第三次作业——结对编程
|
Github项目地址 |
|
|
结对伙伴的作业地址 |
https://www.cnblogs.com/cristiano7/p/10640000.html |
|
我的博客地址 |
|
|
作业链接 |
https://edu.cnblogs.com/campus/xnsy/SoftwareEngineeringClass1/homework/2882 |
一.结对过程
这次结对,本人和搭档找了双方都有空的时间进行有关代码设计文档等的讨论,讨论完后根据个人的编程能力水平,分配任务。各自任务完成后,先自审,再交由对方复审,然后再将双方的代码合并,封装成dll文件,之后进行单元测试与效能分析,并对代码进行改进和增加新功能,最后撰写博客。下图是我们正在对合并好的代码进行单元测试时的照片。
(由于隐私问题,该照片已被本人删除)
二.PSP表格
双方共同制定的psp表格如下:
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
35 | 40 |
|
· Estimate |
· 估计这个任务需要多少时间 |
1770 | 1950 |
|
Development |
开发 |
1620 | 1780 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
50 | 60 |
|
· Design Spec |
· 生成设计文档 |
45 | 35 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
30 | 35 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
25 | 30 |
|
· Design |
· 具体设计 |
70 | 80 |
|
· Coding |
· 具体编码 |
1200 | 1320 |
|
· Code Review |
· 代码复审 |
140 | 150 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
60 | 70 |
|
Reporting |
报告 |
150 | 170 |
|
· Test Report |
· 测试报告 |
60 | 70 |
|
· Size Measurement |
· 计算工作量 |
60 | 50 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 | 50 |
|
合计 |
1805 | 1990 |
PSP的目的是:记录工程师如何实现需求的效率,和我们使用项目管理工具(例如微软的Project Professional,或者禅道等)进行项目进度规划类似。
三.解题思路描述
在拿到题目的一开始,本人一头雾水,不知道应该如何下手,因为对c#文件操作的不熟悉,在编写代码前查阅了大量资料,并且对cmd命令行操作进行了研究。
对字符数,行数及单词总数的统计,使用循环和ReadLine结合,逐行读取文本文档操作,这样能更为精确的进行统计。考虑到统计字符数后面的要求只统计AscII码,故在逐行读取文本文件内容时,应将内容利用StreamReader(path, Encoding.ASCII)将其中的每个字符转化为其相应的AscII值。
