语法分析
语法分析
Grammar Analysis
语法分析
说实话,上课我能听懂,但是,看到作业题目的我是懵逼的,到底想让我们干什么?
在阅读学长代码的时候,我仿佛又明白了想让我们干什么,就是输出而已,可是这和上课讲的符号表、语法树有什么关系呢,为啥学长代码里有符号表和语法树的部分?
后来我才知道,因为是“增量开发”,我们要先写一个大型的字符串处理器来做语法分析,然后再慢慢加上符号表等。
如何入手
先看一段代码:
// <Decl>::= <ConstDecl> | <VarDecl>
// <ConstDecl>::= 'const' 'int' <ConstDef> {, <ConstDef>}
// <VarDecl>::= 'int' <VarDef> { ',' <VarDef> } ';'
// promise: already read a token
void Parser::Decl() {
if (type_code_ == TypeCode::CONSTTK) {
ConstDecl();
} else if (type_code_ == TypeCode::INTTK) {
VarDecl();
} else {
handle_error("expect a const or int head of <Decl>");
}
output("<Decl>");
}
首先保证,当进入 Decl 分析时,已经读取了一个 token,接下来,若这个 token 的类别码为 const 时,就进入 ConstDecl 分析,
若为 int,就进入 VarDecl 分析。
分析完之后,再输出<Decl>。这就是为什么样例的最后会输出非终结符。
那么我们要做的事就明确了——为每一个非终结符写一个分析函数,在函数的结尾输出这个非终结符。
根据文法,粗粗一算,大概要写 20~30 个函数。
接下来,我们具体讲一讲怎么写这个递归下降的字符串处理器。
明确非终结符
为了写函数,我们得明确文法中有哪些非终结符。
我的方法是,画一棵树,这棵树表明了非终结符之间的依赖关系,而树上有所有要输出的非终结符号。
为了不遗漏地将非终结符的分析函数写出来,我们要遍历自己画的这棵树。
我画的树如下:
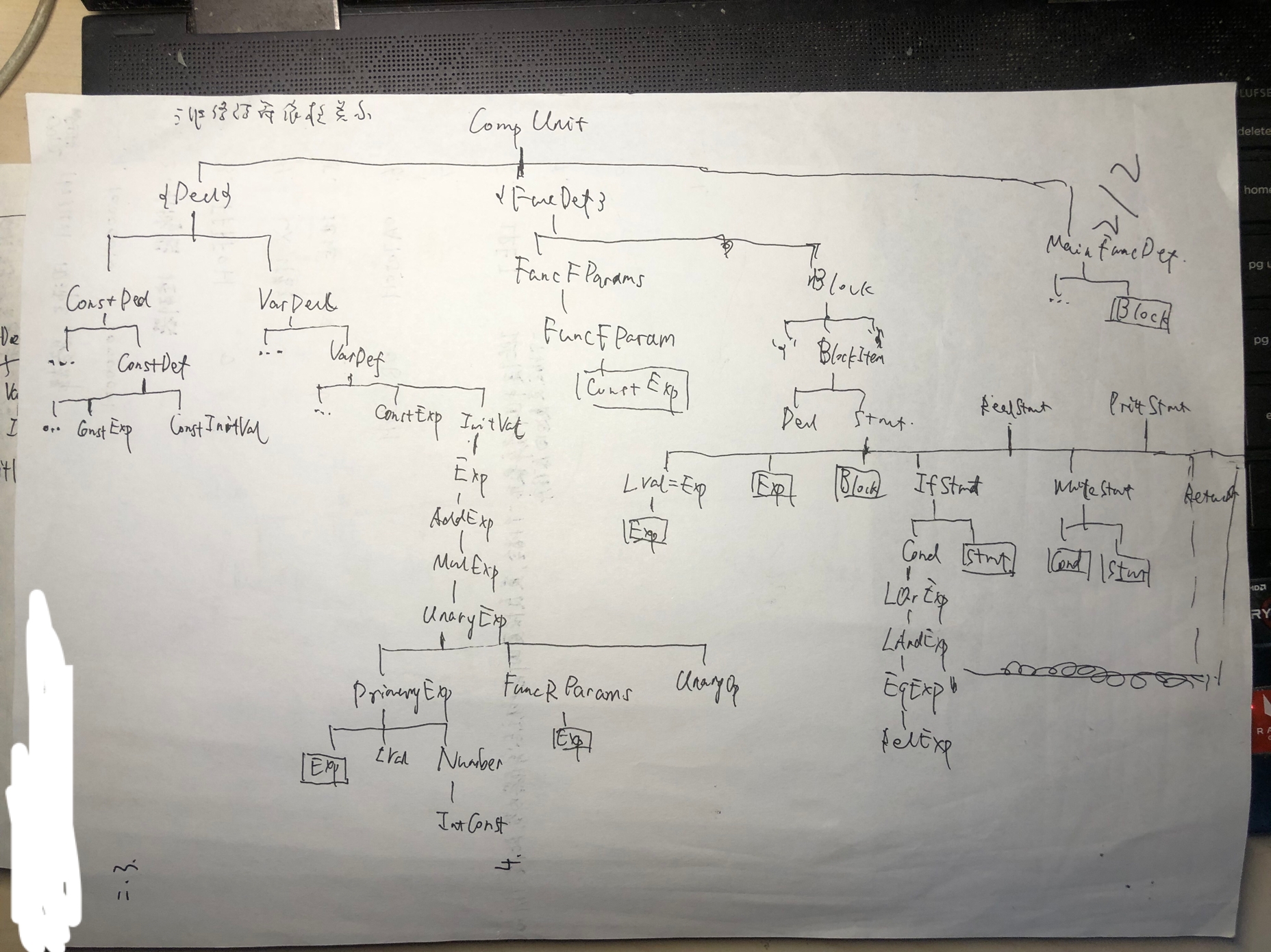
各种文法情况
首先,我们约定,进入一个非终结符函数时,已经帮这个非终结符读取了一个 token;
而从非终结符出来时,没有再预读。
分支处理
下面是一个典型的分支处理的例子,面对如此多的分支,进行判断,然后进入相应的非终结符处理函数。
// Stmt-> 'if' '(' Cond ')' Stmt [ 'else' Stmt ] |
// 'while' '(' Cond ')' Stmt |
// 'return' [Exp] ';' |
// 'printf''('FormatString{,Exp}')'';'
void Parser::Stmt() {
if (type_code_ == TypeCode::IFTK) {
IfStmt();
} else if (type_code_ == TypeCode::WHILETK) {
WhileStmt();
} else if (type_code_ == TypeCode::RETURNTK) {
ReturnStmt();
} else if (type_code_ == TypeCode::PRINTFTK) {
WriteStmt();
} else {
handle_error("expect ';' end of <Stmt>");
}
output("<Stmt>");
