

深度学习(MHA、MQA、GQA)
注意力机制中MHA,MQA和GQA是三种经典的结构:
MHA:每个头有独立的Q、K、V,参数多,模型表现力强,计算成本高。
MQA:所有头共享K和V,每个头有独立的Q,参数少,计算快,但可能牺牲一定的表达能力。
GQA:折中方案,将头分成g组,每组共享K和V,平衡参数和性能。
下图比较好的展示了三种结构的不同:
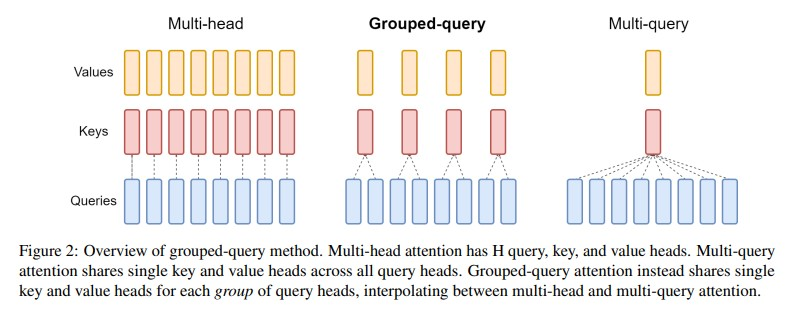
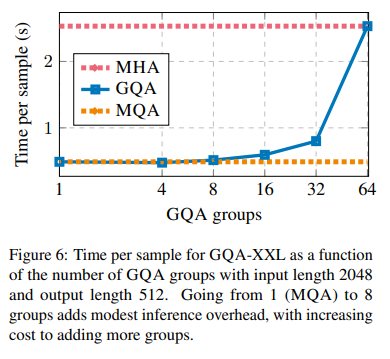
计算成本对比:
代码如下:
import torch import torch.nn as nn class MHA(nn.Module): def __init__(self, d_model, num_heads): super().__init__() self.d_model = d_model self.num_heads = num_heads self.head_dim = d_model // num_heads self.q = nn.Linear(d_model, d_model) self.k = nn.Linear(d_model, d_model) self.v = nn.Linear(d_model, d_model) def forward(self, x): B, L, _ = x.shape q = self.q(x).reshape(B, L, self.num_heads, self.head_dim).transpose(1, 2) k = self.k(x).reshape(B, L, self.num_heads, self.head_dim).transpose(1, 2) v = self.v(x).reshape(B, L, self.num_heads, self.head_dim).transpose(1, 2) print("mha q k v:", q.shape, k.shape, v.shape) attn = torch.matmul(q, k.transpose(-1,-2)) attn = torch.softmax(attn / (self.head_dim ** 0.5), dim=-1) print("mha attn:", attn.shape) out = torch.matmul(attn, v) print("mha out:", out.shape) out = out.transpose(1,2).reshape(B, L, self.d_model) return out class GQA(nn.Module): def __init__(self, d_model, num_heads, num_groups): super().__init__() self.d_model = d_model self.num_heads = num_heads self.num_groups = num_groups self.head_dim = d_model // num_heads self.q = nn.Linear(d_model, d_model) self.k = nn.Linear(d_model, num_groups * self.head_dim) self.v = nn.Linear(d_model, num_groups * self.head_dim) def forward(self, x): B, L, _ = x.shape q = self.q(x).reshape(B, L, self.num_heads, self.head_dim).transpose(1, 2) k = self.k(x).reshape(B, L, self.num_groups, self.head_dim).transpose(1, 2) v = self.v(x).reshape(B, L, self.num_groups, self.head_dim).transpose(1, 2) k = k.repeat_interleave(self.num_heads // self.num_groups, dim=1) v = v.repeat_interleave(self.num_heads // self.num_groups, dim=1) print("gqa q k v:", q.shape, k.shape, v.shape) attn = torch.matmul(q, k.transpose(-1,-2)) attn = torch.softmax(attn / (self.head_dim ** 0.5), dim=-1) print("gqa attn:", attn.shape) out = torch.matmul(attn, v) print("gqa out:", out.shape) out = out.transpose(1,2).reshape(B, L, self.d_model) return out class MQA(nn.Module): def __init__(self, d_model, num_heads): super().__init__() self.d_model = d_model self.num_heads = num_heads self.head_dim = d_model // num_heads self.q = nn.Linear(d_model, d_model) self.k = nn.Linear(d_model, self.head_dim) self.v = nn.Linear(d_model, self.head_dim) def forward(self, x): B, L, _ = x.shape q = self.q(x).reshape(B, L, self.num_heads, self.head_dim).transpose(1, 2) k = self.k(x).reshape(B, L, 1, self.head_dim).transpose(1, 2) v = self.v(x).reshape(B, L, 1, self.head_dim).transpose(1, 2) print("mqa q k v:", q.shape, k.shape, v.shape) attn = torch.matmul(q, k.transpose(-1, -2)) print("mqa attn:", attn.shape) attn = torch.softmax(attn / (self.head_dim ** 0.5), dim=-1) out = torch.matmul(attn, v) print("mqa out:", out.shape) out = out.transpose(1,2).reshape(B, L, self.d_model) return out x = torch.randn(20, 30, 512) # (batch_size, seq_len, d_model) mha = MHA(512, 8) # 512 descriptors, 8 heads gqa = GQA(512, 8, 4) # 512 descriptors, 8 heads, 4 groups mqa = MQA(512, 8) # 512 descriptors, 8 heads y_mha = mha(x) y_gqa = gqa(x) y_mqa = mqa(x) print("MHA Output Shape:", y_mha.shape) print("GQA Output Shape:", y_gqa.shape) print("MQA Output Shape:", y_mqa.shape) total = sum([param.nelement() for param in mha.parameters()]) print("Number of mha parameter: %.2fM" % (total/1e6)) total = sum([param.nelement() for param in gqa.parameters()]) print("Number of gqa parameter: %.2fM" % (total/1e6)) total = sum([param.nelement() for param in mqa.parameters()]) print("Number of mqa parameter: %.2fM" % (total/1e6))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号