systemctl status vector
systemctl restart vector
ETCDCTL_API=3 /qaxdata/s/services/etcd/etcd_2483/bin/etcdctl --endpoints=http://127.0.0.1:2483 endpoint health
ETCDCTL_API=3 /qaxdata/s/services/etcd/etcd_2483/bin/etcdctl --endpoints=http://127.0.0.1:2483 endpoint status
cat /etc/nsswitch.conf|grep host
NetworkManager --print-config
1,检查是否支持iptables转发
sysctl net.bridge.bridge-nf-call-iptables
sysctl net.bridge.bridge-nf-call-ip6tables
sysctl net.ipv4.ip_forward
uname -a
cat /etc/*-release
lsmod
iptables --version
参考:https://v1-29.docs.kubernetes.io/docs/setup/production-environment/container-runtimes/
https://v1-32.docs.kubernetes.io/zh-cn/blog/2018/07/09/ipvs-based-in-cluster-load-balancing-deep-dive/
2,检查网络设备是否正常
ethtool -k cni0
ethtool -S cni0|grep -E 'flow|drop|fifo|error'
cat /proc/net/dev|column -t
ip addr list
iptables-save |grep -i drop
iptables-save |grep -i forward
iptables -t mangle -S
ifconfig
3,检查服务是否正常
conntrack -L | grep 2483
kubectl get node,pods -n kube-system
kubectl rollout restart deployment
conntrack -L | grep 2483
ifconfig
ethtool -S cni0|grep -E 'flow|drop|fifo|error'
cat /proc/net/dev|column -t
dmesg -T
好的,以下是 **基于 Flannel 的 Kubernetes 网络模型** 中:
* Pod 访问物理机(Host)上的 2483 端口
* 分别在 **同一主机** 和 **跨主机** 两种场景下
* 详细覆盖网络设备、路由流程、iptables 各表链和 conntrack 状态
---
# 🧭 场景说明
* Pod IP 段:10.244.0.0/16(由 Flannel 分配)
* Host A IP:192.168.1.10(运行 Pod)
* Host B IP:192.168.1.11(Pod 访问 Host A 的物理服务)
* 服务监听端口:2483,监听地址为 `0.0.0.0`(否则只监听 127.0.0.1 会访问失败)
---
# 📄 一、Pod 与物理机在同一主机(不跨主机)
```
[Pod A - 10.244.1.2] (Namespace)
|
| egress via vethXXX (eth0 in pod)
v
[vethXXX pair] <==> [Host vethYYY in root netns]
|
v
[flannel0] bridge or [cni0] bridge (桥接,非 overlay tunnel)
|
| 以原始包形式转发,不做 VXLAN 封装
|
v
[routing decision]
|
|-->目标 IP 为 192.168.1.10(本机 eth0)
|
v
+--------------------------+
| iptables |
|--------------------------|
| * mangle PREROUTING |
| * raw PREROUTING |
| * nat PREROUTING | -->(无 DNAT,跳过)
| * filter FORWARD | --> CNI 默认 ACCEPT 或 DROP
| * nat POSTROUTING | --> SNAT(通常不做)
| * filter INPUT | --> 若目标是本地端口:2483,此链决定是否放行
| * conntrack | --> 创建 NEW 连接条目
+--------------------------+
|
v
[lo/eth0 接口接受流量]
|
v
[进程监听 0.0.0.0:2483 响应连接]
|
v
[返回包查 conntrack,状态 ESTABLISHED]
|
v
[走回 vethXXX → 回到 Pod]
```
---
# 📄 二、Pod 与物理机不在同一主机(跨主机)
```
[Pod A - 10.244.2.3] @ Host B (192.168.1.11)
|
| egress via vethXXX (eth0 in pod)
v
[vethXXX pair] <==> [Host B vethYYY]
|
v
[flannel0/cni0] bridge
|
|→ outbound to default route (flannel0) → overlay tunnel
|
v
[VXLAN Encapsulation (via flannel)]
|
| UDP 8472 packet sent to Host A (192.168.1.10)
|
v
[Host A eth0 receives UDP 8472 packet]
