

深度学习(DBBNet重参数化)
DBBNet重参数化是ACNet的升级版本,又可以叫做ACNetV2。
结构如下,训练时将多个结构并联,推理时整合为一个卷积层:
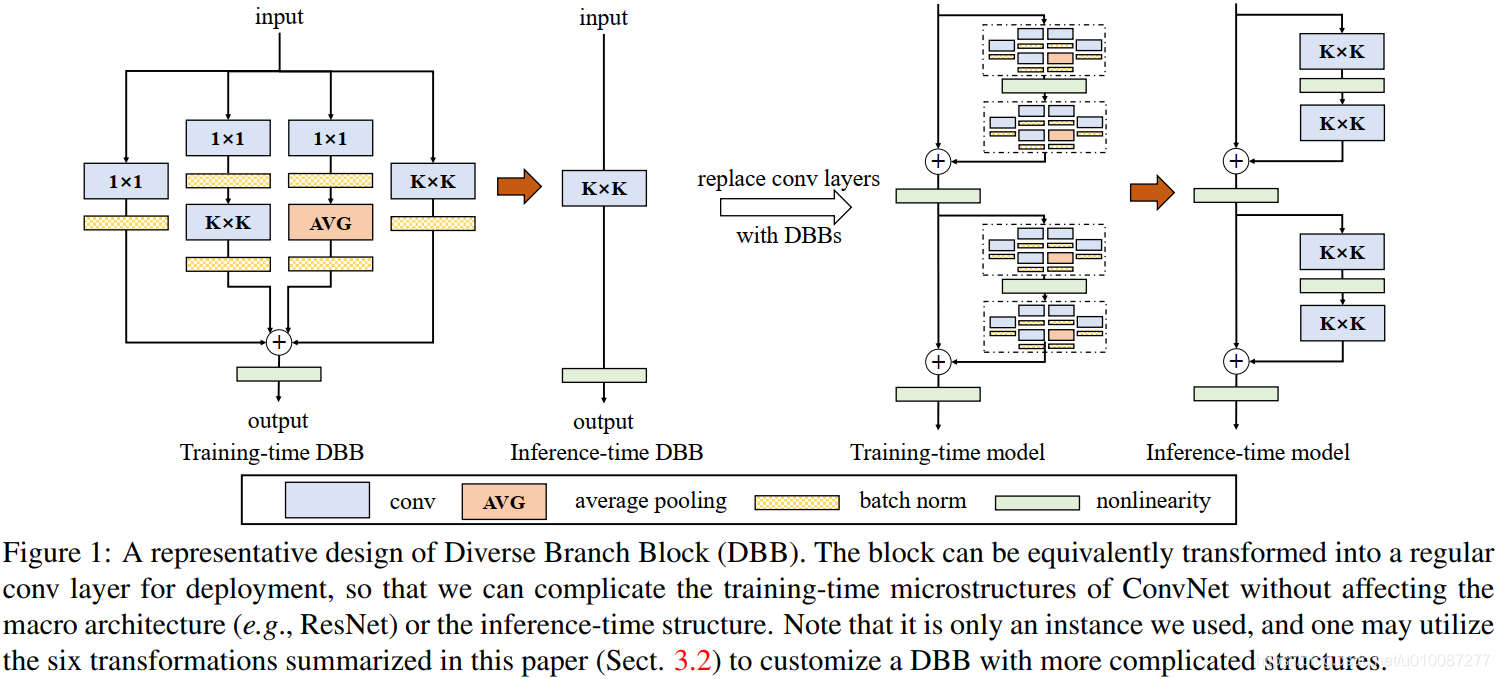
我实现时发现两个卷积做串联再重参数无法保证输入输出张量一样大,最后参考了原始作者代码发现他将BN层改造了一下,从而保证张量大小一致。
串联两个卷积再做重参数可以参考这篇文章:PyTorch 卷积的工作原理或如何将两个卷积折叠为一个 |迈向数据科学
下面代码参考了原始开源工程:https://github.com/DingXiaoH/DiverseBranchBlock
import torch import torch.nn as nn import torch.nn.functional as F import numpy as np def transI_fusebn(kernel, bn): gamma = bn.weight std = (bn.running_var + bn.eps).sqrt() return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / std def transIII_1x1_kxk(k1, b1, k2, b2, groups): if groups == 1: k = F.conv2d(k2, k1.permute(1, 0, 2, 3)) # b_hat = (k2 * b1.reshape(1, -1, 1, 1)).sum((1, 2, 3)) else: k_slices = [] b_slices = [] k1_T = k1.permute(1, 0, 2, 3) k1_group_width = k1.size(0) // groups k2_group_width = k2.size(0) // groups for g in range(groups): k1_T_slice = k1_T[:, g*k1_group_width:(g+1)*k1_group_width, :, :] k2_slice = k2[g*k2_group_width:(g+1)*k2_group_width, :, :, :] k_slices.append(F.conv2d(k2_slice, k1_T_slice)) b_slices.append((k2_slice * b1[g*k1_group_width:(g+1)*k1_group_width].reshape(1, -1, 1, 1)).sum((1, 2, 3))) k, b_hat = transIV_depthconcat(k_slices, b_slices) return k, b_hat + b2 def transIV_depthconcat(kernels, biases): return torch.cat(kernels, dim=0), torch.cat(biases) def transV_avg(channels, kernel_size, groups): input_dim = channels // groups k = torch.zeros((channels, input_dim, kernel_size, kernel_size)) k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2 return k def transVI_multiscale(kernel, target_kernel_size): H_pixels_to_pad = (target_kernel_size - kernel.size(2)) // 2 W_pixels_to_pad = (target_kernel_size - kernel.size(3)) // 2 return F.pad(kernel, [H_pixels_to_pad, H_pixels_to_pad, W_pixels_to_pad, W_pixels_to_pad]) class BNAndPadLayer(nn.Module): def __init__(self, pad_pixels, num_features, eps=1e-5, momentum=0.1, affine=True, track_running_stats=True): super(BNAndPadLayer, self).