![]()
![]()
![]()
以下是关于 TiKV 中 **读取点(Read Point)** 和 **协处理器(Coprocessor)** 如何提升性能的详细解释:
---
### **1. 读取点(Read Point)的核心作用**
在 TiKV 中,**读取点(Read Point)** 是通过 **MVCC(多版本并发控制)** 实现的关键机制,用于确保数据的一致性和隔离性。其核心原理与优化点如下:
#### **(1) MVCC 与读取点的关系**
- **数据版本化**:每个键值对(Key-Value)附带时间戳(由 PD 分配的 TSO),记录写入版本(`commit_ts`)和删除版本(`delete_ts`)。
- **读取点定义**:事务或查询在读取数据时,指定一个时间戳(如事务的 `start_ts`),表示仅读取该时间戳之前已提交的数据版本。
- 示例:若事务的 `start_ts = 100`,则只能读取 `commit_ts ≤ 100` 的数据。
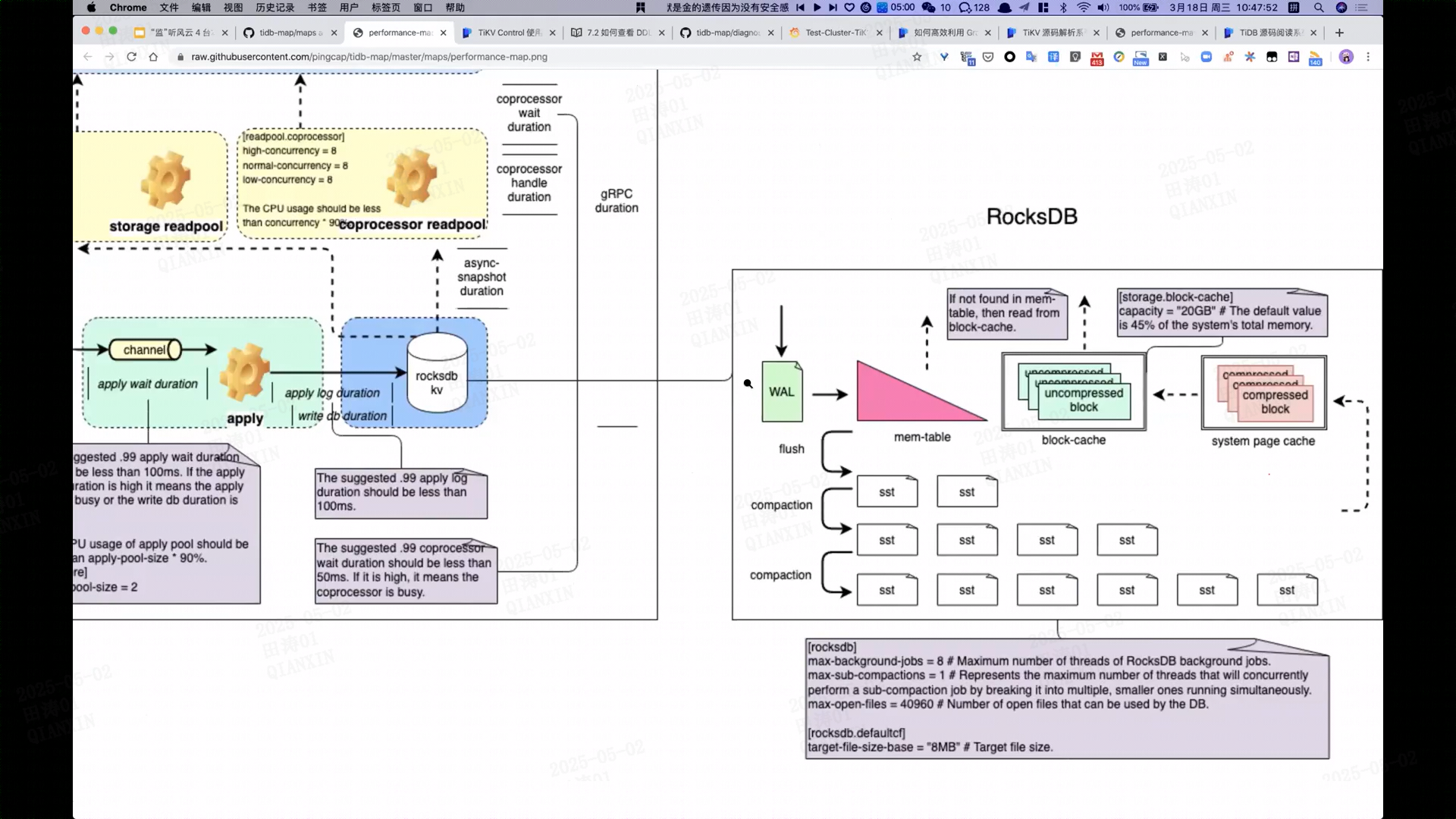
#### **(2) 存储层优化(Storage Read Point)**
- **快照隔离(Snapshot Isolation)**:
