


一、时序数据库是什么?
时间序列数据库 Time Series Database (TSDB)
时序数据是随时间不断产生的一系列数据,简单来说,就是带时间戳的数据。
1.时序数据库相关概念
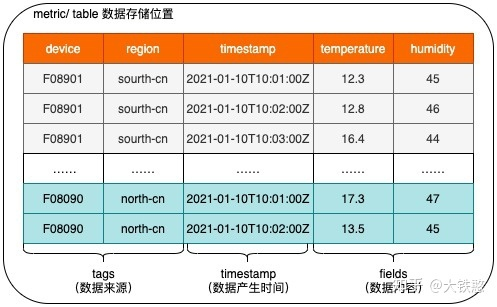
- 度量 Metric:Metric 类似关系型数据库里的表(Table),代表一系列同类时序数据的集合,例如为空气质量传感器建立一个 Table,存储所有传感器的监测数据。
- 标签 Tag:Tag 描述数据源的特征,通常不随时间变化,例如传感器设备,包含设备 DeviceId、设备所在的 Region 等 Tag 信息,数据库内部会自动为 Tag 建立索引,支持根据 Tag 来进行多维检索查询;Tag 由 Tag Key、Tag Value 组成,两者均为 String 类型。
- 时间戳 Timestamp:Timestamp代表数据产生的时间点,可以写入时指定,也可由系统自动生成;
- 量测值 Field:Field描述数据源的量测指标,通常随着时间不断变化,例如传感器设备包含温度、湿度等Field;
- 数据点Data Point:数据源在某个时间产生的某个量测指标值(Field Value)称为一个数据点,数据库查询、写入时按数据点数来作为统计指标;
- 时间线 Time Series:数据源的某一个指标随时间变化,形成时间线,Metric + Tags + Field 组合确定一条时间线;针对时序数据的计算包括降采样、聚合(sum、count、max、min等)、插值等都基于时间线维度进行;
2.时序数据库特点
时序数据库具有不变性、唯一性、时间排序性
- 时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
- 时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能
数据写入特点
- 写入平稳、持续、高并发高吞吐:时序数据的写入是比较平稳的,这点与应用数据不同,应用数据通常与应用的访问量成正比,而应用的访问量通常存在波峰波谷。时序数据的产生通常是以一个固定的时间频率产生,不会受其他因素的制约,其数据生成的速度是相对比较平稳的。
- 写多读少:时序数据上95%-99%的操作都是写操作,是典型的写多读少的数据。这与其数据特性相关,例如监控数据,你的监控项可能很多,但是你真正去读的可能比较少,通常只会关心几个特定的关键指标或者在特定的场景下才会去读数据。
- 实时写入最近生成的数据,无更新:时序数据的写入是实时的,且每次写入都是最近生成的数据,这与其数据生成的特点相关,因为其数据生成是随着时间推进的,而新生成的数据会实时的进行写入。数据写入无更新,在时间这个维度上,随着时间的推进,每次数据都是新数据,不会存在旧数据的更新,不过不排除人为的对数据做订正。
数据存储特点
- 数据量大:拿监控数据来举例,如果我们采集的监控数据的时间间隔是1s,那一个监控项每天会产生86400个数据点,若有10000个监控项,则一天就会产生864000000个数据点。在物联网场景下,这个数字会更大。整个数据的规模,是TB甚至是PB级的。
- 冷热分明:时序数据有非常典型的冷热特征,越是历史的数据,被查询和分析的概率越低。
- 具有时效性:时序数据具有时效性,数据通常会有一个保存周期,超过这个保存周期的数据可以认为是失效的,可以被回收。一方面是因为越是历史的数据,可利用的价值越低;另一方面是为了节省存储成本,低价值的数据可以被清理。
数据模型
时间序列数据可以分成两部分
- 序列 :就是标识符(维度),主要的目的是方便进行搜索和筛选
-
数据点:时间戳和数值构成的数组列存:两个数组,一个存时间戳,一个存数值,如[ 2017-09-03-21:24:44, 2017-09-03-21:24:45], [0.1002, 0.1012]一般情况下:列存能有更好的压缩率和查询性能
二、常用时序数据库
可以按照以下需求自行选择合适的存储:
- 小而精,性能高,数据量较小(亿级): InfluxDB
- 简单,数据量不大(千万级),有联合查询、关系型数据库基础:timescales
- 数据量较大,大数据服务基础,分布式集群需求: opentsdb、KairosDB
- 分布式集群需求,olap实时在线分析,资源较充足:druid
- 性能极致追求,数据冷热差异大:Beringei
- 兼顾检索加载,分布式聚合计算: elsaticsearch
- 如果你兼具索引和时间序列的需求。那么Druid和Elasticsearch是最好的选择。其性能都不差,同时满足检索和时间序列的特性,并且都是高可用容错架构。
三、RedisTimeSeries
RedisTimeSeries 是 Redis 的一个扩展模块。它专门面向时间序列数据提供了数据类型和访问接口,并且支持在 Redis 实例上直接对数据进行按时间范围的聚合计算。
当用于时间序列数据存取时,RedisTimeSeries 的操作主要有 5 个:
-
用 TS.CREATE 命令创建时间序列数据集合在 TS.CREATE 命令中,我们需要设置时间序列数据集合的 key 和数据的过期时间(以毫秒为单位)。此外,我们还可以为数据集合设置标签,来表示数据集合的属性。例如,我们执行下面的命令,创建一个 key 为 device:temperature、数据有效期为 600s 的时间序列数据集合。也就是说,这个集合中的数据创建了 600s 后,就会被自动删除。最后,我们给这个集合设置了一个标签属性{device_id:1},表明这个数据集合中记录的是属于设备 ID 号为 1 的数据。
