

本次采用一个主节点 3个从节点
1.安装4台虚拟机
-
先安装一台虚拟机
-
安装jdk
-
将下载的jdk解压到/usr/local目录下
-
将jdk加入到环境变量中
-
-
安装ssh
-
克隆这台虚拟机3次 并将克隆的虚拟机MAC地址重新生成
- 修改每台虚拟机的hostname 分别修改为Master(主节点)、Slave1、Slave2、Slave3
2. 固定每台虚拟机的IP地址
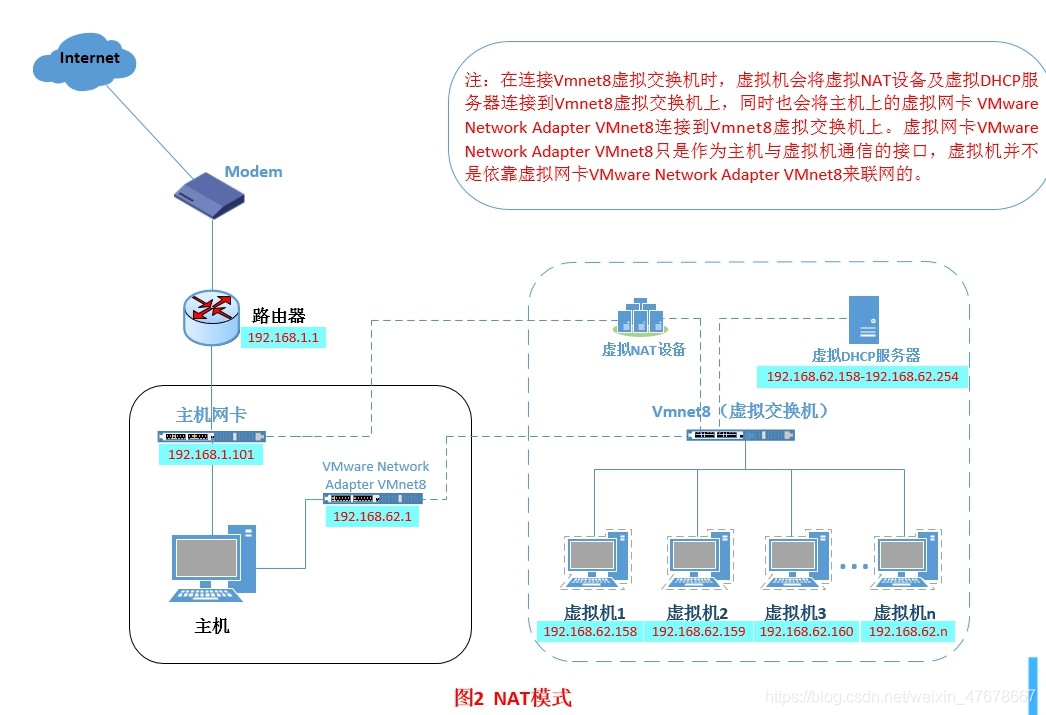
采用NAT模式 (主机和虚拟机、虚拟机与虚拟机之间可以互相通信)
NAT模式图解:
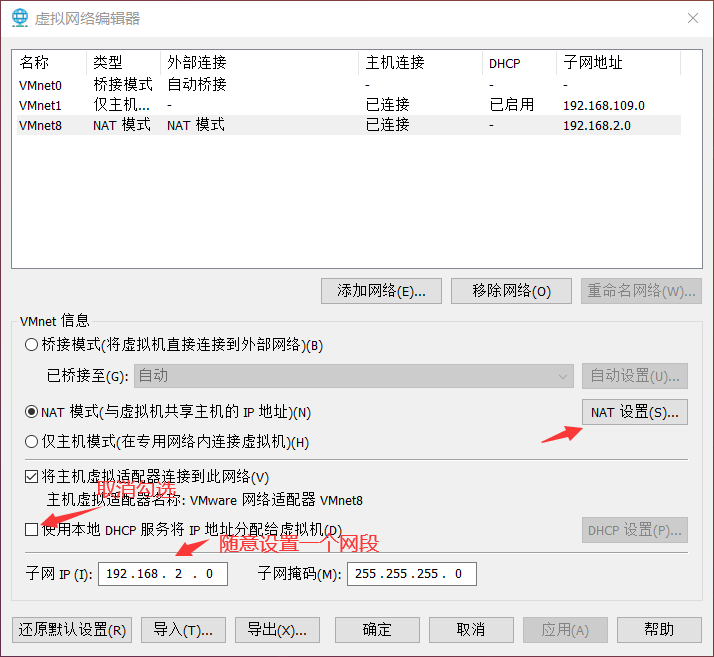
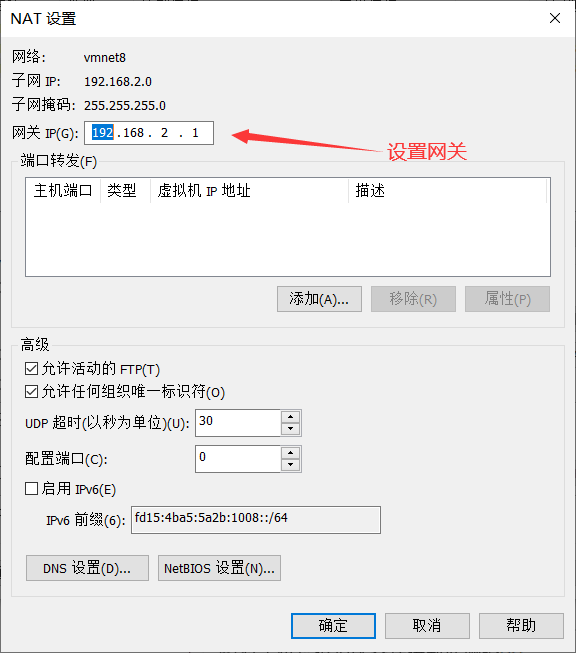
- 设置网段、网关 ,关闭虚拟DHCP服务
-
给每台虚拟机设置静态IP
ubuntu从17.10开始,已放弃在/etc/network/interfaces里固定IP的配置,即使配置也不会生效,而是改成netplan方式 ,配置写在/etc/netplan/01-netcfg.yaml或者类似名称的yaml文件里,修改配置以后执行
netplan apply命令让配置生效。$sudo nano /etc/netplan/50-cloud-init.yaml,配置文件可按如下内容修改。
network:
version: 2
renderer: networkd
ethernets:
ens33: #配置的网卡名称
dhcp4: no #dhcp4关闭
dhcp6: no #dhcp6关闭
addresses: [192.168.1.55/24] #设置本机IP及掩码
gateway4: 192.168.1.254 #设置网关
nameservers:
addresses: [114.114.114.114, 8.8.8.8] #设置DNS
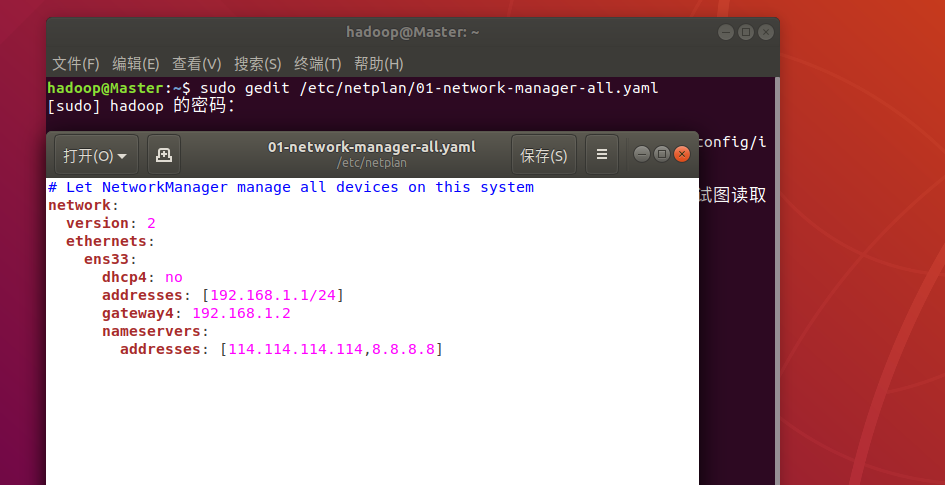
里面的内容有严格的缩进
设置完成后执行命令 sudo netplan apply 通过 ifconfig 命令可以查看是否设置成功
给每台虚拟机设置的IP地址为:
Master : 192.168.2.10
Slave1 : 192.168.2.11
Slave2 : 192.168.2.12
Slave3 : 192.168.2.13
配置完成后 各个虚拟机之间应该可以互相ping通。
3. 增加IP和主机名的映射
对每台虚拟机都进行下列操作:
修改/etc/hosts 文件
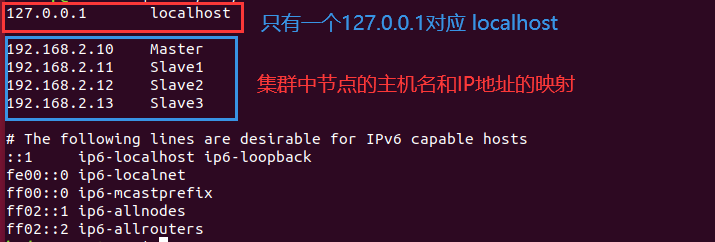
一般hosts文件中只能有一个127.0.0.1,其对应主机名为localhost,如果有多余127.0.0.1映射,应删除,特别是不能存在“127.0.0.1 Master”这样的映射记录。修改后需要重启Linux系统。
4. 设置ssh免密码登录
让Master节点可以SSH无密码登录到各个Slave节点上
在Master中操作
在每个从节点中操作
4. 安装并配置Hadoop
-
解压下载的Hadoop到/usr/local目录下 (在Master中操作)
-
修改Hadoop文件夹权限
-
将Hadoop加入到环境变量当中
-
修改 workers文件 (步骤4、5、6、7、8文件都在
/usr/local/hadoop/etc/hadoop/目录下)把所有数据节点的主机名写入该文件,每行一个,默认为 localhost(即把本机作为数据节点)在进行分布式配置时,可以保留localhost,让Master节点同时充当名称节点和数据节点,或者也可以删掉localhost这行,让Master节点仅作为名称节点使用。
