
注:本人只是吧一些零散帖子的知识点进行整合,方便查看
# Flask
## 环境安装
### 安装Flask
pip install flask
### 安装数据库模块
#### 用于连接数据
pip install flask_sqlalchemy
#### 用于操作数据库
pip install mysqlclient
## 启动
`python run.py`
## 获取传入值方式
### 默认GET传值
#### str默认
`@app.route('/hello/<name>/')`
#### int参数
`@app.route('/hello/<int:id>/')`
#### float参数
`@app.route('/hello/<float:id>/')`
#### string参数
`@app.route('/hello/<string:id>/')`
#### path参数
`@app.route('/hello/<path:id>/')`
#### uuuid参数
`@app.route('/hello/<uuuid:id>/')`
### request 获取传值 比如 id=1
#### GET获取
`request.args.getlist('id')`
#### POST获取
`request.form.getlist('id')`
## 数据库操作
### 基础类型
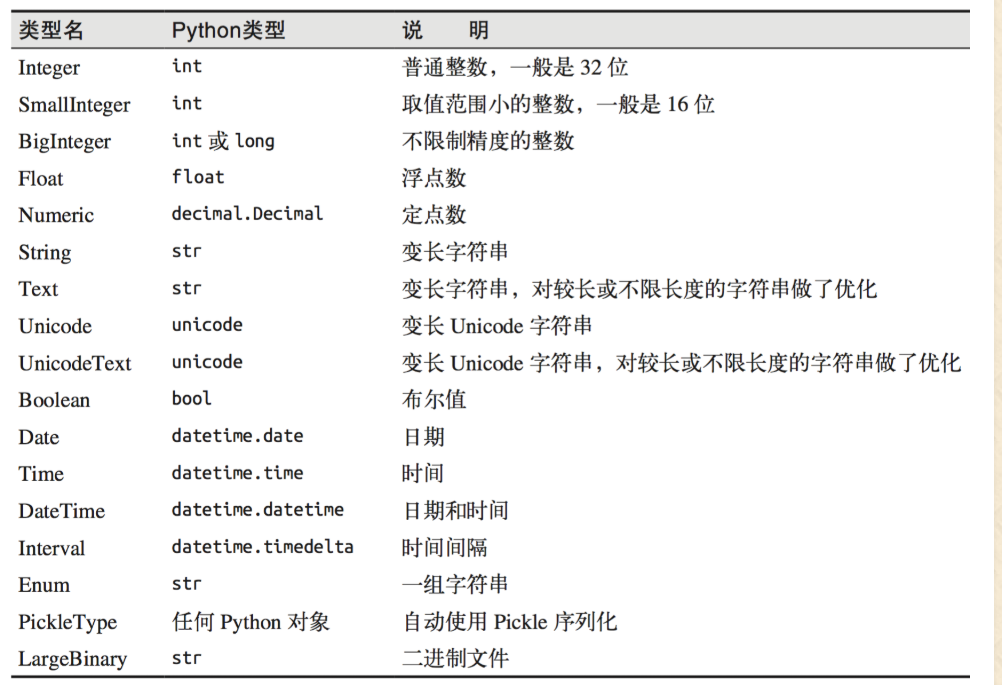
###列设置
![]()

