
Alchemy: A structured task distribution for meta-reinforcement learning
 把元学习当作一种提升强化学习的灵活性和样本利用率已经逐渐得到越来越多的关注。然而,这个领域研究的一个问题是缺乏一个足够好的benchmark任务。总体来说,之前的benchmark的结构要么太简单,不具有内在的趣味性,要么定义不当,不支持原则性分析。在这个工作中,我们介绍了元强化学习的一个新的benchmark,它结合了结构丰富度和结构透明度。Alchemy是一款3D视频游戏,在Unity中实现,涉及到一个潜在的因果结构,该结构在一个episode到另一个episode的过程中重新取样,提供结构学习、在线推理、假设检验和基于抽象领域知识的动作排序。我们在Alchemy上评估了一堆强大的智能体,并对其中一个做了深度分析。结果清楚地表明了元学习的失败,为Alchemy作为一个元强化学习的有挑战性的benchmark提供了验证。和这份报告一起,我们开源了Alchemy,以及一套分析工具和示例智能体轨迹。
把元学习当作一种提升强化学习的灵活性和样本利用率已经逐渐得到越来越多的关注。然而,这个领域研究的一个问题是缺乏一个足够好的benchmark任务。总体来说,之前的benchmark的结构要么太简单,不具有内在的趣味性,要么定义不当,不支持原则性分析。在这个工作中,我们介绍了元强化学习的一个新的benchmark,它结合了结构丰富度和结构透明度。Alchemy是一款3D视频游戏,在Unity中实现,涉及到一个潜在的因果结构,该结构在一个episode到另一个episode的过程中重新取样,提供结构学习、在线推理、假设检验和基于抽象领域知识的动作排序。我们在Alchemy上评估了一堆强大的智能体,并对其中一个做了深度分析。结果清楚地表明了元学习的失败,为Alchemy作为一个元强化学习的有挑战性的benchmark提供了验证。和这份报告一起,我们开源了Alchemy,以及一套分析工具和示例智能体轨迹。
Introduction
虽然现在有一些有趣且有创新性的元强化学习技术,但该领域缺乏理想的benchmark。深度强化学习需要一个任务,但元深度强化学习需要一个任务分布,在分布中任务要有一些相似的结构。元强化学习的定义是通过从任务分布中每一次新的抽样,会产生更快的学习过程。一个经典例子是bandit问题分布,每个都有自己的行动或有奖励概率抽样集。
