
关联规则
一、关联规则概述及相关指标
1、关联规则概述
寻找物品间的关联规则也就是要寻找物品之间的潜在关系。要寻找这种关系,有两步,以超市为例:
- 找出频繁一起出现的物品集的集合,我们称之为频繁项集。比如一个超市的频繁项集可能有{{啤酒,尿布},{鸡蛋,牛奶},{香蕉,苹果}}
- 在频繁项集的基础上,使用关联规则算法找出其中物品的关联结果。
简单点说,就是先找频繁项集,再根据关联规则找关联物品。
为什么要先找频繁项集呢?还是以超市为例,你想想啊,我们找物品关联规则的目的是什么,是为了提高物品的销售额。如果一个物品本身购买的人就不多,那么你再怎么提升,它也不会高到哪去。所以从效率和价值的角度来说,肯定是优先找出那些人们频繁购买的物品的关联物品。
2、关联规则的几个指标
例子:
| 交易编号 | 购买商品 |
| 0 | 牛奶,洋葱,肉豆蔻,芸豆,鸡蛋,酸奶 |
| 1 | 莳萝,洋葱,肉豆蔻,芸豆,鸡蛋,酸奶 |
| 2 | 牛奶,苹果,芸豆,鸡蛋 |
| 3 | 牛奶,独角兽,玉米,芸豆,酸奶 |
| 4 | 玉米,洋葱,洋葱,芸豆,冰淇淋,鸡蛋 |
(1)支持度(Surport):项集出现的频率,计算公式如下:
支持度 = (包含物品A的记录数量) / (总的记录数量)
用上面的超市记录举例,一共有五个交易,牛奶出现在三个交易中,故而{牛奶}的支持度为3/5。{鸡蛋}的支持度是4/5。牛奶和鸡蛋同时出现的次数是2,故而{牛奶,鸡蛋}的支持度为2/5。
(2)置信度(Confidence):指在购买物品A的前提下,再购买物品B的几率。计算方式是这样:
置信度( A -> B) = (包含物品A和B的记录数量) / (包含 A 的记录数量)
(牛奶,鸡蛋)的支持度是2/5,(鸡蛋)的支持度是4/5。故Confidence(牛奶->鸡蛋)=(2/5) / (4/5)。
(3)提升度(Lift):指当销售一个物品时,另一个物品销售率会增加多少。计算方式是:
提升度( A -> B) = 置信度( A -> B) / (支持度 A)
上面我们计算了牛奶和鸡蛋的置信度Confidence(牛奶->鸡蛋)=2 / 4。牛奶的支持度Support(牛奶)=3 / 5,那么我们就能计算牛奶和鸡蛋的支持度Lift(牛奶->鸡蛋)=0.83
当提升度(A->B)的值大于1的时候,说明物品A卖得越多,B也会卖得越多;
提升度等于1则意味着产品A和B之间没有关联;
提升度小于1那么意味着购买A反而会减少B的销量。
二、频繁项集——Apriori算法
