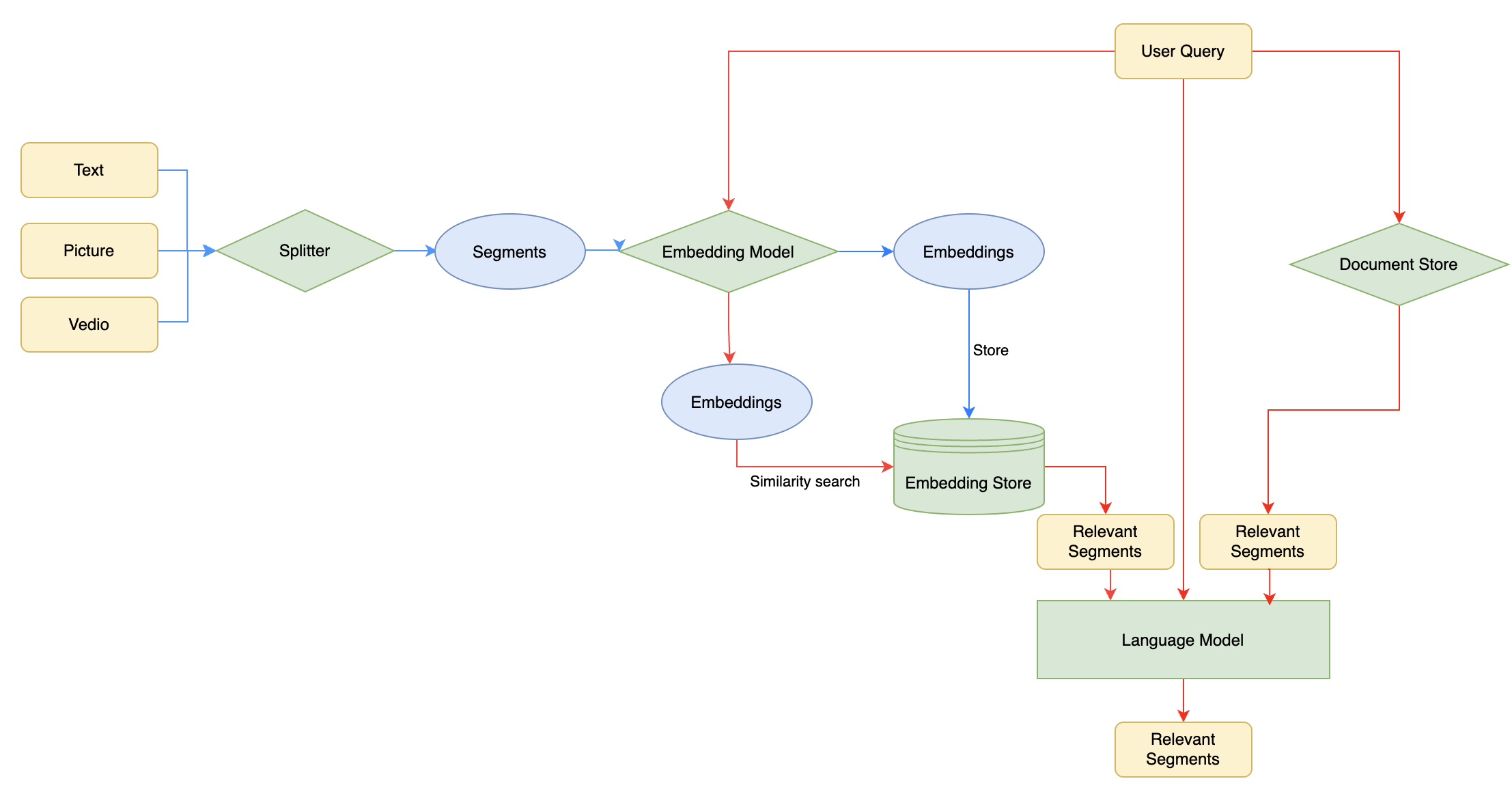
简单示例
添加依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>
添加向量数据库(这里方便起见使用内存向量数据库)
// LLMConfig.java
@Bean
public InMemoryEmbeddingStore<TextSegment> embeddingStore() {
return new InMemoryEmbeddingStore<>();
}
构建 AIService
// ChatAssictant.java
public interface ChatAssistant {
/**
* 聊天
*
* @param message 消息
* @return {@link String }
*/ String chat(String message);
}
// LLMConfig.java
@Bean
public ChatAssistant assistant(ChatModel chatModel, EmbeddingStore<TextSegment> embeddingStore)
{
return AiServices.builder(ChatAssistant.class)
.chatModel(chatModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(50))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号