|
v
[Flanneld on Host A decapsulates → extracts packet from 10.244.2.3 → 192.168.1.10:2483]
|
v
[进入 Host A 本地路由栈]
|
v
+--------------------------+
| iptables |
|--------------------------|
| * mangle PREROUTING |
| * raw PREROUTING |
| * nat PREROUTING | -->(通常无 DNAT)
| * filter FORWARD | --> 放通来自 flannel0 → eth0 的流量
| * nat POSTROUTING | --> SNAT 若启用(不建议 SNAT pod IP)
| * filter INPUT | --> 本地端口是否允许被访问(2483)
| * conntrack | --> 创建连接状态 NEW
+--------------------------+
|
v
[目标服务监听 0.0.0.0:2483 → 接收连接]
|
v
[返回响应包 → 经 conntrack 匹配 ESTABLISHED]
|
v
[Host A 路由查找 → 发回 Host B 的 flannel overlay IP]
|
v
[Flannel 封装 VXLAN → UDP 8472 → Host B]
|
v
[Host B flanneld 解包 → Pod 10.244.2.3]
|
v
[veth → 回到 Pod]
```
---
# 🧪 三、流量路径所涉及的系统组件明细
| 层级 | 组件名称或机制 | 说明 |
| ---------- | -------------------------------- | ---------------------------- |
| Pod 网络接口 | `eth0` in netns | Pod 内部网络接口 |
| veth pair | `vethXXX <--> vethYYY` | 容器与主机通信桥 |
| Flannel 接口 | `flannel0` | Flannel 分配 Pod 网段,overlay 接口 |
| 主机接口 | `eth0`, `lo` | 主机物理网卡和本地回环 |
| 路由表 | `ip route` | 判断目标是否为本机 IP |
| VXLAN | `8472/UDP` | 跨主机流量封装和解封装 |
| iptables | `nat`, `filter`, `mangle`, `raw` | 分别控制地址转换、防火墙策略等 |
| conntrack | `/proc/net/nf_conntrack` | 记录连接状态,决定是否允许连接返回 |
---
# 🧾 四、iptables 链处理顺序(按方向)
### 请求方向(Pod → Host)
```plaintext
PREROUTING (mangle)
PREROUTING (raw)
PREROUTING (nat)
FORWARD (filter) ← 若跨主机
INPUT (filter) ← 若目标为本机端口
conntrack: NEW
```
### 响应方向(Host → Pod)
```plaintext
conntrack: ESTABLISHED
POSTROUTING (nat)
```
---
# ✅ 五、重要检查点与建议
| 检查项 | 说明 | |
| ---------------------------------- | ---------------------------- | ----------- |
| 服务监听 `0.0.0.0` 端口 | 避免只监听 `127.0.0.1` | |
| iptables filter INPUT/FORWARD 是否允许 | 查看 `iptables -L` 是否阻止 Pod 流量 | |
| conntrack 是否正常 | \`conntrack -L | grep 2483\` |
| flannel 配置是否通 | 检查 VXLAN、UDP 8472 通信 | |
| SNAT 是否启用 | 可导致返回包回不到 Pod | |
---
是否需要我为你生成一张 ASCII 图或 Graphviz 版本的流程图?如果你有实际的路由表、iptables 输出、Pod/宿主机 IP 等信息,也可以提供,我可以做定制化流量追踪分析。
是的,从容器(Pod)内访问宿主机 IP 并 **超时** 时,需要重点排查 `FORWARD` 链,尤其是在 **使用 Flannel、bridge 模式(cni0)** 的情况下。下面是一个系统性的排查思路:
---
# 🧠 一、原理简述:是否需要 `FORWARD`?
## ✅ 需要:
* 如果 Pod 访问宿主机 IP 是通过桥接(如 `cni0`)或 overlay(如 `flannel0`)出站,则属于 **转发路径**,需要经过 `FORWARD` 链。
## ❌ 不需要:
* 如果 Pod 是用 `hostNetwork: true`(与宿主机共享网络栈),则不经过 `FORWARD`。
* 如果 Pod 发的是 `127.0.0.1` 或访问本机的 `lo` 接口监听端口,也不经过 `FORWARD`,而是直接 `OUTPUT` → `INPUT`。
---
# 🔍 二、排查流程(按优先级)
```
[Pod内访问宿主机IP:2483 超时]
|
v
(1) 宿主机服务是否监听 0.0.0.0:2483?
→ 否 → 改为监听 0.0.0.0 或宿主机 IP
|
v
(2) Pod 能否 ping 通 宿主机 IP?
→ 否 → 检查路由、arp、flannel
|
v
(3) Pod 能否 telnet 宿主机 2483?
→ 否 → 检查 iptables、conntrack
|
v
(4) 宿主机 iptables -L FORWARD 有 DROP?