元强化学习可以看作是分层贝叶斯推断,具有相对缓慢的过程,跨越样本,逐渐推断参数化的结构。任何元强化学习benchmark都需要两个特点,首先是分布的ground-truth的参数化应该是可访问的,使得智能体的表现可以和一个最优的baseline进行比较,这正是一个贝叶斯学习者,有时被称为“理想观察者”。其次,任务分布的结构应该是有趣的,保证它可以对标真实环境任务中的挑战,这种有趣性包括组成性,因果关系和概念抽象,产生的任务需要有策略性顺序特点。
本文提出的Alchemy是一个3D,第一视角的游戏,具有高度结构化和非平凡的潜在因果结构,每次玩游戏都会重新取样,需要玩家拥有基于知识的实验和策略行动序列。Alchemy的级别是基于完全可访问的生成过程和定义良好的参数化程序创建的,因此可以实现一个贝叶斯理想观测者作为性能的黄金标准。
The Alchemy environment
游戏玩一系列trails,组合成一个episode,每一个trail中,智能体的目标是用一些药水将石头转化成更有价值的,在将石头丢到坩埚的时候获得reward。石头的价值和它的外形及颜色有一定的关系,但是在不同episode这个关系会不断变化,而且药水的作用也在不同episode之间会发生变化,每个episode潜在的这种石头属性和药水关系是一个chemistry。每一个episode的隐藏挑战是找到最佳的药水配置,制造最有价值的石头。这个转换关系可以用一个图表示,如下面所示。
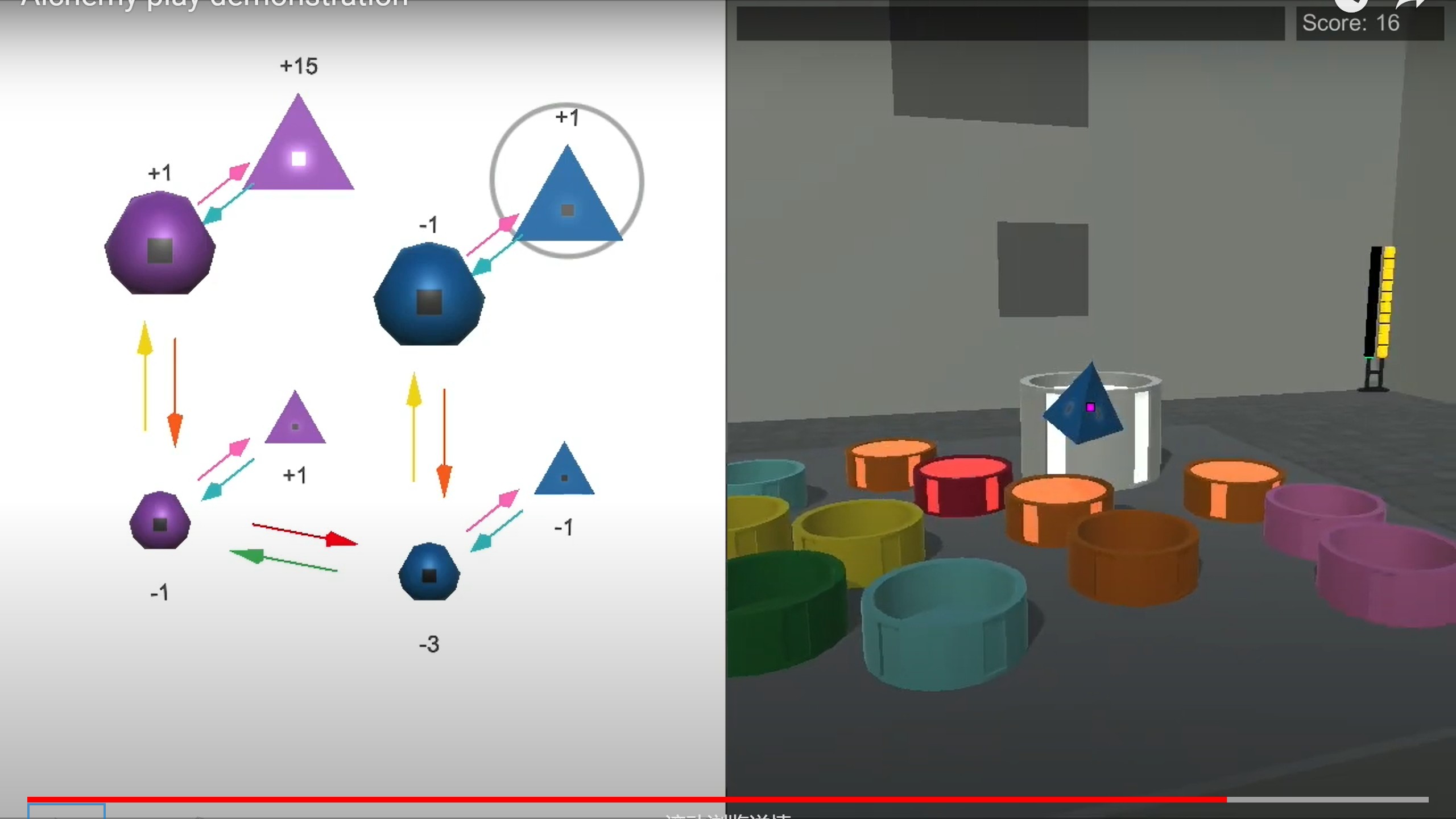
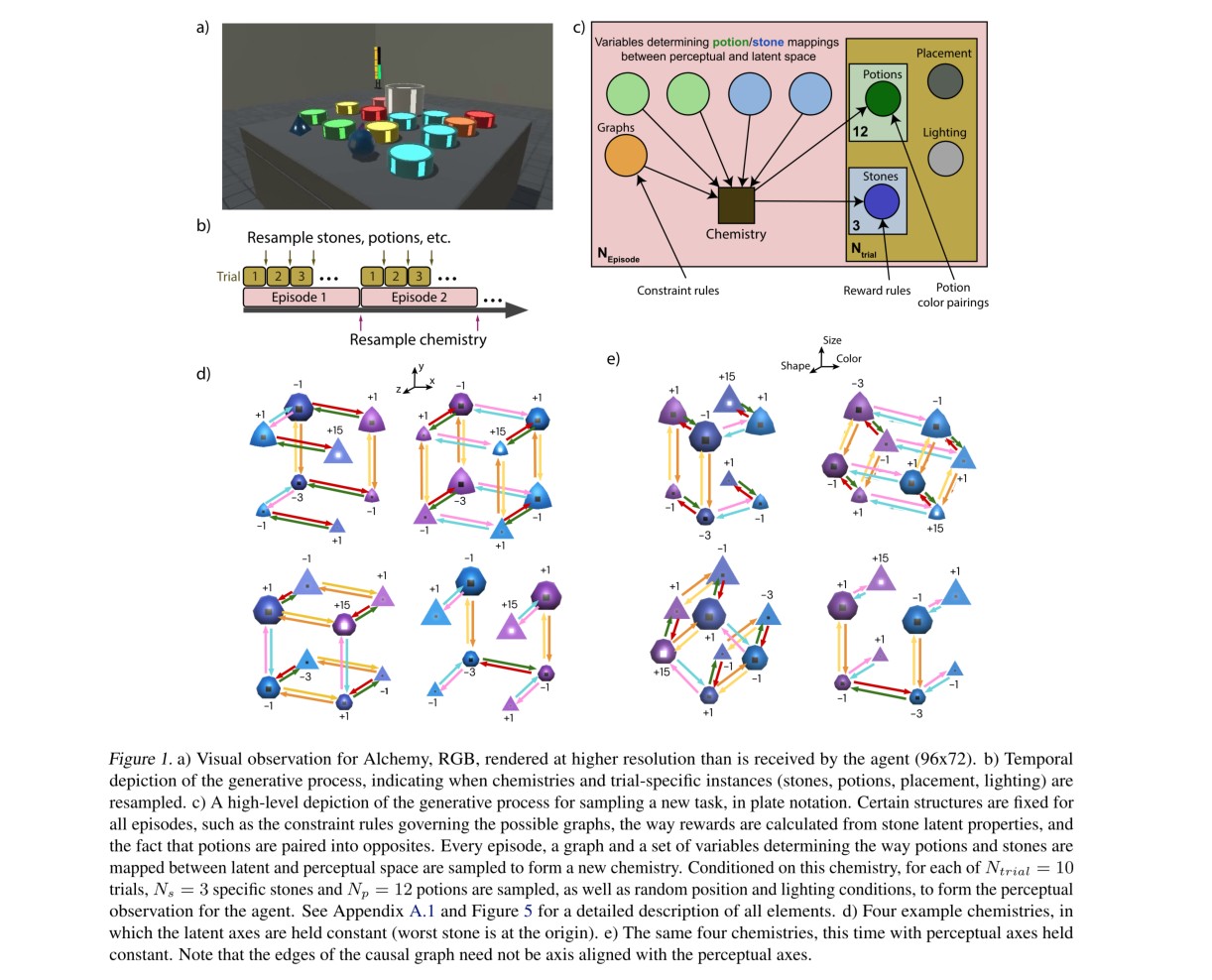
整个环境如图1所示。
Observations, actions, and task logic
每个trail开始,agent可以看到一个桌子,放着坩埚,三个石头,12瓶药剂,这个是从Alchemy生成过程采样出来的。石头有三个属性:尺寸、颜色、形状。石头上有个标记点的亮度表示其value(-3,-1,+1,+15)。每瓶药剂从6种颜色中采样,agent输入\(96\times72\)RGB像素第一人称视角图像,以及其他定义的变量(加速度、距离、机械手的力,及机械手是否抓住物体)。动作空间有9维,由导航、对象操纵执行器和离散抓取动作组成。当石头与药剂接触时,药剂会被完全消耗,并且根据当前的化学反应,石头的外观和价值可能会发生变化。每个trail持续60s,每秒30帧。工作区的每个角落都有一个可视指示器,指示剩余时间。每一集包括十个试验,chemistry在交叉试验中,但在每个trail开始时对石头和药水的位置、空间位置和照明重新取样。https://youtu.be/k2ziWeyMxAk是一个视频示例。