TiKV 存储引擎(基于 RocksDB)为每个读取点创建数据快照,避免读取过程中因写入冲突导致的锁等待。
- **性能优化**:
- **减少锁竞争**:读操作无需加锁,直接通过 MVCC 版本选择实现一致性。
- **并行读取**:不同事务的读取点互不干扰,支持高并发查询。
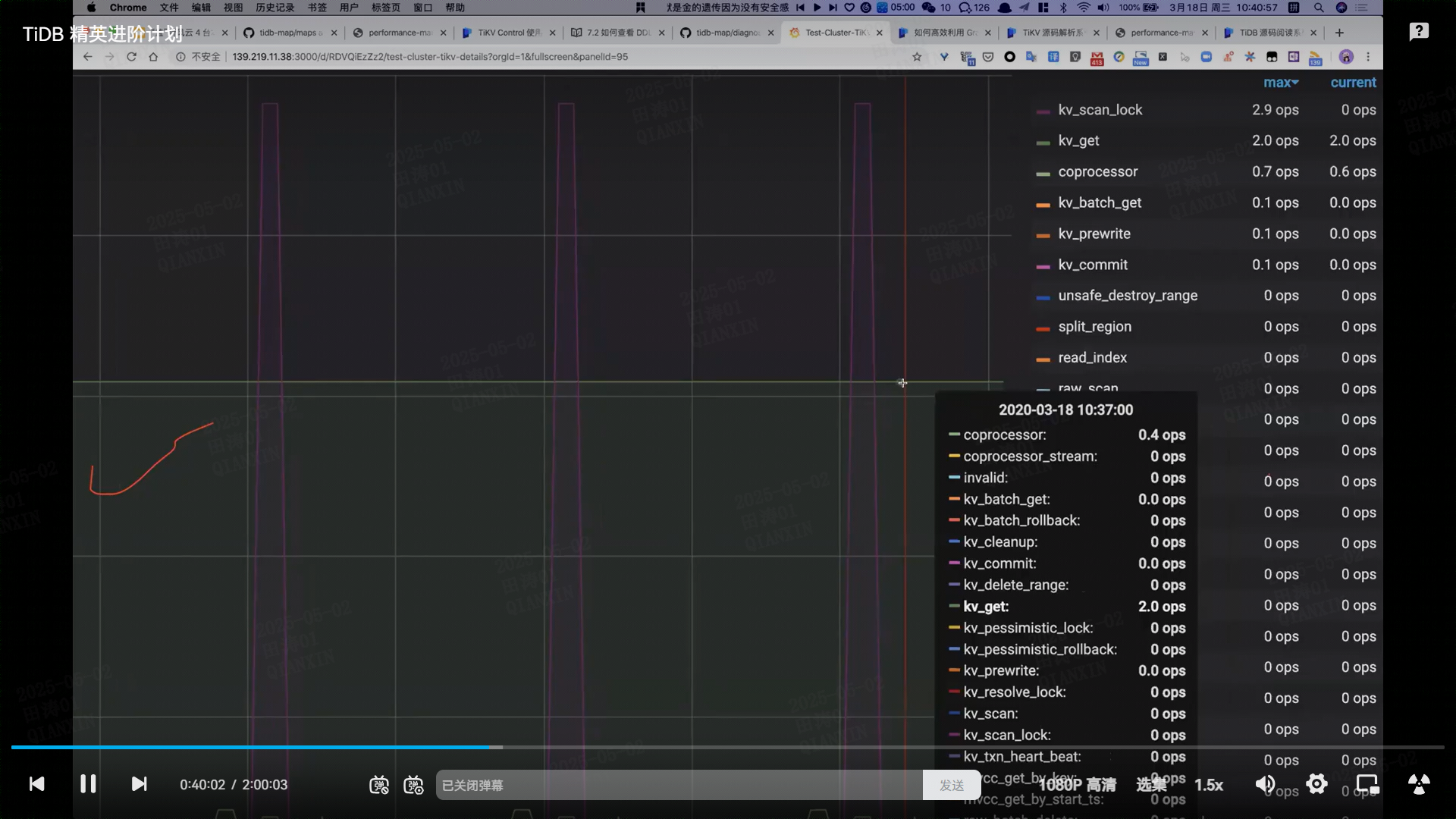
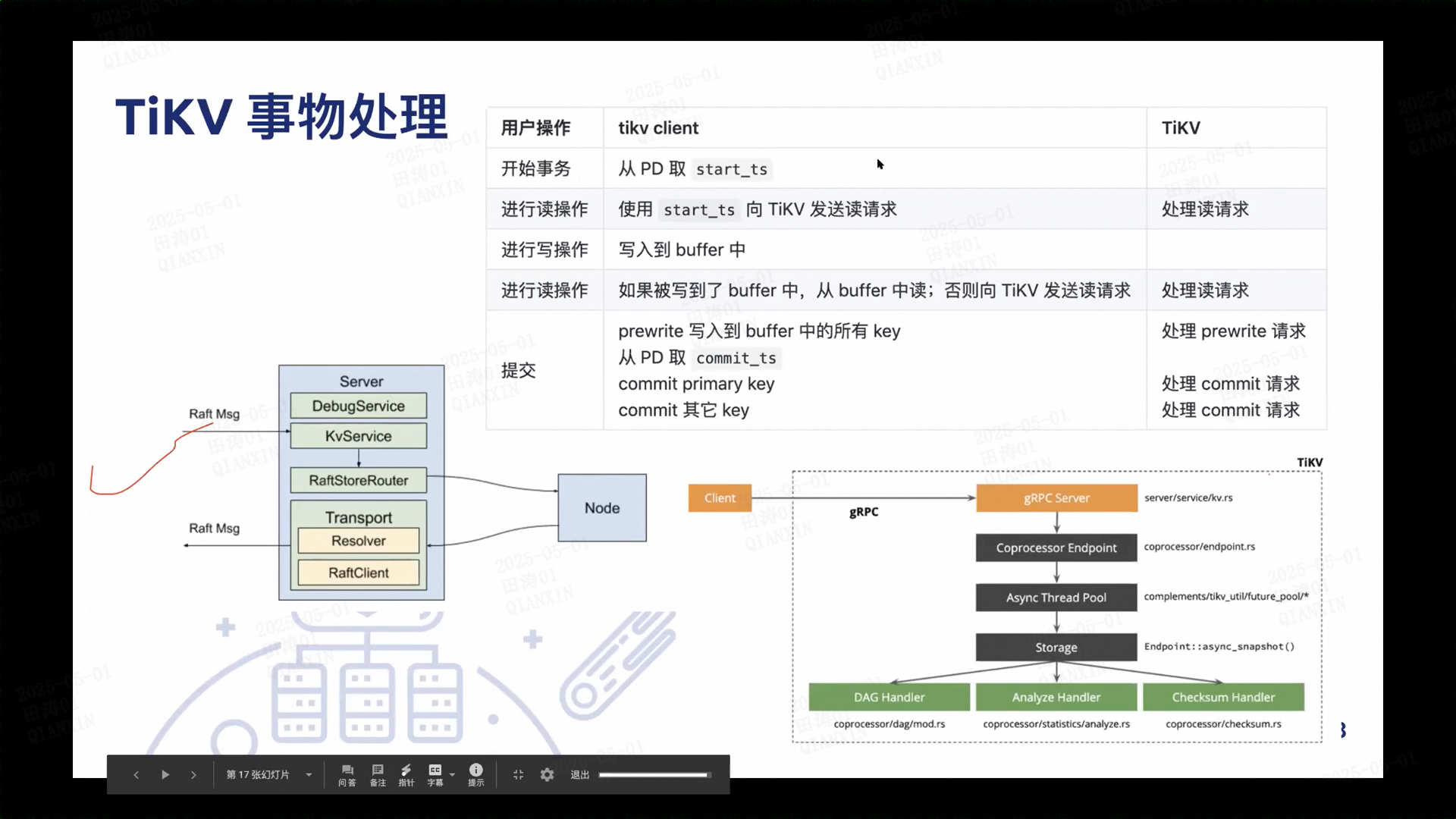
#### **(3) 协处理器的读取点(Coprocessor Read Point)**
- **下推计算的上下文**:
当 TiDB 将计算下推到 TiKV 的 Coprocessor 时,会传递事务的 `start_ts` 作为读取点,确保协处理器在本地读取一致的数据版本。
- **优化效果**:
- **减少网络往返**:过滤、聚合等操作直接在存储层完成,仅返回结果集。
- **避免重复版本检查**:协处理器基于读取点直接定位有效数据,跳过无效版本。
---
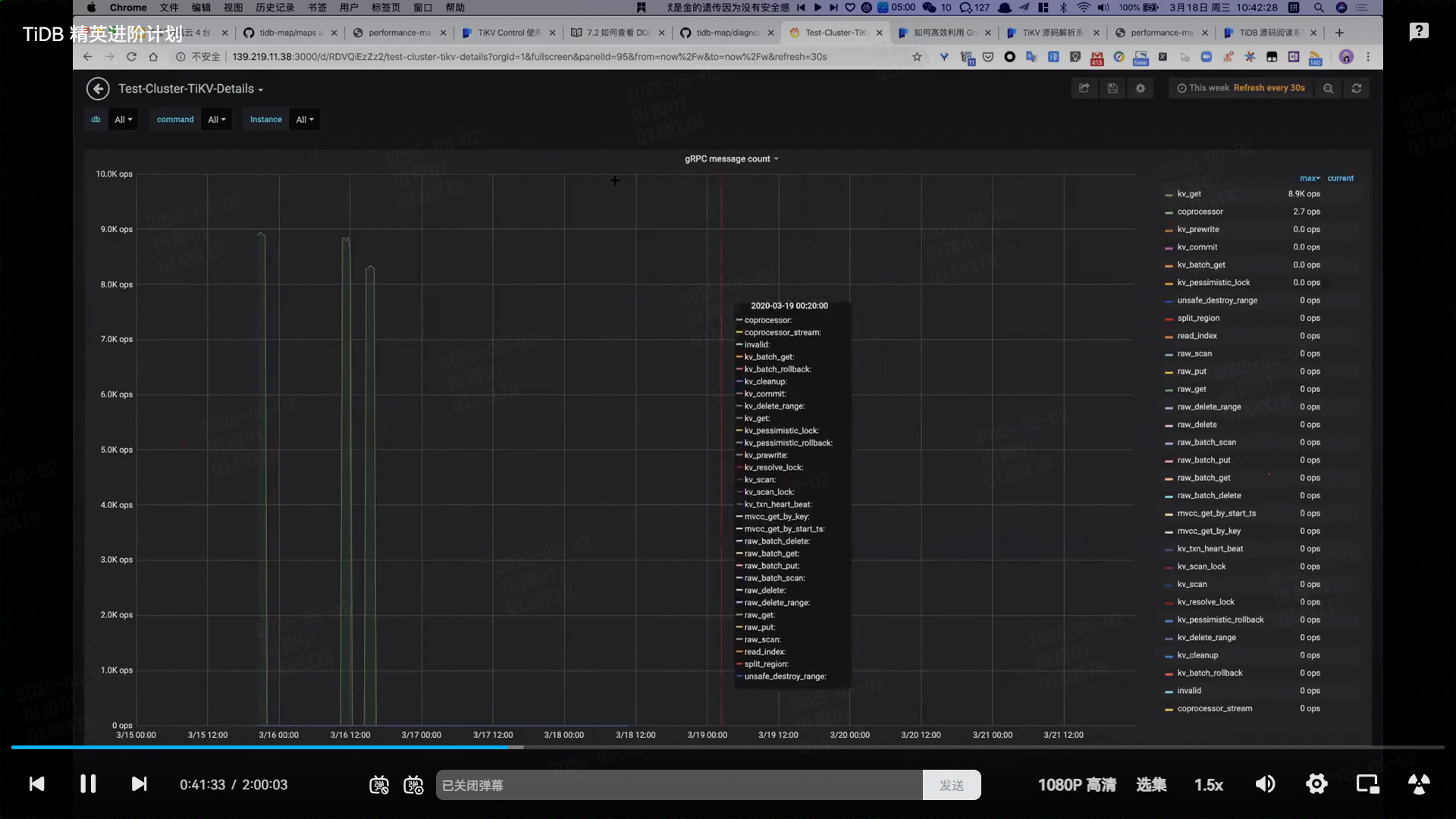
### **2. 协处理器(Coprocessor)如何加速 TiKV**
#### **(1) 计算下推的核心思想**
- **将计算靠近数据**:
将部分 SQL 计算逻辑(如过滤、聚合、排序)下推到 TiKV 节点执行,减少 TiDB 与 TiKV 之间的数据传输量。
- **示例**:
```sql
SELECT COUNT(*) FROM t WHERE age > 18;
```
- **无下推**:TiKV 返回所有数据,TiDB 在计算层过滤并计数。
- **有下推**:TiKV 直接过滤 `age > 18` 并计算 `COUNT(*)`,仅返回最终结果。
#### **(2) 协处理器与读取点的协同优化**
- **一致性保证**:
协处理器使用事务的读取点(`start_ts`)确保下推计算基于一致的数据快照。
- **减少数据传输**:
下推过滤(`WHERE`)和投影(`SELECT` 列)后,仅需传输少量数据到 TiDB。
- **资源利用率提升**:
分布式并行计算:多个 TiKV 节点并行处理不同 Region 的数据,TiDB 仅需聚合结果。
#### **(3) 性能提升的量化效果**
| **场景** | **网络传输量** | **TiDB 计算负载** | **TiKV 计算负载** |
|------------------------|----------------|-------------------|--------------------|
| **无协处理器下推** | 高(原始数据) | 高(全量处理) | 低(仅扫描数据) |
| **有协处理器下推** | 低(结果数据) | 低(聚合结果) | 高(本地计算) |
---
### **3. 实际案例:读取点与协处理器的协作流程**
#### **场景:执行 `SELECT SUM(sales) FROM orders WHERE region = 'Asia' AND ts <= 2023-01-01`**
1. **TiDB 解析与优化**:
- 生成执行计划,将 `WHERE region = 'Asia'` 和 `SUM(sales)` 下推到 TiKV。
2. **读取点传递**:
- TiDB 向 Coprocessor 传递事务的 `start_ts`(如 `1000`),确保读取 2023-01-01 前的数据。
3. **TiKV 协处理器执行**:
- 根据 `start_ts` 读取 MVCC 快照,过滤 `region = 'Asia'`,计算 `SUM(sales)`。
4. **结果返回**:
- TiKV 仅返回聚合结果(如 `SUM(sales) = 1,000,000`),而非全量数据。
#### **性能优化点**:
- **网络传输**:从 TB 级数据缩减为单个数值。
- **计算效率**:并行扫描多个 Region,本地聚合降低 TiDB 负载。
- **一致性**:基于读取点的 MVCC 快照,避免中途写入干扰。
---
### **4. 总结:为什么这些机制让 TiKV 更快?**
| **机制** | **优化目标** | **具体效果** |
|------------------------|---------------------|-----------------------------------------------------------------------------|
| **读取点(Read Point)** | 一致性 & 并发控制 | 无锁读取、快照隔离、高并发查询。 |
| **协处理器(Coprocessor)** | 计算下推 & 数据局部性 | 减少网络传输、分布式并行计算、降低 TiDB 负载。 |
| **MVCC 版本管理** | 多版本支持 | 避免写操作阻塞读操作,提升读写并发能力。 |
通过上述机制,TiKV 在保持强一致性的同时,显著提升了分布式查询的吞吐量和响应速度,尤其适合 OLAP 与 HTAP 混合负载场景。
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号