对单词的判断,使用正则表达式匹配法,精确匹配符合要求的单词,为此,上网查询了许多与正则表达式有关的资料,其中这篇资料对这次编程提供了很大的帮助,链接:https://www.cnblogs.com/hehehehehe/p/6043710.html
之后就是对词组的判断了,选择利用双重循环来判断词组,最后利用排序等方法输出指定长度的词组及其词频,并按照字典序排序。
四.设计实现过程
由于编程经验欠缺,这次设计参考了网络上的许多代码,并且因为搭档水平也不够,所以这次设计大多是由本人进行设计。搭档完成的部分为统计字符数,单词总数,有效行数和对单词进行判断。这部分代码和设计在搭档博客中。
之后,在将两人的代码合并后,将判断单词的方法IsWords(),统计字符的方法CountChar(),统计单词总数的方法CountSumofWords()和统计词频的方法CountWord()这几个方法封装在了一个类Words中,以便能将这些功能作为一个独立的模块运行以满足不同的需求,并将其在WordCount中进行调用。这就是“Information Hiding”原则和“Loose Coupling“原则的体现。在主函数中,通过switchcase语句,增强程序的人机交互性能和接口的稳定性,这体现的是“Interface Design”原则。
在实现输出词频和输出词组词频的方法中,判断单词的方法IsWords()在这里是很重要的,在这两个方法中都需要对这一方法进行引用。
本人设计的是输出文本文件中频率前n位的单词及其词频输出和用户给定长度词组词频按字典序输出的方法,这两个算法的独到之处就是利用linq语句进行排序,比起一般的冒泡排序等排序方法效率更高。而且由于利用了c#中的字典操作,在排序前将单词存入字典中,查找速度更快。
设计输出词频的方法,首先需要创建从单词到频率的新映射,使用dictionary<string,int>创建从string到int的空白映射,将用它统计每个单词在一段给定文本中的频率,然后,利用IsWords方法找出文本中的所有单词,将这些单词一同存入一个链表当中,最后遍历链表,对每个单词都检查它是否已经在映射中。如果是,就增加现有计数,否则,就为单词赋予一个初始计数1 ,负责递增的代码不需要执行到 int的强制类型转换,就可以执行加法运算:取回的值在编译时是int类型。统计完后输出各个单词的词频,使用linq语句进行排序,输出按照字典序排序的单词词频。
设计输出词组频率的方法与输出词频的方法类似,只需要增加判断词组的语句即可,先通过传入参数确定词组的长度,同样对文本文件中每行进行遍历操作,将长度符合要求的词组组成字符串,之后进行与输出词频方法类似的循环遍历每行,计算出各个长度符合要求的词组的词频即可。
五.代码规范
代码规范参考:http://www.cnblogs.com/wulinfeng/archive/2012/08/31/2664720.html
六.改进记录
在写完第一个版本的程序后,发现在输出文本文档中单词数的时候,对于下面的示例文本文档进行单词总数输出时:

程序会将第一行的第五个单词和下一行的单词连在一起,形成一个单词,这样得到的单词总数就不正确,在发现这个问题后,在正则表达式中加入了对换行符的匹配,解决了这一问题。
然后在改完这个问题后,对初次完成的项目进行了一次性能分析,截图如下:
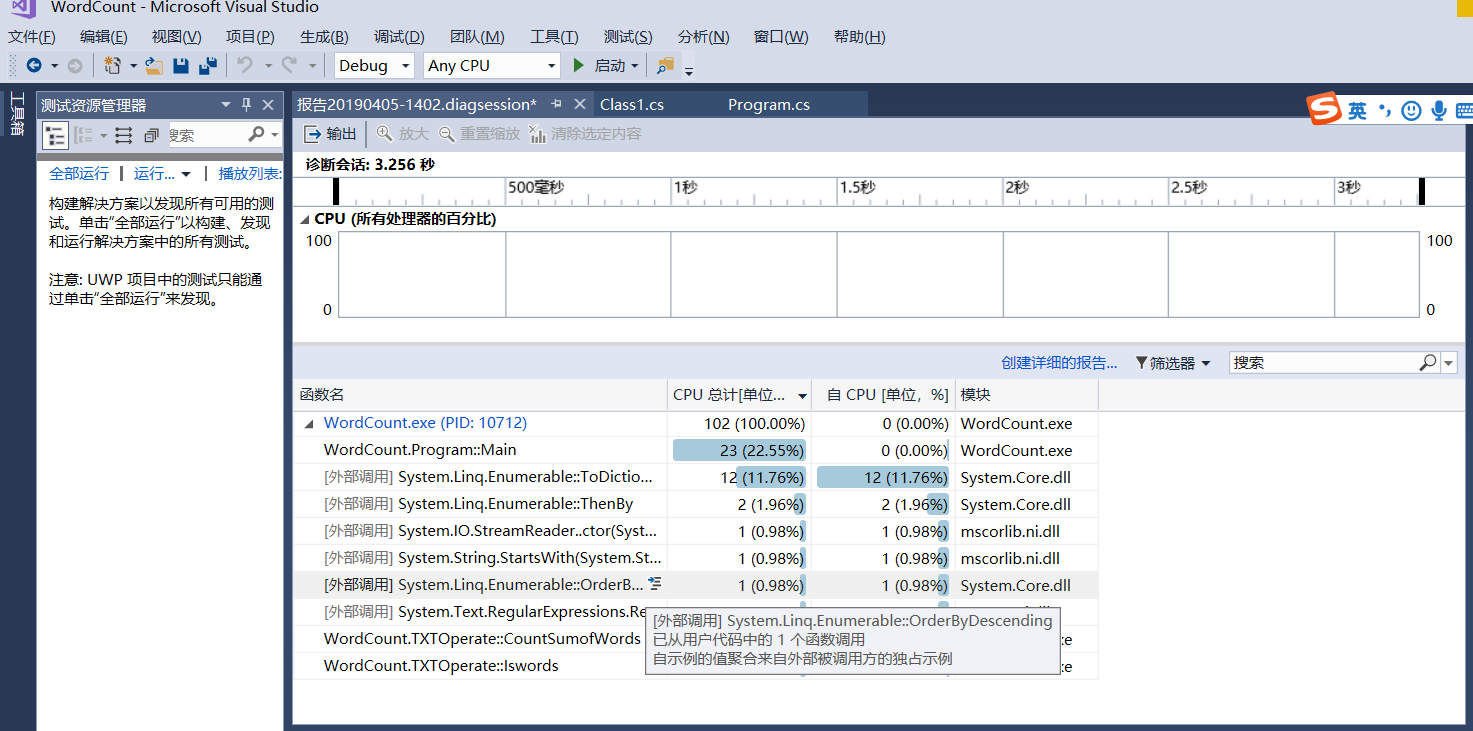
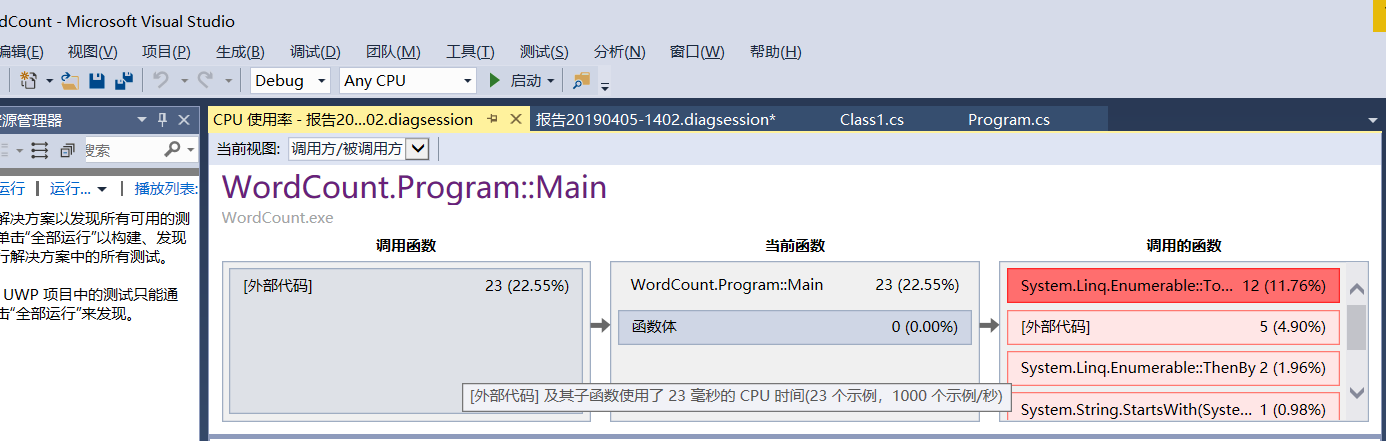
在经过性能分析后,发现其中消耗最大的是main函数,原因是因为一些必要的命令行操作导致循环次数过多。本来如果找到了执行操作就应该终止,但实际上会产生不必要的消耗,于是就在循环后添加了break关键字,消耗减小。改进程序性能大约花费15分钟左右。
消耗最大的函数展示:
七.代码说明
由于本人设计的部分为词频输出和词组词频输出,这两部分都是重要部分,其代码见下,设计思路在设计实现过程中有,不再阐述。
词频输出:
/// <summary> /// 单词词频输出 /// </summary> /// <param name="path"></param> /// <returns></returns> public static Dictionary<string, int> CountWord(string path) { List<string> list = new List<string>(); list = TxtOperate.Iswords(path); Dictionary<string, int> frequencies = new Dictionary<string, int>(StringComparer.OrdinalIgnoreCase); foreach (string word in list) { if (frequencies.ContainsKey(word)) { frequencies[word]++; } else frequencies[word] = 1; } return frequencies; }
词组词频输出:
/// <summary> /// 词组词频输出 /// </summary> /// <param name="path"></param> /// <param name="n"></param> /// <returns></returns> private static Dictionary<string, int> CountPhrase(string path, int n) { List<string> list = new List<string>();//存储符合要求的单词集合 list = TxtOperate.Iswords(path); Dictionary<string, int> frequencies = new Dictionary<string, int>(StringComparer.OrdinalIgnoreCase); string s = "";//将长度为n的词组存入字符串 for (int i = 0; i <= list.Count - n; i++) { int j; for (s = list[i], j = 0; j < n - 1; j++) { s += " " + list[i + j + 1]; } if (frequencies.ContainsKey(s)) { frequencies[s]++; } else frequencies[s] = 1; } return frequencies; }