The chemistry
每个episode的chemistry都会改变,当前的chemistry决定了可能出现的特定石头外观、每种外观的附加值,以及至关重要的是,药剂对石头的转化效果。每一episode的具体化学成分从结构化生成过程中取样,如图1-c所示。
这个配置的要点是1)每个episode的chemistry都会重新设置,2)每个chemistry都抽象了原理或规律。正如我们所注意到的,前者的变化方面包括石头外观、石头价值和药剂效果。考虑到这些因素的所有可能组合,总共存在167424种可能的化学成分(考虑到每次试验中也对石头和药水样本进行取样,得出了1240亿左右的一组可能的试验初始值,但仍然忽略了物体空间位置、照明、,等等)。1从某种意义上说,跨越情节的原则更为重要,因为识别和利用这些规律是元学习问题的本质。Alchemy的不变性可以总结为:
1.在每一episode中,具有相同视觉特征的石头具有相同的价值,并且对药剂的反应相同。类似地,同样颜色的药剂也有同样的效果。
2.在每集中,只能出现八个石头外观,这些外观对应于三维外观空间中立方体的顶点。药剂效果只沿着立方体的边缘运行,有效地使其成为因果图。
3.每种药剂类型(颜色)在外观空间中仅向一个方向“移动”石头外观。也就是说,每种药剂只能沿着三次因果图的平行边运行。
4.药剂有固定的配对(红色/绿色,黄色/橙色,粉色/绿松石色),它们总是有相反的效果。例如,红色药水的效果在不同的情节中有所不同,但无论其效果如何,绿色药水都会产生相反的效果。
5.在某些化学中,因果图的边可能缺失,即任何一种药剂都不会影响两种特殊石头外观之间的过渡。然而,潜在因果图的拓扑不是任意的;它由生成语法控制,生成高度结构化的拓扑分布。
由于任务的这些概念方面在不同的episode中保持不变,因此从大量episode中收集的经验为agent提供了发现它们的机会,调整产生每一个episode和trail的生成过程的结构。正是在这个层次上学习的能力,以及利用所学知识的能力,与agent的元学习性能相对应。
Symbolic version
作为对Alchemy术规范3D版本的补充,我们还创建了任务的符号版本。这涉及到相同的潜在生成过程,并保留了对产生的潜在结构进行推理和规划的挑战,但排除了整个环境的视觉空间和运动复杂性。符号炼金术作为观察返回一个串联向量,指示所有取样药剂和石头的特征,并包含一个离散的动作空间,指定石头和放置它的容器(药剂或坩埚),加上一个无操作动作。全部细节见附录。
