

tikv学习5shared region



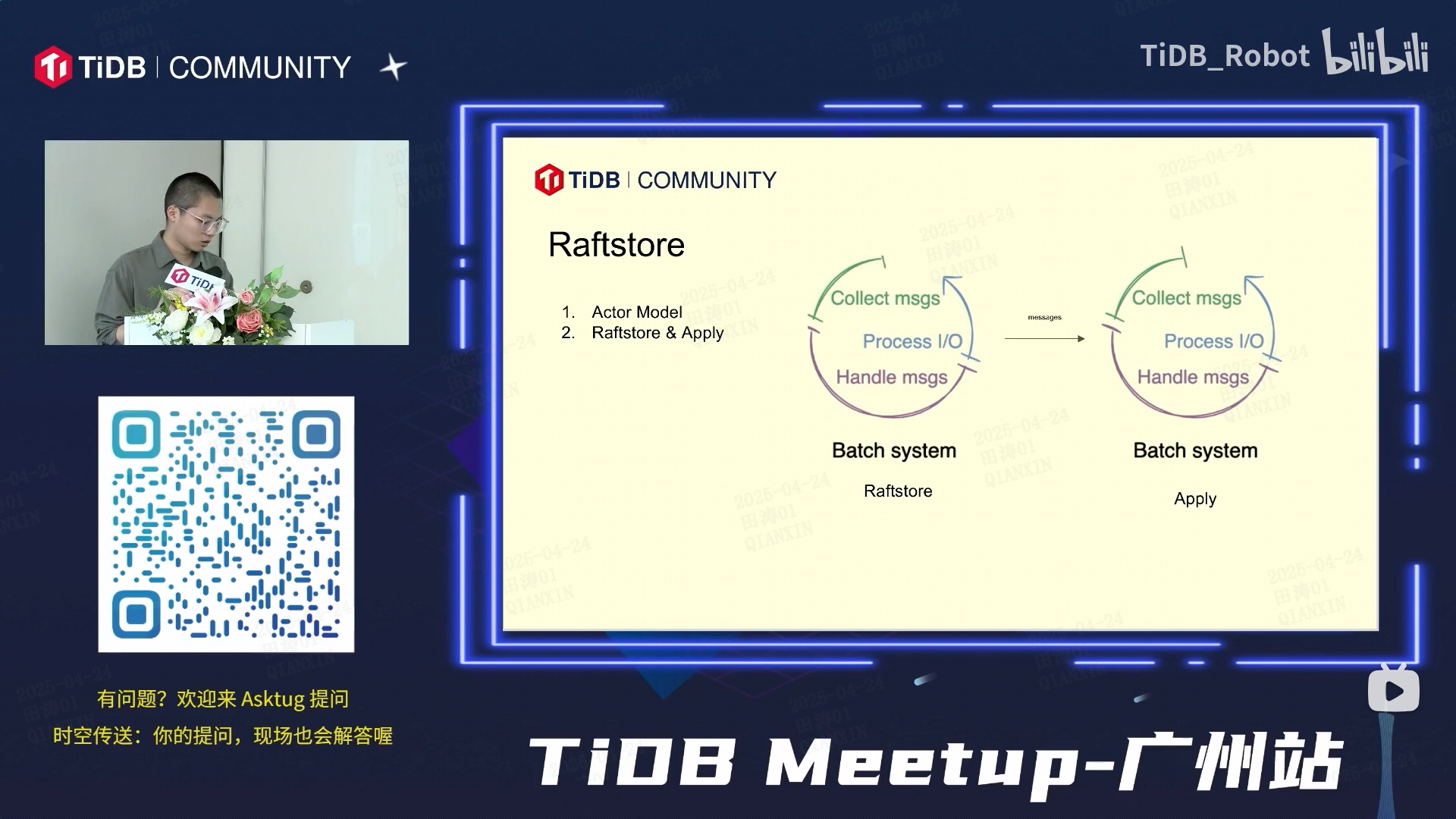
TiKV 是基于 Raft 协议和分布式键值存储的数据库引擎,以下是图像中核心概念的解析及其架构逻辑:
---
### **1. Actor Model(参与者模型)**
- **作用**:TiKV 使用多线程的 Actor 模型处理并发请求,每个 Actor 是独立的计算单元(如处理读写请求、复制日志等),通过消息传递实现异步通信。
- **流程**:
- **Collect msgs**:从客户端或其他节点收集请求消息。
- **Process I/O**:处理磁盘 I/O(如写入 RocksDB 存储引擎)。
- **Handle msgs**:处理消息逻辑(如生成 Raft 日志或返回响应)。
---
### **2. Raft & Rafstore(Raft 存储引擎)**
- **Raft 协议**:用于分布式一致性,确保数据在多个副本间同步。
- **Raftstore**:
- **功能**:管理 Raft 组(Region)的生命周期、日志复制、心跳检测等。
- **流程**:
- 将用户请求转换为 Raft 日志。
- 通过 Batch System(批量系统)将日志批量提交到 Raft 组的其他副本。
- 持久化日志到 RocksDB。
---
### **3. Apply(日志应用)**
- **作用**:将已达成共识的 Raft 日志应用到状态机(即实际存储引擎)。
- **流程**:
- **Batch System(批量系统)**:批量处理已提交的日志,提升效率。
- **Apply**:将日志中的操作(如写入、删除)应用到底层存储(RocksDB),完成数据持久化。
---
### **4. 其他关键点**
- **Batch System(批量系统)**:通过批量处理日志提交和应用,减少 I/O 次数,优化性能。
- **时空传送**:可能指 TiKV 的实时数据处理能力,请求会被立即分发并处理。
- **“学霸”相关**:可能是用户自定义的业务标签(如学习场景的激励机制),与 TiKV 核心功能无直接关联。
---
### **架构流程图**
```
Client Request
│
▼
Actor Model(处理消息)
│
▼
Raftstore(生成 Raft 日志,批量提交)
│
▼
Batch System(批量处理日志)
│
▼
Apply(应用日志到 RocksDB)
│
▼
Data Persisted(数据持久化)
```
---
### **总结**
TiKV 通过 **Actor 模型**实现高并发,依赖 **Raftstore** 保障分布式一致性,利用 **Batch System** 和 **Apply** 机制提升性能,最终将数据持久化到 RocksDB。图中提到的“学霸”可能是业务层的扩展功能,需结合具体场景进一步分析。