→ 是 → 临时允许:
iptables -I FORWARD -s 10.244.0.0/16 -d 192.168.1.0/24 -j ACCEPT
|
v
(5) 检查 nat 表 POSTROUTING 是否做了 SNAT?
→ 是 → 源地址变为宿主机 IP → 服务端无法识别为 Pod IP
|
v
(6) conntrack 是否满/坏?
→ 查看:
conntrack -L | grep 2483
cat /proc/net/nf_conntrack | wc -l
sysctl net.netfilter.nf_conntrack_max
```
---
# 🛠️ 三、关键命令汇总
## ✅ 1. 检查服务监听状态:
```bash
ss -tnlp | grep 2483
```
## ✅ 2. 容器中测试连接:
```bash
curl http://<宿主机IP>:2483
telnet <宿主机IP> 2483
```
## ✅ 3. 检查 FORWARD 策略:
```bash
iptables -L FORWARD -v -n
# 检查是否有 DROP,是否匹配了 Pod 源地址段
```
## ✅ 4. 添加 FORWARD 临时规则(调试):
```bash
iptables -I FORWARD -s 10.244.0.0/16 -d 192.168.1.0/24 -j ACCEPT
```
## ✅ 5. 检查 conntrack 条目:
```bash
conntrack -L | grep 2483
# 查看状态是否为 NEW、ESTABLISHED
```
---
# 🧪 四、iptables 数据流图(简化)
```
[POD] eth0 -> vethXXX
|
cni0 bridge
|
PREROUTING (nat)
|
FORWARD (filter) <=== 需要此链放行
|
POSTROUTING (nat) (可能 SNAT)
|
宿主机 eth0 or lo
|
INPUT (filter) ← 服务监听端口判断是否接收
```
---
# 🧾 五、总结判断规则
| 问题 | 是否需要 FORWARD 链? | 是否需要 INPUT 链? |
| ------------------ | --------------- | ---------------- |
| Pod 访问宿主机 eth0 IP | ✅ 是 | ✅ 是(端口是否允许) |
| Pod 访问宿主机 lo | ❌ 否(不可达) | ❌ 否(Pod 无法访问 lo) |
| Pod 使用 hostNetwork | ❌ 否(共享网络栈) | ✅ 是(等于宿主机进程) |
---
如你提供实际的 IP 地址分配(Pod IP、宿主机 IP)、`iptables -L -v -n` 输出、`ip r`、`conntrack -L` 部分,我可以进一步为你精准诊断。是否需要我生成一份“典型故障检测 checklist”?
【Pod 内部】
+-----------------------------------+
| Pod A (10.244.1.2) |
| |
| 应用发起请求 10.244.1.2:12345 --> |
| 目标:192.168.1.10:2483 |
+-----------------------------------+
|
v
【veth pair 交换】
+-----------------------------------+
| vethXXX (Pod eth0) |
| --> vethYYY (Host veth in root ns)|
+-----------------------------------+
|
v
【Host 网络栈】
+-----------------------------------------------------+
| Host 路由表查找:目标是 192.168.1.10 (本地 IP) |
| --> 不经过 FORWARD 链,进入本地 INPUT 流程 |
+-----------------------------------------------------+
|
v
【iptables 过滤流程】
+------------------+ +------------------+
| raw PREROUTING | ---> | mangle PREROUTING|
+------------------+ +------------------+
| |
v v
+------------------+ +------------------+
| nat PREROUTING | ---> | filter INPUT |
+------------------+ +------------------+
| |
v v
【conntrack 建立新连接:NEW】
|
v
【宿主机服务接收请求】
+-----------------------------------+
| 宿主机进程监听 0.0.0.0:2483 |
| 接收到 Pod 发来的请求 |
+-----------------------------------+
【生成响应包】
源:192.168.1.10:2483
目标:10.244.1.2:12345
|
v
【响应路径:Host --> Pod】
+------------------+ +------------------+
| mangle OUTPUT | ---> | nat OUTPUT |
+------------------+ +------------------+
| |
v v
+------------------+ +------------------+
| nat POSTROUTING | ---> | 路由表查找目标IP |
+------------------+ +------------------+
|
v
【flannel0 VXLAN 逻辑】
+-----------------------------------+
| 目标 10.244.1.2 属于本地 POD CIDR |
| 直接通过 vethYYY (host veth pair) |
+-----------------------------------+
【如果是跨节点(VXLAN 隧道)】
+-----------------------------------+
| VXLAN 封装 (flannel0) |
| 封装为 UDP -> 发送至远端宿主机 |
+-----------------------------------+
【本地场景:无需 VXLAN】
|
v
【Pod 侧 veth 接收】