### 关系选项
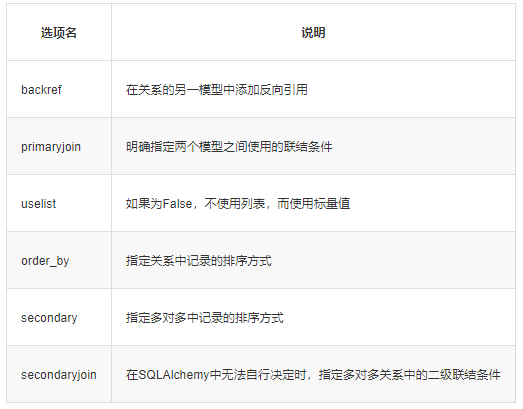
### 数据库过滤器和查询函数

### 数据库操作详细方法
```bash
# 删除全部表
db.drop_all()
# 新建全部表
db.create_all()
# ro1为需要添加的实体类
# 添加单条数据
db.session.add(ro1)
# 添加多条数据
db.session.add_all([ro1,ro2,ro3,ro4,....])
# 数据的查询功能
## 下面方面都是返回新的查询,需要配合执行器使用
filter(): 过滤,功能比较强大。
filter_by():过滤,用在一些比较简单的过滤场景。
order_by():排序。默认是升序,降序需要导包:from sqlalchemy import * 。然后引入desc方法。比如order_by(desc("email")).按照邮箱字母的降序排序。
group_by():分组
## 以下都是一些常用的执行器:配合上面的过滤器使用。
get():获得id等于几的函数。比如:查询id=1的对象。get(1)。切记:括号里没有“id=”,直接传入id的数值就ok。因为该函数的功能就是查询主键等于几的对象。
all():查询所有的数据。
first():查询第一个数据。
count():返回查询结果的数量。
paginate():分页查询,返回一个分页对象。paginate(参数1,参数2,参数3)
参数1:当前是第几页,参数2:每页显示几条记录,参数3:是否要返回错误。
返回的分页对象有三个属性:items:获得查询的结果,pages:获得一共有多少页,page:获得当前页。
## 常用的逻辑符:
需要倒入包才能用的有:from sqlalchemy import *
not_ and_ or_ 还有上面说的排序desc。
常用的内置的有:in_ 表示某个字段在什么范围之中。
## 其他关系的一些数据库查询
endswith():以什么结尾。
startswith():以什么开头。
contains():包含
# 数据查询具体实例
## 查询全部用户
User.query.all()
## 查询有多少用户
User.query.count()
## 查询第一个用户
User.query.first()
## 查询id为4的用户[3种方式]
User.query.get(4)
User.query.filter_by(id=4).first()
User.query.filter(User.id==4).first()
(注:filter:(类名.属性名==) filter_by:(属性名=) filter_by: 用于查询简单的列名,不支持比较运算符 filter比filter_by的功能更强大,支持比较运算符,支持or_、in_等语法。)
## 查询名字结尾字符为g的所有数据[开始/包含]
User.query.filter(User.name.endswith('g')).all()
User.query.filter(User.name.contains('g')).all()
## 查询名字不等于wang的所有数据[2种方式]
from sqlalchemy import not_
注意了啊:逻辑查询的格式:逻辑符_(类属性其他的一些判断)
User.query.filter(not_(User.name=='wang')).all()
User.query.filter(User.name!='wang').all()
## 查询名字和邮箱都以 li 开头的所有数据[2种方式]
from sqlalchemy import and_
User.query.filter(and_(User.name.startswith('li'), User.email.startswith('li'))).all()
User.query.filter(User.name.startswith('li'), User.email.startswith('li')).all()
## 查询password是 `123456` 或者 `email` 以 `itheima.com` 结尾的所有数据
from sqlalchemy import or_
User.query.filter(or_(User.password=='123456', User.email.endswith('itheima.com'))).all()
## 查询id为 [1, 3, 5, 7, 9] 的用户列表
User.query.filter(User.id.in_([1, 3, 5, 7, 9])).all()
## 查询name为liu的角色数据
关系引用
User.query.filter_by(name='liu').first().role.name
## 查询所有用户数据,并以邮箱排序
排序
User.query.order_by('email').all() 默认升序
User.query.order_by(desc('email')).all() 降序
## 查询第2页的数据, 每页只显示3条数据
help(User.query.paginate)
三个参数: 1. 当前要查询的页数 2. 每页的数量 3. 是否要返回错误
pages = User.query.paginate(2, 3, False)
pages.items # 获取查询的结果
pages.pages # 总页数
pages.page # 当前页数
# 数据提交或者数据更新
db.session.commit()
```


 浙公网安备 33010602011771号
浙公网安备 33010602011771号