__init__() self.bn = nn.BatchNorm2d(num_features, eps, momentum, affine, track_running_stats) self.pad_pixels = pad_pixels def forward(self, input): output = self.bn(input) if self.pad_pixels > 0: if self.bn.affine: pad_values = self.bn.bias.detach() - self.bn.running_mean * self.bn.weight.detach() / torch.sqrt(self.bn.running_var + self.bn.eps) else: pad_values = - self.bn.running_mean / torch.sqrt(self.bn.running_var + self.bn.eps) output = F.pad(output, [self.pad_pixels] * 4) pad_values = pad_values.view(1, -1, 1, 1) output[:, :, 0:self.pad_pixels, :] = pad_values output[:, :, -self.pad_pixels:, :] = pad_values output[:, :, :, 0:self.pad_pixels] = pad_values output[:, :, :, -self.pad_pixels:] = pad_values return output @property def weight(self): return self.bn.weight @property def bias(self): return self.bn.bias @property def running_mean(self): return self.bn.running_mean @property def running_var(self): return self.bn.running_var @property def eps(self): return self.bn.eps class DBBNet(nn.Module): def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, deploy=False): super(DBBNet, self).__init__() self.deploy = deploy self.kernel_size = kernel_size self.out_channels = out_channels self.groups = groups self.conv_fusion = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=True) self.dbb_1x1= nn.Sequential() self.dbb_1x1.add_module('conv', nn.Conv2d(in_channels, out_channels, 1, stride=stride, padding=0, groups=groups, bias=False)) self.dbb_1x1.add_module('bn', nn.BatchNorm2d(out_channels)) self.dbb_1x1_kxk = nn.Sequential() self.dbb_1x1_kxk.add_module('conv1', nn.Conv2d(in_channels, in_channels,1, stride=1, padding=0, groups=groups, bias=False)) self.dbb_1x1_kxk.add_module('bn1', BNAndPadLayer(pad_pixels=padding, num_features=in_channels, affine=True)) self.dbb_1x1_kxk.add_module('conv2', nn.Conv2d(in_channels, out_channels,kernel_size, stride=stride, padding=0, groups=groups, bias=False)) self.dbb_1x1_kxk.add_module('bn2', nn.BatchNorm2d(out_channels)) self.dbb_1x1_avg = nn.Sequential() self.dbb_1x1_avg.add_module('conv', nn.Conv2d(in_channels, out_channels,1, stride=stride, padding=0, groups=groups, bias=False)) self.dbb_1x1_avg.add_module('bn', BNAndPadLayer(pad_pixels=padding, num_features=in_channels, affine=True)) self.dbb_1x1_avg.add_module('avgpool', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0)) self.dbb_1x1_avg.add_module('avgbn', nn.BatchNorm2d(out_channels)) self.dbb_kxk = nn.Sequential() self.dbb_kxk.add_module('conv', nn.Conv2d(in_channels, out_channels,kernel_size, stride=stride, padding=padding, groups=groups, bias=False)) self.dbb_kxk.add_module('bn', nn.BatchNorm2d(out_channels)) def reparam(self): self.deploy = True # fus 1x1 k_1x1,b_1x1 = transI_fusebn(self.dbb_1x1.conv.weight, self.dbb_1x1.bn) k_1x1 = transVI_multiscale(k_1x1, self.kernel_size) # fus 1x1_kxk k_1x1_kxk_first, b_1x1_kxk_first = transI_fusebn(self.dbb_1x1_kxk.conv1.weight, self.dbb_1x1_kxk.bn1) k_1x1_kxk_second, b_1x1_kxk_second = transI_fusebn(self.dbb_1x1_kxk.conv2.weight, self.dbb_1x1_kxk.bn2) k_1x1_kxk_merged, b_1x1_kxk_merged = transIII_1x1_kxk(k_1x1_kxk_first, b_1x1_kxk_first, k_1x1_kxk_second, b_1x1_kxk_second, groups=self.groups) # fus 1x1_avg k_avg = transV_avg(self.out_channels, self.kernel_size, self.groups) k_1x1_avg_first, b_1x1_avg_first = transI_fusebn(self.dbb_1x1_avg.conv.weight, self.dbb_1x1_avg.bn) k_1x1_avg_second, b_1x1_avg_second = transI_fusebn(k_avg, self.dbb_1x1_avg.avgbn) k_1x1_avg_merged, b_1x1_avg_merged = transIII_1x1_kxk(k_1x1_avg_first, b_1x1_avg_first, k_1x1_avg_second, b_1x1_avg_second, groups=self.groups) # fus kxk k_kxk, b_kxk = transI_fusebn(self.dbb_kxk.conv.weight, self.dbb_kxk.bn) self.conv_fusion.weight.data = k_1x1 + k_1x1_kxk_merged+ k_kxk + k_1x1_avg_merged self.conv_fusion.bias.data = b_1x1 + b_1x1_kxk_merged + b_kxk+ b_1x1_avg_merged def forward(self, inputs): if self.deploy: return self.conv_fusion(inputs) else: return self.dbb_1x1(inputs) + self.dbb_1x1_kxk(inputs) + self.dbb_kxk(inputs)+ self.dbb_1x1_avg(inputs) x = torch.randn(1, 20, 224, 224) net1 = DBBNet(20,20,3,padding=1,deploy=False) torch.save(net1.state_dict(), "dbb.pth") net1.eval() y1 = net1(x) net2 = DBBNet(20,20,3,padding=1,deploy=False) net2.load_state_dict(torch.load("dbb.pth")) net2.reparam() net2.eval() y2 = net2(x) print(y1.shape,y2.shape) print(torch.allclose(y1, y2, atol=1e-4)) torch.onnx.export(net1, x, "dbb.onnx", input_names=['input'], output_names=['output']) torch.onnx.export(net2, x, "dbb_deploy.onnx", input_names=['input'], output_names=['output'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号