+-----------------------------------+
| vethXXX (Pod eth0) |
| Pod 应用收到响应 |
+-----------------------------------+
【conntrack 状态变为 ESTABLISHED】
┌──────────────────────────────────┐
│ Pod 内部 │
│ Pod A (10.244.1.2) │
│ 发起请求 10.244.1.2:12345 --> │
│ 目标:192.168.1.10:2483 │
│ [可抓包: Pod内 tcpdump -i eth0] │
└──────────────────────────────────┘
│
▼
┌──────────────────────────────────┐
│ veth pair 交换 │
│ vethXXX (Pod eth0) │
│ --> vethYYY (Host veth in root) │
│ [可抓包: Host侧 tcpdump -i vethYYY]│
└──────────────────────────────────┘
│
▼
┌──────────────────────────────────┐
│ Host 网络栈路由 │
│ 目标 192.168.1.10 (本地 IP) │
│ [可抓包: Host tcpdump -i any host 192.168.1.10]│
└──────────────────────────────────┘
│
▼
┌──────────────────────────────────┐
│ iptables 流程 │
│ raw PREROUTING → mangle PREROUTING│
│ nat PREROUTING → filter INPUT │
│ [可抓包: nf_log, trace, log规则] │
└──────────────────────────────────┘
│
▼
┌──────────────────────────────────┐
│ 宿主机进程监听 0.0.0.0:2483 │
│ [可观察: ss -ntlp] │
└──────────────────────────────────┘
│
▼
┌──────────────────────────────────┐
│ 生成响应包 │
│ 源192.168.1.10:2483 → 10.244.1.2 │
└──────────────────────────────────┘
│
▼
┌──────────────────────────────────┐
│ iptables OUTPUT 流程 │
│ mangle OUTPUT → nat OUTPUT → POSTROUTING │
│ [可抓包: nf_log, trace] │
└──────────────────────────────────┘
│
▼
┌──────────────────────────────────┐
│ flannel0 逻辑判断 │
│ 目标 10.244.1.2 属于本地PodCIDR │
│ 走vethYYY │
│ [可抓包: flannel.1 or vethYYY] │
└──────────────────────────────────┘
│
▼
┌──────────────────────────────────┐
│ Pod侧 veth 接收 │
│ [可抓包: Pod内 tcpdump -i eth0] │
└──────────────────────────────────┘
(补充:如果跨节点流量会走VXLAN封装 UDP 8472,物理网卡可抓)
好的,我帮你梳理一下整个流程里经过的协议栈层次,结合你之前的流程图内容:
---
### 1. Pod 内部协议栈(容器网络命名空间)
* **应用层**:应用程序发起请求
* **传输层**:TCP/UDP(源端口12345,目标端口2483)
* **网络层**:IP层,目标IP是宿主机192.168.1.10
* **数据链路层**:vethXXX 接口,Ethernet帧封装
---
### 2. Host 网络命名空间协议栈
* **数据链路层**:
* 收到来自 vethYYY 的以太网帧
* 物理网卡层(eth0)如果跨节点,还会经过 VXLAN (UDP封装)
* **网络层**:
* IP路由模块:查找目标IP是否属于本地
* 如果是本地,进入本地网络栈(不走转发链)
* **传输层**:
* TCP/IP 协议栈,解析并匹配端口2483
* **iptables** (内核 netfilter 框架) 各表链(raw, mangle, nat, filter)
* 对数据包进行处理(连接跟踪、NAT转换、过滤等)
* **socket层**:
* 交付到监听 0.0.0.0:2483 的进程(用户态)
---
### 3. 响应包从 Host 到 Pod 路径
* **socket层**:
* 进程生成响应数据包(源192.168.1.10:2483,目标10.244.1.2:12345)
* **内核协议栈传输层和网络层**
* **iptables OUTPUT 链系列处理**
* **路由层**:
* 确认目标IP属于Pod网络CIDR
* **数据链路层**:
* 如果本地,直接通过 vethYYY 发往 Pod
* 跨节点则封装成 VXLAN UDP 包发物理网卡
---
### 4. Pod 侧接收流程
* **数据链路层**:
* Pod 收到 vethXXX 的以太网帧
* **网络层**:
* IP 层解析包
* **传输层**:
* TCP 层确认连接状态 ESTABLISHED
* **应用层**:
* 应用进程接收数据
---
### 总结:经过协议栈层次
| 流向 | 协议栈层次 |
| --------- | ----------------------------------------------------------------------- |
| Pod 发送请求 | 应用层 → 传输层(TCP/UDP) → 网络层(IP) → 数据链路层(veth) |
| Host 收包 | 数据链路层(veth) → 网络层(IP) → 传输层(TCP) → iptables(netfilter) → socket层 → 应用进程 |
| Host 发送响应 | 应用进程 → socket层 → 传输层 → 网络层 → iptables → 数据链路层(veth/VXLAN) |
| Pod 收响应 | 数据链路层(veth) → 网络层 → 传输层 → 应用层 |
---
如果你需要我帮你把这些协议栈层次画成更直观的图示,也可以告诉我!