Apriori算法:一种找出频繁项集的高效算法。
(1)Apriori算法的核心
支持度越高,说明项集越受欢迎,直接遍历所有组合计算它们的支持度虽然可以找出所有频繁项集,但是花的时间太多,效率太低,假设有N个物品,那么一共需要计算2^N-1次。每增加一个物品,数量级是成指数增长。而Apriori就是一种找出频繁项集的高效算法。它的原理就是下面这句话:
某个项集是频繁的,那么它的所有子集也是频繁的。
这句话看起来是没什么用,但是反过来就很有用了。
如果一个项集是 非频繁项集,那么它的所有超集也是非频繁项集。
如图所示,我们发现{A,B}这个项集是非频繁的,那么{A,B}这个项集的超集,{A,B,C},{A,B,D}等等也都是非频繁的,这些就都可以忽略不去计算。运用Apriori算法的思想,我们就能去掉很多非频繁的项集,大大简化计算量。
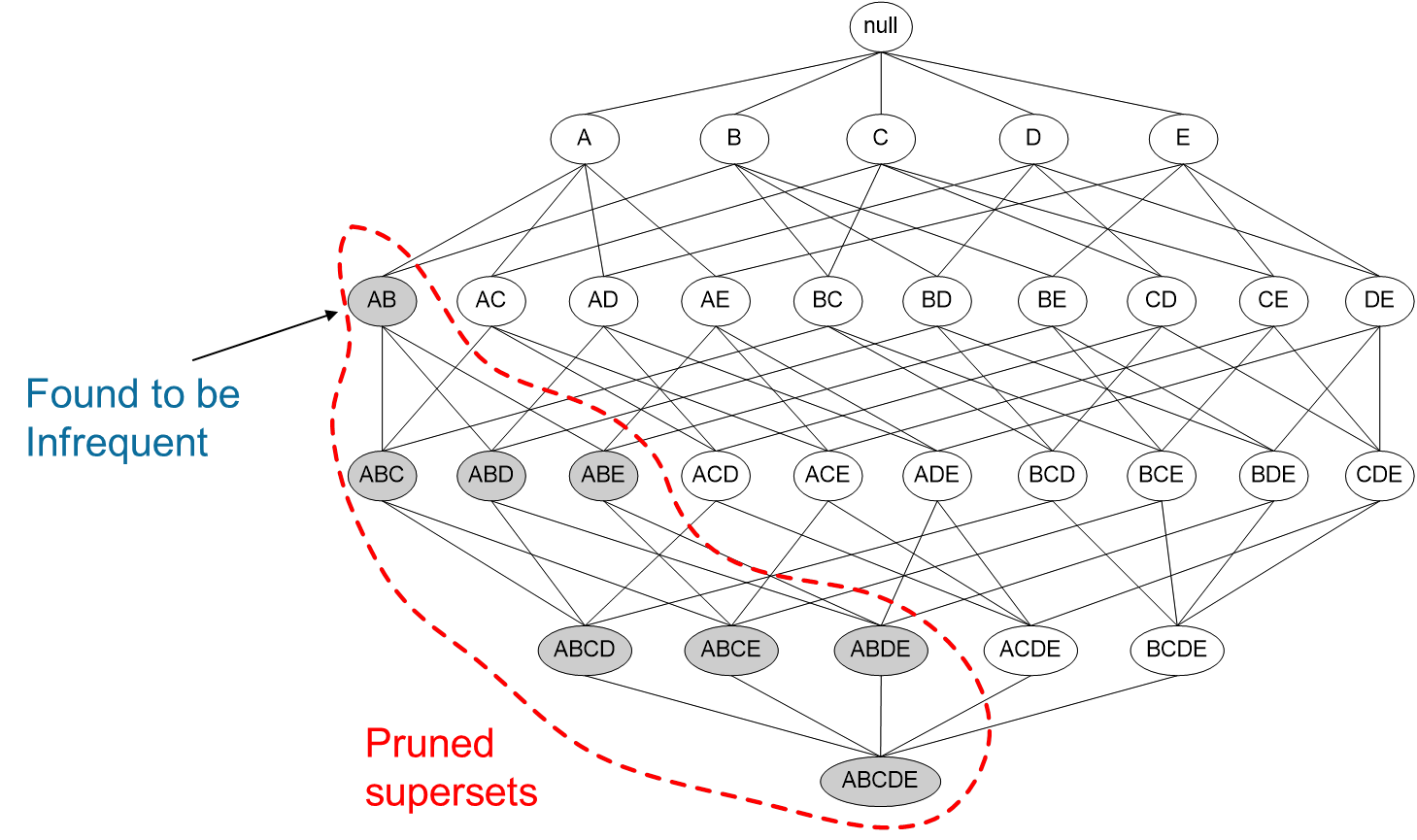
(2)Apriori算法的主要步骤
主观决定给Apriori提供一个最小支持度参数,然后Apriori会返回比这个最小支持度高的那些频繁项集:
a.首先会生成所有单个物品的项集列表
b.扫描交易记录来查看哪些项集满足最小支持度要求,那些不满足最小支持度的集合会被去掉
c.对剩下的集合进行组合以生成包含两个元素的项集
d.接下来重新扫描交易记录,去掉不满足最小支持度的项集,重复进行直到不再有物品可以组合。
三、关联规则
前面已经用Apriori得到频繁项集了。那么就可以在频繁项集的基础上,找到这里面的关联规则。而计算关联规则所用到的,就是置信度和提升度。
*当我们发现置信度(A->B)很高的时候,反过来的值置信度(B->A)不一定很高。
一个物品的关联结果是非常多的,但Apriori思想运用在置信度上也是合适的:
如果一个关联结果的置信度低,那么它的所有超集的置信度也低。
这样一来,就能节省很多的计算量。
参考资料:
【1】http://www.imooc.com/article/details/id/291047
【2】http://www.imooc.com/article/291499
【3】https://blog.csdn.net/qq_36523839/article/details/82191677
【4】常用关联算法总结:https://blog.csdn.net/songguangfan/article/details/93494082

 浙公网安备 33010602011771号
浙公网安备 33010602011771号