以下是图片中 Percolator 事务模型的核心概念解析:
---
### **1. Percolator 事务模型**
Percolator 是 Google 提出的分布式事务协议,TiDB 基于此实现了分布式事务。其核心是通过 **两阶段提交(2PC)** 和 **多版本时间戳(Timestamp Oracle)** 保障 ACID。
---
### **2. 三列存储结构**
Percolator 在存储层通过三列(Data、Lock、Write)管理事务状态:
| 列名 | Key 组成 | Value 内容 | Prewrite 阶段 | Commit 阶段 |
|--------|-------------------------|-----------------|---------------|-------------|
| **Data** | `{userKey}_{startTs}` | 用户数据(Value)| 写入 | 保留 |
| **Lock** | `{userKey}` | 锁元信息(如 Primary Key 和 TTL) | 写入 | 清除 |
| **Write** | `{userKey}_{commitTs}` | 提交时间戳(startTs) | 无 | 写入 |
- **Data 列**:存储实际数据,Key 包含 `startTs`(事务开始时间戳),实现多版本控制。
- **Lock 列**:记录事务锁信息,防止并发冲突。若事务失败,其他事务可通过检查 Lock 列回滚。
- **Write 列**:记录数据的最新提交版本,Key 包含 `commitTs`(事务提交时间戳),用于快速查找已提交数据。
---
### **3. 事务流程(两阶段提交)**
#### **阶段 1:Prewrite**
1. **选择 Primary Key**:任选一个 Key 作为 Primary Lock,其他为 Secondary Locks。
2. **写入 Data 列**:所有涉及 Key 的数据写入 Data 列(带 `startTs`)。
3. **写入 Lock 列**:在 Primary Key 和 Secondary Keys 的 Lock 列写入锁信息。
#### **阶段 2:Commit**
1. **提交 Primary Key**:向 Primary Key 的 Write 列写入 `commitTs`,并删除其 Lock 列。
2. **异步提交 Secondary Keys**:后台异步提交 Secondary Keys 的 Write 列并清除锁。
---
### **4. 关键机制**
- **Primary Lock**:事务提交的原子性保障。若 Primary Key 提交成功,则整个事务成功;否则事务回滚。
- **Secondary Locks**:依赖 Primary Lock 的状态,通过异步提交提升性能。
- **事务回滚**:若检测到 Lock 列中存在超时未提交的锁,其他事务会根据 Primary Key 回滚该事务。
---
### **5. 其他说明**
- **“事故”已提交**:可能是笔误,应为“事务已提交”,表示事务完成。
- **TIDB Meetup-T 网站**:指 TiDB 社区的技术分享活动,可获取更多实践案例。
- **时空传送**:TiDB 的实时数据处理能力,确保事务请求快速响应。
---
### **总结**
Percolator 模型通过 **两阶段提交** 和 **三列存储结构** 实现分布式事务:
- **Data 列**存储多版本数据,**Lock 列**管理并发锁,**Write 列**记录提交状态。
- Primary Key 保障原子性,Secondary Locks 优化性能。
- 事务失败时,依赖 Primary Key 的锁信息实现自动回滚。





 浙公网安备 33010602011771号
浙公网安备 33010602011771号