}
当然,进入分支可能需要更多的预读。比如变量定义、函数定义和主函数定义,在读取到 int 时,还不能判断该进入哪个分支,
这时就需要再读取。
// 一个需要更多预读的文法例子:
int a ( ) // 函数定义
int a, b; // 变量定义
int main ( ) // main 定义
多次预读取可以帮助我们确定要进入哪个分支,但是会带来一个问题,就是进入前,读了不只一个 token。
这时,可以引入retract()函数,将读取到的 token 放回去。
这个操作可以通过建立 token 读取列表实现:retract()时,读取序列的 index 回退,next_sym()时,index 前进。
对于 {} 的处理
{V}表示出现零个或多个 V,在此给出一些例子:
- Vn'::= { sth } xxx
- Vn'::= { Vn } xxx
- Vn'::= { Vt Vn } xxx
- Vn'::= { sth } xxx
我们要将大括号内部的句型的 first 集合分析出来,然后写入 while。
while (token == first_of(sth)) ) {
Vn(); // analyze Vn
next_sym(); // read a token
}
这样我们就能保证不断地读取。
还有一些特殊的情况,比如 xxx 的 first 集合和 Vn 的 first 集合有交集,那么我们在 while 的内部就要再预读,不满足条件时break。
形如:Vt {Vn} Vt' 的文法还有一种处理方法——自后向前处理。用在 Vn 的 first 集合难以分析的时候。
当读取到 Vt 时,再读取一个 token,若读到 Vt',说明 Vn 没有,直接跳过,否则,进入 while。
// already read Vt
next_sym();
while (token != Vt') {
Vn();
next_sym();
}
// now token is Vt'
左递归文法改写
改写文法简单,但是会引起一个 bug,即改写后的文法和原来的文法,
在处理相同的句子时,会造成语法树长得不一样,造成输出少了一个非终结符。
比如下面的例子,两种文法,a && b的语法树是不一样的,改写后的文法少了一个非终结符。
所以,要先擦去之前输出的终结符,再输出非终结符,最后补上终结符。
// <LAndExp>::= <EqExp> | <LAndExp> '&&' <EqExp>
// <LAndExp>::= <EqExp> { '&&' <EqExp> }
// note: left recurrence
// promise: already read a token
void Parser::LAndExp() {
EqExp();
next_sym();
while (type_code_ == TypeCode::AND) {
// ----------------------
retract(); // erase the token before
output("<LAndExp>"); // output the Vn
next_sym(); // output the token
// -----------------------
next_sym();
EqExp();
next_sym();
}
retract();
output("<LAndExp>");
}
检查
- 分号的处理是否正确
- 面对{}的文法,在 while 出来后,是否需要回退
- 每个非终结符定义前,进入前是否预读
bug
- 非终结符少输出
;没有正确处理- 左递归文法改写