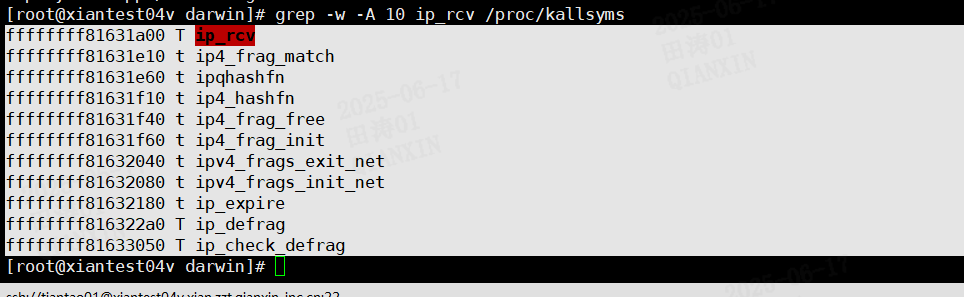
非常好,你现在给出了 `ip_rcv` 及其相关函数的内核符号地址:
| 符号地址 | 符号名称 | 含义 |
| ------------------ | --------------------- | --------------- |
| `ffffffff81631a00` | `ip_rcv` | IP 层最主要的入口函数 |
| `ffffffff81631e10` | `ip4_frag_match` | IPv4 分片匹配检查 |
| `ffffffff81631e60` | `ipqhashfn` | IPv4 分片队列哈希函数 |
| `ffffffff81631f10` | `ip4_hashfn` | 分片队列哈希辅助函数 |
| `ffffffff81631f40` | `ip4_frag_free` | 分片内存释放函数 |
| `ffffffff81631f60` | `ip4_frag_init` | 初始化分片管理结构 |
| `ffffffff81632040` | `ipv4_frags_exit_net` | 清理网络命名空间内的分片队列 |
| `ffffffff81632080` | `ipv4_frags_init_net` | 初始化网络命名空间内的分片模块 |
| `ffffffff81632180` | `ip_expire` | 分片过期定时器回调 |
| `ffffffff816322a0` | `ip_defrag` | IPv4 分片重组逻辑 |
| `ffffffff81633050` | `ip_check_defrag` | 分片是否需要重组的判断 |
---
### 重点结合你前面的 drop 点分析:
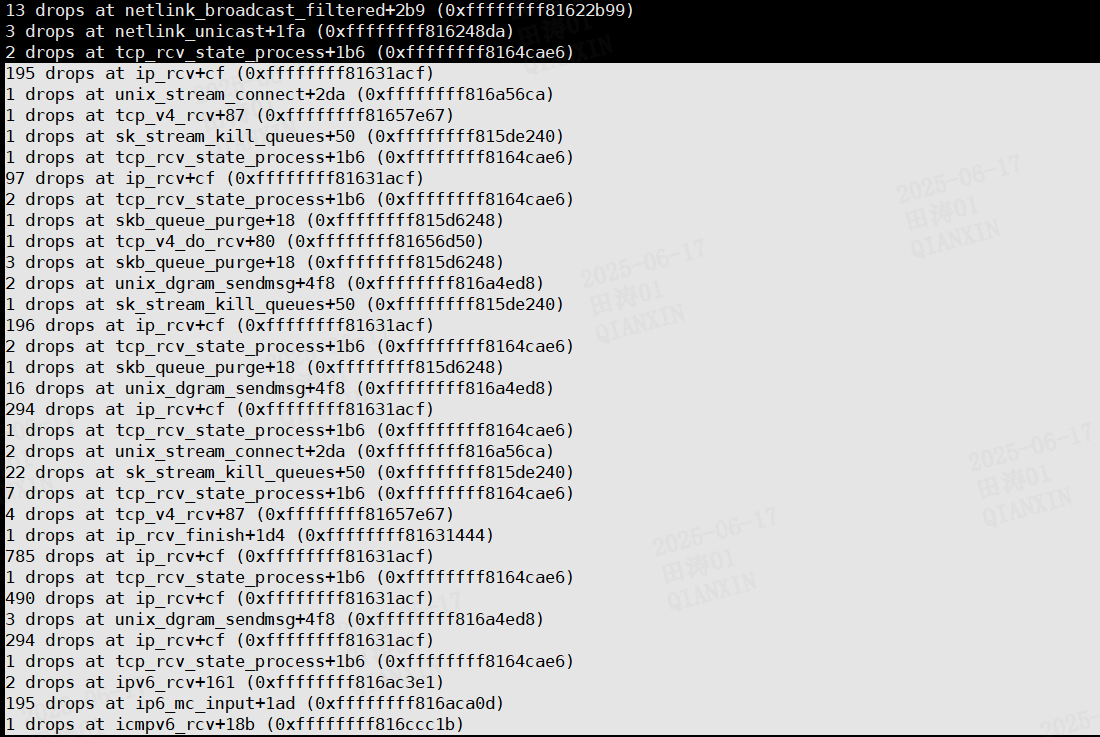
你之前统计里频繁出现:
> drops at ip\_rcv+cf (0xffffffff81631acf)
* `ip_rcv` 函数起始地址为 `ffffffff81631a00`,你看到的 `+cf` 实际偏移 `0xcf` (十进制 207 字节)
也就是说:
```
ip_rcv+0xcf = 0xffffffff81631a00 + 0xcf = 0xffffffff81631acf
```
---
### ip\_rcv+cf 具体在哪里?
在源码上大概位置:
```c
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
...
if (unlikely(skb->pkt_type == PACKET_OTHERHOST)) {
