深度学习(MobileNetV2)
MobileNetV2的结构图:
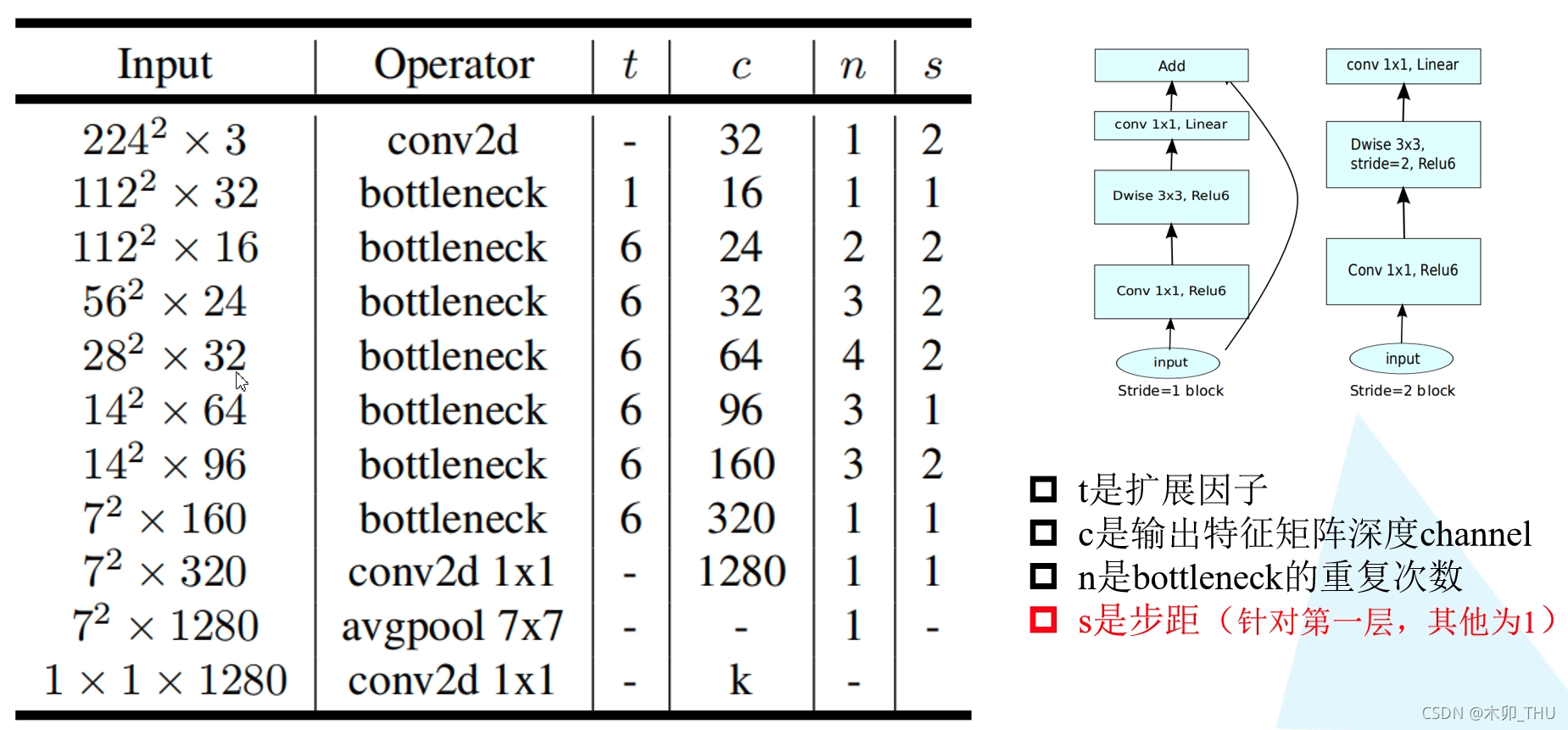
MobileNetV2 的核心创新之一是使用了 倒残差块(Inverted Residual Block)。与传统的残差块不同,倒残差块的结构将卷积操作的顺序进行了颠倒:
- 标准的残差结构:通常先是一个大卷积层(例如,3x3 卷积),然后接一个更小的卷积层(例如,1x1 卷积)。
- 倒残差结构:首先使用一个 1x1 的卷积进行特征映射的扩展(增加通道数),接着使用一个深度可分离卷积(Depthwise Separable Convolution)来处理空间维度,最后再通过一个 1x1 卷积进行特征映射的压缩。
这个设计的优势是,先扩展再压缩,使得网络能够更加高效地提取特征,并保持较低的计算成本。
代码如下:
import torch import torch.nn as nn class InvertedResidual(nn.Module): def __init__(self, in_channels, out_channels, expansion_factor, stride): super(InvertedResidual, self).__init__() self.stride = stride hidden_dim = int(in_channels * expansion_factor) self.conv1 = nn.Conv2d(in_channels, hidden_dim, kernel_size=1, bias=False) self.bn1 = nn.BatchNorm2d(hidden_dim) self.conv2 = nn.Conv2d(hidden_dim, hidden_dim, kernel_size=3, stride=stride, padding=1, groups=hidden_dim, bias=False) self.bn2 = nn.BatchNorm2d(hidden_dim) self.conv3 = nn.Conv2d(hidden_dim, out_channels, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(out_channels) self.use_residual = self.stride == 1 and in_channels == out_channels def forward(self, x): identity = x # 第一个卷积层 x = self.conv1(x) x = self.bn1(x) x = nn.ReLU6(inplace=True)(x) # 第二个卷积层 x = self.conv2(x) x = self.bn2(x) x = nn.ReLU6(inplace=True)(x) # 第三个卷积层 x = self.conv3(x) x = self.bn3(x) # 使用残差连接 if self.use_residual: x += identity return x class MobileNetV2(nn.Module): def __init__(self, num_classes=1000): super(MobileNetV2, self).__init__() pre_channels = 32 self.input_feature = nn.Sequential( nn.Conv2d(3, pre_channels, kernel_size=3, stride=2, padding=1, bias=False), nn.BatchNorm2d(pre_channels), nn.ReLU6(inplace=True)) inverted_residual_setting = [ # t, c, n, s [1, 16, 1, 1], [6, 24, 2, 2], [6, 32, 3, 2], [6, 64, 4, 2], [6, 96, 3, 1], [6, 160, 3, 2], [6, 320, 1, 1]] features = [] for t, c, n, s in inverted_residual_setting: for i in range(n): if i==0: features.append(InvertedResidual(pre_channels, c, expansion_factor=t, stride=s)) else: features.append(InvertedResidual(c, c, expansion_factor=t, stride=1)) pre_channels = c self.features = nn.ModuleList(features) self.out_features = nn.Sequential( nn.Conv2d(320, 1280, kernel_size=1, stride=1, bias=False), nn.BatchNorm2d(1280), nn.ReLU6(inplace=True)) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.classifier = nn.Linear(1280, num_classes) def forward(self, x): x = self.input_feature(x) print(x.shape) for layer in self.features: x = layer(x) print(x.shape) x = self.out_features(x) print(x.shape) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.classifier(x) return x model = MobileNetV2(1000) dat = torch.randn(1, 3, 224, 224) out = model(dat)
参考:
2. https://blog.csdn.net/baidu_36913330/article/details/120079096

 浙公网安备 33010602011771号
浙公网安备 33010602011771号