Ideal-observer reference agent
如引言中所述,当任务分布完全可访问时,可以构建一个贝叶斯最优的“理想观察者”基准代理,作为评估任何代理元学习性能的金标准。本文同样构建了这样一个agent,作为Ideal-observer,这个agetn可以观测到所有状态,并进行便利从而得到每个trail的最大reward。由此产生的策略既可以标记出可达到的最高任务分数(期望值),又可以暴露出最小后悔行为序列,从而在探索或实验与利用之间实现最佳平衡。
同样,有两个其他的agent:Oracle agent和random agent。



Experiments
Agent architectures and training
Agent performance
Augmentation studies
Conclusions from experiments
Discussion
我们引入了Alchemy,一个新的meta-RL研究基准任务环境。Alchemy在现有基准中是新颖的,它将两个可取的特征结合在一起:(1)结构性兴趣,由于其抽象、因果和组合的潜在组织,需要实验、结构化推理和战略行动排序;(2)结构可及性,由其明确定义的生成过程赋予,它提供了一个可解释的先验,并支持贝叶斯最优参考策略的构建,以及许多其他分析操作。希望Alchemy对更大的社区有用,我们正在发布开放源码的Alchemy环境的完整3D和符号版本,以及一套基准策略、分析工具和事件日志https://github.com/deepmind/dm_alchemy。
实验中测试的两种agent都没有表现出明显的元学习过程,从符号版alchemy的失败事实可以知道这不仅仅因为视觉复杂性或者实现任务目标所需行动数量造成的。值得指出的是,在我们看来,目前工作的主要贡献不在于炼金术本身的具体细节,而在于整个科学议程和方法。确定深度RL代理所拥有的知识水平是一项具有挑战性的任务,与试图确定真实动物的知识相当,并且(在后一种情况下)需要详细的认知建模。
作为结束语,我们注意到我们发布的炼金术包括一个人类可玩的版本。我们发现,许多人类玩家觉得炼金术有趣且具有挑战性,我们的非正式测试表明,有动机的玩家,经过充分训练,可以达到复杂的策略和高水平的表现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号