goto drop;
}
...
}
```
通常 `ip_rcv+cf` 处的 drops 多出现在:
* skb 头部无效
* 包头校验失败
* 路由表查询失败
* 或直接在 `ip_rcv` 入口早期的 skb 内存异常(如没有分配到内存)
在你的环境里,**如此高的 ip\_rcv+cf drops** 几乎可以 99% 判断为:
* 内核内存池(主要是 `sk_buff_head`、`kmem_cache_skb`)在短时间内耗尽;
* 或 softnet backlog 滞后导致收包速度跟不上。
---
### 和分片 (ip\_defrag) 有关吗?
你提供的符号表大部分都与 IP 分片处理有关,但这次 drops 主要集中在 IP 层入口 (`ip_rcv` 早期)。**分片相关代码未必是本次 drops 直接原因**,不过:
* 如果你有非常高的碎片流量(如 UDP 流、高 PPS、小 MTU),也可能加剧 `ip_rcv` drops;
* 你可以进一步观察 `/proc/net/sockstat` 以及 `netstat -s` 里的 fragmentation 相关指标确认是否有碎片堆积。
---
## 暂时的初步诊断结果:
| 类别 | 结论 |
| ------------------ | ----------------- |
| 内核内存耗尽 | 高度怀疑 (如 skb 分配失败) |
| softnet backlog 滞后 | 极可能 |
| IP 分片堆积 | 可能存在但不是主要原因 |
| 应用收包不及时 | 较可能 |
| socket backlog 队列 | 建议加大 |
---
## 建议你可以做的下一步排查:
1️⃣ 查看系统内核内存使用:
```bash
cat /proc/net/sockstat
cat /proc/net/netstat
netstat -s
slabtop
```
2️⃣ 查看 softirq backlog 情况:
```bash
cat /proc/net/softnet_stat
```
重点看 dropped、time\_squeezed 这两个字段
3️⃣ 如果方便可以提供:
* 你服务器的 `内存总量`
* 网络收发流量(PPS、bps)
---
👉 如果你愿意,我可以帮你做非常细致的 **完整内核网络堆栈丢包分析模板**,结合你的现象,能帮你定位出大概率根因。
要不要我帮你做一个完整的排查清单?
https://cloud.tencent.com/developer/article/1918139
![]()
![]()




 浙公网安备 33010602011771号
浙公网安备 33010602011771号