本次让Master节点仅作为名称节点使用,故将workers文件中原来的localhost删除,只添加如下三行内容:
-
修改文件core-site.xml
-
修改文件hdfs-site.xml
-
修改文件mapred-site.xml
-
修改文件yarn-site.xml
-
将Master节点上的“/usr/local/hadoop”文件夹复制到各个节点上
-
如果之前运行过伪分布式 切换到分布式集群之前先删除掉临时文件
在Master中操作:
在各个从节点操作:
-
-
首次启动Hadoop集群时,需要先在Master节点执行名称节点的格式化
5. 启动Hadoop
-
在Master中执行如下命令
-
通过jps命令查看各个节点启动的进程
主节点:
![]()
从节点:
![]()
-
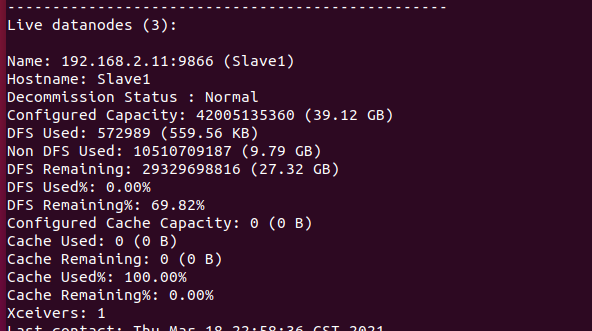
可以在在Master节点上通过命令“hdfs dfsadmin -report”查看数据节点是否正常启动 ,“Live datanodes”不为 0 ,则说明集群启动成功 也可以访问http://localhost:9870 ,通过 Web 页面看到查看名称节点和数据节点的状态。
![]()
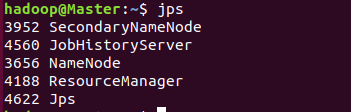
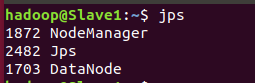
6. 执行分布式实例
在执行过程中,可以在Linux系统中打开浏览器,在地址栏输入“http://master:8088/cluster”,通过Web界面查看任务进度
运行结果:
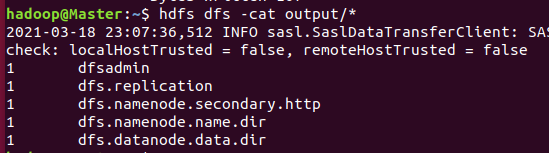
关闭Hadoop集群:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号