八.单元测试
代码:
using Microsoft.VisualStudio.TestTools.UnitTesting; using WordCount; using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace WordCount.Tests { [TestClass()] public class TxtOperateTests { [TestMethod()] public void IswordsTest() { string path = "good123"; Assert.IsNotNull(TxtOperate.Iswords(path)); //Assert.Fail(); } [TestMethod()] public void CountCharTest() { string str = "Hello world!I am a boy."; int count = str.Length; Assert.AreEqual(TxtOperate.CountChar(str), count); string str1 = ""; Assert.AreEqual(TxtOperate.CountChar(str1), str1.Length); //Assert.Fail(); } [TestMethod()] public void CountSumofWordsTest() { string path = "Hello world!I am a boy."; Assert.AreEqual(2,TxtOperate.CountSumofWords(path)); //Assert.Fail(); } } }
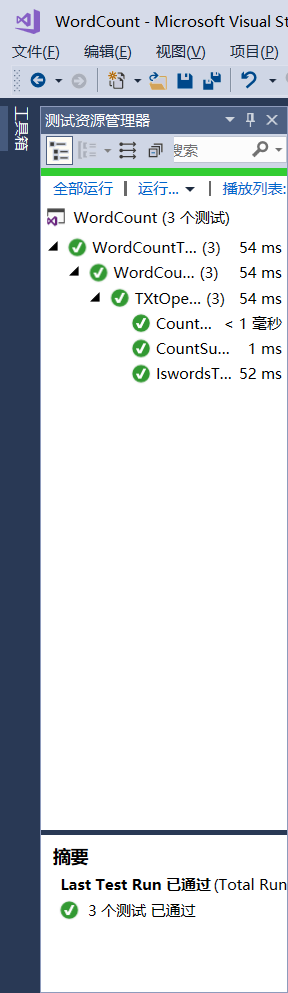
结果:
九.心路历程及收获
在结对编程整体完成后,我们发现预估时间和实际耗时有一定的差距,主要表现在开发阶段两个人的习惯以及思路的不同上,由于我们在代码自审和互审阶段都发现了编码的不规范,所以相比编写代码而言花了更多的时间去修改代码。在编码的过程中我们发现我们要完成的内容比我们想象得要困难,有些部分也从一个小的类改为更为复杂的程序,所以在编码的时候花了比预期更多的时间。在最后测试中,由于我们之间采用的方式不同而导致花费更多的时间。在本次结对编程中,帮助搭档解决了许多其不懂的问题,并且对文件的读写操作,git的相关操作等能更加熟练的运用。还有,我感觉这次结对编程是1+1<2,因为搭档编码经验十分欠缺,所以这次编程基本上都是我一人进行,搭档并没有给予我太多的实质性帮助。
ps:实现过程由于水平有限,可能写的不是很好,见谅。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号