TS.CREATE device:temperature RETENTION 600000 LABELS device_id 1 OK
-
用 TS.ADD 命令插入数据我们可以用 TS.ADD 命令往时间序列集合中插入数据,包括时间戳和具体的数值,并使用 TS.GET 命令读取数据集合中的最新一条数据。例如,我们执行下列 TS.ADD 命令时,就往 device:temperature 集合中插入了一条数据,记录的是设备在 2020 年 8 月 3 日 9 时 5 分的设备温度;
TS.ADD device:temperature 1596416700 25.1 1596416700
- 用 TS.GET 命令读取最新数据
再执行 TS.GET 命令时,就会把刚刚插入的最新数据读取出来。
TS.GET device:temperature 25.1
-
用 TS.MGET 命令按标签过滤查询数据集合在保存多个设备的时间序列数据时,我们通常会把不同设备的数据保存到不同集合中。此时,我们就可以使用 TS.MGET 命令,按照标签查询部分集合中的最新数据。在使用 TS.CREATE 创建数据集合时,我们可以给集合设置标签属性。当我们进行查询时,就可以在查询条件中对集合标签属性进行匹配,最后的查询结果里只返回匹配上的集合中的最新数据。举个例子。假设我们一共用 4 个集合为 4 个设备保存时间序列数据,设备的 ID 号是 1、2、3、4,我们在创建数据集合时,把 device_id 设置为每个集合的标签。此时,我们就可以使用下列 TS.MGET 命令,以及 FILTER 设置(这个配置项用来设置集合标签的过滤条件),查询 device_id 不等于 2 的所有其他设备的数据集合,并返回各自集合中的最新的一条数据。
TS.MGET FILTER device_id!=2 1) 1) "device:temperature:1" 2) (empty list or set) 3) 1) (integer) 1596417000 2) "25.3" 2) 1) "device:temperature:3" 2) (empty list or set) 3) 1) (integer) 1596417000 2) "29.5" 3) 1) "device:temperature:4" 2) (empty list or set) 3) 1) (integer) 1596417000 2) "30.1"
-
用 TS.RANGE 支持聚合计算的范围查询最后,在对时间序列数据进行聚合计算时,我们可以使用 TS.RANGE 命令指定要查询的数据的时间范围,同时用 AGGREGATION 参数指定要执行的聚合计算类型。RedisTimeSeries 支持的聚合计算类型很丰富,包括求均值(avg)、求最大 / 最小值(max/min),求和(sum)等。例如,在执行下列命令时,我们就可以按照每 180s 的时间窗口,对 2020 年 8 月 3 日 9 时 5 分和 2020 年 8 月 3 日 9 时 12 分这段时间内的数据进行均值计算了。
TS.RANGE device:temperature 1596416700 1596417120 AGGREGATION avg 180000 1) 1) (integer) 1596416700 2) "25.6" 2) 1) (integer) 1596416880 2) "25.8" 3) 1) (integer) 1596417060 2) "26.1"
四、Java SDK
<dependencies>
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jredistimeseries</artifactId>
<version>1.4.0</version>
</dependency>
</dependencies>
RedisTimeSeries rts = new RedisTimeSeries("localhost", 6379); Map<String, String> labels = new HashMap<>(); labels.put("country", "US"); labels.put("cores", "8"); rts.create("cpu1", 60*10 /*10min*/, labels); rts.create("cpu1-avg", 60*10 /*10min*/, null); rts.createRule("cpu1", Aggregation.AVG, 60 /*1min*/, "cpu1-avg"); rts.add("cpu1", System.currentTimeMillis()/1000 /* time sec */, 80.0); rts.get("cpu1"); rts.range(System.currentTimeMillis()/1000 - 10*60, System.currentTimeMillis()/1000, Aggregation.AVG, 60, "country=US")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号